User safety is at the heart of everything we do at Google. Our mission to make technology helpful for everyone means building features that protect you while keeping your privacy top of mind. From Gmail’s defenses that stop more than 99.9% of spam, phishing and malware, to Google Messages’ advanced security that protects users from 2 billion suspicious messages a month and beyond, we're constantly developing and expanding protection features that help keep you safe.
We're introducing two new real-time protection features that enhance your safety, all while safeguarding your privacy: Scam Detection in Phone by Google to protect you from scams and fraud, and Google Play Protect live threat detection with real-time alerts to protect you from malware and dangerous apps.
These new security features are available first on Pixel, and are coming soon to more Android devices.
Scammers steal over $1 trillion dollars a year from people, and phone calls are their favorite way to do it. Even more alarming, scam calls are evolving, becoming increasingly more sophisticated, damaging and harder to identify. That’s why we’re using the best of Google AI to identify and stop scams before they can do harm with Scam Detection.
Real-time protection, built with your privacy in mind.
We’re now rolling out Scam Detection to English-speaking Phone by Google public beta users in the U.S. with a Pixel 6 or newer device.
To provide feedback on your experience, please click on Phone by Google App -> Menu -> Help & Feedback -> Send Feedback. We look forward to learning from this beta and your feedback, and we’ll share more about Scam Detection in the months ahead.
Google Play Protect works non-stop to protect you in real-time from malware and unsafe apps. Play Protect analyzes behavioral signals related to the use of sensitive permissions and interactions with other apps and services.With live threat detection, if a harmful app is found, you'll now receive a real-time alert, allowing you to take immediate action to protect your device. By looking at actual activity patterns of apps, live threat detection can now find malicious apps that try extra hard to hide their behavior or lie dormant for a time before engaging in suspicious activity.
At launch, live threat detection will focus on stalkerware, code that may collect personal or sensitive data for monitoring purposes without user consent, and we will explore expanding its detection to other types of harmful apps in the future. All of this protection happens on your device in a privacy preserving way through Private Compute Core, which allows us to protect users without collecting data.
Live threat detection with real-time alerts in Google Play Protect are now available on Pixel 6+ devices and will be coming to additional phone makers in the coming months.
Every day, over a billion people use Google Messages to communicate. That’s why we’ve made security a top priority, building in powerful on-device, AI-powered filters and advanced security that protects users from 2 billion suspicious messages a month. With end-to-end encrypted1 RCS conversations, you can communicate privately with other Google Messages RCS users. And we’re not stopping there. We're committed to constantly developing new controls and features to make your conversations on Google Messages even more secure and private.
As part of cybersecurity awareness month, we're sharing five new protections to help keep you safe while using Google Messages on Android:
These are just some of the new and upcoming features that you can use to better protect yourself when sending and receiving messages. Download Google Messages from the Google Play Store to enjoy these protections and controls and learn more about Google Messages here.
End-to-end encryption is currently available between Google Messages users. Availability of RCS varies by region and carrier. ↩
Availability of features may vary by market and device. Sign up for beta testing and a data plan may be required. ↩
Requires 2 GB of RAM. ↩
Janine Roberta Ferreira was driving home from work in São Paulo when she stopped at a traffic light. A man suddenly appeared and broke the window of her unlocked car, grabbing her phone. She struggled with him for a moment before he wrestled the phone away and ran off. The incident left her deeply shaken. Not only was she saddened at the loss of precious data, like pictures of her nephew, but she also felt vulnerable knowing her banking information was on her phone that was just stolen by a thief.
Situations like Janine’s highlighted the need for a comprehensive solution to phone theft that exceeded existing tools on any platform. Phone theft is a widespread concern in many countries – 97 phones are robbed or stolen every hour in Brazil. The GSM Association reports millions of devices stolen every year, and the numbers continue to grow.
With our phones becoming increasingly central to storing sensitive data, like payment information and personal details, losing one can be an unsettling experience. That’s why we developed and thoroughly beta tested, a full suite of features designed to protect you and your data at every stage – before, during, and after device theft. These advanced theft protection features are now available to users around the world through Android 15 and a Google Play Services update (Android 10+ devices).
Theft Detection Lock uses powerful AI to proactively protect you at the moment of a theft attempt. By using on-device machine learning, Theft Detection Lock is able to analyze various device signals to detect potential theft attempts. If the algorithm detects a potential theft attempt on your unlocked device, it locks your screen to keep thieves out.
To protect your sensitive data if your phone is stolen, Theft Detection Lock uses device sensors to identify theft attempts. We’re working hard to bring this feature to as many devices as possible. This feature is rolling out gradually to ensure compatibility with various devices, starting today with Android devices that cover 90% of active users worldwide. Check your theft protection settings page periodically to see if your device is currently supported.
In addition to Theft Detection Lock, Offline Device Lock protects you if a thief tries to take your device offline to extract data or avoid a remote wipe via Android’s Find My Device. If an unlocked device goes offline for prolonged periods, this feature locks the screen to ensure your phone can’t be used in the hands of a thief.
If your Android device does become lost or stolen, Remote Lock can quickly help you secure it. Even if you can’t remember your Google account credentials in the moment of theft, you can use any device to visit Android.com/lock and lock your phone with just a verified phone number. Remote Lock secures your device while you regain access through Android’s Find My Device – which lets you secure, locate or remotely wipe your device. As a security best practice, we always recommend backing up your device on a continuous basis, so remotely wiping your device is not an issue.
