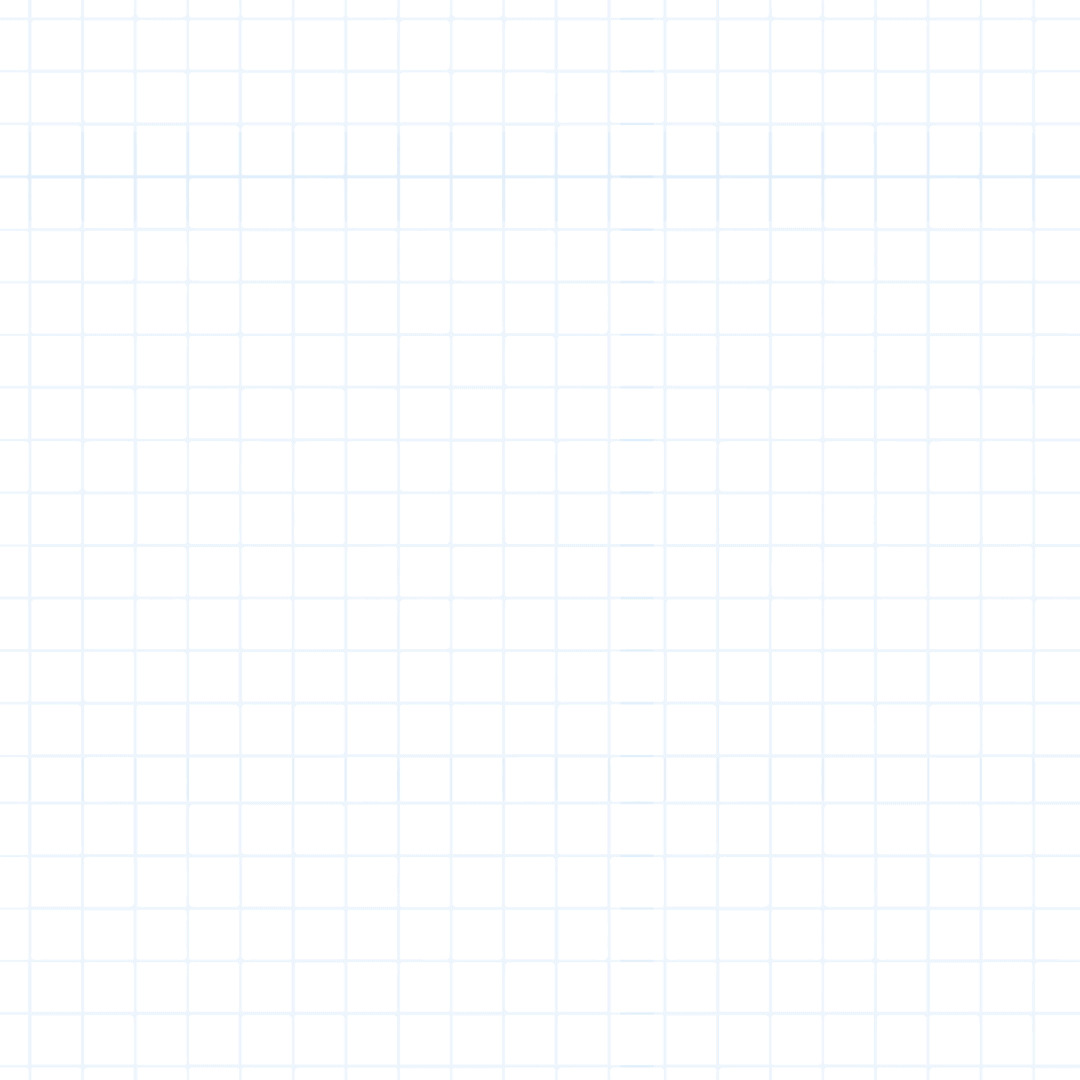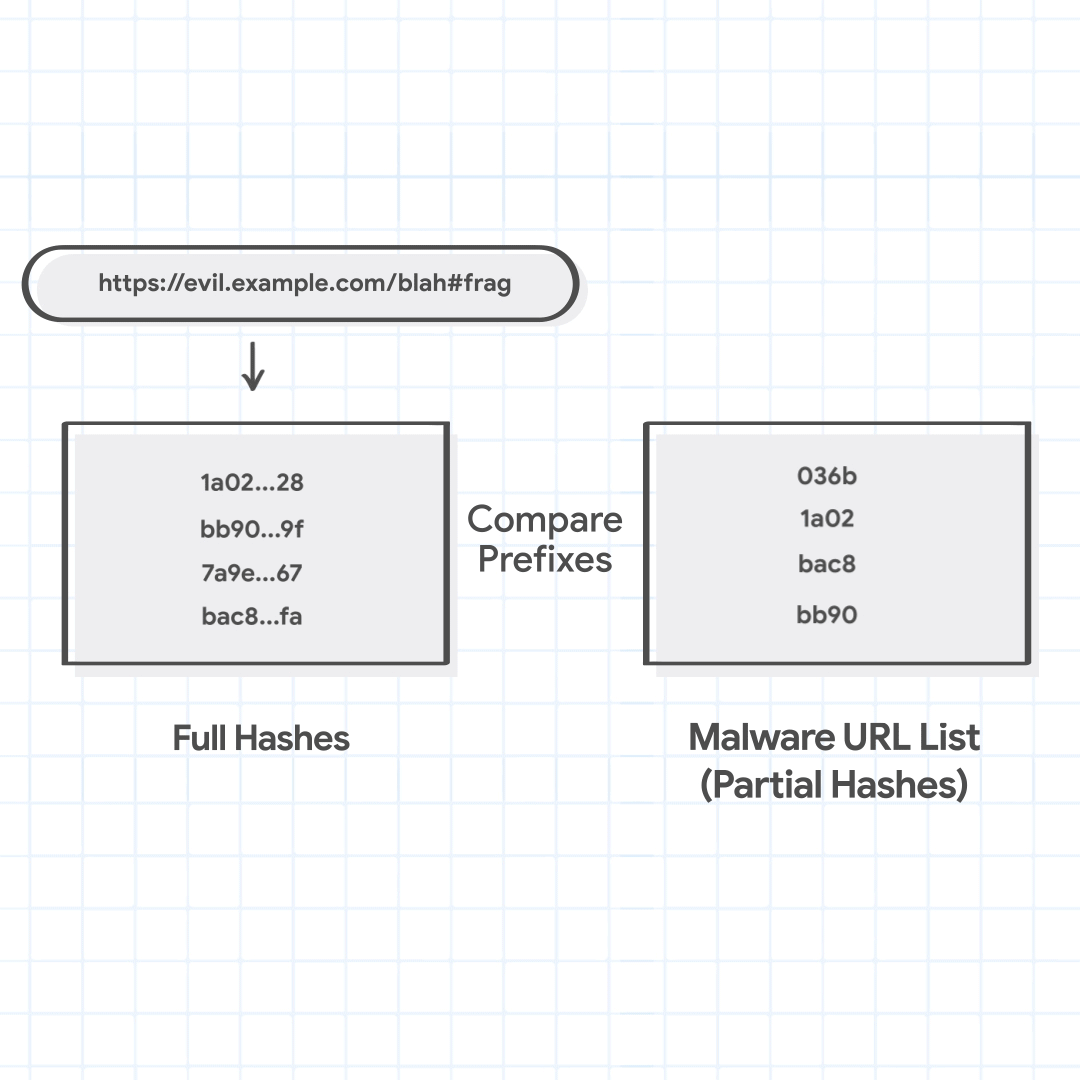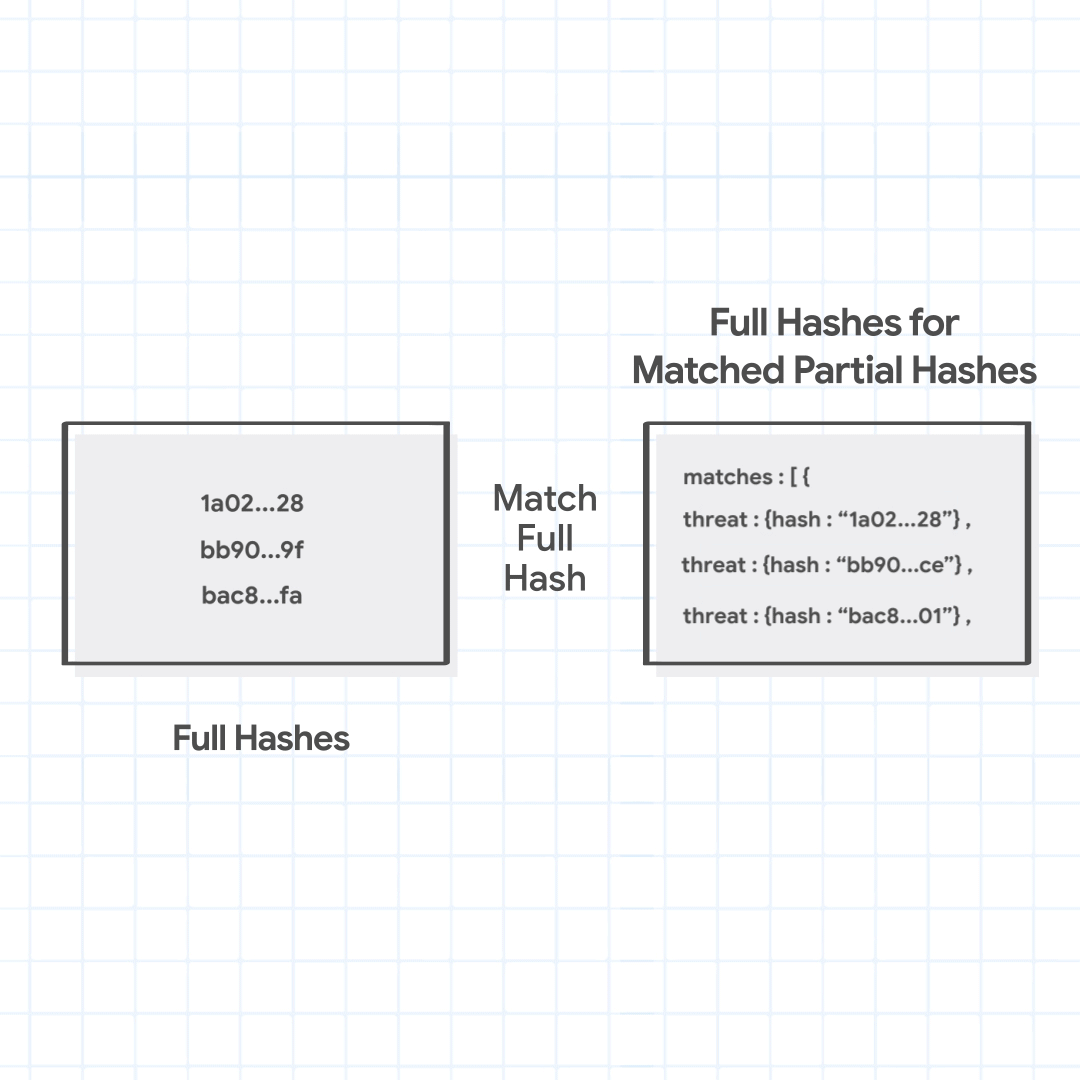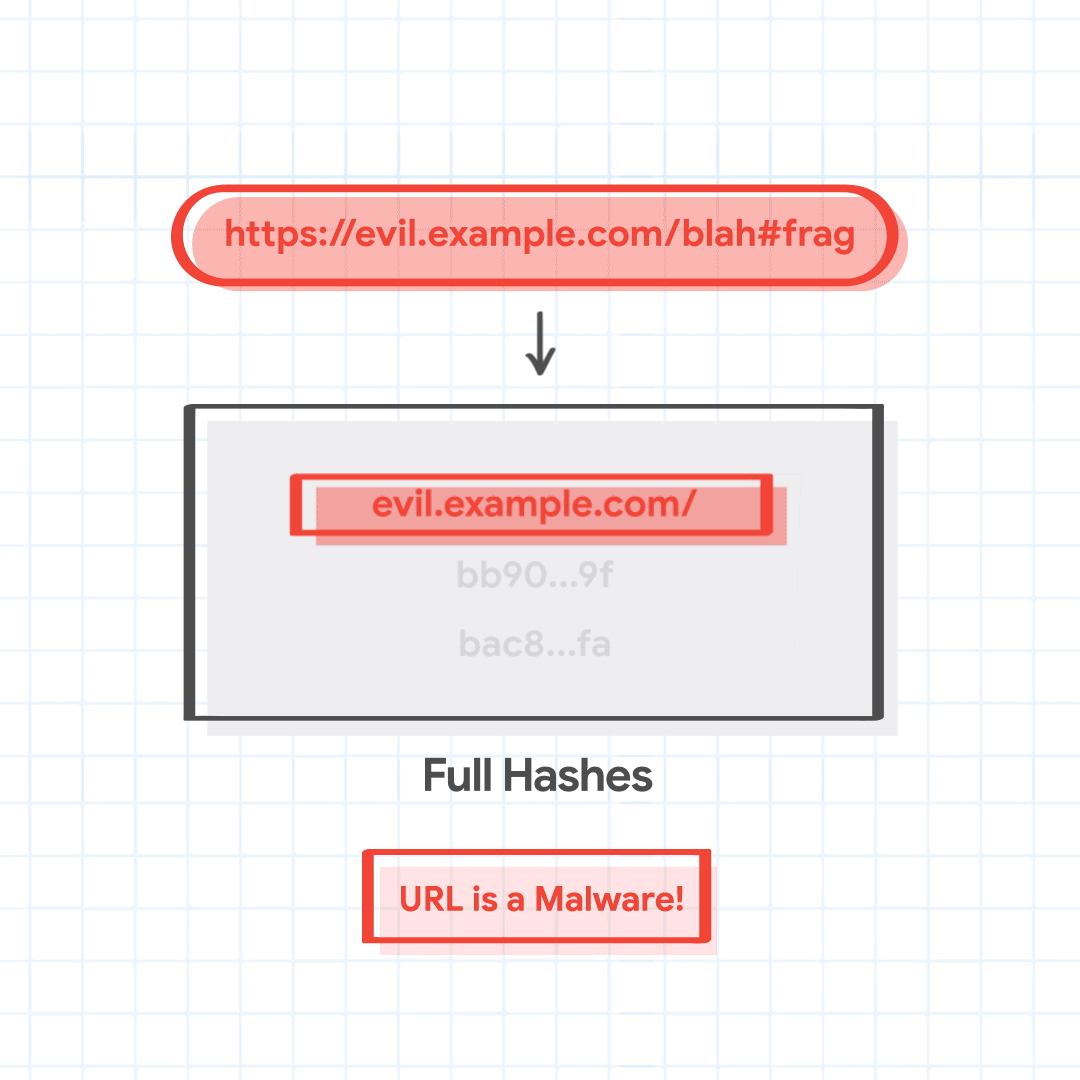Cybercriminals using cookie theft infostealer malware continue to pose a risk to the safety and security of our users. We already have a number of initiatives in this area including Chrome’s download protection using Safe Browsing, Device Bound Session Credentials, and Google’s account-based threat detection to flag the use of stolen cookies. Today, we’re announcing another layer of protection to make Windows users safer from this type of malware.
