
| | |  Ver fuente en GitHub Ver fuente en GitHub |
La API tf.data le permite crear canalizaciones de entrada complejas a partir de piezas simples y reutilizables. Por ejemplo, la tubería para un modelo de imagen podría agregar datos de archivos en un sistema de archivos distribuido, aplicar perturbaciones aleatorias a cada imagen y fusionar imágenes seleccionadas aleatoriamente en un lote para entrenamiento. La tubería para un modelo de texto podría implicar la extracción de símbolos de datos de texto sin procesar, convertirlos en identificadores incrustados con una tabla de búsqueda y agrupar secuencias de diferentes longitudes. La API tf.data permite manejar grandes cantidades de datos, leer desde diferentes formatos de datos y realizar transformaciones complejas.
La API tf.data presenta una abstracción tf.data.Dataset que representa una secuencia de elementos, en la que cada elemento consta de uno o más componentes. Por ejemplo, en una canalización de imágenes, un elemento podría ser un único ejemplo de entrenamiento, con un par de componentes de tensor que representan la imagen y su etiqueta.
Hay dos formas distintas de crear un conjunto de datos:
Una fuente de datos construye un conjunto de
Dataseta partir de datos almacenados en la memoria o en uno o más archivos.Una transformación de datos construye un conjunto de datos a partir de uno o más objetos
tf.data.Dataset.
import tensorflow as tf
import pathlib
import os
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
np.set_printoptions(precision=4)
Mecanica basica
Para crear una canalización de entrada, debe comenzar con una fuente de datos. Por ejemplo, para construir un conjunto de Dataset a partir de datos en la memoria, puede usar tf.data.Dataset.from_tensors() o tf.data.Dataset.from_tensor_slices() . Alternativamente, si sus datos de entrada se almacenan en un archivo en el formato TFRecord recomendado, puede usar tf.data.TFRecordDataset() .
Una vez que tenga un objeto Dataset , puede transformarlo en un nuevo Dataset encadenando llamadas a métodos en el objeto tf.data.Dataset . Por ejemplo, puede aplicar transformaciones por elemento como Dataset.map() y transformaciones de varios elementos como Dataset.batch() . Consulte la documentación de tf.data.Dataset para obtener una lista completa de transformaciones.
El objeto Dataset es iterable en Python. Esto hace posible consumir sus elementos usando un bucle for:
dataset = tf.data.Dataset.from_tensor_slices([8, 3, 0, 8, 2, 1])
dataset
<TensorSliceDataset element_spec=TensorSpec(shape=(), dtype=tf.int32, name=None)>
for elem in dataset:
print(elem.numpy())
8 3 0 8 2 1
O creando explícitamente un iterador de Python usando iter y consumiendo sus elementos usando next :
it = iter(dataset)
print(next(it).numpy())
8
Como alternativa, los elementos del conjunto de datos se pueden consumir mediante la transformación de reduce , que reduce todos los elementos para producir un solo resultado. El siguiente ejemplo ilustra cómo usar la transformación de reduce para calcular la suma de un conjunto de datos de enteros.
print(dataset.reduce(0, lambda state, value: state + value).numpy())
22
Estructura del conjunto de datos
Un conjunto de datos produce una secuencia de elementos , donde cada elemento es la misma estructura (anidada) de componentes . Los componentes individuales de la estructura pueden ser de cualquier tipo representable por tf.TypeSpec , incluidos tf.Tensor , tf.sparse.SparseTensor , tf.RaggedTensor , tf.TensorArray o tf.data.Dataset .
Las construcciones de Python que se pueden usar para expresar la estructura (anidada) de los elementos incluyen tuple , dict , NamedTuple y OrderedDict . En particular, la list no es una construcción válida para expresar la estructura de los elementos del conjunto de datos. Esto se debe a que los primeros usuarios de tf.data estaban convencidos de que las entradas de list (p. ej., pasadas a tf.data.Dataset.from_tensors ) se empaquetaban automáticamente como tensores y las salidas de list (p. ej., valores devueltos de funciones definidas por el usuario) se convertían en una tuple . Como consecuencia, si desea que una entrada de list se trate como una estructura, debe convertirla en tuple y si desea que la salida de una list sea un solo componente, debe empaquetarla explícitamente usando tf.stack .
La propiedad Dataset.element_spec le permite inspeccionar el tipo de cada componente del elemento. La propiedad devuelve una estructura anidada de objetos tf.TypeSpec , que coincide con la estructura del elemento, que puede ser un solo componente, una tupla de componentes o una tupla anidada de componentes. Por ejemplo:
dataset1 = tf.data.Dataset.from_tensor_slices(tf.random.uniform([4, 10]))
dataset1.element_spec
TensorSpec(shape=(10,), dtype=tf.float32, name=None)
dataset2 = tf.data.Dataset.from_tensor_slices(
(tf.random.uniform([4]),
tf.random.uniform([4, 100], maxval=100, dtype=tf.int32)))
dataset2.element_spec
(TensorSpec(shape=(), dtype=tf.float32, name=None), TensorSpec(shape=(100,), dtype=tf.int32, name=None))
dataset3 = tf.data.Dataset.zip((dataset1, dataset2))
dataset3.element_spec
(TensorSpec(shape=(10,), dtype=tf.float32, name=None), (TensorSpec(shape=(), dtype=tf.float32, name=None), TensorSpec(shape=(100,), dtype=tf.int32, name=None)))
# Dataset containing a sparse tensor.
dataset4 = tf.data.Dataset.from_tensors(tf.SparseTensor(indices=[[0, 0], [1, 2]], values=[1, 2], dense_shape=[3, 4]))
dataset4.element_spec
SparseTensorSpec(TensorShape([3, 4]), tf.int32)
# Use value_type to see the type of value represented by the element spec
dataset4.element_spec.value_type
tensorflow.python.framework.sparse_tensor.SparseTensor
Las transformaciones de conjuntos de Dataset admiten conjuntos de datos de cualquier estructura. Cuando se utilizan las Dataset.map() y Dataset.filter() , que aplican una función a cada elemento, la estructura del elemento determina los argumentos de la función:
dataset1 = tf.data.Dataset.from_tensor_slices(
tf.random.uniform([4, 10], minval=1, maxval=10, dtype=tf.int32))
dataset1
<TensorSliceDataset element_spec=TensorSpec(shape=(10,), dtype=tf.int32, name=None)>
for z in dataset1:
print(z.numpy())
[3 3 7 5 9 8 4 2 3 7] [8 9 6 7 5 6 1 6 2 3] [9 8 4 4 8 7 1 5 6 7] [5 9 5 4 2 5 7 8 8 8]
dataset2 = tf.data.Dataset.from_tensor_slices(
(tf.random.uniform([4]),
tf.random.uniform([4, 100], maxval=100, dtype=tf.int32)))
dataset2
<TensorSliceDataset element_spec=(TensorSpec(shape=(), dtype=tf.float32, name=None), TensorSpec(shape=(100,), dtype=tf.int32, name=None))>
dataset3 = tf.data.Dataset.zip((dataset1, dataset2))
dataset3
<ZipDataset element_spec=(TensorSpec(shape=(10,), dtype=tf.int32, name=None), (TensorSpec(shape=(), dtype=tf.float32, name=None), TensorSpec(shape=(100,), dtype=tf.int32, name=None)))>
for a, (b,c) in dataset3:
print('shapes: {a.shape}, {b.shape}, {c.shape}'.format(a=a, b=b, c=c))
shapes: (10,), (), (100,) shapes: (10,), (), (100,) shapes: (10,), (), (100,) shapes: (10,), (), (100,)
Lectura de datos de entrada
Consumir matrices NumPy
Consulte Cargar matrices NumPy para obtener más ejemplos.