These features are now available on most Android 10+ devices1 via a Google Play Services update and must be enabled in settings.
Android 15 introduces new security features to deter theft before it happens by making it harder for thieves to access sensitive settings, apps, or reset your device for resale:
Later this year, we’ll launch Identity Check, an opt-in feature that will add an extra layer of protection by requiring biometric authentication when accessing critical Google account and device settings, like changing your PIN, disabling theft protection, or accessing Passkeys from an untrusted location. This helps prevent unauthorized access even if your device PIN is compromised.
By integrating advanced technology like AI and biometric authentication, we're making Android devices less appealing targets for thieves to give you greater peace of mind. These theft protection features are just one example of how Android is working to provide real-world protection for everyone. We’re dedicated to working with our partners around the world to continuously improve Android security and help you and your data stay safe.
You can turn on the new Android theft features by clicking here on a supported Android device. Learn more about our theft protection features by visiting our help center.
Android Go smartphones, tablets and wearables are not supported ↩
Pixel phones have earned a well-deserved reputation for being security-conscious. In this blog, we'll take a peek under the hood to see how Pixel mitigates common exploits on cellular basebands.
Smartphones have become an integral part of our lives, but few of us think about the complex software that powers them, especially the cellular baseband – the processor on the device responsible for handling all cellular communication (such as LTE, 4G, and 5G). Most smartphones use cellular baseband processors with tight performance constraints, making security hardening difficult. Security researchers have increasingly exploited this attack vector and routinely demonstrated the possibility of exploiting basebands used in popular smartphones.
The good news is that Pixel has been deploying security hardening mitigations in our basebands for years, and Pixel 9 represents the most hardened baseband we've shipped yet. Below, we’ll dive into why this is so important, how specifically we’ve improved security, and what this means for our users.
The Cellular Baseband
The cellular baseband within a smartphone is responsible for managing the device's connectivity to cellular networks. This function inherently involves processing external inputs, which may originate from untrusted sources. For instance, malicious actors can employ false base stations to inject fabricated or manipulated network packets. In certain protocols like IMS (IP Multimedia Subsystem), this can be executed remotely from any global location using an IMS client.
The firmware within the cellular baseband, similar to any software, is susceptible to bugs and errors. In the context of the baseband, these software vulnerabilities pose a significant concern due to the heightened exposure of this component within the device's attack surface. There is ample evidence demonstrating the exploitation of software bugs in modem basebands to achieve remote code execution, highlighting the critical risk associated with such vulnerabilities.
The State of Baseband Security
Baseband security has emerged as a prominent area of research, with demonstrations of software bug exploitation featuring in numerous security conferences. Many of these conferences now also incorporate training sessions dedicated to baseband firmware emulation, analysis, and exploitation techniques.
Recent reports by security researchers have noted that most basebands lack exploit mitigations commonly deployed elsewhere and considered best practices in software development. Mature software hardening techniques that are commonplace in the Android operating system, for example, are often absent from cellular firmwares of many popular smartphones.
There are clear indications that exploit vendors and cyber-espionage firms abuse these vulnerabilities to breach the privacy of individuals without their consent. For example, 0-day exploits in the cellular baseband are being used to deploy the Predator malware in smartphones. Additionally, exploit marketplaces explicitly list baseband exploits, often with relatively low payouts, suggesting a potential abundance of such vulnerabilities. These vulnerabilities allow attackers to gain unauthorized access to a device, execute arbitrary code, escalate privileges, or extract sensitive information.
Recognizing these industry trends, Android and Pixel have proactively updated their Vulnerability Rewards Program in recent years, placing a greater emphasis on identifying and addressing exploitable bugs in connectivity firmware.
Building a Fortress: Proactive Defenses in the Pixel Modem
In response to the rising threat of baseband security attacks, Pixel has incrementally incorporated many of the following proactive defenses over the years, with the Pixel 9 phones (Pixel 9, Pixel 9 Pro, Pixel 9 Pro XL and Pixel 9 Pro Fold) showcasing the latest features:
We also leverage a number of bug detection tools, such as address sanitizer, during our testing process. This helps us identify software bugs and patch them prior to shipping devices to our users.
The Pixel Advantage: Combining Protections for Maximum Security
Security hardening is difficult and our work is never done, but when these security measures are combined, they significantly increase Pixel 9’s resilience to baseband attacks.
Pixel's proactive approach to security demonstrates a commitment to protecting its users across the entire software stack. Hardening the cellular baseband against remote attacks is just one example of how Pixel is constantly working to stay ahead of the curve when it comes to security.
Special thanks to our colleagues who supported our cellular baseband hardening efforts: Dominik Maier, Shawn Yang, Sami Tolvanen, Pirama Arumuga Nainar, Stephen Hines, Kevin Deus, Xuan Xing, Eugene Rodionov, Stephan Somogyi, Wes Johnson, Suraj Harjani, Morgan Shen, Valery Wu, Clint Chen, Cheng-Yi He, Estefany Torres, Hungyen Weng, Jerry Hung, Sherif Hanna
Memory safety vulnerabilities remain a pervasive threat to software security. At Google, we believe the path to eliminating this class of vulnerabilities at scale and building high-assurance software lies in Safe Coding, a secure-by-design approach that prioritizes transitioning to memory-safe languages.
