Cybercriminals using cookie theft infostealer malware continue to pose a risk to the safety and security of our users. We already have a number of initiatives in this area including Chrome’s download protection using Safe Browsing, Device Bound Session Credentials, and Google’s account-based threat detection to flag the use of stolen cookies. Today, we’re announcing another layer of protection to make Windows users safer from this type of malware.
Like other software that needs to store secrets, Chrome currently secures sensitive data like cookies and passwords using the strongest techniques the OS makes available to us - on macOS this is the Keychain services, and on Linux we use a system provided wallet such as kwallet or gnome-libsecret. On Windows, Chrome uses the Data Protection API (DPAPI) which protects the data at rest from other users on the system or cold boot attacks. However, the DPAPI does not protect against malicious applications able to execute code as the logged in user - which infostealers take advantage of.
In Chrome 127 we are introducing a new protection on Windows that improves on the DPAPI by providing Application-Bound (App-Bound) Encryption primitives. Rather than allowing any app running as the logged in user to access this data, Chrome can now encrypt data tied to app identity, similar to how the Keychain operates on macOS.
We will be migrating each type of secret to this new system starting with cookies in Chrome 127. In future releases we intend to expand this protection to passwords, payment data, and other persistent authentication tokens, further protecting users from infostealer malware.
How it works
App-Bound Encryption relies on a privileged service to verify the identity of the requesting application. During encryption, the App-Bound Encryption service encodes the app's identity into the encrypted data, and then verifies this is valid when decryption is attempted. If another app on the system tries to decrypt the same data, it will fail.
Because the App-Bound service is running with system privileges, attackers need to do more than just coax a user into running a malicious app. Now, the malware has to gain system privileges, or inject code into Chrome, something that legitimate software shouldn't be doing. This makes their actions more suspicious to antivirus software – and more likely to be detected. Our other recent initiatives such as providing event logs for cookie decryption work in tandem with this protection, with the goal of further increasing the cost and risk of detection to attackers attempting to steal user data.
Enterprise Considerations
Since malware can bypass this protection by running elevated, enterprise environments that do not grant their users the ability to run downloaded files as Administrator are particularly helped by this protection - malware cannot simply request elevation privilege in these environments and is forced to use techniques such as injection that can be more easily detected by endpoint agents.