Si todos sus datos de entrada caben en la memoria, la forma más sencilla de crear un conjunto de Dataset a partir de ellos es convertirlos en objetos tf.Tensor y usar Dataset.from_tensor_slices() .
train, test = tf.keras.datasets.fashion_mnist.load_data()
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz 32768/29515 [=================================] - 0s 0us/step 40960/29515 [=========================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz 26427392/26421880 [==============================] - 0s 0us/step 26435584/26421880 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz 16384/5148 [===============================================================================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz 4423680/4422102 [==============================] - 0s 0us/step 4431872/4422102 [==============================] - 0s 0us/step
images, labels = train
images = images/255
dataset = tf.data.Dataset.from_tensor_slices((images, labels))
dataset
<TensorSliceDataset element_spec=(TensorSpec(shape=(28, 28), dtype=tf.float64, name=None), TensorSpec(shape=(), dtype=tf.uint8, name=None))>
Consumo de generadores de Python
Otra fuente de datos común que se puede ingerir fácilmente como tf.data.Dataset es el generador de python.
def count(stop):
i = 0
while i<stop:
yield i
i += 1
for n in count(5):
print(n)
0 1 2 3 4
El constructor Dataset.from_generator convierte el generador de python en un tf.data.Dataset totalmente funcional.
El constructor toma un invocable como entrada, no un iterador. Esto le permite reiniciar el generador cuando llega al final. Toma un argumento args opcional, que se pasa como los argumentos del invocable.
El argumento output_types es necesario porque tf.data crea un tf.Graph internamente y los bordes del gráfico requieren un tf.dtype .
ds_counter = tf.data.Dataset.from_generator(count, args=[25], output_types=tf.int32, output_shapes = (), )
for count_batch in ds_counter.repeat().batch(10).take(10):
print(count_batch.numpy())
[0 1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18 19] [20 21 22 23 24 0 1 2 3 4] [ 5 6 7 8 9 10 11 12 13 14] [15 16 17 18 19 20 21 22 23 24] [0 1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18 19] [20 21 22 23 24 0 1 2 3 4] [ 5 6 7 8 9 10 11 12 13 14] [15 16 17 18 19 20 21 22 23 24]
El argumento output_shapes no es obligatorio, pero es muy recomendable, ya que muchas operaciones de TensorFlow no admiten tensores con un rango desconocido. Si la longitud de un eje en particular es desconocida o variable, configúrelo como None en output_shapes .
También es importante tener en cuenta que output_shapes y output_types siguen las mismas reglas de anidamiento que otros métodos de conjuntos de datos.
Aquí hay un generador de ejemplo que demuestra ambos aspectos, devuelve tuplas de matrices, donde la segunda matriz es un vector con una longitud desconocida.
def gen_series():
i = 0
while True:
size = np.random.randint(0, 10)
yield i, np.random.normal(size=(size,))
i += 1
for i, series in gen_series():
print(i, ":", str(series))
if i > 5:
break
0 : [0.3939] 1 : [ 0.9282 -0.0158 1.0096 0.7155 0.0491 0.6697 -0.2565 0.487 ] 2 : [-0.4831 0.37 -1.3918 -0.4786 0.7425 -0.3299] 3 : [ 0.1427 -1.0438 0.821 -0.8766 -0.8369 0.4168] 4 : [-1.4984 -1.8424 0.0337 0.0941 1.3286 -1.4938] 5 : [-1.3158 -1.2102 2.6887 -1.2809] 6 : []
La primera salida es un int32 la segunda es un float32 .
El primer elemento es un escalar, forma () , y el segundo es un vector de longitud desconocida, forma (None,)
ds_series = tf.data.Dataset.from_generator(
gen_series,
output_types=(tf.int32, tf.float32),
output_shapes=((), (None,)))
ds_series
<FlatMapDataset element_spec=(TensorSpec(shape=(), dtype=tf.int32, name=None), TensorSpec(shape=(None,), dtype=tf.float32, name=None))>
Ahora se puede usar como un tf.data.Dataset regular. Tenga en cuenta que al agrupar un conjunto de datos con una forma variable, debe usar Dataset.padded_batch .
ds_series_batch = ds_series.shuffle(20).padded_batch(10)
ids, sequence_batch = next(iter(ds_series_batch))
print(ids.numpy())
print()
print(sequence_batch.numpy())
[ 8 10 18 1 5 19 22 17 21 25] [[-0.6098 0.1366 -2.15 -0.9329 0. 0. ] [ 1.0295 -0.033 -0.0388 0. 0. 0. ] [-0.1137 0.3552 0.4363 -0.2487 -1.1329 0. ] [ 0. 0. 0. 0. 0. 0. ] [-1.0466 0.624 -1.7705 1.4214 0.9143 -0.62 ] [-0.9502 1.7256 0.5895 0.7237 1.5397 0. ] [ 0.3747 1.2967 0. 0. 0. 0. ] [-0.4839 0.292 -0.7909 -0.7535 0.4591 -1.3952] [-0.0468 0.0039 -1.1185 -1.294 0. 0. ] [-0.1679 -0.3375 0. 0. 0. 0. ]]
Para ver un ejemplo más realista, intente envolver preprocessing.image.ImageDataGenerator como tf.data.Dataset .
Primero descarga los datos:
flowers = tf.keras.utils.get_file(
'flower_photos',
'https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz',
untar=True)
Downloading data from https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz 228818944/228813984 [==============================] - 10s 0us/step 228827136/228813984 [==============================] - 10s 0us/step
Crea la image.ImageDataGenerator
img_gen = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255, rotation_range=20)
images, labels = next(img_gen.flow_from_directory(flowers))
Found 3670 images belonging to 5 classes.
print(images.dtype, images.shape)
print(labels.dtype, labels.shape)
float32 (32, 256, 256, 3) float32 (32, 5)
ds = tf.data.Dataset.from_generator(
lambda: img_gen.flow_from_directory(flowers),
output_types=(tf.float32, tf.float32),
output_shapes=([32,256,256,3], [32,5])
)
ds.element_spec
(TensorSpec(shape=(32, 256, 256, 3), dtype=tf.float32, name=None), TensorSpec(shape=(32, 5), dtype=tf.float32, name=None))
for images, label in ds.take(1):
print('images.shape: ', images.shape)
print('labels.shape: ', labels.shape)
Found 3670 images belonging to 5 classes. images.shape: (32, 256, 256, 3) labels.shape: (32, 5)
Consumir datos de TFRecord
Consulte Cargar TFRecords para ver un ejemplo de extremo a extremo.
La API tf.data admite una variedad de formatos de archivo para que pueda procesar grandes conjuntos de datos que no caben en la memoria. Por ejemplo, el formato de archivo TFRecord es un formato binario simple orientado a registros que muchas aplicaciones de TensorFlow usan para entrenar datos. La clase tf.data.TFRecordDataset le permite transmitir el contenido de uno o más archivos TFRecord como parte de una canalización de entrada.
Aquí hay un ejemplo que usa el archivo de prueba de French Street Name Signs (FSNS).
# Creates a dataset that reads all of the examples from two files.
fsns_test_file = tf.keras.utils.get_file("fsns.tfrec", "https://storage.googleapis.com/download.tensorflow.org/data/fsns-20160927/testdata/fsns-00000-of-00001")
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/fsns-20160927/testdata/fsns-00000-of-00001 7905280/7904079 [==============================] - 1s 0us/step 7913472/7904079 [==============================] - 1s 0us/step
El argumento de nombre de filenames para el inicializador TFRecordDataset puede ser una cadena, una lista de cadenas o un tf.Tensor de cadenas. Por lo tanto, si tiene dos conjuntos de archivos con fines de capacitación y validación, puede crear un método de fábrica que produzca el conjunto de datos, tomando los nombres de archivo como argumento de entrada:
dataset = tf.data.TFRecordDataset(filenames = [fsns_test_file])
dataset
<TFRecordDatasetV2 element_spec=TensorSpec(shape=(), dtype=tf.string, name=None)>
Muchos proyectos de TensorFlow usan registros tf.train.Example serializados en sus archivos TFRecord. Estos deben ser decodificados antes de que puedan ser inspeccionados:
raw_example = next(iter(dataset))
parsed = tf.train.Example.FromString(raw_example.numpy())
parsed.features.feature['image/text']
bytes_list {
value: "Rue Perreyon"
}
Consumir datos de texto
Consulte Cargar texto para ver un ejemplo de extremo a extremo.