This post demonstrates why focusing on Safe Coding for new code quickly and counterintuitively reduces the overall security risk of a codebase, finally breaking through the stubbornly high plateau of memory safety vulnerabilities and starting an exponential decline, all while being scalable and cost-effective.
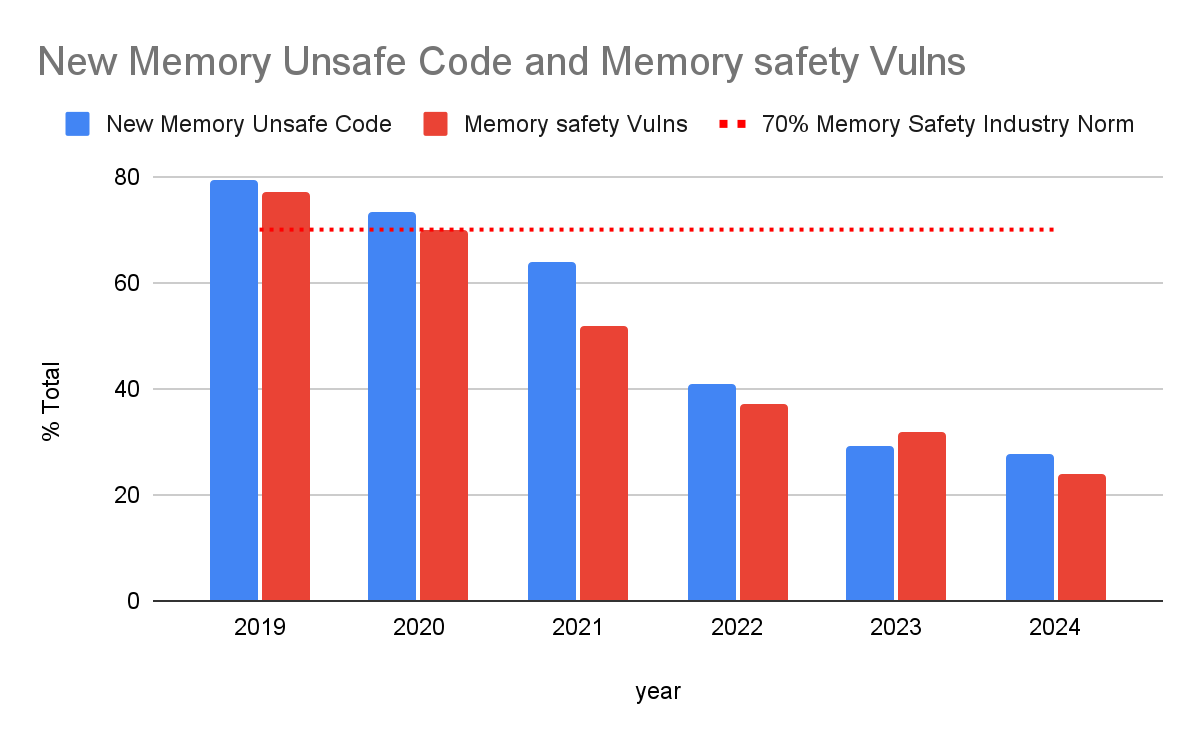
We’ll also share updated data on how the percentage of memory safety vulnerabilities in Android dropped from 76% to 24% over 6 years as development shifted to memory safe languages.
Consider a growing codebase primarily written in memory-unsafe languages, experiencing a constant influx of memory safety vulnerabilities. What happens if we gradually transition to memory-safe languages for new features, while leaving existing code mostly untouched except for bug fixes?
We can simulate the results. After some years, the code base has the following makeup1 as new memory unsafe development slows down, and new memory safe development starts to take over:
In the final year of our simulation, despite the growth in memory-unsafe code, the number of memory safety vulnerabilities drops significantly, a seemingly counterintuitive result not seen with other strategies:
This reduction might seem paradoxical: how is this possible when the quantity of new memory unsafe code actually grew?
The answer lies in an important observation: vulnerabilities decay exponentially. They have a half-life. The distribution of vulnerability lifetime follows an exponential distribution given an average vulnerability lifetime λ:
A large-scale study of vulnerability lifetimes2 published in 2022 in Usenix Security confirmed this phenomenon. Researchers found that the vast majority of vulnerabilities reside in new or recently modified code:
This confirms and generalizes our observation, published in 2021, that the density of Android’s memory safety bugs decreased with the age of the code, primarily residing in recent changes.
This leads to two important takeaways:
For example, based on the average vulnerability lifetimes, 5-year-old code has a 3.4x (using lifetimes from the study) to 7.4x (using lifetimes observed in Android and Chromium) lower vulnerability density than new code.
In real life, as with our simulation, when we start to prioritize prevention, the situation starts to rapidly improve.
The Android team began prioritizing transitioning new development to memory safe languages around 2019. This decision was driven by the increasing cost and complexity of managing memory safety vulnerabilities. There’s much left to do, but the results have already been positive. Here’s the big picture in 2024, looking at total code:
Despite the majority of code still being unsafe (but, crucially, getting progressively older), we’re seeing a large and continued decline in memory safety vulnerabilities. The results align with what we simulated above, and are even better, potentially as a result of our parallel efforts to improve the safety of our memory unsafe code. We first reported this decline in 2022, and we continue to see the total number of memory safety vulnerabilities dropping3. Note that the data for 2024 is extrapolated to the full year (represented as 36, but currently at 27 after the September security bulletin).
