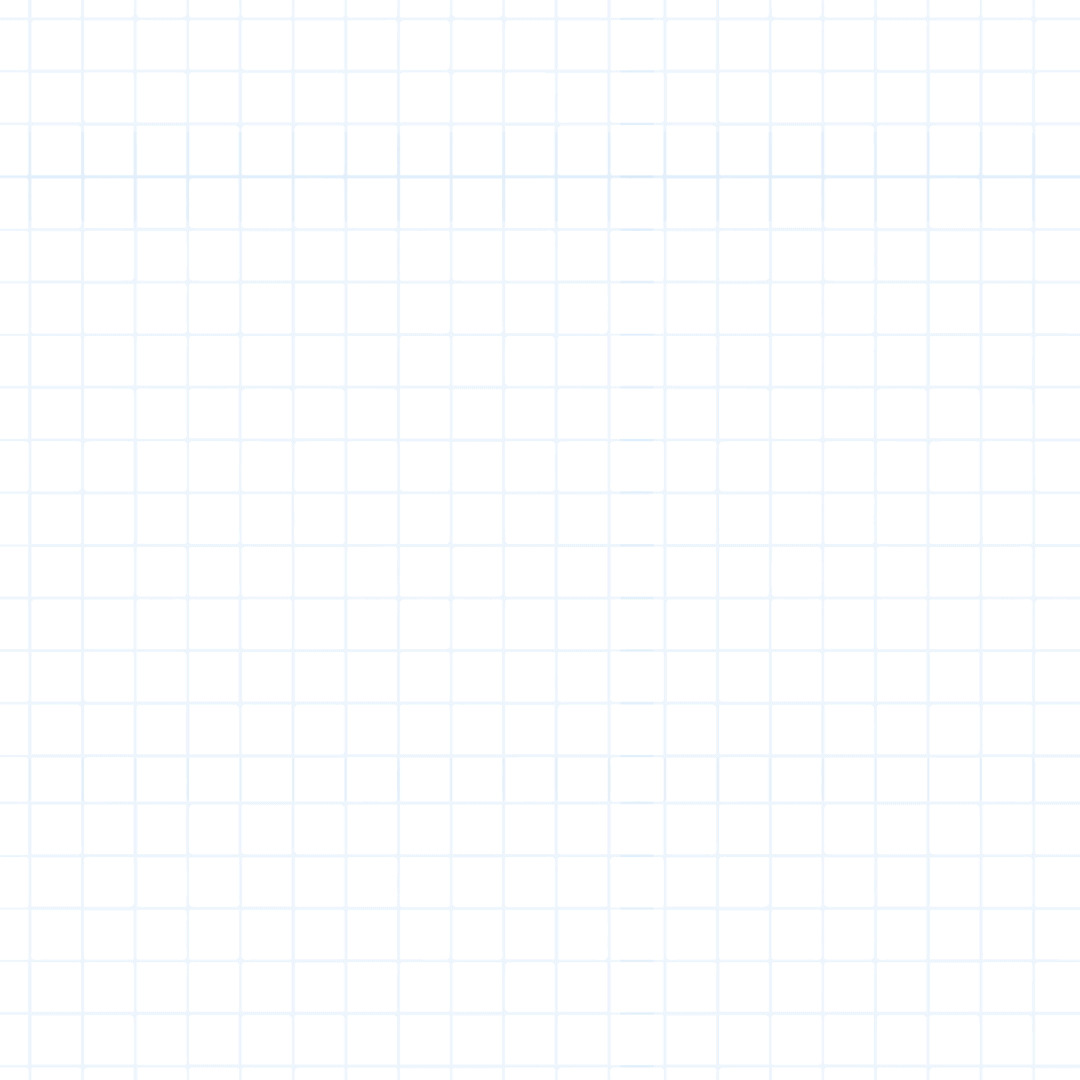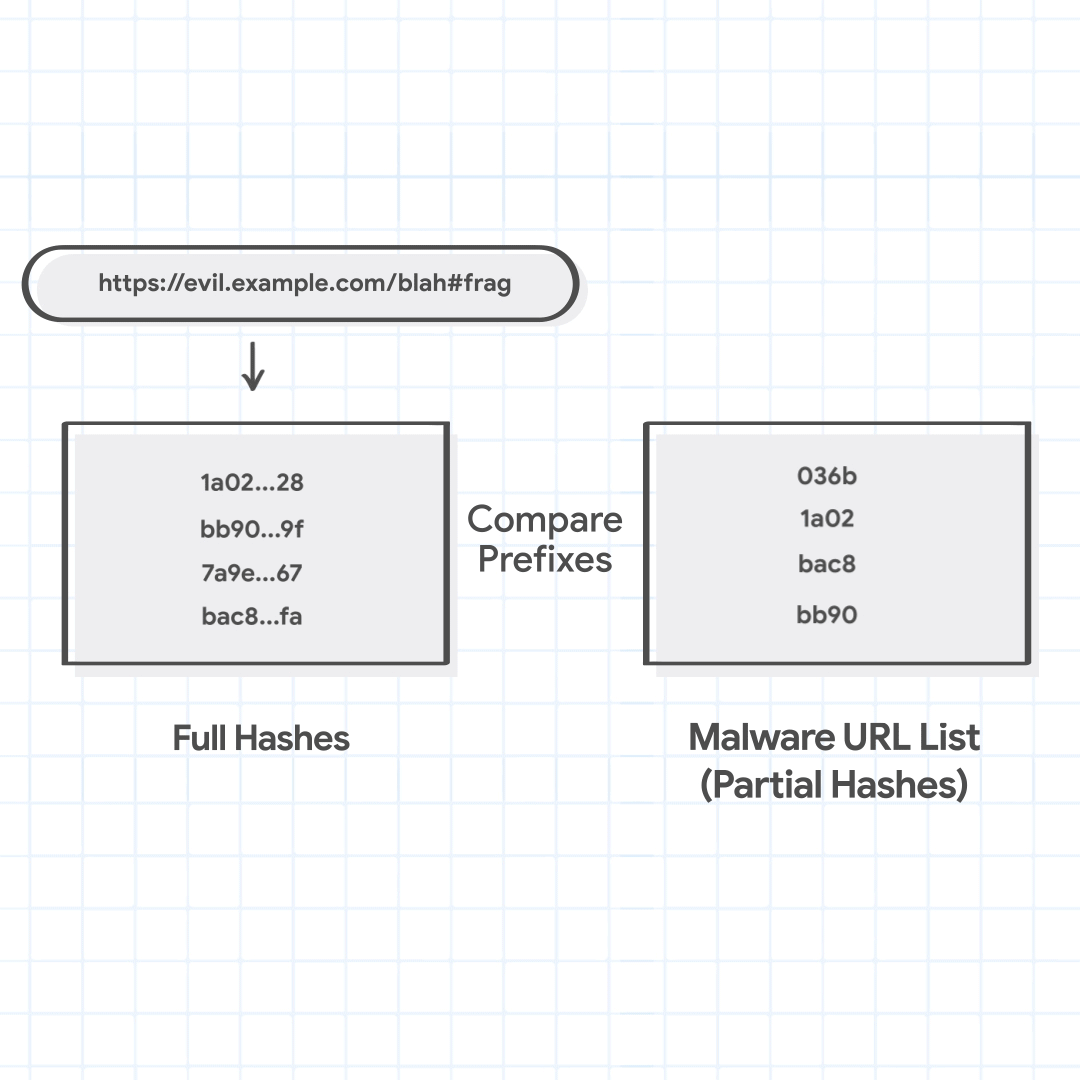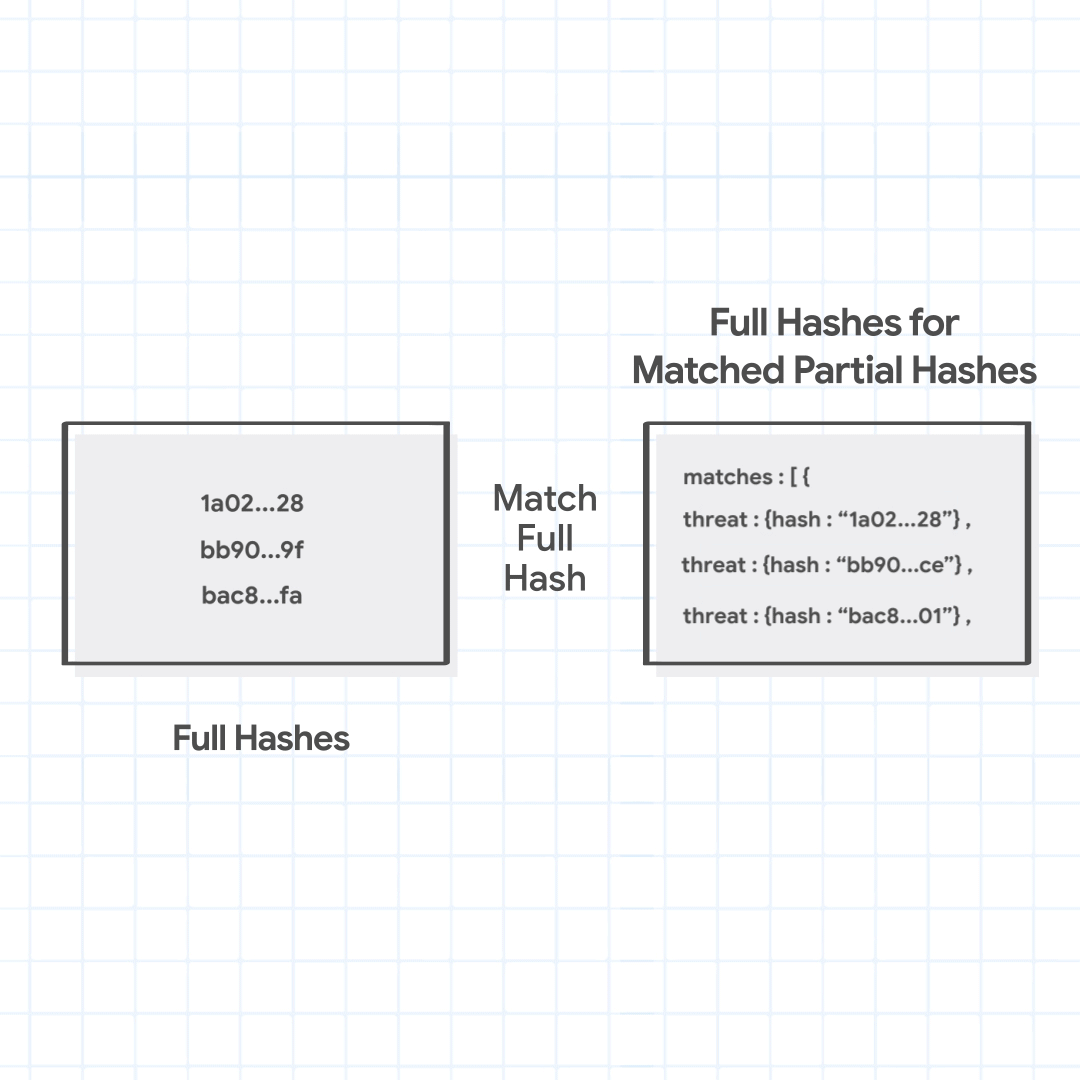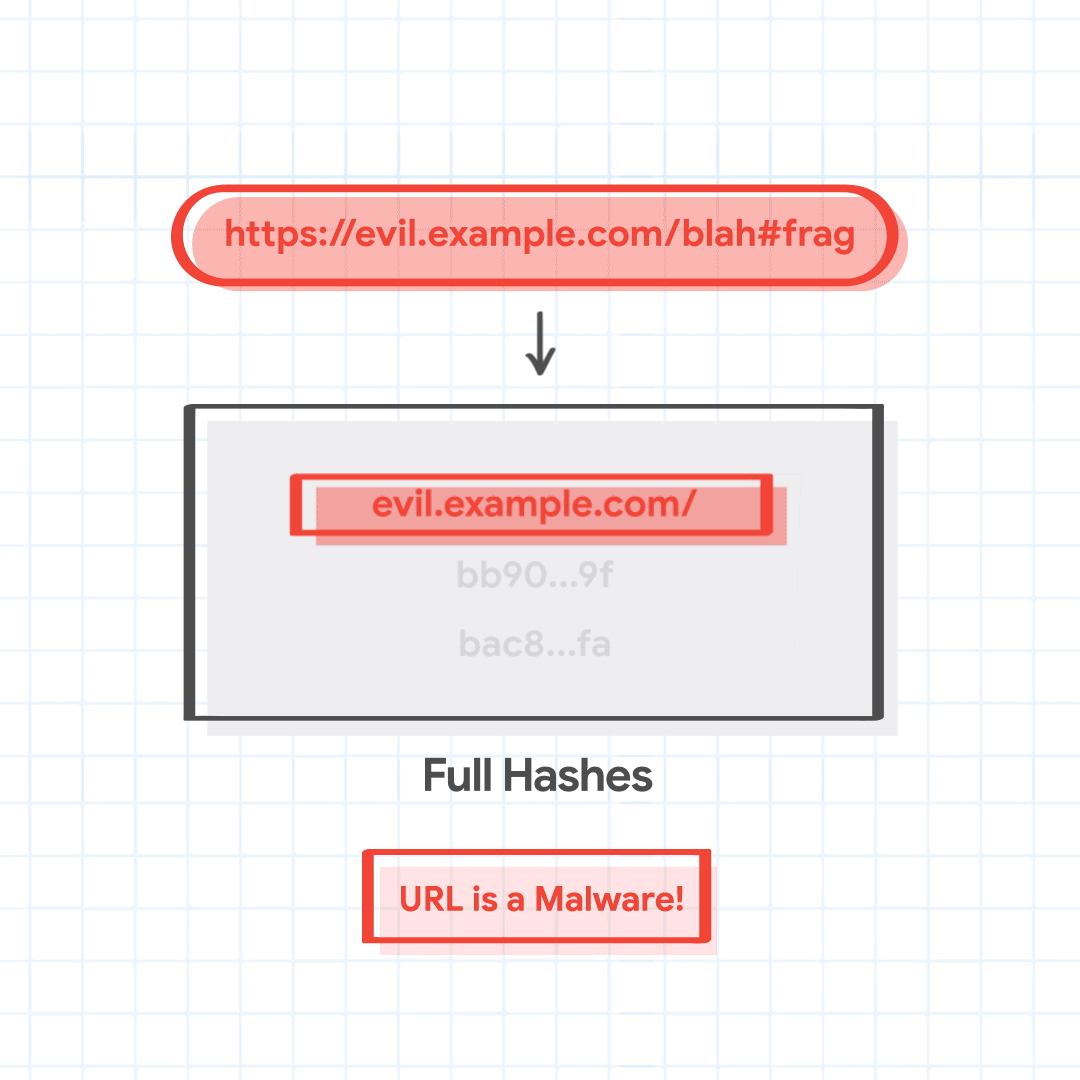Memory safety bugs are the most numerous category of Chrome security issues and we’re continuing to investigate many solutions – both in C++ and in new programming languages. The most common type of memory safety bug is the “use-after-free”. We recently posted about an exciting series of technologies designed to prevent these. Those technologies (collectively, *Scan, pronounced “star scan”) are very powerful but likely require hardware support for sufficient performance.
Today we’re going to talk about a different approach to solving the same type of bugs.
It’s hard, if not impossible, to avoid use-after-frees in a non-trivial codebase. It’s rarely a mistake by a single programmer. Instead, one programmer makes reasonable assumptions about how a bit of code will work, then a later change invalidates those assumptions. Suddenly, the data isn’t valid as long as the original programmer expected, and an exploitable bug results.
These bugs have real consequences. For example, according to Google Threat Analysis Group, a use-after-free in the ChromeHTML engine was exploited this year by North Korea.