Muchos conjuntos de datos se distribuyen como uno o más archivos de texto. El tf.data.TextLineDataset proporciona una manera fácil de extraer líneas de uno o más archivos de texto. Dado uno o más nombres de archivo, un TextLineDataset producirá un elemento con valor de cadena por línea de esos archivos.
directory_url = 'https://storage.googleapis.com/download.tensorflow.org/data/illiad/'
file_names = ['cowper.txt', 'derby.txt', 'butler.txt']
file_paths = [
tf.keras.utils.get_file(file_name, directory_url + file_name)
for file_name in file_names
]
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/illiad/cowper.txt 819200/815980 [==============================] - 0s 0us/step 827392/815980 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/illiad/derby.txt 811008/809730 [==============================] - 0s 0us/step 819200/809730 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/illiad/butler.txt 811008/807992 [==============================] - 0s 0us/step 819200/807992 [==============================] - 0s 0us/step
dataset = tf.data.TextLineDataset(file_paths)
Aquí están las primeras líneas del primer archivo:
for line in dataset.take(5):
print(line.numpy())
b"\xef\xbb\xbfAchilles sing, O Goddess! Peleus' son;" b'His wrath pernicious, who ten thousand woes' b"Caused to Achaia's host, sent many a soul" b'Illustrious into Ades premature,' b'And Heroes gave (so stood the will of Jove)'
Para alternar líneas entre archivos, use Dataset.interleave . Esto hace que sea más fácil mezclar archivos juntos. Aquí están la primera, segunda y tercera líneas de cada traducción:
files_ds = tf.data.Dataset.from_tensor_slices(file_paths)
lines_ds = files_ds.interleave(tf.data.TextLineDataset, cycle_length=3)
for i, line in enumerate(lines_ds.take(9)):
if i % 3 == 0:
print()
print(line.numpy())
b"\xef\xbb\xbfAchilles sing, O Goddess! Peleus' son;" b"\xef\xbb\xbfOf Peleus' son, Achilles, sing, O Muse," b'\xef\xbb\xbfSing, O goddess, the anger of Achilles son of Peleus, that brought' b'His wrath pernicious, who ten thousand woes' b'The vengeance, deep and deadly; whence to Greece' b'countless ills upon the Achaeans. Many a brave soul did it send' b"Caused to Achaia's host, sent many a soul" b'Unnumbered ills arose; which many a soul' b'hurrying down to Hades, and many a hero did it yield a prey to dogs and'
De forma predeterminada, un TextLineDataset produce cada línea de cada archivo, lo que puede no ser deseable, por ejemplo, si el archivo comienza con una línea de encabezado o contiene comentarios. Estas líneas se pueden eliminar mediante las Dataset.skip() o Dataset.filter() . Aquí, omite la primera línea, luego filtra para encontrar solo sobrevivientes.
titanic_file = tf.keras.utils.get_file("train.csv", "https://storage.googleapis.com/tf-datasets/titanic/train.csv")
titanic_lines = tf.data.TextLineDataset(titanic_file)
Downloading data from https://storage.googleapis.com/tf-datasets/titanic/train.csv 32768/30874 [===============================] - 0s 0us/step 40960/30874 [=======================================] - 0s 0us/step
for line in titanic_lines.take(10):
print(line.numpy())
b'survived,sex,age,n_siblings_spouses,parch,fare,class,deck,embark_town,alone' b'0,male,22.0,1,0,7.25,Third,unknown,Southampton,n' b'1,female,38.0,1,0,71.2833,First,C,Cherbourg,n' b'1,female,26.0,0,0,7.925,Third,unknown,Southampton,y' b'1,female,35.0,1,0,53.1,First,C,Southampton,n' b'0,male,28.0,0,0,8.4583,Third,unknown,Queenstown,y' b'0,male,2.0,3,1,21.075,Third,unknown,Southampton,n' b'1,female,27.0,0,2,11.1333,Third,unknown,Southampton,n' b'1,female,14.0,1,0,30.0708,Second,unknown,Cherbourg,n' b'1,female,4.0,1,1,16.7,Third,G,Southampton,n'
def survived(line):
return tf.not_equal(tf.strings.substr(line, 0, 1), "0")
survivors = titanic_lines.skip(1).filter(survived)
for line in survivors.take(10):
print(line.numpy())
b'1,female,38.0,1,0,71.2833,First,C,Cherbourg,n' b'1,female,26.0,0,0,7.925,Third,unknown,Southampton,y' b'1,female,35.0,1,0,53.1,First,C,Southampton,n' b'1,female,27.0,0,2,11.1333,Third,unknown,Southampton,n' b'1,female,14.0,1,0,30.0708,Second,unknown,Cherbourg,n' b'1,female,4.0,1,1,16.7,Third,G,Southampton,n' b'1,male,28.0,0,0,13.0,Second,unknown,Southampton,y' b'1,female,28.0,0,0,7.225,Third,unknown,Cherbourg,y' b'1,male,28.0,0,0,35.5,First,A,Southampton,y' b'1,female,38.0,1,5,31.3875,Third,unknown,Southampton,n'
Consumir datos CSV
Consulte Cargar archivos CSV y Cargar marcos de datos de Pandas para obtener más ejemplos.
El formato de archivo CSV es un formato popular para almacenar datos tabulares en texto sin formato.
Por ejemplo:
titanic_file = tf.keras.utils.get_file("train.csv", "https://storage.googleapis.com/tf-datasets/titanic/train.csv")
df = pd.read_csv(titanic_file)
df.head()
Si sus datos caben en la memoria, el mismo método Dataset.from_tensor_slices funciona en los diccionarios, lo que permite que estos datos se importen fácilmente:
titanic_slices = tf.data.Dataset.from_tensor_slices(dict(df))
for feature_batch in titanic_slices.take(1):
for key, value in feature_batch.items():
print(" {!r:20s}: {}".format(key, value))
'survived' : 0 'sex' : b'male' 'age' : 22.0 'n_siblings_spouses': 1 'parch' : 0 'fare' : 7.25 'class' : b'Third' 'deck' : b'unknown' 'embark_town' : b'Southampton' 'alone' : b'n'
Un enfoque más escalable es cargar desde el disco según sea necesario.
El módulo tf.data proporciona métodos para extraer registros de uno o más archivos CSV que cumplen con RFC 4180 .