The percent of vulnerabilities caused by memory safety issues continues to correlate closely with the development language that’s used for new code. Memory safety issues, which accounted for 76% of Android vulnerabilities in 2019, and are currently 24% in 2024, well below the 70% industry norm, and continuing to drop.
As we noted in a previous post, memory safety vulnerabilities tend to be significantly more severe, more likely to be remotely reachable, more versatile, and more likely to be maliciously exploited than other vulnerability types. As the number of memory safety vulnerabilities have dropped, the overall security risk has dropped along with it.
Over the past decades, the industry has pioneered significant advancements to combat memory safety vulnerabilities, with each generation of advancements contributing valuable tools and techniques that have tangibly improved software security. However, with the benefit of hindsight, it’s evident that we have yet to achieve a truly scalable and sustainable solution that achieves an acceptable level of risk:
1st generation: reactive patching. The initial focus was mainly on fixing vulnerabilities reactively. For problems as rampant as memory safety, this incurs ongoing costs on the business and its users. Software manufacturers have to invest significant resources in responding to frequent incidents. This leads to constant security updates, leaving users vulnerable to unknown issues, and frequently albeit temporarily vulnerable to known issues, which are getting exploited ever faster.
2nd generation: proactive mitigating. The next approach consisted of reducing risk in vulnerable software, including a series of exploit mitigation strategies that raised the costs of crafting exploits. However, these mitigations, such as stack canaries and control-flow integrity, typically impose a recurring cost on products and development teams, often putting security and other product requirements in conflict:
3rd generation: proactive vulnerability discovery. The following generation focused on detecting vulnerabilities. This includes sanitizers, often paired with fuzzing like libfuzzer, many of which were built by Google. While helpful, these methods address the symptoms of memory unsafety, not the root cause. They typically require constant pressure to get teams to fuzz, triage, and fix their findings, resulting in low coverage. Even when applied thoroughly, fuzzing does not provide high assurance, as evidenced by vulnerabilities found in extensively fuzzed code.
Products across the industry have been significantly strengthened by these approaches, and we remain committed to responding to, mitigating, and proactively hunting for vulnerabilities. Having said that, it has become increasingly clear that those approaches are not only insufficient for reaching an acceptable level of risk in the memory-safety domain, but incur ongoing and increasing costs to developers, users, businesses, and products. As highlighted by numerous government agencies, including CISA, in their secure-by-design report, "only by incorporating secure by design practices will we break the vicious cycle of constantly creating and applying fixes."
The shift towards memory safe languages represents more than just a change in technology, it is a fundamental shift in how to approach security. This shift is not an unprecedented one, but rather a significant expansion of a proven approach. An approach that has already demonstrated remarkable success in eliminating other vulnerability classes like XSS.
The foundation of this shift is Safe Coding, which enforces security invariants directly into the development platform through language features, static analysis, and API design. The result is a secure by design ecosystem providing continuous assurance at scale, safe from the risk of accidentally introducing vulnerabilities.
The shift from previous generations to Safe Coding can be seen in the quantifiability of the assertions that are made when developing code. Instead of focusing on the interventions applied (mitigations, fuzzing), or attempting to use past performance to predict future security, Safe Coding allows us to make strong assertions about the code's properties and what can or cannot happen based on those properties.
Safe Coding's scalability lies in its ability to reduce costs by:
Based on what we’ve learned, it's become clear that we do not need to throw away or rewrite all our existing memory-unsafe code. Instead, Android is focusing on making interoperability safe and convenient as a primary capability in our memory safety journey. Interoperability offers a practical and incremental approach to adopting memory safe languages, allowing organizations to leverage existing investments in code and systems, while accelerating the development of new features.
We recommend focusing investments on improving interoperability, as we are doing with Rust ↔︎ C++ and Rust ↔︎ Kotlin. To that end, earlier this year, Google provided a $1,000,000 grant to the Rust Foundation, in addition to developing interoperability tooling like Crubit and autocxx.
As Safe Coding continues to drive down risk, what will be the role of mitigations and proactive detection? We don’t have definitive answers in Android, but expect something like the following:
Fighting against the math of vulnerability lifetimes has been a losing battle. Adopting Safe Coding in new code offers a paradigm shift, allowing us to leverage the inherent decay of vulnerabilities to our advantage, even in large existing systems. The concept is simple: once we turn off the tap of new vulnerabilities, they decrease exponentially, making all of our code safer, increasing the effectiveness of security design, and alleviating the scalability challenges associated with existing memory safety strategies such that they can be applied more effectively in a targeted manner.
This approach has proven successful in eliminating entire vulnerability classes and its effectiveness in tackling memory safety is increasingly evident based on more than half a decade of consistent results in Android.
We'll be sharing more about our secure-by-design efforts in the coming months.
Thanks Alice Ryhl for coding up the simulation. Thanks to Emilia Kasper, Adrian Taylor, Manish Goregaokar, Christoph Kern, and Lars Bergstrom for your helpful feedback on this post.