Half of the known exploitable bugs in Chrome are use-after-frees:
Diving Deeper: Not All Use-After-Free Bugs Are Equal
Chrome has a multi-process architecture, partly to ensure that web content is isolated into a sandboxed “renderer” process where little harm can occur. An attacker therefore usually needs to find and exploit two vulnerabilities - one to achieve code execution in the renderer process, and another bug to break out of the sandbox.
The first stage is often the easier one. The attacker has lots of influence in the renderer process. It’s easy to arrange memory in a specific way, and the renderer process acts upon many different kinds of web content, giving a large “attack surface” that could potentially be exploited.
The second stage, escaping the renderer sandbox, is trickier. Attackers have two options how to do this:
We imagine the attackers squeezing through the narrow part of a funnel:
Here’s a sample of 100 recent high severity Chrome security bugs that made it to the stable channel, divided by root cause and by the process they affect.
You might notice:
As you can see, the biggest category of bugs in each process is: V8 in the renderer process (JavaScript engine logic bugs - work in progress) and use-after-free bugs in the browser process. If we can make that “thin” bit thinner still by removing some of those use-after-free bugs, we make the whole job of Chrome exploitation markedly harder.
MiraclePtr: Preventing Exploitation of Use-After-Free Bugs
This is where MiraclePtr comes in. It is a technology to prevent exploitation of use-after-free bugs. Unlike aforementioned *Scan technologies that offer a non-invasive approach to this problem, MiraclePtr relies on rewriting the codebase to use a new smart pointer type, raw_ptr<T>. There are multiple ways to implement MiraclePtr. We came up with ~10 algorithms and compared the pros and cons. After analyzing their performance overhead, memory overhead, security protection guarantees, developer ergonomics, etc., we concluded that BackupRefPtr was the most promising solution.
class A { ... }; class B { B(A* a) : a_(a) {} void doSomething() { a_->doSomething(); } raw_ptr<A> a_; // MiraclePtr }; std::unique_ptr<A> a = std::make_unique<A>(); std::unique_ptr<B> b = std::make_unique<B>(a.get()); […] a = nullptr; // The free is delayed because the MiraclePtr is still pointing to the object. b->doSomething(); // Use-after-free is neutralized.