La función experimental.make_csv_dataset es la interfaz de alto nivel para leer conjuntos de archivos csv. Admite la inferencia de tipo de columna y muchas otras características, como procesamiento por lotes y barajado, para simplificar el uso.
titanic_batches = tf.data.experimental.make_csv_dataset(
titanic_file, batch_size=4,
label_name="survived")
for feature_batch, label_batch in titanic_batches.take(1):
print("'survived': {}".format(label_batch))
print("features:")
for key, value in feature_batch.items():
print(" {!r:20s}: {}".format(key, value))
'survived': [1 0 0 0] features: 'sex' : [b'female' b'female' b'male' b'male'] 'age' : [32. 28. 37. 50.] 'n_siblings_spouses': [0 3 0 0] 'parch' : [0 1 1 0] 'fare' : [13. 25.4667 29.7 13. ] 'class' : [b'Second' b'Third' b'First' b'Second'] 'deck' : [b'unknown' b'unknown' b'C' b'unknown'] 'embark_town' : [b'Southampton' b'Southampton' b'Cherbourg' b'Southampton'] 'alone' : [b'y' b'n' b'n' b'y']
Puede usar el argumento select_columns si solo necesita un subconjunto de columnas.
titanic_batches = tf.data.experimental.make_csv_dataset(
titanic_file, batch_size=4,
label_name="survived", select_columns=['class', 'fare', 'survived'])
for feature_batch, label_batch in titanic_batches.take(1):
print("'survived': {}".format(label_batch))
for key, value in feature_batch.items():
print(" {!r:20s}: {}".format(key, value))
'survived': [0 1 1 0] 'fare' : [ 7.05 15.5 26.25 8.05] 'class' : [b'Third' b'Third' b'Second' b'Third']
También hay una clase experimental.CsvDataset de nivel inferior que proporciona un control más detallado. No admite la inferencia de tipo de columna. En su lugar, debe especificar el tipo de cada columna.
titanic_types = [tf.int32, tf.string, tf.float32, tf.int32, tf.int32, tf.float32, tf.string, tf.string, tf.string, tf.string]
dataset = tf.data.experimental.CsvDataset(titanic_file, titanic_types , header=True)
for line in dataset.take(10):
print([item.numpy() for item in line])
[0, b'male', 22.0, 1, 0, 7.25, b'Third', b'unknown', b'Southampton', b'n'] [1, b'female', 38.0, 1, 0, 71.2833, b'First', b'C', b'Cherbourg', b'n'] [1, b'female', 26.0, 0, 0, 7.925, b'Third', b'unknown', b'Southampton', b'y'] [1, b'female', 35.0, 1, 0, 53.1, b'First', b'C', b'Southampton', b'n'] [0, b'male', 28.0, 0, 0, 8.4583, b'Third', b'unknown', b'Queenstown', b'y'] [0, b'male', 2.0, 3, 1, 21.075, b'Third', b'unknown', b'Southampton', b'n'] [1, b'female', 27.0, 0, 2, 11.1333, b'Third', b'unknown', b'Southampton', b'n'] [1, b'female', 14.0, 1, 0, 30.0708, b'Second', b'unknown', b'Cherbourg', b'n'] [1, b'female', 4.0, 1, 1, 16.7, b'Third', b'G', b'Southampton', b'n'] [0, b'male', 20.0, 0, 0, 8.05, b'Third', b'unknown', b'Southampton', b'y']
Si algunas columnas están vacías, esta interfaz de bajo nivel le permite proporcionar valores predeterminados en lugar de tipos de columnas.
%%writefile missing.csv
1,2,3,4
,2,3,4
1,,3,4
1,2,,4
1,2,3,
,,,
Writing missing.csv
# Creates a dataset that reads all of the records from two CSV files, each with
# four float columns which may have missing values.
record_defaults = [999,999,999,999]
dataset = tf.data.experimental.CsvDataset("missing.csv", record_defaults)
dataset = dataset.map(lambda *items: tf.stack(items))
dataset
<MapDataset element_spec=TensorSpec(shape=(4,), dtype=tf.int32, name=None)>
for line in dataset:
print(line.numpy())
[1 2 3 4] [999 2 3 4] [ 1 999 3 4] [ 1 2 999 4] [ 1 2 3 999] [999 999 999 999]
De forma predeterminada, un CsvDataset genera todas las columnas de todas las líneas del archivo, lo que puede no ser deseable, por ejemplo, si el archivo comienza con una línea de encabezado que debe ignorarse, o si algunas columnas no son necesarias en la entrada. Estas líneas y campos se pueden eliminar con los argumentos header y select_cols respectivamente.
# Creates a dataset that reads all of the records from two CSV files with
# headers, extracting float data from columns 2 and 4.
record_defaults = [999, 999] # Only provide defaults for the selected columns
dataset = tf.data.experimental.CsvDataset("missing.csv", record_defaults, select_cols=[1, 3])
dataset = dataset.map(lambda *items: tf.stack(items))
dataset
<MapDataset element_spec=TensorSpec(shape=(2,), dtype=tf.int32, name=None)>
for line in dataset:
print(line.numpy())
[2 4] [2 4] [999 4] [2 4] [ 2 999] [999 999]
Consumir conjuntos de archivos
Hay muchos conjuntos de datos distribuidos como un conjunto de archivos, donde cada archivo es un ejemplo.
flowers_root = tf.keras.utils.get_file(
'flower_photos',
'https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz',
untar=True)
flowers_root = pathlib.Path(flowers_root)
El directorio raíz contiene un directorio para cada clase:
for item in flowers_root.glob("*"):
print(item.name)
sunflowers daisy LICENSE.txt roses tulips dandelion
Los archivos en cada directorio de clase son ejemplos:
list_ds = tf.data.Dataset.list_files(str(flowers_root/'*/*'))
for f in list_ds.take(5):
print(f.numpy())
b'/home/kbuilder/.keras/datasets/flower_photos/sunflowers/5018120483_cc0421b176_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/dandelion/8642679391_0805b147cb_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/sunflowers/8266310743_02095e782d_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/tulips/13176521023_4d7cc74856_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/dandelion/19437578578_6ab1b3c984.jpg'
Lea los datos usando la función tf.io.read_file y extraiga la etiqueta de la ruta, devolviendo pares (image, label) :
def process_path(file_path):
label = tf.strings.split(file_path, os.sep)[-2]
return tf.io.read_file(file_path), label
labeled_ds = list_ds.map(process_path)
for image_raw, label_text in labeled_ds.take(1):
print(repr(image_raw.numpy()[:100]))
print()
print(label_text.numpy())
b'\xff\xd8\xff\xe0\x00\x10JFIF\x00\x01\x01\x00\x00\x01\x00\x01\x00\x00\xff\xe2\x0cXICC_PROFILE\x00\x01\x01\x00\x00\x0cHLino\x02\x10\x00\x00mntrRGB XYZ \x07\xce\x00\x02\x00\t\x00\x06\x001\x00\x00acspMSFT\x00\x00\x00\x00IEC sRGB\x00\x00\x00\x00\x00\x00' b'daisy'
Elementos del conjunto de datos por lotes
Dosificación simple
La forma más simple de procesamiento por lotes apila n elementos consecutivos de un conjunto de datos en un solo elemento. La transformación Dataset.batch() hace exactamente esto, con las mismas restricciones que el operador tf.stack() , aplicadas a cada componente de los elementos: es decir, para cada componente i , todos los elementos deben tener un tensor exactamente de la misma forma.
inc_dataset = tf.data.Dataset.range(100)
dec_dataset = tf.data.Dataset.range(0, -100, -1)
dataset = tf.data.Dataset.zip((inc_dataset, dec_dataset))
batched_dataset = dataset.batch(4)
for batch in batched_dataset.take(4):
print([arr.numpy() for arr in batch])
[array([0, 1, 2, 3]), array([ 0, -1, -2, -3])] [array([4, 5, 6, 7]), array([-4, -5, -6, -7])] [array([ 8, 9, 10, 11]), array([ -8, -9, -10, -11])] [array([12, 13, 14, 15]), array([-12, -13, -14, -15])]
Mientras que tf.data intenta propagar información de forma, la configuración predeterminada de Dataset.batch da como resultado un tamaño de lote desconocido porque es posible que el último lote no esté lleno. Tenga en cuenta los None en la forma:
batched_dataset
<BatchDataset element_spec=(TensorSpec(shape=(None,), dtype=tf.int64, name=None), TensorSpec(shape=(None,), dtype=tf.int64, name=None))>
Use el argumento drop_remainder para ignorar ese último lote y obtener una propagación de forma completa:
batched_dataset = dataset.batch(7, drop_remainder=True)
batched_dataset
<BatchDataset element_spec=(TensorSpec(shape=(7,), dtype=tf.int64, name=None), TensorSpec(shape=(7,), dtype=tf.int64, name=None))>
Tensores de dosificación con relleno
La receta anterior funciona para tensores que tienen todos el mismo tamaño. Sin embargo, muchos modelos (p. ej., modelos de secuencias) funcionan con datos de entrada que pueden tener un tamaño variable (p. ej., secuencias de diferentes longitudes). Para manejar este caso, la transformación Dataset.padded_batch le permite procesar por lotes tensores de diferentes formas especificando una o más dimensiones en las que se pueden rellenar.