Like other software that needs to store secrets, Chrome currently secures sensitive data like cookies and passwords using the strongest techniques the OS makes available to us - on macOS this is the Keychain services, and on Linux we use a system provided wallet such as kwallet or gnome-libsecret. On Windows, Chrome uses the Data Protection API (DPAPI) which protects the data at rest from other users on the system or cold boot attacks. However, the DPAPI does not protect against malicious applications able to execute code as the logged in user - which infostealers take advantage of.
In Chrome 127 we are introducing a new protection on Windows that improves on the DPAPI by providing Application-Bound (App-Bound) Encryption primitives. Rather than allowing any app running as the logged in user to access this data, Chrome can now encrypt data tied to app identity, similar to how the Keychain operates on macOS.
We will be migrating each type of secret to this new system starting with cookies in Chrome 127. In future releases we intend to expand this protection to passwords, payment data, and other persistent authentication tokens, further protecting users from infostealer malware.
How it works
App-Bound Encryption relies on a privileged service to verify the identity of the requesting application. During encryption, the App-Bound Encryption service encodes the app's identity into the encrypted data, and then verifies this is valid when decryption is attempted. If another app on the system tries to decrypt the same data, it will fail.
Because the App-Bound service is running with system privileges, attackers need to do more than just coax a user into running a malicious app. Now, the malware has to gain system privileges, or inject code into Chrome, something that legitimate software shouldn't be doing. This makes their actions more suspicious to antivirus software – and more likely to be detected. Our other recent initiatives such as providing event logs for cookie decryption work in tandem with this protection, with the goal of further increasing the cost and risk of detection to attackers attempting to steal user data.
Enterprise Considerations
Since malware can bypass this protection by running elevated, enterprise environments that do not grant their users the ability to run downloaded files as Administrator are particularly helped by this protection - malware cannot simply request elevation privilege in these environments and is forced to use techniques such as injection that can be more easily detected by endpoint agents.
App-Bound Encryption strongly binds the encryption key to the machine, so will not function correctly in environments where Chrome profiles roam between multiple machines. We encourage enterprises who wish to support roaming profiles to follow current best practices. If it becomes necessary, App-Bound encryption can be configured using the new ApplicationBoundEncryptionEnabled policy.
To further help detect any incompatibilities, Chrome emits an event when a failed verification occurs. The Event is ID 257 from 'Chrome' source in the Application log.
Conclusion
App-Bound Encryption increases the cost of data theft to attackers and also makes their actions far noisier on the system. It helps defenders draw a clear line in the sand for what is acceptable behavior for other apps on the system. As the malware landscape continually evolves we are keen to continue engaging with others in the security community on improving detections and strengthening operating system protections, such as stronger app isolation primitives, for any bypasses.
Chrome 106 added support for enforcing key pins on Android by default, bringing Android to parity with Chrome on desktop platforms. But what is key pinning anyway?
One of the reasons Chrome implements key pinning is the “rule of two”. This rule is part of Chrome’s holistic secure development process. It says that when you are writing code for Chrome, you can pick no more than two of: code written in an unsafe language, processing untrustworthy inputs, and running without a sandbox. This blog post explains how key pinning and the rule of two are related.
The Rule of Two
Chrome is primarily written in the C and C++ languages, which are vulnerable to memory safety bugs. Mistakes with pointers in these languages can lead to memory being misinterpreted. Chrome invests in an ever-stronger multi-process architecture built on sandboxing and site isolation to help defend against memory safety problems. Android-specific features can be written in Java or Kotlin. These languages are memory-safe in the common case. Similarly, we’re working on adding support to write Chrome code in Rust, which is also memory-safe.
Much of Chrome is sandboxed, but the sandbox still requires a core high-privilege “broker” process to coordinate communication and launch sandboxed processes. In Chrome, the broker is the browser process. The browser process is the source of truth that allows the rest of Chrome to be sandboxed and coordinates communication between the rest of the processes.
If an attacker is able to craft a malicious input to the browser process that exploits a bug and allows the attacker to achieve remote code execution (RCE) in the browser process, that would effectively give the attacker full control of the victim’s Chrome browser and potentially the rest of the device. Conversely, if an attacker achieves RCE in a sandboxed process, such as a renderer, the attacker's capabilities are extremely limited. The attacker cannot reach outside of the sandbox unless they can additionally exploit the sandbox itself.
Without sandboxing, which limits the actions an attacker can take, and without memory safety, which removes the ability of a bug to disrupt the intended control flow of the program, the rule of two requires that the browser process does not handle untrustworthy inputs. The relative risks between sandboxed processes and the browser process are why the browser process is only allowed to parse trustworthy inputs and specific IPC messages.
Trustworthy inputs are defined extremely strictly: A “trustworthy source” means that Chrome can prove that the data comes from Google. Effectively, this means that in situations where the browser process needs access to data from external sources, it must be read from Google servers. We can cryptographically prove that data came from Google servers if that data comes from:
The component updater and the variations framework are services specific to Chrome used to ship data-only updates and configuration information. These services both use asymmetric cryptography to authenticate their data, and the public key used to verify data sent by these services is shipped in Chrome.
However, Chrome is a feature-filled browser with many different use cases, and many different features beyond just updating itself. Certain features, such as Sign-In and the Discover Feed, need to communicate with Google. For features like this, that communication can be considered trustworthy if it comes from a pinned HTTPS server.
When Chrome connects to an HTTPS server, the server says “a 3rd party you trust (a certification authority; CA) has vouched for my identity.” It does this by presenting a certificate issued by a trusted certification authority. Chrome verifies the certificate before continuing. The modern web necessarily has a lot of CAs, all of whom can provide authentication for any website. To further ensure that the Chrome browser process is communicating with a trustworthy Google server we want to verify something more: whether a specific CA is vouching for the server. We do this by building a map of sites → expected CAs directly into Chrome. We call this key pinning. We call the map the pin set.
What is Key Pinning?
Key pinning was born as a defense against real attacks seen in the wild: attackers who can trick a CA to issue a seemingly-valid certificate for a server, and then the attacker can impersonate that server. This happened to Google in 2011, when the DigiNotar certification authority was compromised and used to issue malicious certificates for Google services. To defend against this risk, Chrome contains a pin set for all Google properties, and we only consider an HTTPS input trustworthy if it’s authenticated using a key in this pin set. This protects against malicious certificate issuance by third parties.
Key pinning can be brittle, and is rarely worth the risks. Allowing the pin set to get out of date can lead to locking users out of a website or other services, potentially permanently. Whenever pinning, it’s important to have safety-valves such as not enforcing pinning (i.e. failing open) when the pins haven't been updated recently, including a “backup” key pin, and having fallback mechanisms for bootstrapping. It's hard for individual sites to manage all of these mechanisms, which is why dynamic pinning over HTTPS (HPKP) was deprecated. Key pinning is still an important tool for some use cases, however, where there's high-privilege communication that needs to happen between a client and server that are operated by the same entity, such as web browsers, automatic software updates, and package managers.
Security Benefits of Key Pinning in Chrome, Now on Android
By pinning in Chrome, we can protect users from CA compromise. We take steps to prevent an out-of-date pinset from unnecessarily blocking users from accessing Google or Google's services. As both a browser vendor and site operator, however, we have additional tools to ensure we keep our pin sets up to date—if we use a new key or a new domain, we can add it to the pin set in Chrome at the same time. In our original implementation of pinning, the pin set is directly compiled into Chrome and updating the pin set requires updating the entire Chrome binary. To make sure that users of old versions of Chrome can still talk to Google, pinning isn't enforced if Chrome detects that it is more than 10 weeks old.
Historically, Chrome enforced the age limit by comparing the current time to the build timestamp in the Chrome binary. Chrome did not enforce pinning on Android because the build timestamp on Android wasn’t always reflective of the age of the Chrome pinset, which meant that the chance of a false positive pin mismatch was higher.