Simulation was based on numbers similar to Android and other Google projects. The code base doubles every 6 years. The average lifetime for vulnerabilities is 2.5 years. It takes 10 years to transition to memory safe languages for new code, and we use a sigmoid function to represent the transition. Note that the use of the sigmoid function is why the second chart doesn’t initially appear to be exponential. ↩
Alexopoulos et al. "How Long Do Vulnerabilities Live in the Code? A Large-Scale Empirical Measurement Study on FOSS Vulnerability Lifetimes". USENIX Security 22. ↩
Unlike our simulation, these are vulnerabilities from a real code base, which comes with higher variance, as you can see in the slight increase in 2023. Vulnerability reports were unusually high that year, but in line with expectations given code growth, so while the percentage of memory safety vulnerabilities continued to drop, the absolute number increased slightly. ↩
You, me, and the entire ecosystem! GPUs (graphics processing units) are critical in delivering rich visual experiences on mobile devices. However, the GPU software and firmware stack has become a way for attackers to gain permissions and entitlements (privilege escalation) to Android-based devices. There are plenty of issues in this category that can affect all major GPU brands, for example, CVE-2023-4295, CVE-2023-21106, CVE-2021-0884, and more. Most exploitable GPU vulnerabilities are in the implementation of the GPU kernel mode modules. These modules are pieces of code that load/unload during runtime, extending functionality without the need to reboot the device.
Proactive testing is good hygiene as it can lead to the detection and resolution of new vulnerabilities before they’re exploited. It’s also one of the most complex investigations to do as you don’t necessarily know where the vulnerability will appear (that’s the point!). By combining the expertise of Google’s engineers with IP owners and OEMs, we can ensure the Android ecosystem retains a strong measure of integrity.
When researching vulnerabilities, GPUs are a popular target due to:
Nobody wants a slow, unresponsive device; any hits to GPU performance could result in a noticeably degraded user experience. As such, the GPU software stack in Android relies on an in-process HAL model where the API & user space drivers communicating with the GPU kernel mode module are running directly within the context of apps, thus avoiding IPC (interprocess communication). This opens the door for potentially untrusted code from a third party app being able to directly access the interface exposed by the GPU kernel module. If there are any vulnerabilities in the module, the third party app has an avenue to exploit them. As a result, a potentially untrusted code running in the context of the third party application is able to directly access the interface exposed by the GPU kernel module and exploit potential vulnerabilities in the kernel module.
Additionally, the implementation of GPU subsystems (and kernel modules specifically) from major OEMs are increasingly complex. Kernel modules for most GPUs are typically written in memory unsafe languages such as C, which are susceptible to memory corruption vulnerabilities like buffer overflow.
Great news, we already have! Who’s we? The Android Red Team and Arm! We’ve worked together to run an engagement on the Mali GPU (more on that below), but first, a brief introduction:
Android Red Team
The Android Red Team performs time-bound security assessment engagements on all aspects of the Android open source codebase and conducts regular security reviews and assessments of internal Android components. Throughout these engagements, the Android Red Team regularly collaborates with 3rd party software and hardware providers to analyze and understand proprietary and “closed source” code repositories and relevant source code that are utilized by Android products with the sole objective to identify security risks and potential vulnerabilities before they can be exploited by adversaries outside of Android. This year, the Android Red Team collaborated directly with our industry partner, Arm, to conduct the Mali GPU engagement and further secure millions of Android devices.
Arm Product Security and GPU Teams
Arm has a central product security team that sets the policy and practice across the company. They also have dedicated product security experts embedded in engineering teams. Arm operates a systematic approach which is designed to prevent, discover, and eliminate security vulnerabilities. This includes a Security Development Lifecycle (SDL), a Monitoring capability, and Incident Response. For this collaboration the Android Red Teams were supported by the embedded security experts based in Arm’s GPU engineering team.
Google’s Android Security teams and Arm have been working together for a long time. Security requirements are never static, and challenges exist with all GPU vendors. By frequently sharing expertise, the Android Red Team and Arm were able to accelerate detection and resolution. Investigations of identified vulnerabilities, potential remediation strategies, and hardening measures drove detailed analyses and the implementation of fixes where relevant.
Recent research focused on the Mali GPU because it is the most popular GPU in today's Android devices. Collaborating on GPU security allowed us to:
Investigations have led to significant improvements, leveling up the security of the GPU software/firmware stack across a wide segment of the Android ecosystem.
One key component of the GPU subsystem is its kernel mode driver. During this engagement, both the Android Red Team and Arm invested significant effort looking at the Mali kbase kernel driver. Due to its complexity, fuzzing was chosen as the primary testing approach for this area. Fuzzing automates and scales vulnerability discovery in a way not possible via manual methods. With help from Arm, the Android Red Team added more syzkaller fuzzing descriptions to match the latest Mali kbase driver implementation.
The team built a few customizations to enable fuzzing the Mali kbase driver in the cloud, without physical hardware. This provided a huge improvement to fuzzing performance and scalability. With the Pixel team’s support, we also were able to set up fuzzing on actual Pixel devices. Through the combination of cloud-based fuzzing, Pixel-based fuzzing, and manual review, we were able to uncover two memory issues in Pixel’s customization of driver code (CVE-2023-48409 and CVE-2023-48421).
Both issues occurred inside of the gpu_pixel_handle_buffer_liveness_update_ioctl function, which is implemented by the Pixel team as part of device specific customization. These are both memory issues caused by integer overflow problems. If exploited carefully alongside other vulnerabilities, these issues could lead to kernel privilege escalation from user space. Both issues were fixed and the patch was released to affected devices in Pixel security bulletin 2023-12-01.