dataset = tf.data.Dataset.range(100)
dataset = dataset.map(lambda x: tf.fill([tf.cast(x, tf.int32)], x))
dataset = dataset.padded_batch(4, padded_shapes=(None,))
for batch in dataset.take(2):
print(batch.numpy())
print()
[[0 0 0] [1 0 0] [2 2 0] [3 3 3]] [[4 4 4 4 0 0 0] [5 5 5 5 5 0 0] [6 6 6 6 6 6 0] [7 7 7 7 7 7 7]]
La transformación Dataset.padded_batch le permite establecer un relleno diferente para cada dimensión de cada componente, y puede ser de longitud variable (significado como None en el ejemplo anterior) o de longitud constante. También es posible anular el valor de relleno, que por defecto es 0.
Flujos de trabajo de entrenamiento
Procesando varias épocas
La API tf.data ofrece dos formas principales de procesar varias épocas de los mismos datos.
La forma más sencilla de iterar sobre un conjunto de datos en varias épocas es usar la transformación Dataset.repeat() . Primero, cree un conjunto de datos de datos titánicos:
titanic_file = tf.keras.utils.get_file("train.csv", "https://storage.googleapis.com/tf-datasets/titanic/train.csv")
titanic_lines = tf.data.TextLineDataset(titanic_file)
def plot_batch_sizes(ds):
batch_sizes = [batch.shape[0] for batch in ds]
plt.bar(range(len(batch_sizes)), batch_sizes)
plt.xlabel('Batch number')
plt.ylabel('Batch size')
Aplicar la transformación Dataset.repeat() sin argumentos repetirá la entrada indefinidamente.
La transformación Dataset.repeat concatena sus argumentos sin señalar el final de una época y el comienzo de la siguiente. Debido a esto, un Dataset.batch aplicado después de Dataset.repeat generará lotes que se extienden a ambos lados de los límites de época:
titanic_batches = titanic_lines.repeat(3).batch(128)
plot_batch_sizes(titanic_batches)
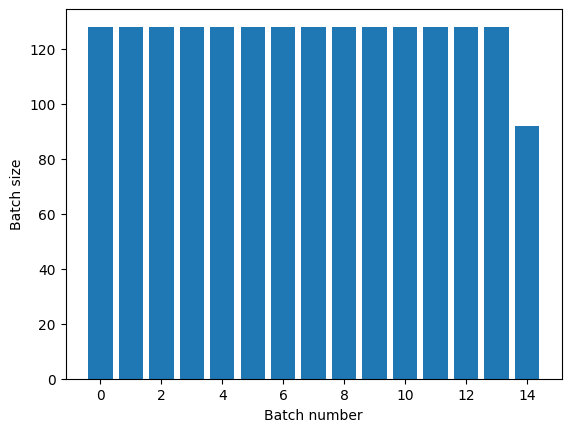
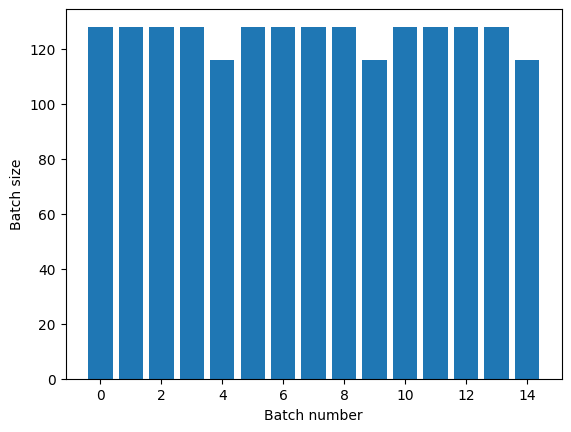
Si necesita una clara separación de épocas, coloque Dataset.batch antes de la repetición:
titanic_batches = titanic_lines.batch(128).repeat(3)
plot_batch_sizes(titanic_batches)
Si desea realizar un cálculo personalizado (por ejemplo, para recopilar estadísticas) al final de cada época, lo más sencillo es reiniciar la iteración del conjunto de datos en cada época:
epochs = 3
dataset = titanic_lines.batch(128)
for epoch in range(epochs):
for batch in dataset:
print(batch.shape)
print("End of epoch: ", epoch)
(128,) (128,) (128,) (128,) (116,) End of epoch: 0 (128,) (128,) (128,) (128,) (116,) End of epoch: 1 (128,) (128,) (128,) (128,) (116,) End of epoch: 2
Mezcla aleatoria de datos de entrada
La transformación Dataset.shuffle() mantiene un búfer de tamaño fijo y elige el siguiente elemento uniformemente al azar de ese búfer.
Agregue un índice al conjunto de datos para que pueda ver el efecto:
lines = tf.data.TextLineDataset(titanic_file)
counter = tf.data.experimental.Counter()
dataset = tf.data.Dataset.zip((counter, lines))
dataset = dataset.shuffle(buffer_size=100)
dataset = dataset.batch(20)
dataset
<BatchDataset element_spec=(TensorSpec(shape=(None,), dtype=tf.int64, name=None), TensorSpec(shape=(None,), dtype=tf.string, name=None))>
Dado que buffer_size es 100 y el tamaño del lote es 20, el primer lote no contiene elementos con un índice superior a 120.
n,line_batch = next(iter(dataset))
print(n.numpy())
[ 52 94 22 70 63 96 56 102 38 16 27 104 89 43 41 68 42 61 112 8]
Al igual que con Dataset.batch , el orden relativo a Dataset.repeat importa.