Without enforcing pins on Android, Chrome was limiting the ways engineers could build features that comply with the rule of two. To remove this limitation, we built an improved mechanism for distributing the built-in pin set to Chrome installs, including Android devices. Chrome still contains a built-in pin set compiled into the binary. However, we now additionally distribute the pin set via the component updater, which is a mechanism for Chrome to dynamically push out data-only updates to all Chrome installs without requiring a full Chrome update or restart. The component contains the latest version of the built-in pin set, as well as the certificate transparency log list and the contents of the Chrome Root Store. This means that even if Chrome is out of date, it can still receive updates to the pin set. The component also includes the timestamp the pin list was last updated, rather than relying on build timestamp. This drastically reduces the false positive risk of enabling key pinning on Android.
After we moved the pin set to component updater, we were able to do a slow rollout of pinning enforcement on Android. We determined that the false positive risk was now in line with desktop platforms, and enabled key pinning enforcement by default since Chrome 106, released in September 2022.
This change has been entirely invisible to users of Chrome. While not all of the changes we make in Chrome are flashy, we're constantly working behind the scenes to keep Chrome as secure as possible and we're excited to bring this protection to Android.
To get security fixes to you faster, starting now in Chrome 116, Chrome is shipping weekly Stable channel updates.
Chrome ships a new milestone release every four weeks. In between those major releases, we ship updates to address security and other high impact bugs. We currently schedule one of these Stable channel updates (or “Stable Refresh”) between each milestone. Starting in Chrome 116, Stable updates will be released every week between milestones.
This should not change how you use or update Chrome, nor is the frequency of milestone releases changing, but it does mean security fixes will get to you faster.
Chromium is the open source project which powers Chrome and many other browsers. Anyone can view the source code, submit changes for review, and see the changes made by anyone else, even security bug fixes. Users of our Canary (and Beta) channels receive those fixes and can sometimes give us early warning of unexpected stability, compatibility, or performance problems in advance of the fix reaching the Stable channel.
This openness has benefits in testing fixes and discovering bugs, but comes at a cost: bad actors could possibly take advantage of the visibility into these fixes and develop exploits to apply against browser users who haven’t yet received the fix. This exploitation of a known and patched security issue is referred to as n-day exploitation.
That’s why we believe it’s really important to ship security fixes as soon as possible, to minimize this “patch gap”.
When a Chrome security bug is fixed, the fix is landed in the public Chromium source code repository. The fix is then publicly accessible and discoverable. After the patch is landed, individuals across Chrome are working to test and verify the patch, and evaluate security bug fixes for backporting to affected release branches. Security fixes impacting Stable channel then await the next Stable channel update once they have been backported. The time between the patch being landed and shipped in a Stable channel update is the patch gap.
Chrome began releasing Stable channel updates every two weeks in 2020, with Chrome 77, as a way to help reduce the patch gap. Before Chrome 77, our patch gap averaged 35 days. Since moving the biweekly release cadence, the patch gap has been reduced to around 15 days. The switch to weekly updates allows us to ship security fixes even faster, and further reduce the patch gap.
While we can’t fully remove the potential for n-day exploitation, a weekly Chrome security update cadence allows up to ship security fixes 3.5 days sooner on average, greatly reducing the already small window for n-day attackers to develop and use an exploit against potential victims and making their lives much more difficult.
Not all security bug fixes are used for n-day exploitation. But we don’t know which bugs are exploited in practice, and which aren't, so we treat all critical and high severity bugs as if they will be exploited. A lot of work goes into making sure these bugs get triaged and fixed as soon as possible. Rather than having fixes sitting and waiting to be included in the next bi-weekly update, weekly updates will allow us to get important security bug fixes to you sooner, and better protect you and your most sensitive data.
As always, we treat any Chrome bug with a known in-the-wild exploit as a security incident of the highest priority and set about fixing the bug and getting a fix out to users as soon as possible. This has meant shipping the fix in an unscheduled update, so that you are protected immediately. By now shipping stable updates weekly, we expect the number of unplanned updates to decrease since we’ll be shipping updates more frequently.
Keep a lookout for notifications from your desktop or mobile device letting you know an update of Chrome is available. If an update is available, please update immediately each time!
If you are concerned that updating Chrome will interrupt your work or result in lost tabs, not to worry – when relaunching Chrome to update, your open tabs and windows are saved and Chrome re-opens them after restart. If you are browsing in Incognito mode, your tabs will not be saved. You can simply choose to delay restarting by selecting Not now, and the updates will be applied the next time you restart Chrome.
We are exploring improved ways of informing you a new Chrome update is available. Keep a lookout for these new notifications which have been rolled out for Stable experimentation to 1% of users.
Other Chromium-based browsers have varying patch gaps. Chrome does not control the update cadence of other Chromium browsers. The change described here is only applicable to Chrome. If you are using other Chromium browsers, you may want to explore the security update cadence of those browsers.
The rest is on us – with this change we’re dedicated to continuing to work to get security fixes to you as fast as possible.
Browser extensions, while offering valuable functionalities, can seem risky to organizations. One major concern is the potential for security vulnerabilities. Poorly designed or malicious extensions could compromise data integrity and expose sensitive information to unauthorized access. Moreover, certain extensions may introduce performance issues or conflicts with other software, leading to system instability. Therefore, many organizations find it crucial to have visibility into the usage of extensions and the ability to control them. Chrome browser offers these extension management capabilities and reporting via Chrome Browser Cloud Management. In this blog post, we will walk you through how to utilize these features to keep your data and users safe.
Visibility into Extensions being used in your environment
Having visibility into what and how extensions are being used enables IT and security teams to assess potential security implications, ensure compliance with organizational policies, and mitigate potential risks. There are three ways you can get critical information about extensions in your organization:
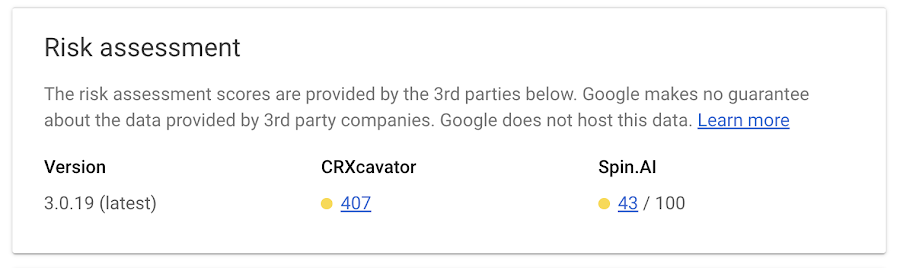
1. App and extension usage reportingOrganizations can gain visibility into every Chrome extension that is installed across an enterprise’s fleet in Chrome App and Extension Usage Reporting.2. Extension Risk AssessmentCRXcavator and Spin.AI Risk Assessment are tools used to assess the risks of browser extensions and minimize the risks associated with them. We are making extension scores via these two platforms available directly in Chrome Browser Cloud Management, so security teams can have an at-a-glance view of risk scores of the extensions being used in their browser environment.
Extension controls for added security
By having control over extensions, organizations can maintain a secure and stable browsing environment, safeguard sensitive data, and protect their overall digital infrastructure. There are several ways IT and security teams can set and enforce controls over extensions:
1. Extension permissionOrganizations can control whether users can install apps or extensions based on the information an extension can access—also known as permissions. For example, you might want to prevent users from installing any extension that wants permission to see a device location.