App-Bound Encryption strongly binds the encryption key to the machine, so will not function correctly in environments where Chrome profiles roam between multiple machines. We encourage enterprises who wish to support roaming profiles to follow current best practices. If it becomes necessary, App-Bound encryption can be configured using the new ApplicationBoundEncryptionEnabled policy.
To further help detect any incompatibilities, Chrome emits an event when a failed verification occurs. The Event is ID 257 from 'Chrome' source in the Application log.
Conclusion
App-Bound Encryption increases the cost of data theft to attackers and also makes their actions far noisier on the system. It helps defenders draw a clear line in the sand for what is acceptable behavior for other apps on the system. As the malware landscape continually evolves we are keen to continue engaging with others in the security community on improving detections and strengthening operating system protections, such as stronger app isolation primitives, for any bypasses.
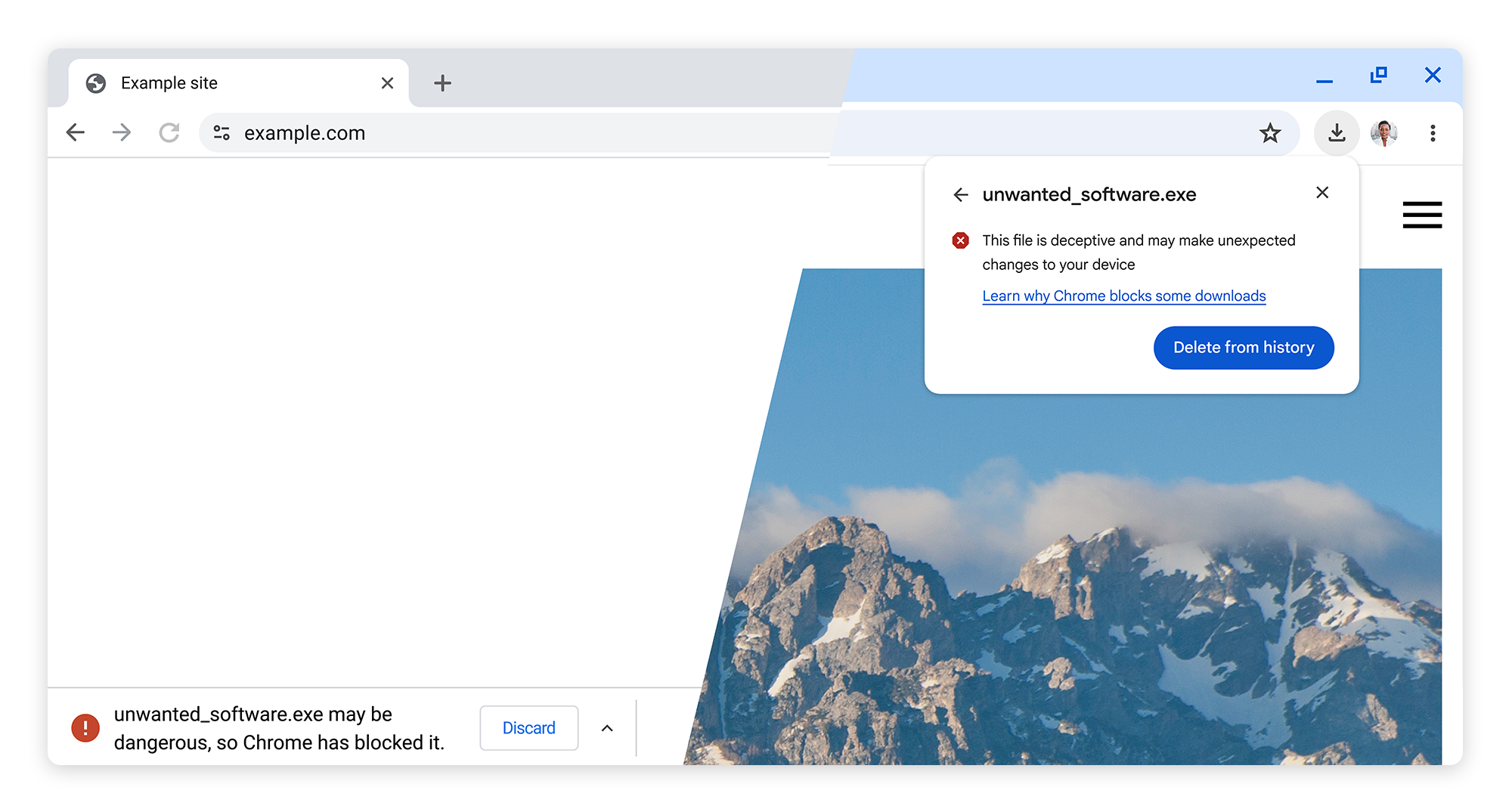
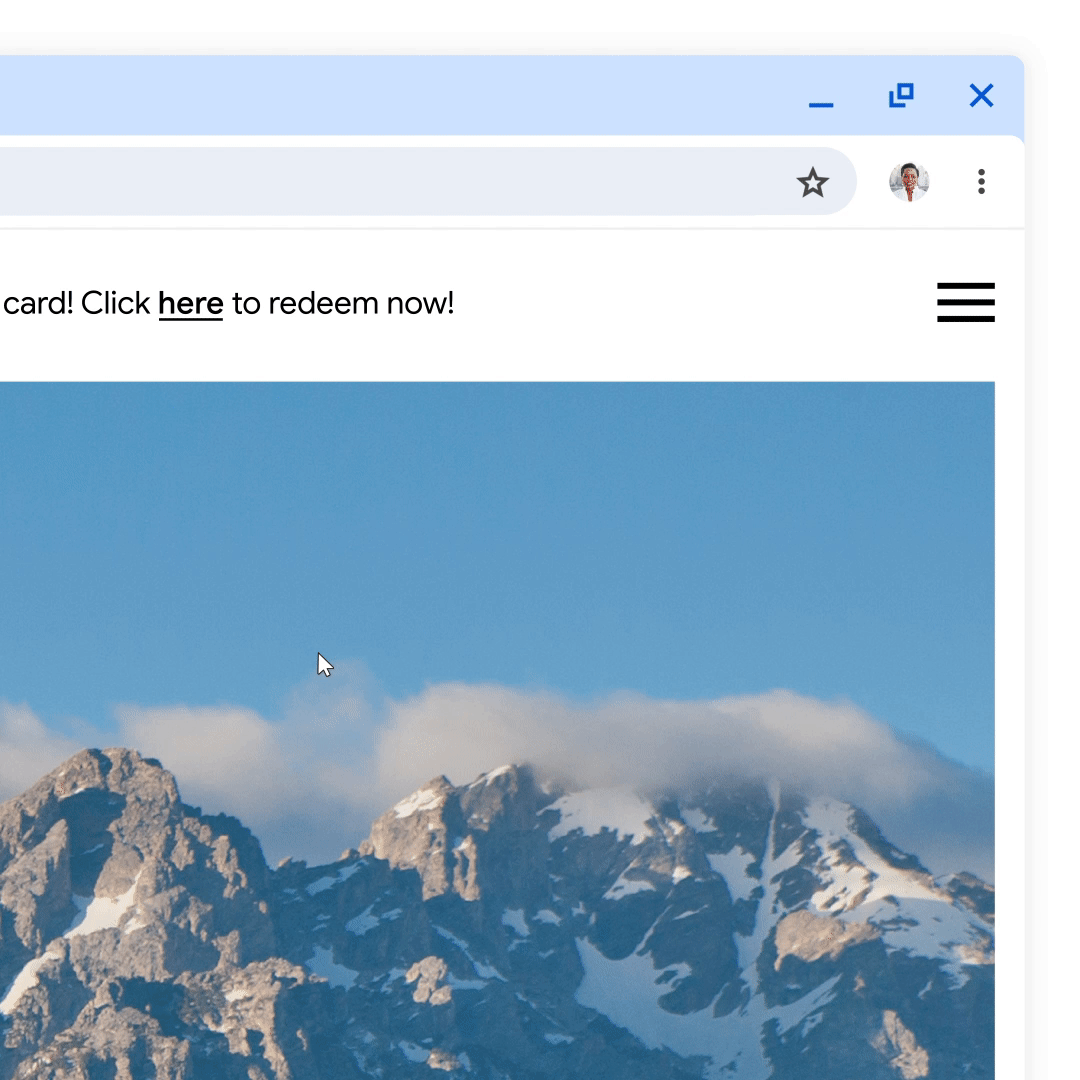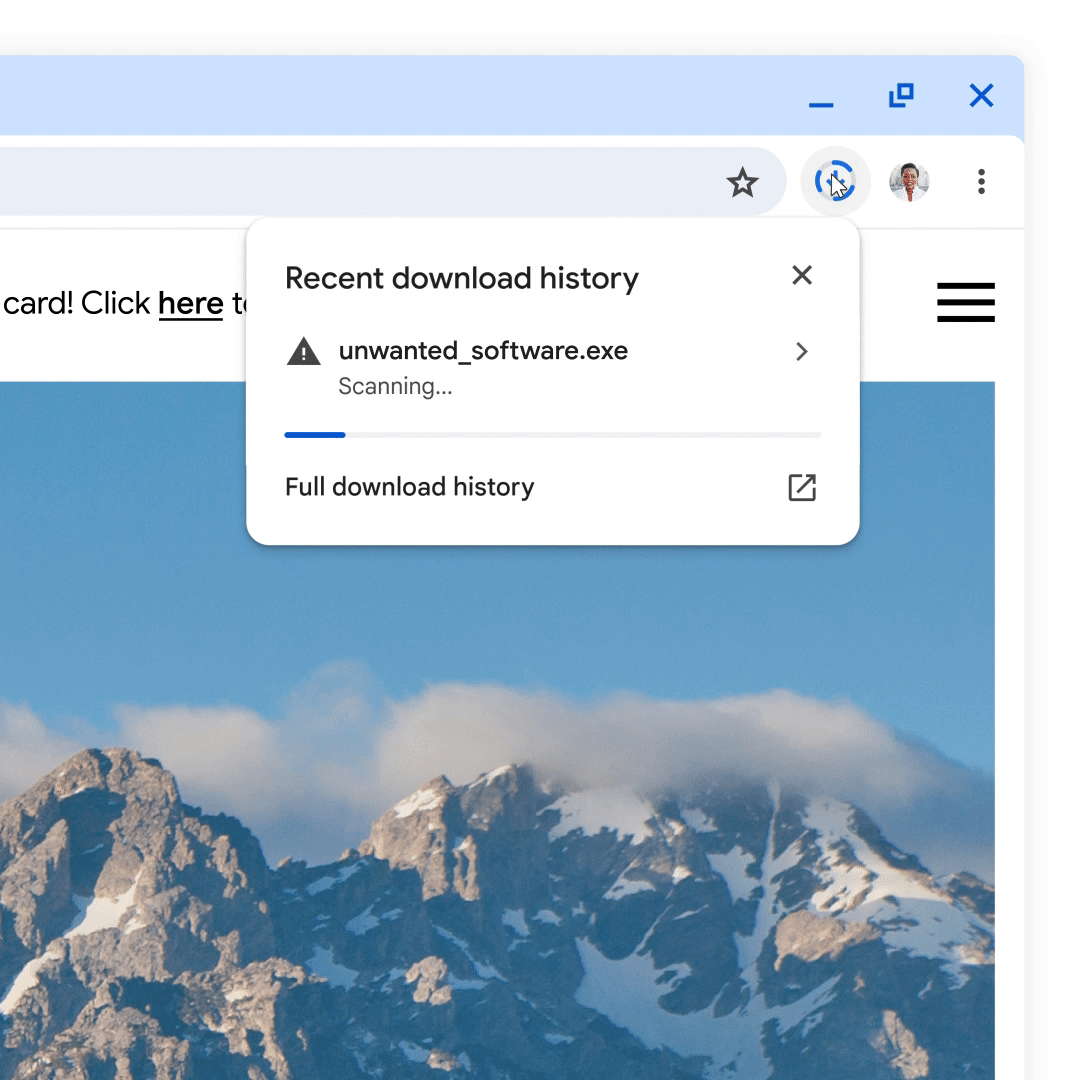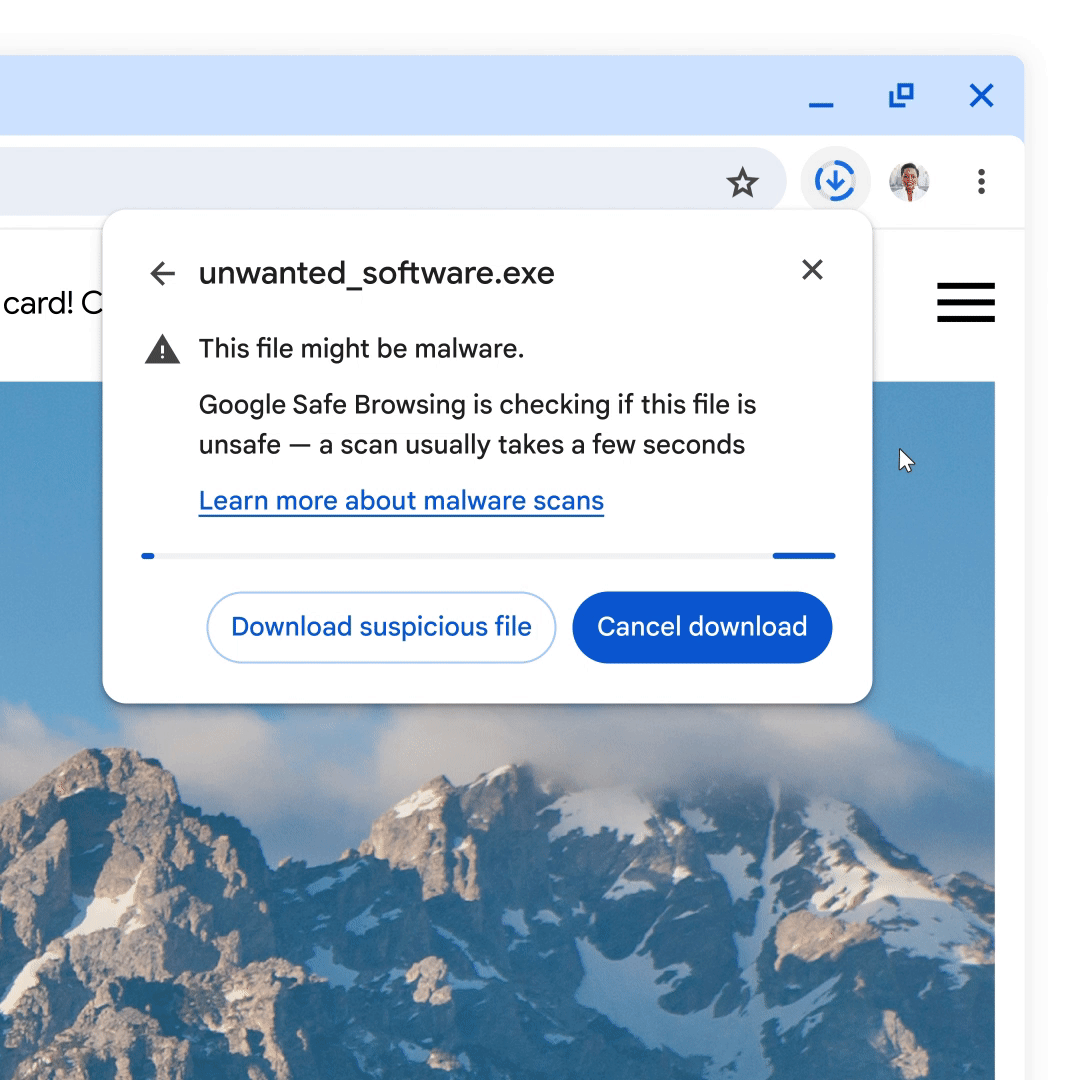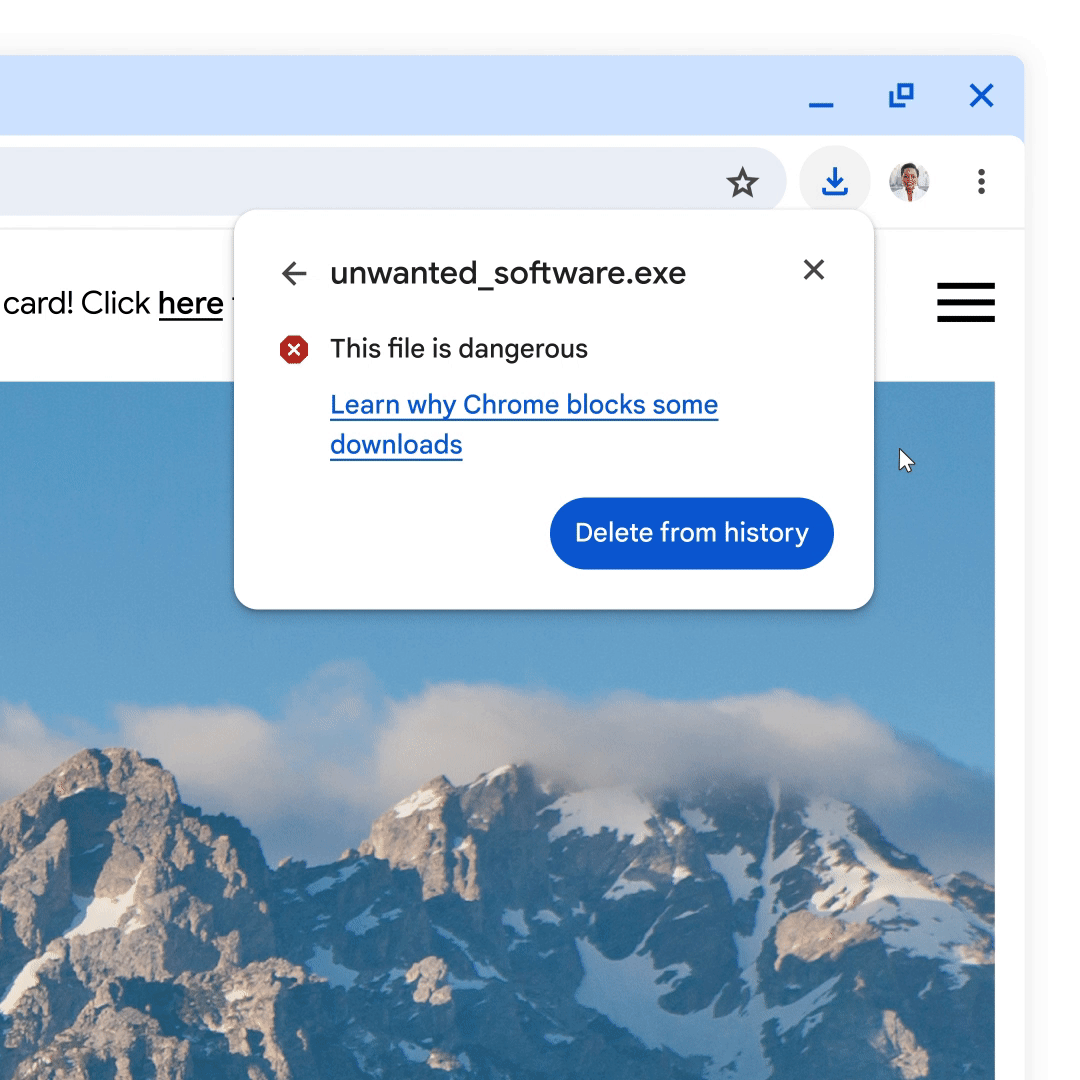
Last year, we introduced a redesign of the Chrome downloads experience on desktop to make it easier for users to interact with recent downloads. At the time, we mentioned that the additional space and more flexible UI of the new Chrome downloads experience would give us new opportunities to make sure users stay safe when downloading files.