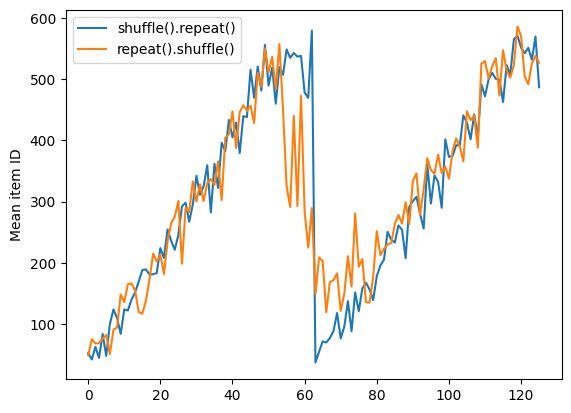
Dataset.shuffle no señala el final de una época hasta que el búfer de reproducción aleatoria está vacío. Entonces, una reproducción aleatoria colocada antes de una repetición mostrará todos los elementos de una época antes de pasar a la siguiente:
dataset = tf.data.Dataset.zip((counter, lines))
shuffled = dataset.shuffle(buffer_size=100).batch(10).repeat(2)
print("Here are the item ID's near the epoch boundary:\n")
for n, line_batch in shuffled.skip(60).take(5):
print(n.numpy())
Here are the item ID's near the epoch boundary: [509 595 537 550 555 591 480 627 482 519] [522 619 538 581 569 608 531 558 461 496] [548 489 379 607 611 622 234 525] [ 59 38 4 90 73 84 27 51 107 12] [77 72 91 60 7 62 92 47 70 67]
shuffle_repeat = [n.numpy().mean() for n, line_batch in shuffled]
plt.plot(shuffle_repeat, label="shuffle().repeat()")
plt.ylabel("Mean item ID")
plt.legend()
<matplotlib.legend.Legend at 0x7f7e7061c650>

Pero una repetición antes de una mezcla mezcla los límites de la época:
dataset = tf.data.Dataset.zip((counter, lines))
shuffled = dataset.repeat(2).shuffle(buffer_size=100).batch(10)
print("Here are the item ID's near the epoch boundary:\n")
for n, line_batch in shuffled.skip(55).take(15):
print(n.numpy())
Here are the item ID's near the epoch boundary: [ 6 8 528 604 13 492 308 441 569 475] [ 5 626 615 568 20 554 520 454 10 607] [510 542 0 363 32 446 395 588 35 4] [ 7 15 28 23 39 559 585 49 252 556] [581 617 25 43 26 548 29 460 48 41] [ 19 64 24 300 612 611 36 63 69 57] [287 605 21 512 442 33 50 68 608 47] [625 90 91 613 67 53 606 344 16 44] [453 448 89 45 465 2 31 618 368 105] [565 3 586 114 37 464 12 627 30 621] [ 82 117 72 75 84 17 571 610 18 600] [107 597 575 88 623 86 101 81 456 102] [122 79 51 58 80 61 367 38 537 113] [ 71 78 598 152 143 620 100 158 133 130] [155 151 144 135 146 121 83 27 103 134]
repeat_shuffle = [n.numpy().mean() for n, line_batch in shuffled]
plt.plot(shuffle_repeat, label="shuffle().repeat()")
plt.plot(repeat_shuffle, label="repeat().shuffle()")
plt.ylabel("Mean item ID")
plt.legend()
<matplotlib.legend.Legend at 0x7f7e706013d0>
Preprocesamiento de datos
La Dataset.map(f) produce un nuevo conjunto de datos al aplicar una función dada f a cada elemento del conjunto de datos de entrada. Se basa en la función map() que se aplica comúnmente a listas (y otras estructuras) en lenguajes de programación funcionales. La función f toma los objetos tf.Tensor que representan un solo elemento en la entrada y devuelve los objetos tf.Tensor que representarán un solo elemento en el nuevo conjunto de datos. Su implementación utiliza operaciones estándar de TensorFlow para transformar un elemento en otro.
Esta sección cubre ejemplos comunes de cómo usar Dataset.map() .
Decodificación de datos de imagen y cambio de tamaño
Cuando se entrena una red neuronal con datos de imágenes del mundo real, a menudo es necesario convertir imágenes de diferentes tamaños a un tamaño común, para que puedan agruparse en un tamaño fijo.
Reconstruya el conjunto de datos de nombres de archivos de flores:
list_ds = tf.data.Dataset.list_files(str(flowers_root/'*/*'))
Escriba una función que manipule los elementos del conjunto de datos.
# Reads an image from a file, decodes it into a dense tensor, and resizes it
# to a fixed shape.
def parse_image(filename):
parts = tf.strings.split(filename, os.sep)
label = parts[-2]
image = tf.io.read_file(filename)
image = tf.io.decode_jpeg(image)
image = tf.image.convert_image_dtype(image, tf.float32)
image = tf.image.resize(image, [128, 128])
return image, label
Prueba que funciona.
file_path = next(iter(list_ds))
image, label = parse_image(file_path)
def show(image, label):
plt.figure()
plt.imshow(image)
plt.title(label.numpy().decode('utf-8'))
plt.axis('off')
show(image, label)

Mapa sobre el conjunto de datos.
images_ds = list_ds.map(parse_image)
for image, label in images_ds.take(2):
show(image, label)


Aplicar la lógica arbitraria de Python
Por motivos de rendimiento, utilice las operaciones de TensorFlow para preprocesar sus datos siempre que sea posible. Sin embargo, a veces es útil llamar a bibliotecas externas de Python al analizar los datos de entrada. Puede usar la operación tf.py_function() en una transformación Dataset.map() .
Por ejemplo, si desea aplicar una rotación aleatoria, el módulo tf.image solo tiene tf.image.rot90 , que no es muy útil para el aumento de imágenes.
Para demostrar tf.py_function , intente usar la función scipy.ndimage.rotate en su lugar:
import scipy.ndimage as ndimage
def random_rotate_image(image):
image = ndimage.rotate(image, np.random.uniform(-30, 30), reshape=False)
return image
image, label = next(iter(images_ds))
image = random_rotate_image(image)
show(image, label)
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).

Para usar esta función con Dataset.map , se aplican las mismas advertencias que con Dataset.from_generator , debe describir las formas y los tipos de retorno cuando aplica la función:
def tf_random_rotate_image(image, label):
im_shape = image.shape
[image,] = tf.py_function(random_rotate_image, [image], [tf.float32])
image.set_shape(im_shape)
return image, label
rot_ds = images_ds.map(tf_random_rotate_image)
for image, label in rot_ds.take(2):
show(image, label)
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).


Análisis de mensajes de búfer de protocolo tf.Example
Muchas canalizaciones de entrada extraen mensajes de búfer de protocolo tf.train.Example desde un formato TFRecord. Cada registro tf.train.Example contiene una o más "características", y la canalización de entrada normalmente convierte estas características en tensores.
fsns_test_file = tf.keras.utils.get_file("fsns.tfrec", "https://storage.googleapis.com/download.tensorflow.org/data/fsns-20160927/testdata/fsns-00000-of-00001")
dataset = tf.data.TFRecordDataset(filenames = [fsns_test_file])
dataset
<TFRecordDatasetV2 element_spec=TensorSpec(shape=(), dtype=tf.string, name=None)>
Puede trabajar con prototipos de tf.train.Example fuera de un tf.data.Dataset para comprender los datos:
raw_example = next(iter(dataset))
parsed = tf.train.Example.FromString(raw_example.numpy())
feature = parsed.features.feature
raw_img = feature['image/encoded'].bytes_list.value[0]
img = tf.image.decode_png(raw_img)
plt.imshow(img)
plt.axis('off')
_ = plt.title(feature["image/text"].bytes_list.value[0])

raw_example = next(iter(dataset))
def tf_parse(eg):
example = tf.io.parse_example(
eg[tf.newaxis], {
'image/encoded': tf.io.FixedLenFeature(shape=(), dtype=tf.string),
'image/text': tf.io.FixedLenFeature(shape=(), dtype=tf.string)
})
return example['image/encoded'][0], example['image/text'][0]
img, txt = tf_parse(raw_example)
print(txt.numpy())
print(repr(img.numpy()[:20]), "...")
b'Rue Perreyon' b'\x89PNG\r\n\x1a\n\x00\x00\x00\rIHDR\x00\x00\x02X' ...
decoded = dataset.map(tf_parse)
decoded
<MapDataset element_spec=(TensorSpec(shape=(), dtype=tf.string, name=None), TensorSpec(shape=(), dtype=tf.string, name=None))>
image_batch, text_batch = next(iter(decoded.batch(10)))
image_batch.shape
TensorShape([10])
Ventanas de series de tiempo
Para ver un ejemplo de serie temporal de extremo a extremo, consulte: Pronóstico de series temporales .
Los datos de series de tiempo a menudo se organizan con el eje de tiempo intacto.
Use un Dataset.range simple para demostrar:
range_ds = tf.data.Dataset.range(100000)
Por lo general, los modelos basados en este tipo de datos querrán un intervalo de tiempo contiguo.