Firmware is another fundamental building block of the GPU subsystem. It’s the intermediary working with kernel drivers and GPU hardware. In many cases, firmware functionality is directly/indirectly accessible from the application. So “application ⇒ kernel ⇒ firmware ⇒ kernel” is a known attack flow in this area. Also, in general, firmware runs on embedded microcontrollers with limited resources. Commonly used security kernel mitigations (ASLR, stack protection, heap protection, certain sanitizers, etc.) might not be applicable to firmware due to resource constraints and performance impact. This can make compromising firmware easier, in some cases, than directly compromising kernel drivers from user space. To test the integrity of existing firmware, the Android Red Team and Arm worked together to perform both fuzzing and formal verification along with manual analysis. This multi-pronged approach led to the discovery of CVE-2024-0153, which had a patch released in the July 2024 Android Security Bulletin.
CVE-2024-0153 happens when GPU firmware handles certain instructions. When handling such instructions, the firmware copies register content into a buffer. There are size checks before the copy operation. However, under very specific conditions, an out-of-bounds write happens to the destination buffer, leading to a buffer overflow. When carefully manipulated, this overflow will overwrite some other important structures following the buffer, causing code execution inside of the GPU firmware.
The conditions necessary to reach and potentially exploit this issue are very complex as it requires a deep understanding of how instructions are executed. With collective expertise, the Android Red Team and Arm were able to verify the exploitation path and leverage the issue to gain limited control of GPU firmware. This eventually circled back to the kernel to obtain privilege escalation. Arm did an excellent job to respond quickly and remediate the issue. Altogether, this highlights the strength of collaboration between both teams to dive deeper.
It’s known that attackers exploit GPU vulnerabilities in the wild, and time to patch is crucial to reduce risk of exploitation and protect users. As a result of this engagement, nine new Security Test suite (STS) tests were built to help partners automatically check their builds for missing Mali kbase patches. (Security Test Suite is software provided by Google to help partners automate the process of checking their builds for missing security patches.)
The Arm Product Security Team is actively involved in security-focused industry communities and collaborates closely with its ecosystem partners. The engagement with the Android Red Team, for instance, provides valuable enablement that drives best practices and product excellence. Building on this collaborative approach, Arm is complementing its product security assurance capabilities with a bug bounty program. This investment will expand Arm’s efforts to identify potential vulnerabilities. For more information on Arm's product security initiatives, please visit this product security page.
The Android Red Team and Arm continue to work together to proactively raise the bar on GPU security. With thorough testing, rapid fixing, and updates to the security test suite, we’re improving the ecosystem for Android users. The Android Red Team looks forward to replicating this working relationship with other ecosystem partners to make devices more secure.
Posted by Ivan Lozano and Dominik Maier, Android Team
Android's use of safe-by-design principles drives our adoption of memory-safe languages like Rust, making exploitation of the OS increasingly difficult with every release. To provide a secure foundation, we’re extending hardening and the use of memory-safe languages to low-level firmware (including in Trusty apps).
In this blog post, we'll show you how to gradually introduce Rust into your existing firmware, prioritizing new code and the most security-critical code. You'll see how easy it is to boost security with drop-in Rust replacements, and we'll even demonstrate how the Rust toolchain can handle specialized bare-metal targets.
Drop-in Rust replacements for C code are not a novel idea and have been used in other cases, such as librsvg’s adoption of Rust which involved replacing C functions with Rust functions in-place. We seek to demonstrate that this approach is viable for firmware, providing a path to memory-safety in an efficient and effective manner.
Firmware serves as the interface between hardware and higher-level software. Due to the lack of software security mechanisms that are standard in higher-level software, vulnerabilities in firmware code can be dangerously exploited by malicious actors. Modern phones contain many coprocessors responsible for handling various operations, and each of these run their own firmware. Often, firmware consists of large legacy code bases written in memory-unsafe languages such as C or C++. Memory unsafety is the leading cause of vulnerabilities in Android, Chrome, and many other code bases.
Rust provides a memory-safe alternative to C and C++ with comparable performance and code size. Additionally it supports interoperability with C with no overhead. The Android team has discussed Rust for bare-metal firmware previously, and has developed training specifically for this domain.
Our incremental approach focusing on replacing new and highest risk existing code (for example, code which processes external untrusted input) can provide maximum security benefits with the least amount of effort. Simply writing any new code in Rust reduces the number of new vulnerabilities and over time can lead to a reduction in the number of outstanding vulnerabilities.
You can replace existing C functionality by writing a thin Rust shim that translates between an existing Rust API and the C API the codebase expects. The C API is replicated and exported by the shim for the existing codebase to link against. The shim serves as a wrapper around the Rust library API, bridging the existing C API and the Rust API. This is a common approach when rewriting or replacing existing libraries with a Rust alternative.
There are several challenges you need to consider before introducing Rust to your firmware codebase. In the following section we address the general state of no_std Rust (that is, bare-metal Rust code), how to find the right off-the-shelf crate (a rust library), porting an std crate to no_std, using Bindgen to produce FFI bindings, how to approach allocators and panics, and how to set up your toolchain.
Rust's standard library consists of three crates: core, alloc, and std. The core crate is always available. The alloc crate requires an allocator for its functionality. The std crate assumes a full-blown operating system and is commonly not supported in bare-metal environments. A third-party crate indicates it doesn’t rely on std through the crate-level #![no_std] attribute. This crate is said to be no_std compatible. The rest of the blog will focus on these.