Adding context and consistency to download warnings
The redesigned Chrome downloads experience gives us the opportunity to provide even more context when Chrome protects a user from a potentially malicious file. Taking advantage of the additional space available in the new downloads UI, we have replaced our previous warning messages with more detailed ones that convey more nuance about the nature of the danger and can help users make more informed decisions.
Our legacy, space-constrained warning vs. our redesigned one
We also made download warnings more understandable by introducing a two-tier download warning taxonomy based on AI-powered malware verdicts from Google Safe Browsing. These are:
These two tiers of warnings are distinguished by iconography, color, and text, to make it easy for users to quickly and confidently make the best choice for themselves based on the nature of the danger and Safe Browsing's level of certainty. Overall, these improvements in clarity and consistency have resulted in significant changes in user behavior, including fewer warnings bypassed, warnings heeded more quickly, and all in all, better protection from malicious downloads.
Differentiation between suspicious and dangerous warnings
Protecting more downloads with automatic deep scans
Users who have opted-in to the Enhanced Protection mode of Safe Browsing in Chrome are prompted to send the contents of suspicious files to Safe Browsing for deep scanning before opening the file. Suspicious files are a small fraction of overall downloads, and file contents are only scanned for security purposes and are deleted shortly after a verdict is returned.
We've found these additional scans to have been extraordinarily successful – they help catch brand new malware that Safe Browsing has not seen before and dangerous files hosted on brand new sites. In fact, files sent for deep scanning are over 50x more likely to be flagged as malware than downloads in the aggregate.
Since Enhanced Protection users have already agreed to send a small fraction of their downloads to Safe Browsing for security purposes in order to benefit from additional protections, we recently moved towards automatic deep scans for these users rather than prompting each time. This will protect users from risky downloads while reducing user friction.
An automatic deep scan resulting in a warning
Staying ahead of attackers who hide in encrypted archives
Not all deep scans can be conducted automatically. A current trend in cookie theft malware distribution is packaging malicious software in an encrypted archive – a .zip, .7z, or .rar file, protected by a password – which hides file contents from Safe Browsing and other antivirus detection scans. In order to combat this evasion technique, we have introduced two protection mechanisms depending on the mode of Safe Browsing selected by the user in Chrome.