El enfoque más simple sería agrupar los datos por lotes:
usando batch
batches = range_ds.batch(10, drop_remainder=True)
for batch in batches.take(5):
print(batch.numpy())
[0 1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18 19] [20 21 22 23 24 25 26 27 28 29] [30 31 32 33 34 35 36 37 38 39] [40 41 42 43 44 45 46 47 48 49]
O para hacer predicciones densas un paso hacia el futuro, puede cambiar las características y las etiquetas en un paso relativo entre sí:
def dense_1_step(batch):
# Shift features and labels one step relative to each other.
return batch[:-1], batch[1:]
predict_dense_1_step = batches.map(dense_1_step)
for features, label in predict_dense_1_step.take(3):
print(features.numpy(), " => ", label.numpy())
[0 1 2 3 4 5 6 7 8] => [1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18] => [11 12 13 14 15 16 17 18 19] [20 21 22 23 24 25 26 27 28] => [21 22 23 24 25 26 27 28 29]
Para predecir una ventana completa en lugar de un desplazamiento fijo, puede dividir los lotes en dos partes:
batches = range_ds.batch(15, drop_remainder=True)
def label_next_5_steps(batch):
return (batch[:-5], # Inputs: All except the last 5 steps
batch[-5:]) # Labels: The last 5 steps
predict_5_steps = batches.map(label_next_5_steps)
for features, label in predict_5_steps.take(3):
print(features.numpy(), " => ", label.numpy())
[0 1 2 3 4 5 6 7 8 9] => [10 11 12 13 14] [15 16 17 18 19 20 21 22 23 24] => [25 26 27 28 29] [30 31 32 33 34 35 36 37 38 39] => [40 41 42 43 44]
Para permitir cierta superposición entre las características de un lote y las etiquetas de otro, use Dataset.zip :
feature_length = 10
label_length = 3
features = range_ds.batch(feature_length, drop_remainder=True)
labels = range_ds.batch(feature_length).skip(1).map(lambda labels: labels[:label_length])
predicted_steps = tf.data.Dataset.zip((features, labels))
for features, label in predicted_steps.take(5):
print(features.numpy(), " => ", label.numpy())
[0 1 2 3 4 5 6 7 8 9] => [10 11 12] [10 11 12 13 14 15 16 17 18 19] => [20 21 22] [20 21 22 23 24 25 26 27 28 29] => [30 31 32] [30 31 32 33 34 35 36 37 38 39] => [40 41 42] [40 41 42 43 44 45 46 47 48 49] => [50 51 52]
usando window
Si bien el uso Dataset.batch funciona, hay situaciones en las que puede necesitar un control más preciso. El método Dataset.window le brinda un control completo, pero requiere cierto cuidado: devuelve un conjunto de Dataset de conjuntos de Datasets . Consulte Estructura del conjunto de datos para obtener más detalles.
window_size = 5
windows = range_ds.window(window_size, shift=1)
for sub_ds in windows.take(5):
print(sub_ds)
<_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)> <_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)> <_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)> <_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)> <_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)>
El método Dataset.flat_map puede tomar un conjunto de datos de conjuntos de datos y aplanarlo en un único conjunto de datos:
for x in windows.flat_map(lambda x: x).take(30):
print(x.numpy(), end=' ')
0 1 2 3 4 1 2 3 4 5 2 3 4 5 6 3 4 5 6 7 4 5 6 7 8 5 6 7 8 9
En casi todos los casos, querrá .batch el conjunto de datos primero:
def sub_to_batch(sub):
return sub.batch(window_size, drop_remainder=True)
for example in windows.flat_map(sub_to_batch).take(5):
print(example.numpy())
[0 1 2 3 4] [1 2 3 4 5] [2 3 4 5 6] [3 4 5 6 7] [4 5 6 7 8]
Ahora, puede ver que el argumento de shift controla cuánto se mueve cada ventana.
Juntando esto, podrías escribir esta función:
def make_window_dataset(ds, window_size=5, shift=1, stride=1):
windows = ds.window(window_size, shift=shift, stride=stride)
def sub_to_batch(sub):
return sub.batch(window_size, drop_remainder=True)
windows = windows.flat_map(sub_to_batch)
return windows
ds = make_window_dataset(range_ds, window_size=10, shift = 5, stride=3)
for example in ds.take(10):
print(example.numpy())
[ 0 3 6 9 12 15 18 21 24 27] [ 5 8 11 14 17 20 23 26 29 32] [10 13 16 19 22 25 28 31 34 37] [15 18 21 24 27 30 33 36 39 42] [20 23 26 29 32 35 38 41 44 47] [25 28 31 34 37 40 43 46 49 52] [30 33 36 39 42 45 48 51 54 57] [35 38 41 44 47 50 53 56 59 62] [40 43 46 49 52 55 58 61 64 67] [45 48 51 54 57 60 63 66 69 72]
Entonces es fácil extraer etiquetas, como antes:
dense_labels_ds = ds.map(dense_1_step)
for inputs,labels in dense_labels_ds.take(3):
print(inputs.numpy(), "=>", labels.numpy())
[ 0 3 6 9 12 15 18 21 24] => [ 3 6 9 12 15 18 21 24 27] [ 5 8 11 14 17 20 23 26 29] => [ 8 11 14 17 20 23 26 29 32] [10 13 16 19 22 25 28 31 34] => [13 16 19 22 25 28 31 34 37]
remuestreo
Cuando trabaje con un conjunto de datos que está muy desequilibrado entre clases, es posible que desee volver a muestrear el conjunto de datos. tf.data proporciona dos métodos para hacer esto. El conjunto de datos de fraude con tarjetas de crédito es un buen ejemplo de este tipo de problema.
zip_path = tf.keras.utils.get_file(
origin='https://storage.googleapis.com/download.tensorflow.org/data/creditcard.zip',
fname='creditcard.zip',
extract=True)
csv_path = zip_path.replace('.zip', '.csv')
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/creditcard.zip 69156864/69155632 [==============================] - 2s 0us/step 69165056/69155632 [==============================] - 2s 0us/step
creditcard_ds = tf.data.experimental.make_csv_dataset(
csv_path, batch_size=1024, label_name="Class",
# Set the column types: 30 floats and an int.
column_defaults=[float()]*30+[int()])
Ahora, verifique la distribución de clases, está muy sesgada:
def count(counts, batch):
features, labels = batch
class_1 = labels == 1
class_1 = tf.cast(class_1, tf.int32)
class_0 = labels == 0
class_0 = tf.cast(class_0, tf.int32)
counts['class_0'] += tf.reduce_sum(class_0)
counts['class_1'] += tf.reduce_sum(class_1)
return counts
counts = creditcard_ds.take(10).reduce(
initial_state={'class_0': 0, 'class_1': 0},
reduce_func = count)
counts = np.array([counts['class_0'].numpy(),
counts['class_1'].numpy()]).astype(np.float32)
fractions = counts/counts.sum()
print(fractions)
[0.9956 0.0044]
Un enfoque común para entrenar con un conjunto de datos desequilibrado es equilibrarlo. tf.data incluye algunos métodos que permiten este flujo de trabajo:
Muestreo de conjuntos de datos
Un enfoque para volver a muestrear un conjunto de datos es usar sample_from_datasets . Esto es más aplicable cuando tiene datos separados data.Dataset de datos para cada clase.