We successfully rewrote more than 15,000 raw pointers in the Chrome codebase into raw_ptr<T>, then enabled BackupRefPtr for the browser process on Windows and Android (both 64 bit and 32 bit) in Chrome 102 Stable. We anticipate that MiraclePtr meaningfully reduces the browser process attack surface of Chrome by protecting ~50% of use-after-free issues against exploitation. We are now working on enabling BackupRefPtr in the network, utility and GPU processes, and for other platforms. In the end state, our goal is to enable BackupRefPtr on all platforms because that ensures that a given pointer is protected for all users of Chrome.
Balancing Security and Performance
There is no free lunch, however. This security protection comes at a cost, which we have carefully weighed in our decision making.
Unsurprisingly, the main cost is memory. Luckily, related investments into PartitionAlloc over the past year led to 10-25% total memory savings, depending on usage patterns and platforms. So we were able to spend some of those savings on security: MiraclePtr increased the memory usage of the browser process 4.5-6.5% on Windows and 3.5-5% on Android1, still well below their previous levels. While we were worried about quarantined memory, in practice this is a tiny fraction (0.01%) of the browser process usage. By far the bigger culprit is the additional memory needed to store the reference count. One might think that adding 4 bytes to each allocation wouldn’t be a big deal. However, there are many small allocations in Chrome, so even the 4B overhead is not negligible. PartitionAlloc also uses pre-defined bucket sizes, so this extra 4B pushes certain allocations (particularly power-of-2 sized) into a larger bucket, e.g. 4096B->5120B.
We also considered the performance cost. Adding an atomic increment/decrement on common operations such as pointer assignment has unavoidable overhead. Having excluded a number of performance-critical pointers, we drove this overhead down until we could gain back the same margin through other performance optimizations. On Windows, no statistically significant performance regressions were observed on most of our top-level performance metrics like Largest Contentful Paint, First Input Delay, etc. The only adverse change there1 is an increase of the main thread contention (~7%). On Android1, in addition to a similar increase in the main thread contention (~6%), there were small regressions in First Input Delay (~1%), Input Delay (~3%) and First Contentful Paint (~0.5%). We don't anticipate these regressions to have a noticeable impact on user experience, and are confident that they are strongly outweighed by the additional safety for our users.
We should emphasize that MiraclePtr currently protects only class/struct pointer fields, to minimize the overhead. As future work, we are exploring options to expand the pointer coverage to on-stack pointers so that we can protect against more use-after-free bugs.
Note that the primary goal of MiraclePtr is to prevent exploitation of use-after-free bugs. Although it wasn’t designed for diagnosability, it already helped us find and fix a number of bugs that were previously undetected. We have ongoing efforts to make MiraclePtr crash reports even more informative and actionable.
Continue to Provide Us Feedback
Last but not least, we’d like to encourage security researchers to continue to report issues through the Chrome Vulnerability Reward Program, even if those issues are mitigated by MiraclePtr. We still need to make MiraclePtr available to all users, collect more data on its impact through reported issues, and further refine our processes and tooling. Until that is done, we will not consider MiraclePtr when determining the severity of a bug or the reward amount.
1 Measured in Chrome 99.
Recently, OSS-Fuzz—our community fuzzing service that regularly checks 700 critical open source projects for bugs—detected a serious vulnerability (CVE-2022-3008): a bug in the TinyGLTF project that could have allowed attackers to execute malicious code in projects using TinyGLTF as a dependency.
TinyGLTF
The bug was soon patched, but the wider significance remains: OSS-Fuzz caught a trivially exploitable command injection vulnerability. This discovery shows that fuzzing, a type of testing once primarily known for detecting memory corruption vulnerabilities in C/C++ code, has considerable untapped potential to find broader classes of vulnerabilities. Though the TinyGLTF library is written in C++, this vulnerability is easily applicable to all programming languages and confirms that fuzzing is a beneficial and necessary testing method for all software projects.
OSS-Fuzz was launched in 2016 in response to the Heartbleed vulnerability, discovered in one of the most popular open source projects for encrypting web traffic. The vulnerability had the potential to affect almost every internet user, yet was caused by a relatively simple memory buffer overflow bug that could have been detected by fuzzing—that is, by running the code on randomized inputs to intentionally cause unexpected behaviors or crashes that signal bugs. At the time, though, fuzzing was not widely used and was cumbersome for developers, requiring extensive manual effort.
Google created OSS-Fuzz to fill this gap: it's a free service that runs fuzzers for open source projects and privately alerts developers to the bugs detected. Since its launch, OSS-Fuzz has become a critical service for the open source community, helping get more than 8,000 security vulnerabilities and more than 26,000 other bugs in open source projects fixed. With time, OSS-Fuzz has grown beyond C/C++ to detect problems in memory-safe languages such as Go, Rust, and Python.
Google Cloud’s Assured Open Source Software Service, which provides organizations a secure and curated set of open source dependencies, relies on OSS-Fuzz as a foundational layer of security scanning. OSS-Fuzz is also the basis for free fuzzing tools for the community, such as ClusterFuzzLite, which gives developers a streamlined way to fuzz both open source and proprietary code before committing changes to their projects. All of these efforts are part of Google’s $10B commitment to improving cybersecurity and continued work to make open source software more secure for everyone.
Last December, OSS-Fuzz announced an effort to improve our bug detectors (known as sanitizers) to find more classes of vulnerabilities, by first showing that fuzzing can find Log4Shell. The TinyGLTF bug was found using one of those new sanitizers, SystemSan, which was developed specifically to find bugs that can be exploited to execute arbitrary commands in any programming language. This vulnerability shows that it was possible to inject backticks into the input glTF file format and allow commands to be executed during parsing.