When choosing a component to replace, focus on self-contained components with robust testing. Ideally, the components functionality can be provided by an open-source implementation readily available which supports bare-metal environments.
Parsers which handle standard and commonly used data formats or protocols (such as, XML or DNS) are good initial candidates. This ensures the initial effort focuses on the challenges of integrating Rust with the existing code base and build system rather than the particulars of a complex component and simplifies testing. This approach eases introducing more Rust later on.
Picking the right open-source crate (Rust library) to replace the chosen component is crucial. Things to consider are:
Is the crate well maintained, for example, are open issues being addressed and does it use recent crate versions?
How widely used is the crate? This may be used as a quality signal, but also important to consider in the context of using crates later on which may depend on it.
Does the crate have acceptable documentation?
Does it have acceptable test coverage?
Additionally, the crate should ideally be no_std compatible, meaning the standard library is either unused or can be disabled. While a wide range of no_std compatible crates exist, others do not yet support this mode of operation – in those cases, see the next section on converting a std library to no_std.
By convention, crates which optionally support no_std will provide an std feature to indicate whether the standard library should be used. Similarly, the alloc feature usually indicates using an allocator is optional.
Note: Even when a library declares #![no_std] in its source, there is no guarantee that its dependencies don’t depend on std. We recommend looking through the dependency tree to ensure that all dependencies support no_std, or test whether the library compiles for a no_std target. The only way to know is currently by trying to compile the crate for a bare-metal target.
For example, one approach is to run cargo check with a bare-metal toolchain provided through rustup:
$ rustup target add aarch64-unknown-none
$ cargo check --target aarch64-unknown-none --no-default-features
If a library does not support no_std, it might still be possible to port it to a bare-metal environment – especially file format parsers and other OS agnostic workloads. Higher-level functionality such as file handling, threading, and async code may present more of a challenge. In those cases, such functionality can be hidden behind feature flags to still provide the core functionality in a no_std build.
To port a std crate to no_std (core+alloc):
In the cargo.toml file, add a std feature, then add this std feature to the default features
Add the following lines to the top of the lib.rs:
#![no_std]
#[cfg(feature = "std")]
extern crate std;
extern crate alloc;
Then, iteratively fix all occurring compiler errors as follows:
Move any use directives from std to either core or alloc.
Add use directives for all types that would otherwise automatically be imported by the std prelude, such as alloc::vec::Vec and alloc::string::String.
Hide anything that doesn't exist in core or alloc and cannot otherwise be supported in the no_std build (such as file system accesses) behind a #[cfg(feature = "std")] guard.
Anything that needs to interact with the embedded environment may need to be explicitly handled, such as functions for I/O. These likely need to be behind a #[cfg(not(feature = "std"))] guard.
Disable std for all dependencies (that is, change their definitions in Cargo.toml, if using Cargo).
This needs to be repeated for all dependencies within the crate dependency tree that do not support no_std yet.
There are a number of officially supported targets by the Rust compiler, however, many bare-metal targets are missing from that list. Thankfully, the Rust compiler lowers to LLVM IR and uses an internal copy of LLVM to lower to machine code. Thus, it can support any target architecture that LLVM supports by defining a custom target.
Defining a custom target requires a toolchain built with the channel set to dev or nightly. Rust’s Embedonomicon has a wealth of information on this subject and should be referred to as the source of truth.
To give a quick overview, a custom target JSON file can be constructed by finding a similar supported target and dumping the JSON representation:
$ rustc --print target-list
[...]
armv7a-none-eabi
$ rustc -Z unstable-options --print target-spec-json --target armv7a-none-eabi
This will print out a target JSON that looks something like:
$ rustc --print target-spec-json -Z unstable-options --target=armv7a-none-eabi
{
"abi": "eabi",
"arch": "arm",
"c-enum-min-bits": 8,
"crt-objects-fallback": "false",
"data-layout": "e-m:e-p:32:32-Fi8-i64:64-v128:64:128-a:0:32-n32-S64",
}
This output can provide a starting point for defining your target. Of particular note, the data-layout field is defined in the LLVM documentation.
Once the target is defined, libcore and liballoc (and libstd, if applicable) must be built from source for the newly defined target. If using Cargo, building with -Z build-std accomplishes this, indicating that these libraries should be built from source for your target along with your crate module:
# set build-std to the list of libraries needed
cargo build -Z build-std=core,alloc --target my_target.json
If the bare-metal architecture is not supported by the LLVM bundled internal to the Rust toolchain, a custom Rust toolchain can be produced with any LLVM prebuilts that support the target.
The instructions for building a Rust toolchain can be found in detail in the Rust Compiler Developer Guide. In the config.toml, llvm-config must be set to the path of the LLVM prebuilts.
You can find the latest Rust Toolchain supported by a particular version of LLVM by checking the release notes and looking for releases which bump up the minimum supported LLVM version. For example, Rust 1.76 bumped the minimum LLVM to 16 and 1.73 bumped the minimum LLVM to 15. That means with LLVM15 prebuilts, the latest Rust toolchain that can be built is 1.75.
To create a drop-in replacement for the C/C++ function or API being replaced, the shim needs two things: it must provide the same API as the replaced library and it must know how to run in the firmware’s bare-metal environment.