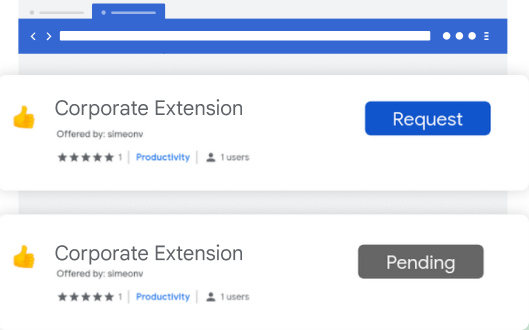
2. Extension workflowExtension workflow allows end users to request extensions for review. From there, IT can either approve or deny them. This is a great approach for teams that want to control the extensions in their environment, but allow end users to have some say over the extensions they use.
We recently added a prompt for business justification for documenting why users are requesting the extension. This gives admins more information as to why the extension may or may not be helpful for their workforce, and can help speed approvals for business users.
For 13 years, a key pillar of the Chrome Security ecosystem has included encouraging security researchers to find security vulnerabilities in Chrome browser and report them to us, through the Chrome Vulnerability Rewards Program.
Starting today and until 1 December 2023, the first security bug report we receive with a functional full chain exploit, resulting in a Chrome sandbox escape, is eligible for triple the full reward amount. Your full chain exploit could result in a reward up to $180,000 (potentially more with other bonuses).
Any subsequent full chains submitted during this time are eligible for double the full reward amount!
We have historically put a premium on reports with exploits – “high quality reports with a functional exploit” is the highest tier of reward amounts in our Vulnerability Rewards Program. Over the years, the threat model of Chrome browser has evolved as features have matured and new features and new mitigations, such a MiraclePtr, have been introduced. Given these evolutions, we’re always interested in explorations of new and novel approaches to fully exploit Chrome browser and we want to provide opportunities to better incentivize this type of research. These exploits provide us valuable insight into the potential attack vectors for exploiting Chrome, and allow us to identify strategies for better hardening specific Chrome features and ideas for future broad-scale mitigation strategies.
The full details of this bonus opportunity are available on the Chrome VRP rules and rewards page. The summary is as follows:
As is consistent with our general rewards policy, if the exploit allows for remote code execution (RCE) in the browser or other highly-privileged process, such as network or GPU process, to result in a sandbox escape without the need of a first stage bug, the reward amount for renderer RCE “high quality report with functional exploit” would be granted and included in the calculation of the bonus reward total.
Based on our current Chrome VRP reward matrix, your full chain exploit could result in a total reward of over $165,000 -$180,000 for the first full chain exploit and over $110,000 - $120,000 for subsequent full chain exploits we receive in the six month window of this reward opportunity.
We’d like to thank our entire Chrome researcher community for your past and ongoing efforts and security bug submissions! You’ve truly helped us make Chrome more secure for all users.
Happy Hunting!
Introduction
Chrome is trusted by millions of business users as a secure enterprise browser. Organizations can use Chrome Browser Cloud Management to help manage Chrome browsers more effectively. As an admin, they can use the Google Admin console to get Chrome to report critical security events to third-party service providers such as Splunk® to create custom enterprise security remediation workflows.
Security remediation is the process of responding to security events that have been triggered by a system or a user. Remediation can be done manually or automatically, and it is an important part of an enterprise security program.
Why is Automated Security Remediation Important?
When a security event is identified, it is imperative to respond as soon as possible to prevent data exfiltration and to prevent the attacker from gaining a foothold in the enterprise. Organizations with mature security processes utilize automated remediation to improve the security posture by reducing the time it takes to respond to security events. This allows the usually over burdened Security Operations Center (SOC) teams to avoid alert fatigue.
Automated Security Remediation using Chrome Browser Cloud Management and Splunk
Chrome integrates with Chrome Enterprise Recommended partners such as Splunk® using Chrome Enterprise Connectors to report security events such as malware transfer, unsafe site visits, password reuse. Other supported events can be found on our support page.
The Splunk integration with Chrome browser allows organizations to collect, analyze, and extract insights from security events. The extended security insights into managed browsers will enable SOC teams to perform better informed automated security remediations using Splunk® Alert Actions.
Splunk Alert Actions are a great capability for automating security remediation tasks. By creating alert actions, enterprises can automate the process of identifying, prioritizing, and remediating security threats.
In Splunk®, SOC teams can use alerts to monitor for and respond to specific Chrome Browser Cloud Management events. Alerts use a saved search to look for events in real time or on a schedule and can trigger an Alert Action when search results meet specific conditions as outlined in the diagram below.
Use Case
If a user downloads a malicious file after bypassing a Chrome “Dangerous File” message their managed browser/managed CrOS device should be quarantined.
Prerequisites
Setup
Please follow installation instructions here depending on your Splunk Installation to install the Google Chrome Add-on for Splunk App.
Please follow the guide here to set up Chrome Browser Cloud Management and Splunk® integration.
To call the Chrome Browser Cloud Management API, use a service account properly configured in the Google admin console. Create a (or use an existing) service account and download the JSON representation of the key.
Create a (or use an existing) role in the admin console with all the “Chrome Management” privileges as shown below.
Assign the created role to the service account using the “Assign service accounts” button.
Install the App i.e. Alert Action from our Github page. You will notice that the Splunk App uses the below directory structure. Please take some time to understand the directory structure layout.
Create a “Quarantine” OU to move managed browsers into. Apply restrictive policies to this OU which will then be applied to managed browsers and managed CrOS devices that are moved to this OU. In our case we set the below policies for our “Quarantine” OU called Investigate.These policies ensure that the quarantined CrOS device/browser can only open a limited set of approved URLS.
Investigate.
URL Blocklist - Block access to all URLs
URL Allowlist - Allow only approved URLs for e.g. IT Helpdesk website
New Tab Page Location - Set New tab page URL to an internal website asking the user to contact IT Helpdesk.
Home Page is New Tab Page - Use the
Configuration
As seen in the screenshot we have configured the Chrome Browser Cloud Management Remediation Alert Action App with
/Investigate
Test the setup
Use the testsafebrowsing website to generate sample security events to test the setup.
Desktop Download Warnings
Dangerous Download blocked
Discard
Keep
Security remediation is vital to any organization’s security program. In this blog we discussed configuring automated security remediation of Chrome Browser Cloud Management security events using Splunk alert actions. This scalable approach can be used to protect a company from online security threats by detecting and quickly responding to high fidelity Chrome Browser Cloud Management security events thereby greatly reducing the time to respond.
Our team will be at the Gartner Security and Risk Management Summit in National Harbor, MD, next week. Come see us in action if you’re attending the summit.
Starting in Chrome 111 we will begin to turn down the Chrome Cleanup Tool, an application distributed to Chrome users on Windows to help find and remove unwanted software (UwS).
The Chrome Cleanup Tool was introduced in 2015 to help users recover from unexpected settings changes, and to detect and remove unwanted software. To date, it has performed more than 80 million cleanups, helping to pave the way for a cleaner, safer web.
In recent years, several factors have led us to reevaluate the need for this application to keep Chrome users on Windows safe.
First, the user perspective – Chrome user complaints about UwS have continued to fall over the years, averaging out to around 3% of total complaints in the past year. Commensurate with this, we have observed a steady decline in UwS findings on users' machines. For example, last month just 0.06% of Chrome Cleanup Tool scans run by users detected known UwS.
Next, several positive changes in the platform ecosystem have contributed to a more proactive safety stance than a reactive one. For example, Google Safe Browsing as well as antivirus software both block file-based UwS more effectively now, which was originally the goal of the Chrome Cleanup Tool. Where file-based UwS migrated over to extensions, our substantial investments in the Chrome Web Store review process have helped catch malicious extensions that violate the Chrome Web Store's policies.
Finally, we've observed changing trends in the malware space with techniques such as Cookie Theft on the rise – as such, we've doubled down on defenses against such malware via a variety of improvements including hardened authentication workflows and advanced heuristics for blocking phishing and social engineering emails, malware landing pages, and downloads.