SystemSan
# Craft an input that exploits the vulnerability to insert a string to poc $ echo '{"images":[{"uri":"a`echo iamhere > poc`"}], "asset":{"version":""}}' > payload.gltf # Execute the vulnerable program with the input $ ./loader_exampler payload.gltf # The string was inserted to poc, proving the vulnerability was successfully exploited $ cat poc iamhere
A proof of exploit in TinyGLTF, extended from the input found by OSS-Fuzz with SystemSan. The culprit was the use of the “wordexp” function to expand file paths.
SystemSan uses ptrace, and is built in a language-independent and highly extensible way to allow new bug detectors to be added easily. For example, we’ve built proofs of concept to detect issues in JavaScript and Python libraries, and an external contributor recently added support for detecting arbitrary file access (e.g. through path traversal).
ptrace
OSS-Fuzz has also continued to work with Code Intelligence to improve Java fuzzing by integrating over 50 additional Java projects into OSS-Fuzz and developing sanitizers for detecting Java-specific issues such as deserialization and LDAP injection vulnerabilities. A number of these types of vulnerabilities have been found already and are pending disclosure.
Want to get involved with making fuzzing more widely used and get rewarded? There are two ways:
To apply for these rewards, see the OSS-Fuzz integration reward program.
Fuzzing still has a lot of unexplored potential in discovering more classes of vulnerabilities. Through our combined efforts we hope to take this effective testing method to the next level and enable more of the open source community to enjoy the benefits of fuzzing.
Today, we are launching Google’s Open Source Software Vulnerability Rewards Program (OSS VRP) to reward discoveries of vulnerabilities in Google’s open source projects. As the maintainer of major projects such as Golang, Angular, and Fuchsia, Google is among the largest contributors and users of open source in the world. With the addition of Google’s OSS VRP to our family of Vulnerability Reward Programs (VRPs), researchers can now be rewarded for finding bugs that could potentially impact the entire open source ecosystem.
Google has been committed to supporting security researchers and bug hunters for over a decade. The original VRP program, established to compensate and thank those who help make Google’s code more secure, was one of the first in the world and is now approaching its 12th anniversary. Over time, our VRP lineup has expanded to include programs focused on Chrome, Android, and other areas. Collectively, these programs have rewarded more than 13,000 submissions, totaling over $38M paid.
The addition of this new program addresses the ever more prevalent reality of rising supply chain compromises. Last year saw a 650% year-over-year increase in attacks targeting the open source supply chain, including headliner incidents like Codecov and the Log4j vulnerability that showed the destructive potential of a single open source vulnerability. Google's OSS VRP is part of our $10B commitment to improving cybersecurity, including securing the supply chain against these types of attacks for both Google’s users and open source consumers worldwide.
Google's OSS VRP encourages researchers to report vulnerabilities with the greatest real, and potential, impact on open source software under the Google portfolio. The program focuses on:
All up-to-date versions of open source software (including repository settings) stored in the public repositories of Google-owned GitHub organizations (eg. Google, GoogleAPIs, GoogleCloudPlatform, …).
Those projects’ third-party dependencies (with prior notification to the affected dependency required before submission to Google’s OSS VRP).
The top awards will go to vulnerabilities found in the most sensitive projects: Bazel, Angular, Golang, Protocol buffers, and Fuchsia. After the initial rollout we plan to expand this list. Be sure to check back to see what’s been added.
To focus efforts on discoveries that have the greatest impact on the supply chain, we welcome submissions of:
Vulnerabilities that lead to supply chain compromise
Design issues that cause product vulnerabilities
Other security issues such as sensitive or leaked credentials, weak passwords, or insecure installations
Depending on the severity of the vulnerability and the project’s importance, rewards will range from $100 to $31,337. The larger amounts will also go to unusual or particularly interesting vulnerabilities, so creativity is encouraged.
Before you start, please see the program rules for more information about out-of-scope projects and vulnerabilities, then get hacking and let us know what you find. If your submission is particularly unusual, we’ll reach out and work with you directly for triaging and response. In addition to a reward, you can receive public recognition for your contribution. You can also opt to donate your reward to charity at double the original amount.
Not sure whether a bug you’ve found is right for Google’s OSS VRP? Don’t worry, if needed, we’ll route your submission to a different VRP that will give you the highest possible payout. We also encourage you to check out our Patch Rewards program, which rewards security improvements to Google’s open source projects (for example, up to $20K for fuzzing integrations in OSS-Fuzz).
Google is proud to both support and be a part of the open source software community. Through our existing bug bounty programs, we’ve rewarded bug hunters from over 84 countries and look forward to increasing that number through this new VRP. The community has continuously surprised us with its creativity and determination, and we cannot wait to see what new bugs and discoveries you have in store. Together, we can help improve the security of the open source ecosystem.
Give it a try, and happy bug hunting!
Paranoid is a project to detect well-known weaknesses in large amounts of crypto artifacts, like public keys and digital signatures. On August 3rd 2022 we open sourced the library containing the checks that we implemented so far (https://github.com/google/paranoid_crypto). The library is developed and maintained by members of the Google Security Team, but it is not an officially supported Google product.
Crypto artifacts may be generated by systems with implementations unknown to us; we refer to them as “black boxes.” An artifact may be generated by a black-box if, for example, it was not generated by one of our own tools (such as Tink), or by a library that we can inspect and test using Wycheproof. Unfortunately, sometimes we end up relying on black-box generated artifacts (e.g. generated by proprietary HSMs).
After the disclosure of the ROCA vulnerability, we wondered what other weaknesses may exist in crypto artifacts generated by black boxes, and what we could do to detect and mitigate them. We then started working on this project in 2019 and created a library to perform checks against large amounts of crypto artifacts.
The library contains implementations and optimizations of existing work found in the literature. The literature shows that the generation of artifacts is flawed in some cases - below are examples of publications the library is based on.