Attackers often make the passwords to encrypted archives available in places like the page from which the file was downloaded, or in the download file name. For Enhanced Protection users, downloads of suspicious encrypted archives will now prompt the user to enter the file's password and send it along with the file to Safe Browsing so that the file can be opened and a deep scan may be performed. Uploaded files and file passwords are deleted a short time after they're scanned, and all collected data is only used by Safe Browsing to provide better download protections.
Enter a file password to send an encrypted file for a malware scan
For those who use Standard Protection mode which is the default in Chrome, we still wanted to be able to provide some level of protection. In Standard Protection mode, downloading a suspicious encrypted archive will also trigger a prompt to enter the file's password, but in this case, both the file and the password stay on the local device and only the metadata of the archive contents are checked with Safe Browsing. As such, in this mode, users are still protected as long as Safe Browsing had previously seen and categorized the malware.
The Chrome Security team works closely with Safe Browsing, Google's Threat Analysis Group, and security researchers from around the world to gain insights into the techniques attackers are using. Using these insights, we are constantly adapting our product strategy to stay ahead of attackers and to keep users safe while downloading files in Chrome. We look forward to sharing more in the future!
Update (09/10/2024): In support of more closely aligning Chrome’s planned compliance action with a major release milestone (i.e., M131), blocking action will now begin on November 12, 2024. This post has been updated to reflect the date change. Website operators who will be impacted by the upcoming change can explore continuity options offered by Entrust. Entrust has expressed its commitment to continuing to support customer needs, and is best positioned to describe the available options for website operators. Learn more at Entrust’s TLS Certificate Information Center.
The Chrome Security Team prioritizes the security and privacy of Chrome’s users, and we are unwilling to compromise on these values.
The Chrome Root Program Policy states that CA certificates included in the Chrome Root Store must provide value to Chrome end users that exceeds the risk of their continued inclusion. It also describes many of the factors we consider significant when CA Owners disclose and respond to incidents. When things don’t go right, we expect CA Owners to commit to meaningful and demonstrable change resulting in evidenced continuous improvement.
Over the past several years, publicly disclosed incident reports highlighted a pattern of concerning behaviors by Entrust that fall short of the above expectations, and has eroded confidence in their competence, reliability, and integrity as a publicly-trusted CA Owner.
In response to the above concerns and to preserve the integrity of the Web PKI ecosystem, Chrome will take the following actions.
Upcoming change in Chrome 131 and higher:
Additionally, should a Chrome user or enterprise explicitly trust any of the above certificates on a platform and version of Chrome relying on the Chrome Root Store (e.g., explicit trust is conveyed through a Group Policy Object on Windows), the SCT-based constraints described above will be overridden and certificates will function as they do today.
To further minimize risk of disruption, website operators are encouraged to review the “Frequently Asked Questions" listed below.
Certification Authorities (CAs) serve a privileged and trusted role on the Internet that underpin encrypted connections between browsers and websites. With this tremendous responsibility comes an expectation of adhering to reasonable and consensus-driven security and compliance expectations, including those defined by the CA/Browser TLS Baseline Requirements.
Over the past six years, we have observed a pattern of compliance failures, unmet improvement commitments, and the absence of tangible, measurable progress in response to publicly disclosed incident reports. When these factors are considered in aggregate and considered against the inherent risk each publicly-trusted CA poses to the Internet ecosystem, it is our opinion that Chrome’s continued trust in Entrust is no longer justified.
Blocking action will begin on approximately November 12, 2024, affecting certificates issued at that point or later.
Blocking action will occur in Versions of Chrome 131 and greater on Windows, macOS, ChromeOS, Android, and Linux. Apple policies prevent the Chrome Certificate Verifier and corresponding Chrome Root Store from being used on Chrome for iOS.
By default, Chrome users in the above populations who navigate to a website serving a certificate issued by Entrust or AffirmTrust after November 11, 2024 (11:59:59 PM UTC) will see a full page interstitial similar to this one.
Certificates issued by other CAs are not impacted by this action.
Website operators can determine if they are affected by this issue by using the Chrome Certificate Viewer.
Use the Chrome Certificate Viewer
We recommend that affected website operators transition to a new publicly-trusted CA Owner as soon as reasonably possible. To avoid adverse website user impact, action must be completed before the existing certificate(s) expire if expiry is planned to take place after November 11, 2024 (11:59:59 PM UTC).
While website operators could delay the impact of blocking action by choosing to collect and install a new TLS certificate issued from Entrust before Chrome’s blocking action begins on November 12, 2024, website operators will inevitably need to collect and install a new TLS certificate from one of the many other CAs included in the Chrome Root Store.
Yes.
A command-line flag was added beginning in Chrome 128 (available in Canary/Dev at the time of this post’s publication) that allows administrators and power users to simulate the effect of an SCTNotAfter distrust constraint as described in this blog post FAQ.