Starting in Chrome 111, users will no longer be able to request a Chrome Cleanup Tool scan through Safety Check or leverage the "Reset settings and cleanup" option offered in chrome://settings on Windows. Chrome will also remove the component that periodically scans Windows machines and prompts users for cleanup should it find anything suspicious.
Even without the Chrome Cleanup Tool, users are automatically protected by Safe Browsing in Chrome. Users also have the option to turn on Enhanced protection by navigating to chrome://settings/security – this mode substantially increases protection from dangerous websites and downloads by sharing real-time data with Safe Browsing.
While we'll miss the Chrome Cleanup Tool, we wanted to take this opportunity to acknowledge its role in combating UwS for the past 8 years. We'll continue to monitor user feedback and trends in the malware ecosystem, and when adversaries adapt their techniques again – which they will – we'll be at the ready.
As always, please feel free to send us feedback or find us on Twitter @googlechrome.
Note: This post is a follow-up to discussions carried out on the Mozilla “Dev Security Policy” Web PKI public discussion forum Google Group in December 2022. Google Chrome communicated its distrust of TrustCor in the public forum on December 15, 2022.
The Chrome Security Team prioritizes the security and privacy of Chrome’s users, and we are unwilling to compromise on these values.
Google includes or removes CA certificates within the Chrome Root Store as it deems appropriate for user safety in accordance with our policies. The selection and ongoing inclusion of CA certificates is done to enhance the security of Chrome and promote interoperability.
Behavior that attempts to degrade or subvert security and privacy on the web is incompatible with organizations whose CA certificates are included in the Chrome Root Store. Due to a loss of confidence in its ability to uphold these fundamental principles and to protect and safeguard Chrome’s users, certificates issued by TrustCor Systems will no longer be recognized as trusted by:
This change was first communicated in the Mozilla “Dev Security Policy” Web PKI public discussion forum Google Group on December 15, 2022.
This change will be implemented via our existing mechanisms to respond to CA incidents via:
Beginning approximately March 7, 2023, navigations to websites that use a certificate that chains to one of the roots detailed below will be considered insecure and result in a full page certificate error interstitial.
Affected Certificates (SHA-256 fingerprint):
This change will be integrated into the Chromium open-source project as part of a default build. Questions about the expected behavior in specific Chromium-based browsers should be directed to their maintainers.
This change will be incorporated as part of the regular Chrome release process to ensure sufficient time for testing and replacing affected certificates by website operators. Information about release timetables and milestones is available at https://chromiumdash.appspot.com/schedule.
Beginning approximately February 9, 2023, website operators can preview these changes in Chrome 111 Beta. Website operators will also be able to preview the change sooner, using our Dev and Canary channels. The majority of users will not encounter behavior changes until the release of Chrome 111 to the Stable channel, approximately March 7, 2023.
Summarizing security response of other Google products:
We are pleased to announce that moving forward, the Chromium project is going to support the use of third-party Rust libraries from C++ in Chromium. To do so, we are now actively pursuing adding a production Rust toolchain to our build system. This will enable us to include Rust code in the Chrome binary within the next year. We’re starting slow and setting clear expectations on what libraries we will consider once we’re ready.
In this blog post, we will discuss how we arrived at the decision to support third-party Rust libraries at this time, and not broader usage of Rust in Chromium.
Why We Chose to Bring Rust into Chromium
Our goal in bringing Rust into Chromium is to provide a simpler (no IPC) and safer (less complex C++ overall, no memory safety bugs in a sandbox either) way to satisfy the rule of two, in order to speed up development (less code to write, less design docs, less security review) and improve the security (increasing the number of lines of code without memory safety bugs, decreasing the bug density of code) of Chrome. And we believe that we can use third-party Rust libraries to work toward this goal.
Rust was developed by Mozilla specifically for use in writing a browser, so it’s very fitting that Chromium would finally begin to rely on this technology too. Thank you Mozilla for your huge contribution to the systems software industry. Rust has been an incredible proof that we should be able to expect a language to provide safety while also being performant.
We know that C++ and Rust can play together nicely, through tools like cxx, autocxx bindgen, cbindgen, diplomat, and (experimental) crubit. However there are also limitations. We can expect that the shape of these limitations will change in time through new or improved tools, but the decisions and descriptions here are based on the current state of technology.
How Chromium Will Support the Use of Rust
The Chrome Security team has been investing time into researching how we should approach using Rust alongside our C++ code. Understanding the implications of incrementally moving to writing Rust instead of C++, even in the middle of our software stack. What the limits of safe, simple, and reliable interop might be.
Based on our research, we landed on two outcomes for Chromium.
The Interop Between Rust and C++ in Chromium
We have observed that most successful C/C++ and Rust interop stories to date have been built around interop through narrow APIs (e.g. libraries for QUIC or bluetooth, Linux drivers) or through clearly isolated components (e.g. IDLs, IPCs). Chrome is built on foundational but really wide C++ APIs, such as the //content/public layer. We examined what it would mean for us to build Rust components against these types of APIs. At a high level what we found was that because C++ and Rust play by different rules, things can go sideways very easily.
For example, Rust guarantees temporal memory safety with static analysis that relies on two inputs: lifetimes (inferred or explicitly written) and exclusive mutability. The latter is incompatible with how the majority of Chromium’s C++ is written. We hold redundant mutable pointers throughout the system, and pointers that provide multiple paths to reach mutable pointers. We have cyclical mutable data structures. This is especially true in our browser process, which contains a giant interconnected system of (mutable) pointers. If these C++ pointers were also used as Rust references in a complex or long-lived way, it would require our C++ authors to understand the aliasing rules of Rust and prevent the possibility of violating them, such as by:
Without interop tools providing support via the compiler and the type system, developers would need to understand all of the assumptions being made by Rust compiler, in order to not violate them from C++. In this framing, C++ is much like unsafe Rust. And while unsafe Rust is very costly to a project, its cost is managed by keeping it encapsulated and to the minimum possible. In the same way, the full complexity of C++ would need to be encapsulated from safe Rust. Narrow APIs designed for interop can provide similar encapsulation, and we hope that interop tools can provide encapsulation in other ways that allow wider APIs between the languages.
The high-level summary is that without additional interop tooling support:
Any cross-language interop between arbitrary code introduces difficulties where concepts in one language are not found in the other. For Rust calling into C++, support for language features like templates or inheritance can be difficult for a binding generator to support. For C++ calling into Rust, proc macros, and traits are examples that provide similar challenges. At times, the impedance mismatch represents intentional design choices made for either language, however they also imply limits on FFI (interop) between the languages. We rely on interop tools to model the ideas of each language in a way that makes sense to the other, or to disallow them.
Accessing the Rust Ecosystem from Chromium
These challenges present an opportunity, both to make interop easier and more seamless, but also to get access to a wider range of libraries from either language. Google is investing in Crubit, an experiment in how to increase the fidelity of interop between C++ and Rust and express or encapsulate the requirements of each language to the other.
The Rust ecosystem is incredibly important, especially to a security-focused open source project like Chromium. The ecosystem is enormous (96k+ crates on crates.io) and growing, with investment from the systems development industry at large, including Google. Chrome relies heavily on third-party code, and we need to keep up with where that third-party investment is happening. It is critical that we build out support for including Rust into the Chromium project.
We will be following this strategy to establish norms, and to maintain a level of API review through the third-party process, while we look to the future of interop support pushing the boundaries of what is possible and reasonable to do between Rust and C++.
Some Other Related Content
Memory unsafety is an industry-wide problem, and making use of Rust is one part of a strategy to move the needle in this area. Recently, Android and Apple have each published a great blog post on the subject if you’re interested in learning more. With Chrome’s millions of lines of C++, we’re still working hard to improve the safety of our C++ too, through projects such as MiraclePtr.