Arjen K. Lenstra, James P. Hughes, Maxime Augier, Joppe W. Bos, Thorsten Kleinjung, and Christophe Wachter. (2012). Ron was wrong, Whit is right. Cryptology ePrint Archive, Paper 2012/064;
Nadia Heninger, Zakir Durumeric, Eric Wustrow, and J. Alex Halderman. (2012). Mining Your Ps and Qs: Detection of Widespread Weak Keys in Network Devices. USENIX Associations;
Daniel J. Bernstein, Yun-An Chang, Chen-Mou Cheng, Li-Ping Chou, Nadia Heninger, Tanja Lange, and Nicko van Someren. (2013). Factoring RSA keys from certified smart cards: Coppersmith in the wild. Cryptology ePrint Archive, Paper 2013/599;
Joachim Breitner and Nadia Heninger. (2019). Biased Nonce Sense: Lattice Attacks against Weak ECDSA Signatures in Cryptocurrencies. Cryptology ePrint Archive, Paper 2019/023.
As a recent example, CVE-2022-26320 found by Hanno Böck, confirmed the importance of checking for known weaknesses. Paranoid has already found similar weak keys independently (via the CheckFermat test). We also believe the project has potential to detect new vulnerabilities since we typically attempt to generalize detections as much as we can.
The goal of open sourcing the library is to increase transparency, allow other ecosystems to use it (such as Certificate Authorities - CAs that need to run similar checks to meet compliance), and receive contributions from external researchers. By doing so, we’re making a call for contributions, in hopes that after researchers find and report crypto vulnerabilities, the checks are added into the library. This way, Google and the rest of the world can respond quickly to new threats.
Note, the project is intended to be light in its use of computational resources. The checks must be fast enough to run against large numbers of artifacts and must make sense in real world production context. Projects with less restrictions, such as RsaCtfTool, may be more appropriate for different use cases.
In addition to contributions of new checks, improvements to those that already exist are also welcome. By analyzing the released source one can see some problems that are still open. For example, for ECDSA signatures in which the secrets are generated using java.util.random, we have a precomputed model that is able to detect this vulnerability given two signatures over secp256r1 in most cases. However, for larger curves such as secp384r1, we have not been able to precompute a model with significant success.
In addition to ECDSA signatures, we also implemented checks for RSA and EC public keys, and general (pseudo) random bit streams. For the latter, we were able to build some improvements on the NIST SP 800-22 test suite and to include additional tests using lattice reduction techniques.
Similar to other published works, we have been analyzing the crypto artifacts from Certificate Transparency (CT), which logs issued website certificates since 2013 with the goal of making them transparent and verifiable. Its database contains more than 7 billion certificates.
For the checks of EC public keys and ECDSA signatures, so far, we have not found any weak artifacts in CT. For the RSA public key checks with severities high or critical, we have the following results:
Some of these certificates were already expired or revoked. For the ones that were still active (most of the CheckGCD ones), we immediately reported them to the CAs to be revoked. Reporting weak certificates is important to keep the internet secure, as stated by the policies of the CAs. The Let's Encrypt policy, for example, is defined here. In another example, Digicert states:
Certificate revocation and certificate problem reporting are an important part of online trust. Certificate revocation is used to prevent the use of certificates with compromised private keys, reduce the threat of malicious websites, and address system-wide attacks and vulnerabilities. As a member of the online community, you play an important role in helping maintain online trust by requesting certificate revocations when needed.
We plan to continue analyzing Certificate Transparency, and now with the help of external contributions, we will continue the implementation of new checks and optimization of those existing.
We are also closely watching the NIST Post-Quantum Cryptography Standardization Process for new algorithms that make sense to implement checks. New crypto implementations carry the possibility of new bugs, and it is important that Paranoid is able to detect them.
Cover of the medieval cookbook. Title in large letters kernel Exploits. Adorned. Featuring a small penguin. 15th century. Color. High quality picture. Private collection. Detailed.
The Linux kernel is a key component for the security of the Internet. Google uses Linux in almost everything, from the computers our employees use, to the products people around the world use daily like Chromebooks, Android on phones, cars, and TVs, and workloads on Google Cloud. Because of this, we have heavily invested in Linux’s security - and today, we’re announcing how we’re building on those investments and increasing our rewards.
In 2020, we launched an open-source Kubernetes-based Capture-the-Flag (CTF) project called, kCTF. The kCTF Vulnerability Rewards Program (VRP) lets researchers connect to our Google Kubernetes Engine (GKE) instances, and if they can hack it, they get a flag, and are potentially rewarded. All of GKE and its dependencies are in scope, but every flag caught so far has been a container breakout through a Linux kernel vulnerability. We’ve learned that finding and exploiting heap memory corruption vulnerabilities in the Linux kernel could be made a lot harder. Unfortunately, security mitigations are often hard to quantify, however, we think we’ve found a way to do so concretely going forward.
When we launched kCTF, we hoped to build a community of Linux kernel exploitation hackers. This worked well and allowed the community to learn from several members of the security community like Markak, starlabs, Crusaders of Rust, d3v17, slipper@pangu, valis, kylebot, pqlqpql and Awarau.
Now, we’re making updates to the kCTF program. First, we are indefinitely extending the increased reward amounts we announced earlier this year, meaning we’ll continue to pay $20,000 - $91,337 USD for vulnerabilities on our lab kCTF deployment to reward the important work being done to understand and improve kernel security. This is in addition to our existing patch rewards for proactive security improvements.
Second, we’re launching new instances with additional rewards to evaluate the latest Linux kernel stable image as well as new experimental mitigations in a custom kernel we've built. Rather than simply learning about the current state of the stable kernels, the new instances will be used to ask the community to help us evaluate the value of both our latest and more experimental security mitigations.
Today, we are starting with a set of mitigations we believe will make most of the vulnerabilities (9/10 vulns and 10/13 exploits) we received this past year more difficult to exploit. For new exploits of vulnerabilities submitted which also compromise the latest Linux kernel, we will pay an additional $21,000 USD. For those which compromise our custom Linux kernel with our experimental mitigations, the reward will be another $21,000 USD (if they are clearly bypassing the mitigations we are testing). This brings the total rewards up to a maximum of $133,337 USD. We hope this will allow us to learn more about how hard (or easy) it is to bypass our experimental mitigations.