How to: Simulate an SCTNotAfter distrust
1. Close all open versions of Chrome
2. Start Chrome using the following command-line flag, substituting variables described below with actual values
3. Evaluate the effects of the flag with test websites
Example: The following command will simulate an SCTNotAfter distrust with an effective date of April 30, 2024 11:59:59 PM GMT for all of the Entrust trust anchors included in the Chrome Root Store. The expected behavior is that any website whose certificate is issued before the enforcement date/timestamp will function in Chrome, and all issued after will display an interstitial.
Illustrative Command (on Windows):
Illustrative Command (on macOS):
Note: If copy and pasting the above commands, ensure no line-breaks are introduced.
Learn more about command-line flags here.
Beginning in Chrome 127, enterprises can override Chrome Root Store constraints like those described for Entrust in this blog post by installing the corresponding root CA certificate as a locally-trusted root on the platform Chrome is running (e.g., installed in the Microsoft Certificate Store as a Trusted Root CA).
Customer organizations should defer to platform provider guidance.
Other Google product team updates may be made available in the future.
Google is committed to enhancing the security of open-source technologies, especially those that make up the foundation for many of our products, like Linux and KVM. To this end we are excited to announce the launch of kvmCTF, a vulnerability reward program (VRP) for the Kernel-based Virtual Machine (KVM) hypervisor first announced in October 2023.
KVM is a robust hypervisor with over 15 years of open-source development and is widely used throughout the consumer and enterprise landscape, including platforms such as Android and Google Cloud. Google is an active contributor to the project and we designed kvmCTF as a collaborative way to help identify & remediate vulnerabilities and further harden this fundamental security boundary.
Similar to kernelCTF, kvmCTF is a vulnerability reward program designed to help identify and address vulnerabilities in the Kernel-based Virtual Machine (KVM) hypervisor. It offers a lab environment where participants can log in and utilize their exploits to obtain flags. Significantly, in kvmCTF the focus is on zero day vulnerabilities and as a result, we will not be rewarding exploits that use n-days vulnerabilities. Details regarding the zero day vulnerability will be shared with Google after an upstream patch is released to ensure that Google obtains them at the same time as the rest of the open-source community. Additionally, kvmCTF uses the Google Bare Metal Solution (BMS) environment to host its infrastructure. Finally, given how critical a hypervisor is to overall system security, kvmCTF will reward various levels of vulnerabilities up to and including code execution and VM escape.
The environment consists of a bare metal host running a single guest VM. Participants will be able to reserve time slots to access the guest VM and attempt to perform a guest-to-host attack. The goal of the attack must be to exploit a zero day vulnerability in the KVM subsystem of the host kernel. If successful, the attacker will obtain a flag that proves their accomplishment in exploiting the vulnerability. The severity of the attack will determine the reward amount, which will be based on the reward tier system explained below. All reports will be thoroughly evaluated on a case-by-case basis.
The rewards tiers are the following:
Full VM escape: $250,000
Arbitrary memory write: $100,000
Arbitrary memory read: $50,000
Relative memory write: $50,000
Denial of service: $20,000
Relative memory read: $10,000
To facilitate the relative memory write/read tiers and partly the denial of service, kvmCTF offers the option of using a host with KASAN enabled. In that case, triggering a KASAN violation will allow the participant to obtain a flag as proof.
How to participate
To begin, start by reading the rules of the program. There you will find information on how to reserve a time slot, connect to the guest and obtain the flags, the mapping of the various KASAN violations with the reward tiers and instructions on how to report a vulnerability, send us your submission, or contact us on Discord.
The US Defense Advanced Research Projects Agency, DARPA, recently kicked off a two-year AI Cyber Challenge (AIxCC), inviting top AI and cybersecurity experts to design new AI systems to help secure major open source projects which our critical infrastructure relies upon. As AI continues to grow, it’s crucial to invest in AI tools for Defenders, and this competition will help advance technology to do so.
Google’s OSS-Fuzz and Security Engineering teams have been excited to assist AIxCC organizers in designing their challenges and competition framework. We also playtested the competition by building a Cyber Reasoning System (CRS) tackling DARPA’s exemplar challenge.
This blog post will share our approach to the exemplar challenge using open source technology found in Google’s OSS-Fuzz, highlighting opportunities where AI can supercharge the platform’s ability to find and patch vulnerabilities, which we hope will inspire innovative solutions from competitors.
AIxCC challenges focus on finding and fixing vulnerabilities in open source projects. OSS-Fuzz, our fuzz testing platform, has been finding vulnerabilities in open source projects as a public service for years, resulting in over 11,000 vulnerabilities found and fixed across 1200+ projects. OSS-Fuzz is free, open source, and its projects and infrastructure are shaped very similarly to AIxCC challenges. Competitors can easily reuse its existing toolchains, fuzzing engines, and sanitizers on AIxCC projects. Our baseline Cyber Reasoning System (CRS) mainly leverages non-AI techniques and has some limitations. We highlight these as opportunities for competitors to explore how AI can advance the state of the art in fuzz testing.