As a follow-up to a previous blog post about How Hash-Based Safe Browsing Works in Google Chrome, we wanted to provide more details about Safe Browsing’s Enhanced Protection mode in Chrome. Specifically, how it came about, the protections that are offered and what it means for your data.
Security and privacy have always been top of mind for Chrome. Our goal is to make security effortless for you while browsing the web, so that you can go about your day without having to worry about the links that you click on or the files that you download. This is why Safe Browsing’s phishing and malware protections have been a core part of Chrome since 2007. You may have seen these in action if you have ever come across one of our red warning pages.
We show these warnings whenever we believe a site that you are trying to visit or file that you are trying to download might put you at risk for an attack. To give you a better understanding of how the Enhanced Protection mode in Safe Browsing provides the strongest level of defense it’s useful to know what is offered in Standard Protection.
Enabled by default in Chrome, Standard Protection was designed to be privacy preserving at its core by using hash-based checks. This has been effective at protecting users by warning millions of users about dangerous websites. However, hash-based checks are inherently limited as they rely on lookups to a list of known bad sites. We see malicious actors moving fast and constantly evolving their tactics to avoid detection using sophisticated techniques. To counter this, we created a stronger and more customized level of protection that we could offer to users. To this end, we launched Enhanced Protection in 2020, which builds upon the Standard Protection mode in Safe Browsing to keep you safer.
This is the fastest and strongest level of protection against dangerous sites and downloads that Safe Browsing offers in Chrome. It enables more advanced detection techniques that adapt quickly as malicious activity evolves. As a result, Enhanced Protection users are phished 20-35% less than users on Standard Protection. A few of these features include:
By opting into Enhanced Protection, you are sharing additional data with Safe Browsing systems that allow us to offer better and faster security both for you, and for all users online. Ensuring user privacy is of utmost importance for us and we go through great lengths to anonymize as much of the data as possible. This data is only used for security purposes and only retained for a short period of time. As threats evolve we will continuously add and improve our existing protections for Enhanced Protection users. These features go through extensive privacy reviews to ensure that your privacy continues to be prioritized while still providing you the highest level of security possible.
Safe Browsing’s Enhanced Protection is currently available for all desktop platforms, Android devices and now iOS mobile devices. It can be enabled by navigating to the Privacy and Security option located in Chrome settings.
For enterprise admins, you have the option of enabling Enhanced Safe Browsing on your managed devices using the SafeBrowsingProtectionLevel policy and in the Admin Console.
For more details and updates about Safe Browsing and its Enhanced Protection mode, please visit our Google Safe Browsing website and follow the Google Security Blog for updates on new features.
Memory safety bugs are the most numerous category of Chrome security issues and we’re continuing to investigate many solutions – both in C++ and in new programming languages. The most common type of memory safety bug is the “use-after-free”. We recently posted about an exciting series of technologies designed to prevent these. Those technologies (collectively, *Scan, pronounced “star scan”) are very powerful but likely require hardware support for sufficient performance.
Today we’re going to talk about a different approach to solving the same type of bugs.
It’s hard, if not impossible, to avoid use-after-frees in a non-trivial codebase. It’s rarely a mistake by a single programmer. Instead, one programmer makes reasonable assumptions about how a bit of code will work, then a later change invalidates those assumptions. Suddenly, the data isn’t valid as long as the original programmer expected, and an exploitable bug results.
These bugs have real consequences. For example, according to Google Threat Analysis Group, a use-after-free in the ChromeHTML engine was exploited this year by North Korea.
Half of the known exploitable bugs in Chrome are use-after-frees:
Diving Deeper: Not All Use-After-Free Bugs Are Equal
Chrome has a multi-process architecture, partly to ensure that web content is isolated into a sandboxed “renderer” process where little harm can occur. An attacker therefore usually needs to find and exploit two vulnerabilities - one to achieve code execution in the renderer process, and another bug to break out of the sandbox.
The first stage is often the easier one. The attacker has lots of influence in the renderer process. It’s easy to arrange memory in a specific way, and the renderer process acts upon many different kinds of web content, giving a large “attack surface” that could potentially be exploited.
The second stage, escaping the renderer sandbox, is trickier. Attackers have two options how to do this:
We imagine the attackers squeezing through the narrow part of a funnel:
Here’s a sample of 100 recent high severity Chrome security bugs that made it to the stable channel, divided by root cause and by the process they affect.
You might notice:
As you can see, the biggest category of bugs in each process is: V8 in the renderer process (JavaScript engine logic bugs - work in progress) and use-after-free bugs in the browser process. If we can make that “thin” bit thinner still by removing some of those use-after-free bugs, we make the whole job of Chrome exploitation markedly harder.
MiraclePtr: Preventing Exploitation of Use-After-Free Bugs
This is where MiraclePtr comes in. It is a technology to prevent exploitation of use-after-free bugs. Unlike aforementioned *Scan technologies that offer a non-invasive approach to this problem, MiraclePtr relies on rewriting the codebase to use a new smart pointer type, raw_ptr<T>. There are multiple ways to implement MiraclePtr. We came up with ~10 algorithms and compared the pros and cons. After analyzing their performance overhead, memory overhead, security protection guarantees, developer ergonomics, etc., we concluded that BackupRefPtr was the most promising solution.
class A { ... }; class B { B(A* a) : a_(a) {} void doSomething() { a_->doSomething(); } raw_ptr<A> a_; // MiraclePtr }; std::unique_ptr<A> a = std::make_unique<A>(); std::unique_ptr<B> b = std::make_unique<B>(a.get()); […] a = nullptr; // The free is delayed because the MiraclePtr is still pointing to the object. b->doSomething(); // Use-after-free is neutralized.
We successfully rewrote more than 15,000 raw pointers in the Chrome codebase into raw_ptr<T>, then enabled BackupRefPtr for the browser process on Windows and Android (both 64 bit and 32 bit) in Chrome 102 Stable. We anticipate that MiraclePtr meaningfully reduces the browser process attack surface of Chrome by protecting ~50% of use-after-free issues against exploitation. We are now working on enabling BackupRefPtr in the network, utility and GPU processes, and for other platforms. In the end state, our goal is to enable BackupRefPtr on all platforms because that ensures that a given pointer is protected for all users of Chrome.
Balancing Security and Performance
There is no free lunch, however. This security protection comes at a cost, which we have carefully weighed in our decision making.
Unsurprisingly, the main cost is memory. Luckily, related investments into PartitionAlloc over the past year led to 10-25% total memory savings, depending on usage patterns and platforms. So we were able to spend some of those savings on security: MiraclePtr increased the memory usage of the browser process 4.5-6.5% on Windows and 3.5-5% on Android1, still well below their previous levels. While we were worried about quarantined memory, in practice this is a tiny fraction (0.01%) of the browser process usage. By far the bigger culprit is the additional memory needed to store the reference count. One might think that adding 4 bytes to each allocation wouldn’t be a big deal. However, there are many small allocations in Chrome, so even the 4B overhead is not negligible. PartitionAlloc also uses pre-defined bucket sizes, so this extra 4B pushes certain allocations (particularly power-of-2 sized) into a larger bucket, e.g. 4096B->5120B.
We also considered the performance cost. Adding an atomic increment/decrement on common operations such as pointer assignment has unavoidable overhead. Having excluded a number of performance-critical pointers, we drove this overhead down until we could gain back the same margin through other performance optimizations. On Windows, no statistically significant performance regressions were observed on most of our top-level performance metrics like Largest Contentful Paint, First Input Delay, etc. The only adverse change there1 is an increase of the main thread contention (~7%). On Android1, in addition to a similar increase in the main thread contention (~6%), there were small regressions in First Input Delay (~1%), Input Delay (~3%) and First Contentful Paint (~0.5%). We don't anticipate these regressions to have a noticeable impact on user experience, and are confident that they are strongly outweighed by the additional safety for our users.