The mitigations we've built attempt to tackle the following exploit primitives:
Out-of-bounds write on slab
Cross-cache attacks
Elastic objects
Freelist corruption
With the kCTF VRP program, we are building a pipeline to analyze, experiment, measure and build security mitigations to make the Linux kernel as safe as we can with the help of the security community. We hope that, over time, we will be able to make security mitigations that make exploitation of Linux kernel vulnerabilities as hard as possible.
There are various threats a user faces when browsing the web. Users may be tricked into sharing sensitive information like their passwords with a misleading or fake website, also called phishing. They may also be led into installing malicious software on their machines, called malware, which can collect personal data and also hold it for ransom. Google Chrome, henceforth called Chrome, enables its users to protect themselves from such threats on the internet. When Chrome users browse the web with Safe Browsing protections, Chrome uses the Safe Browsing service from Google to identify and ward off various threats.
Safe Browsing works in different ways depending on the user's preferences. In the most common case, Chrome uses the privacy-conscious Update API (Application Programming Interface) from the Safe Browsing service. This API was developed with user privacy in mind and ensures Google gets as little information about the user's browsing history as possible. If the user has opted-in to "Enhanced Protection" (covered in an earlier post) or "Make Searches and Browsing Better", Chrome shares limited additional data with Safe Browsing only to further improve user protection.
This post describes how Chrome implements the Update API, with appropriate pointers to the technical implementation and details about the privacy-conscious aspects of the Update API. This should be useful for users to understand how Safe Browsing protects them, and for interested developers to browse through and understand the implementation. We will cover the APIs used for Enhanced Protection users in a future post.
When a user navigates to a webpage on the internet, their browser fetches objects hosted on the internet. These objects include the structure of the webpage (HTML), the styling (CSS), dynamic behavior in the browser (Javascript), images, downloads initiated by the navigation, and other webpages embedded in the main webpage. These objects, also called resources, have a web address which is called their URL (Uniform Resource Locator). Further, URLs may redirect to other URLs when being loaded. Each of these URLs can potentially host threats such as phishing websites, malware, unwanted downloads, malicious software, unfair billing practices, and more. Chrome with Safe Browsing checks all URLs, redirects or included resources, to identify such threats and protect users.
Safe Browsing provides a list for each threat it protects users against on the internet. A full catalog of lists that are used in Chrome can be found by visiting chrome://safe-browsing/#tab-db-manager on desktop platforms.
chrome://safe-browsing/#tab-db-manager
A list does not contain unsafe web addresses, also referred to as URLs, in entirety; it would be prohibitively expensive to keep all of them in a device’s limited memory. Instead it maps a URL, which can be very long, through a cryptographic hash function (SHA-256), to a unique fixed size string. This distinct fixed size string, called a hash, allows a list to be stored efficiently in limited memory. The Update API handles URLs only in the form of hashes and is also called hash-based API in this post.
Further, a list does not store hashes in entirety either, as even that would be too memory intensive. Instead, barring a case where data is not shared with Google and the list is small, it contains prefixes of the hashes. We refer to the original hash as a full hash, and a hash prefix as a partial hash.A list is updated following the Update API’s request frequency section. Chrome also follows a back-off mode in case of an unsuccessful response. These updates happen roughly every 30 minutes, following the minimum wait duration set by the server in the list update response.
For those interested in browsing relevant source code, here’s where to look:
As an example of a Safe Browsing list, let's say that we have one for malware, containing partial hashes of URLs known to host malware. These partial hashes are generally 4 bytes long, but for illustrative purposes, we show only 2 bytes.
['036b', '1a02', 'bac8', 'bb90']
Whenever Chrome needs to check the reputation of a resource with the Update API, for example when navigating to a URL, it does not share the raw URL (or any piece of it) with Safe Browsing to perform the lookup. Instead, Chrome uses full hashes of the URL (and some combinations) to look up the partial hashes in the locally maintained Safe Browsing list. Chrome sends only these matched partial hashes to the Safe Browsing service. This ensures that Chrome provides these protections while respecting the user’s privacy. This hash-based lookup happens in three steps in Chrome:
When Google blocks URLs that host potentially unsafe resources by placing them on a Safe Browsing list, the malicious actor can host the resource on a different URL. A malicious actor can cycle through various subdomains to generate new URLs. Safe Browsing uses host suffixes to identify malicious domains that host malware in their subdomains. Similarly, malicious actors can also cycle through various subpaths to generate new URLs. So Safe Browsing also uses path prefixes to identify websites that host malware at various subpaths. This prevents malicious actors from cycling through subdomains or paths for new malicious URLs, allowing robust and efficient identification of threats.
To incorporate these host suffixes and path prefixes, Chrome first computes the full hashes of the URL and some patterns derived from the URL. Following Safe Browsing API's URLs and Hashing specification, Chrome computes the full hashes of URL combinations by following these steps:
For instance, let's say that a user is trying to visit https://evil.example.com/blah#frag. The canonical url is https://evil.example.com/blah. The host suffixes to be tried are evil.example.com, and example.com. The path prefixes are / and /blah. The four combined URL combinations are evil.example.com/, evil.example.com/blah, example.com/, and example.com/blah.
https://evil.example.com/blah#frag
https://evil.example.com/blah
evil.example.com
example.com
/
/blah
evil.example.com/
evil.example.com/blah
example.com/
example.com/blah
url_combinations = ["evil.example.com/", "evil.example.com/blah","example.com/", "example.com/blah"] full_hashes = ['1a02…28', 'bb90…9f', '7a9e…67', 'bac8…fa']
Chrome then checks the full hashes of the URL combinations against the locally maintained Safe Browsing lists. These lists, which contain partial hashes, do not provide a decisive malicious verdict, but can quickly identify if the URL is considered not malicious. If the full hash of the URL does not match any of the partial hashes from the local lists, the URL is considered safe and Chrome proceeds to load it. This happens for more than 99% of the URLs checked.
Chrome finds that three full hashes 1a02…28, bb90…9f, and bac8…fa match local partial hashes. We note that this is for demonstration purposes, and a match here is rare.