For userspace Java and C/C++ challenges, fuzzing with engines such as libFuzzer, AFL(++), and Jazzer is straightforward because they use the same interface as OSS-Fuzz.
Fuzzing the kernel is trickier, so we considered two options:
Syzkaller, an unsupervised coverage guided kernel fuzzer
A general purpose coverage guided fuzzer, such as AFL
Syzkaller has been effective at finding Linux kernel vulnerabilities, but is not suitable for AIxCC because Syzkaller generates sequences of syscalls to fuzz the whole Linux kernel, while AIxCC kernel challenges (exemplar) come with a userspace harness to exercise specific parts of the kernel.
Instead, we chose to use AFL, which is typically used to fuzz userspace programs. To enable kernel fuzzing, we followed a similar approach to an older blog post from Cloudflare. We compiled the kernel with KCOV and KSAN instrumentation and ran it virtualized under QEMU. Then, a userspace harness acts as a fake AFL forkserver, which executes the inputs by executing the sequence of syscalls to be fuzzed.
After every input execution, the harness read the KCOV coverage and stored it in AFL’s coverage counters via shared memory to enable coverage-guided fuzzing. The harness also checked the kernel dmesg log after every run to discover whether or not the input caused a KASAN sanitizer to trigger.
Some changes to Cloudflare’s harness were required in order for this to be pluggable with the provided kernel challenges. We needed to turn the harness into a library/wrapper that could be linked against arbitrary AIxCC kernel harnesses.
AIxCC challenges come with their own main() which takes in a file path. The main() function opens and reads this file, and passes it to the harness() function, which takes in a buffer and size representing the input. We made our wrapper work by wrapping the main() during compilation via $CC -Wl,--wrap=main harness.c harness_wrapper.a
The wrapper starts by setting up KCOV, the AFL forkserver, and shared memory. The wrapper also reads the input from stdin (which is what AFL expects by default) and passes it to the harness() function in the challenge harness.
Because AIxCC's harnesses aren't within our control and may misbehave, we had to be careful with memory or FD leaks within the challenge harness. Indeed, the provided harness has various FD leaks, which means that fuzzing it will very quickly become useless as the FD limit is reached.
To address this, we could either:
Forcibly close FDs created during the running of harness by checking for newly created FDs via /proc/self/fd before and after the execution of the harness, or
Just fork the userspace harness by actually forking in the forkserver.
The first approach worked for us. The latter is likely most reliable, but may worsen performance.
All of these efforts enabled afl-fuzz to fuzz the Linux exemplar, but the vulnerability cannot be easily found even after hours of fuzzing, unless provided with seed inputs close to the solution.
This limitation of fuzzing highlights a potential area for competitors to explore AI’s capabilities. The input format being complicated, combined with slow execution speeds make the exact reproducer hard to discover. Using AI could unlock the ability for fuzzing to find this vulnerability quickly—for example, by asking an LLM to generate seed inputs (or a script to generate them) close to expected input format based on the harness source code. Competitors might find inspiration in some interesting experiments done by Brendan Dolan-Gavitt from NYU, which show promise for this idea.
One alternative to fuzzing to find vulnerabilities is to use static analysis. Static analysis traditionally has challenges with generating high amounts of false positives, as well as difficulties in proving exploitability and reachability of issues it points out. LLMs could help dramatically improve bug finding capabilities by augmenting traditional static analysis techniques with increased accuracy and analysis capabilities.
The culprit commit, which can be found from git history bisection.
The expected sanitizer, which can be found by running the reproducer to get the crash and parsing the resulting stacktrace.
Once the culprit commit has been identified, one obvious way to “patch” the vulnerability is to just revert this commit. However, the commit may include legitimate changes that are necessary for functionality tests to pass. To ensure functionality doesn’t break, we could apply delta debugging: we progressively try to include/exclude different parts of the culprit commit until both the vulnerability no longer triggers, yet all functionality tests still pass.
This is a rather brute force approach to “patching.” There is no comprehension of the code being patched and it will likely not work for more complicated patches that include subtle changes required to fix the vulnerability without breaking functionality.
These limitations highlight a second area for competitors to apply AI’s capabilities. One approach might be to use an LLM to suggest patches. A 2024 whitepaper from Google walks through one way to build an LLM-based automated patching pipeline.
Competitors will need to address the following challenges:
Validating the patches by running crashes and tests to ensure the crash was prevented and the functionality was not impacted
Narrowing prompts to include only the functions present in the crashing stack trace, to fit prompt limitations
Building a validation step to filter out invalid patches
Using an LLM agent is likely another promising approach, where competitors could combine an LLM’s generation capabilities with the ability to compile and receive debug test failures or stacktraces iteratively.



.png)