We should emphasize that MiraclePtr currently protects only class/struct pointer fields, to minimize the overhead. As future work, we are exploring options to expand the pointer coverage to on-stack pointers so that we can protect against more use-after-free bugs.
Note that the primary goal of MiraclePtr is to prevent exploitation of use-after-free bugs. Although it wasn’t designed for diagnosability, it already helped us find and fix a number of bugs that were previously undetected. We have ongoing efforts to make MiraclePtr crash reports even more informative and actionable.
Continue to Provide Us Feedback
Last but not least, we’d like to encourage security researchers to continue to report issues through the Chrome Vulnerability Reward Program, even if those issues are mitigated by MiraclePtr. We still need to make MiraclePtr available to all users, collect more data on its impact through reported issues, and further refine our processes and tooling. Until that is done, we will not consider MiraclePtr when determining the severity of a bug or the reward amount.
1 Measured in Chrome 99.
There are various threats a user faces when browsing the web. Users may be tricked into sharing sensitive information like their passwords with a misleading or fake website, also called phishing. They may also be led into installing malicious software on their machines, called malware, which can collect personal data and also hold it for ransom. Google Chrome, henceforth called Chrome, enables its users to protect themselves from such threats on the internet. When Chrome users browse the web with Safe Browsing protections, Chrome uses the Safe Browsing service from Google to identify and ward off various threats.
Safe Browsing works in different ways depending on the user's preferences. In the most common case, Chrome uses the privacy-conscious Update API (Application Programming Interface) from the Safe Browsing service. This API was developed with user privacy in mind and ensures Google gets as little information about the user's browsing history as possible. If the user has opted-in to "Enhanced Protection" (covered in an earlier post) or "Make Searches and Browsing Better", Chrome shares limited additional data with Safe Browsing only to further improve user protection.
This post describes how Chrome implements the Update API, with appropriate pointers to the technical implementation and details about the privacy-conscious aspects of the Update API. This should be useful for users to understand how Safe Browsing protects them, and for interested developers to browse through and understand the implementation. We will cover the APIs used for Enhanced Protection users in a future post.
When a user navigates to a webpage on the internet, their browser fetches objects hosted on the internet. These objects include the structure of the webpage (HTML), the styling (CSS), dynamic behavior in the browser (Javascript), images, downloads initiated by the navigation, and other webpages embedded in the main webpage. These objects, also called resources, have a web address which is called their URL (Uniform Resource Locator). Further, URLs may redirect to other URLs when being loaded. Each of these URLs can potentially host threats such as phishing websites, malware, unwanted downloads, malicious software, unfair billing practices, and more. Chrome with Safe Browsing checks all URLs, redirects or included resources, to identify such threats and protect users.
Safe Browsing provides a list for each threat it protects users against on the internet. A full catalog of lists that are used in Chrome can be found by visiting chrome://safe-browsing/#tab-db-manager on desktop platforms.
chrome://safe-browsing/#tab-db-manager
A list does not contain unsafe web addresses, also referred to as URLs, in entirety; it would be prohibitively expensive to keep all of them in a device’s limited memory. Instead it maps a URL, which can be very long, through a cryptographic hash function (SHA-256), to a unique fixed size string. This distinct fixed size string, called a hash, allows a list to be stored efficiently in limited memory. The Update API handles URLs only in the form of hashes and is also called hash-based API in this post.
Further, a list does not store hashes in entirety either, as even that would be too memory intensive. Instead, barring a case where data is not shared with Google and the list is small, it contains prefixes of the hashes. We refer to the original hash as a full hash, and a hash prefix as a partial hash.A list is updated following the Update API’s request frequency section. Chrome also follows a back-off mode in case of an unsuccessful response. These updates happen roughly every 30 minutes, following the minimum wait duration set by the server in the list update response.
For those interested in browsing relevant source code, here’s where to look:
As an example of a Safe Browsing list, let's say that we have one for malware, containing partial hashes of URLs known to host malware. These partial hashes are generally 4 bytes long, but for illustrative purposes, we show only 2 bytes.
['036b', '1a02', 'bac8', 'bb90']
Whenever Chrome needs to check the reputation of a resource with the Update API, for example when navigating to a URL, it does not share the raw URL (or any piece of it) with Safe Browsing to perform the lookup. Instead, Chrome uses full hashes of the URL (and some combinations) to look up the partial hashes in the locally maintained Safe Browsing list. Chrome sends only these matched partial hashes to the Safe Browsing service. This ensures that Chrome provides these protections while respecting the user’s privacy. This hash-based lookup happens in three steps in Chrome:
When Google blocks URLs that host potentially unsafe resources by placing them on a Safe Browsing list, the malicious actor can host the resource on a different URL. A malicious actor can cycle through various subdomains to generate new URLs. Safe Browsing uses host suffixes to identify malicious domains that host malware in their subdomains. Similarly, malicious actors can also cycle through various subpaths to generate new URLs. So Safe Browsing also uses path prefixes to identify websites that host malware at various subpaths. This prevents malicious actors from cycling through subdomains or paths for new malicious URLs, allowing robust and efficient identification of threats.
To incorporate these host suffixes and path prefixes, Chrome first computes the full hashes of the URL and some patterns derived from the URL. Following Safe Browsing API's URLs and Hashing specification, Chrome computes the full hashes of URL combinations by following these steps:
For instance, let's say that a user is trying to visit https://evil.example.com/blah#frag. The canonical url is https://evil.example.com/blah. The host suffixes to be tried are evil.example.com, and example.com. The path prefixes are / and /blah. The four combined URL combinations are evil.example.com/, evil.example.com/blah, example.com/, and example.com/blah.
https://evil.example.com/blah#frag
https://evil.example.com/blah
evil.example.com
example.com
/
/blah
evil.example.com/
evil.example.com/blah
example.com/
example.com/blah
url_combinations = ["evil.example.com/", "evil.example.com/blah","example.com/", "example.com/blah"] full_hashes = ['1a02…28', 'bb90…9f', '7a9e…67', 'bac8…fa']
Chrome then checks the full hashes of the URL combinations against the locally maintained Safe Browsing lists. These lists, which contain partial hashes, do not provide a decisive malicious verdict, but can quickly identify if the URL is considered not malicious. If the full hash of the URL does not match any of the partial hashes from the local lists, the URL is considered safe and Chrome proceeds to load it. This happens for more than 99% of the URLs checked.
Chrome finds that three full hashes 1a02…28, bb90…9f, and bac8…fa match local partial hashes. We note that this is for demonstration purposes, and a match here is rare.
1a02…28
bb90…9f
bac8…fa
Next, Chrome sends only the matching partial hash (not the full URL or any particular part of the URL, or even their full hashes), to the Safe Browsing service's fullHashes.find method. In response, it receives the full hashes of all malicious URLs for which the full hash begins with one of the partial hashes sent by Chrome. Chrome checks the fetched full hashes with the generated full hashes of the URL combinations. If any match is found, it identifies the URL with various threats and their severities inferred from the matched full hashes.
fullHashes.find
Chrome sends the matched partial hashes 1a02, bb90, and bac8 to fetch the full hashes. The server returns full hashes that match these partial hashes, 1a02…28, bb90…ce, and bac8…01. Chrome finds that one of the full hashes matches with the full hash of the URL combination being checked, and identifies the malicious URL as hosting malware.
1a02…28, bb90…ce,
bac8…01
Safe Browsing protects Chrome users from various malicious threats on the internet. While providing these protections, Chrome faces challenges such as constraints in memory capacity, network bandwidth usage, and a dynamic threat landscape. Chrome is also mindful of the users’ privacy choices, and shares little data with Google.
In a follow up post, we will cover the more advanced protections Chrome provides to its users who have opted in to “Enhanced Protection”.