1a02…28
bb90…9f
bac8…fa
Next, Chrome sends only the matching partial hash (not the full URL or any particular part of the URL, or even their full hashes), to the Safe Browsing service's fullHashes.find method. In response, it receives the full hashes of all malicious URLs for which the full hash begins with one of the partial hashes sent by Chrome. Chrome checks the fetched full hashes with the generated full hashes of the URL combinations. If any match is found, it identifies the URL with various threats and their severities inferred from the matched full hashes.
fullHashes.find
Chrome sends the matched partial hashes 1a02, bb90, and bac8 to fetch the full hashes. The server returns full hashes that match these partial hashes, 1a02…28, bb90…ce, and bac8…01. Chrome finds that one of the full hashes matches with the full hash of the URL combination being checked, and identifies the malicious URL as hosting malware.
1a02…28, bb90…ce,
bac8…01
Safe Browsing protects Chrome users from various malicious threats on the internet. While providing these protections, Chrome faces challenges such as constraints in memory capacity, network bandwidth usage, and a dynamic threat landscape. Chrome is also mindful of the users’ privacy choices, and shares little data with Google.
In a follow up post, we will cover the more advanced protections Chrome provides to its users who have opted in to “Enhanced Protection”.
Posted by Matthew Maurer and Mike Yu, Android team
To help keep Android users’ DNS queries private, Android supports encrypted DNS. In addition to existing support for DNS-over-TLS, Android now supports DNS-over-HTTP/3 which has a number of improvements over DNS-over-TLS.
Most network connections begin with a DNS lookup. While transport security may be applied to the connection itself, that DNS lookup has traditionally not been private by default: the base DNS protocol is raw UDP with no encryption. While the internet has migrated to TLS over time, DNS has a bootstrapping problem. Certificate verification relies on the domain of the other party, which requires either DNS itself, or moves the problem to DHCP (which may be maliciously controlled). This issue is mitigated by central resolvers like Google, Cloudflare, OpenDNS and Quad9, which allow devices to configure a single DNS resolver locally for every network, overriding what is offered through DHCP.
In Android 9.0, we announced the Private DNS feature, which uses DNS-over-TLS (DoT) to protect DNS queries when enabled and supported by the server. Unfortunately, DoT incurs overhead for every DNS request. An alternative encrypted DNS protocol, DNS-over-HTTPS (DoH), is rapidly gaining traction within the industry as DoH has already been deployed by most public DNS operators, including the Cloudflare Resolver and Google Public DNS. While using HTTPS alone will not reduce the overhead significantly, HTTP/3 uses QUIC, a transport that efficiently multiplexes multiple streams over UDP using a single TLS session with session resumption. All of these features are crucial to efficient operation on mobile devices.
DNS-over-HTTP/3 (DoH3) support was released as part of a Google Play system update, so by the time you’re reading this, Android devices from Android 11 onwards1 will use DoH3 instead of DoT for well-known2 DNS servers which support it. Which DNS service you are using is unaffected by this change; only the transport will be upgraded. In the future, we aim to support DDR which will allow us to dynamically select the correct configuration for any server. This feature should decrease the performance impact of encrypted DNS.
DNS-over-HTTP/3 avoids several problems that can occur with DNS-over-TLS operation:
In unreliable networks, DoH3 may even outperform traditional DNS. While unintuitive, this is because the flow control mechanisms in QUIC can alert either party that packets weren’t received. In traditional DNS, the timeout for a query needs to be based on expected time for the entire query, not just for the resolver to receive the packet.
Field measurements during the initial limited rollout of this feature show that DoH3 significantly improves on DoT’s performance. For successful queries, our studies showed that replacing DoT with DoH3 reduces median query time by 24%, and 95th percentile query time by 44%. While it might seem suspect that the reported data is conditioned on successful queries, both DoT and DoH3 resolve 97% of queries successfully, so their metrics are directly comparable. UDP resolves only 83% of queries successfully. As a result, UDP latency is not directly comparable to TLS/HTTP3 latency because non-connection-oriented protocols have a different notion of what a "query" is. We have still included it for rough comparison.
The DNS resolver processes input that could potentially be controlled by an attacker, both from the network and from apps on the device. To reduce the risk of security vulnerabilities, we chose to use a memory safe language for the implementation.
Fortunately, we’ve been adding Rust support to the Android platform. This effort is intended exactly for cases like this — system level features which need to be performant or low level (both in this case) and which would carry risk to implement in C++. While we’ve previously launched Keystore 2.0, this represents our first foray into Rust in Mainline Modules. Cloudflare maintains an HTTP/3 library called quiche, which fits our use case well, as it has a memory-safe implementation, few dependencies, and a small code size. Quiche also supports use directly from C++. We considered this, but even the request dispatching service had sufficient complexity that we chose to implement that portion in Rust as well.
We built the query engine using the Tokio async framework to simultaneously handle new requests, incoming packet events, control signals, and timers. In C++, this would likely have required multiple threads or a carefully crafted event loop. By leveraging asynchronous in Rust, this occurs on a single thread with minimal locking4. The DoH3 implementation is 1,640 lines and uses a single runtime thread. By comparison, DoT takes 1,680 lines while managing less and using up to 4 threads per DoT server in use.
With the introduction of Rust, we are able to improve both security and the performance at the same time. Likewise, QUIC allows us to improve network performance and privacy simultaneously. Finally, Mainline ensures that such improvements are able to make their way to more Android users sooner.
Special thanks to Luke Huang who greatly contributed to the development of this feature, and Lorenzo Colitti for his in-depth review of the technical aspects of this post.
Some Android 10 devices which adopted Google Play system updates early will also receive this feature. ↩
Google DNS and Cloudflare DNS at launch, others may be added in the future. ↩
DoT can be implemented in a way that avoids this problem, as the client must accept server responses out of order. However, in practice most servers do not implement this reordering. ↩
There is a lock used for the SSL context which is accessed once per DNS server, and another on the FFI when issuing a request. The FFI lock could be removed with changes to the C++ side, but has remained because it is low contention. ↩