The first is achieved by defining a Rust FFI interface with the same function signatures.
We try to keep the amount of unsafe Rust as minimal as possible by putting the actual implementation in a safe function and exposing a thin wrapper type around.
For example, the FreeRTOS coreJSON example includes a JSON_Validate C function with the following signature:
JSONStatus_t JSON_Validate( const char * buf, size_t max );
We can write a shim in Rust between it and the memory safe serde_json crate to expose the C function signature. We try to keep the unsafe code to a minimum and call through to a safe function early:
#[no_mangle]
pub unsafe extern "C" fn JSON_Validate(buf: *const c_char, len: usize) -> JSONStatus_t {
if buf.is_null() {
JSONStatus::JSONNullParameter as _
} else if len == 0 {
JSONStatus::JSONBadParameter as _
} else {
json_validate(slice_from_raw_parts(buf as _, len).as_ref().unwrap()) as _
// No more unsafe code in here.
fn json_validate(buf: &[u8]) -> JSONStatus {
if serde_json::from_slice::<Value>(buf).is_ok() {
JSONStatus::JSONSuccess
ILLEGAL_DOC
Note: This is a very simple example. For a highly resource constrained target, you can avoid alloc and use serde_json_core, which has even lower overhead but requires pre-defining the JSON structure so it can be allocated on the stack.
For further details on how to create an FFI interface, the Rustinomicon covers this topic extensively.
In order for any Rust component to be functional within a C-based firmware, it will need to call back into the C code for things such as allocations or logging. Thankfully, there are a variety of tools available which automatically generate Rust FFI bindings to C. That way, C functions can easily be invoked from Rust.
The standard means of doing this is with the Bindgen tool. You can use Bindgen to parse all relevant C headers that define the functions Rust needs to call into. It's important to invoke Bindgen with the same CFLAGS as the code in question is built with, to ensure that the bindings are generated correctly.
Experimental support for producing bindings to static inline functions is also available.
Next we need to hook up Rust panic handlers, global allocators, and critical section handlers to the existing code base. This requires producing definitions for each of these which call into the existing firmware C functions.
The Rust panic handler must be defined to handle unexpected states or failed assertions. A custom panic handler can be defined via the panic_handler attribute. This is specific to the target and should, in most cases, either point to an abort function for the current task/process, or a panic function provided by the environment.
If an allocator is available in the firmware and the crate relies on the alloc crate, the Rust allocator can be hooked up by defining a global allocator implementing GlobalAlloc.
If the crate in question relies on concurrency, critical sections will need to be handled. Rust's core or alloc crates do not directly provide a means for defining this, however the critical_section crate is commonly used to handle this functionality for a number of architectures, and can be extended to support more.
It can be useful to hook up functions for logging as well. Simple wrappers around the firmware’s existing logging functions can expose these to Rust and be used in place of print or eprint and the like. A convenient option is to implement the Log trait.
Rusts alloc crate normally assumes that allocations are infallible (that is, memory allocations won’t fail). However due to memory constraints this isn’t true in most bare-metal environments. Under normal circumstances Rust panics and/or aborts when an allocation fails; this may be acceptable behavior for some bare-metal environments, in which case there are no further considerations when using alloc.
If there’s a clear justification or requirement for fallible allocations however, additional effort is required to ensure that either allocations can’t fail or that failures are handled.
One approach is to use a crate that provides statically allocated fallible collections, such as the heapless crate, or dynamic fallible allocations like fallible_vec. Another is to exclusively use try_* methods such as Vec::try_reserve, which check if the allocation is possible.
Rust is in the process of formalizing better support for fallible allocations, with an experimental allocator in nightly allowing failed allocations to be handled by the implementation. There is also the unstable cfg flag for alloc called no_global_oom_handling which removes the infallible methods, ensuring they are not used.
Building the Rust library with LTO is necessary to optimize for code size. The existing C/C++ code base does not need to be built with LTO when passing -C lto=true to rustc. Additionally, setting -C codegen-unit=1 results in further optimizations in addition to reproducibility.
If using Cargo to build, the following Cargo.toml settings are recommended to reduce the output library size:
[profile.release]
panic = "abort"
lto = true
codegen-units = 1
strip = "symbols"
# opt-level "z" may produce better results in some circumstances
opt-level = "s"
Passing the -Z remap-cwd-prefix=. flag to rustc or to Cargo via the RUSTFLAGS env var when building with Cargo to strip cwd path strings.
In terms of performance, Rust demonstrates similar performance to C. The most relevant example may be the Rust binder Linux kernel driver, which found “that Rust binder has similar performance to C binder”.
When linking LTO’d Rust staticlibs together with C/C++, it’s recommended to ensure a single Rust staticlib ends up in the final linkage, otherwise there may be duplicate symbol errors when linking. This may mean combining multiple Rust shims into a single static library by re-exporting them from a wrapper module.
Using the process outlined in this blog post, You can begin to introduce Rust into large legacy firmware code bases immediately. Replacing security critical components with off-the-shelf open-source memory-safe implementations and developing new features in a memory safe language will lead to fewer critical vulnerabilities while also providing an improved developer experience.
Special thanks to our colleagues who have supported and contributed to these efforts: Roger Piqueras Jover, Stephan Chen, Gil Cukierman, Andrew Walbran, and Erik Gilling