Aquí, solo use el filtro para generarlos a partir de los datos de fraude de tarjetas de crédito:
negative_ds = (
creditcard_ds
.unbatch()
.filter(lambda features, label: label==0)
.repeat())
positive_ds = (
creditcard_ds
.unbatch()
.filter(lambda features, label: label==1)
.repeat())
for features, label in positive_ds.batch(10).take(1):
print(label.numpy())
[1 1 1 1 1 1 1 1 1 1]
Para usar tf.data.Dataset.sample_from_datasets , pase los conjuntos de datos y el peso de cada uno:
balanced_ds = tf.data.Dataset.sample_from_datasets(
[negative_ds, positive_ds], [0.5, 0.5]).batch(10)
Ahora el conjunto de datos produce ejemplos de cada clase con una probabilidad del 50/50:
for features, labels in balanced_ds.take(10):
print(labels.numpy())
[1 0 1 0 1 0 1 1 1 1] [0 0 1 1 0 1 1 1 1 1] [1 1 1 1 0 0 1 0 1 0] [1 1 1 0 1 0 0 1 1 1] [0 1 0 1 1 1 0 1 1 0] [0 1 0 0 0 1 0 0 0 0] [1 1 1 1 1 0 0 1 1 0] [0 0 0 1 0 1 1 1 0 0] [0 0 1 1 1 1 0 1 1 1] [1 0 0 1 1 1 1 0 1 1]
Remuestreo de rechazo
Un problema con el enfoque anterior de Dataset.sample_from_datasets es que necesita un tf.data.Dataset separado por clase. Podría usar Dataset.filter para crear esos dos conjuntos de datos, pero eso da como resultado que todos los datos se carguen dos veces.
El método data.Dataset.rejection_resample se puede aplicar a un conjunto de datos para reequilibrarlo, mientras solo se carga una vez. Los elementos se eliminarán del conjunto de datos para lograr el equilibrio.
data.Dataset.rejection_resample toma un argumento class_func . Este class_func se aplica a cada elemento del conjunto de datos y se usa para determinar a qué clase pertenece un ejemplo con el fin de equilibrarlo.
El objetivo aquí es equilibrar la distribución de etiquetas, y los elementos de creditcard_ds ya son pares (features, label) . Entonces class_func solo necesita devolver esas etiquetas:
def class_func(features, label):
return label
El método de remuestreo trata con ejemplos individuales, por lo que en este caso debe unbatch el conjunto de datos antes de aplicar ese método.
El método necesita una distribución objetivo y, opcionalmente, una estimación de distribución inicial como entradas.
resample_ds = (
creditcard_ds
.unbatch()
.rejection_resample(class_func, target_dist=[0.5,0.5],
initial_dist=fractions)
.batch(10))
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/data/ops/dataset_ops.py:5797: Print (from tensorflow.python.ops.logging_ops) is deprecated and will be removed after 2018-08-20. Instructions for updating: Use tf.print instead of tf.Print. Note that tf.print returns a no-output operator that directly prints the output. Outside of defuns or eager mode, this operator will not be executed unless it is directly specified in session.run or used as a control dependency for other operators. This is only a concern in graph mode. Below is an example of how to ensure tf.print executes in graph mode:
El método rejection_resample devuelve (class, example) pares donde la class es la salida de class_func . En este caso, el example ya era un par (feature, label) , así que use el map para soltar la copia adicional de las etiquetas:
balanced_ds = resample_ds.map(lambda extra_label, features_and_label: features_and_label)
Ahora el conjunto de datos produce ejemplos de cada clase con una probabilidad del 50/50:
for features, labels in balanced_ds.take(10):
print(labels.numpy())
Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] [0 1 1 1 0 1 1 0 1 1] [1 1 0 1 0 0 0 0 1 1] [1 1 1 1 0 0 0 0 1 1] [1 0 0 1 0 0 1 0 1 1] [1 0 0 0 0 1 0 0 0 0] [1 0 0 1 1 0 1 1 1 0] [1 1 0 0 0 0 0 0 0 1] [0 0 1 0 0 0 1 0 1 1] [0 1 0 1 0 1 0 0 0 1] [0 0 0 0 0 0 0 0 1 1]
Puntos de control del iterador
Tensorflow admite la toma de puntos de control para que, cuando se reinicie el proceso de entrenamiento, pueda restaurar el último punto de control para recuperar la mayor parte de su progreso. Además de marcar las variables del modelo, también puede marcar el progreso del iterador del conjunto de datos. Esto podría ser útil si tiene un conjunto de datos grande y no desea iniciar el conjunto de datos desde el principio en cada reinicio. Sin embargo, tenga en cuenta que los puntos de control del iterador pueden ser grandes, ya que las transformaciones como la shuffle y la prefetch requieren elementos de almacenamiento en búfer dentro del iterador.
Para incluir su iterador en un punto de control, pase el iterador al constructor tf.train.Checkpoint .
range_ds = tf.data.Dataset.range(20)
iterator = iter(range_ds)
ckpt = tf.train.Checkpoint(step=tf.Variable(0), iterator=iterator)
manager = tf.train.CheckpointManager(ckpt, '/tmp/my_ckpt', max_to_keep=3)
print([next(iterator).numpy() for _ in range(5)])
save_path = manager.save()
print([next(iterator).numpy() for _ in range(5)])
ckpt.restore(manager.latest_checkpoint)
print([next(iterator).numpy() for _ in range(5)])
[0, 1, 2, 3, 4] [5, 6, 7, 8, 9] [5, 6, 7, 8, 9]
Usando tf.data con tf.keras
La API tf.keras simplifica muchos aspectos de la creación y ejecución de modelos de aprendizaje automático. Sus .fit() y .evaluate() y .predict() admiten conjuntos de datos como entradas. Aquí hay un conjunto de datos rápido y una configuración del modelo:
train, test = tf.keras.datasets.fashion_mnist.load_data()
images, labels = train
images = images/255.0
labels = labels.astype(np.int32)
fmnist_train_ds = tf.data.Dataset.from_tensor_slices((images, labels))
fmnist_train_ds = fmnist_train_ds.shuffle(5000).batch(32)
model = tf.keras.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(10)
])
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
Pasar un conjunto de datos de pares (feature, label) es todo lo que se necesita para Model.fit y Model.evaluate :
model.fit(fmnist_train_ds, epochs=2)
Epoch 1/2 1875/1875 [==============================] - 4s 2ms/step - loss: 0.5984 - accuracy: 0.7973 Epoch 2/2 1875/1875 [==============================] - 4s 2ms/step - loss: 0.4607 - accuracy: 0.8430 <keras.callbacks.History at 0x7f7e70283110>
Si pasa un conjunto de datos infinito, por ejemplo llamando a Dataset.repeat() , solo necesita pasar también el argumento steps_per_epoch :
model.fit(fmnist_train_ds.repeat(), epochs=2, steps_per_epoch=20)
Epoch 1/2 20/20 [==============================] - 0s 2ms/step - loss: 0.4574 - accuracy: 0.8672 Epoch 2/2 20/20 [==============================] - 0s 2ms/step - loss: 0.4216 - accuracy: 0.8562 <keras.callbacks.History at 0x7f7e144948d0>
Para la evaluación, puede pasar el número de pasos de evaluación:
loss, accuracy = model.evaluate(fmnist_train_ds)
print("Loss :", loss)
print("Accuracy :", accuracy)
1875/1875 [==============================] - 4s 2ms/step - loss: 0.4350 - accuracy: 0.8524 Loss : 0.4350026249885559 Accuracy : 0.8524333238601685
Para conjuntos de datos largos, establezca la cantidad de pasos para evaluar:
loss, accuracy = model.evaluate(fmnist_train_ds.repeat(), steps=10)
print("Loss :", loss)
print("Accuracy :", accuracy)
10/10 [==============================] - 0s 2ms/step - loss: 0.4345 - accuracy: 0.8687 Loss : 0.43447819352149963 Accuracy : 0.8687499761581421
Las etiquetas no son necesarias cuando se llama a Model.predict .
predict_ds = tf.data.Dataset.from_tensor_slices(images).batch(32)
result = model.predict(predict_ds, steps = 10)
print(result.shape)
(320, 10)
Pero las etiquetas se ignoran si pasa un conjunto de datos que las contiene:
result = model.predict(fmnist_train_ds, steps = 10)
print(result.shape)
(320, 10)