(Note: We’ve updated this post to reflect that the API works by collecting 3.25 bytes of the hashed username)
To make this easier, Chrome introduced the Password Checkup feature in 2019, which notifies you when one of the passwords you’ve saved in Chrome is exposed. We’re now bringing this functionality to your Android apps through Autofill with Google. Whenever you fill or save credentials into an app, we’ll check those credentials against a list of known compromised credentials and alert you if your password has been compromised. The prompt can also take you to your Password Manager page, where you can do a comprehensive review of your saved passwords. Password Checkup on Android apps is available on Android 9 and above, for users of Autofill with Google.
Follow the instructions below to enable Autofill with Google on your Android device:
If you can’t find these options, check out this page with details on how to get information from your device manufacturer.
How it works
User privacy is top of mind, especially when it comes to features that handle sensitive data such as passwords. Autofill with Google is built on the Android autofill framework which enforces strict privacy & security invariants that ensure that we have access to the user’s credentials only in the following two cases: 1) the user has already saved said credential to their Google account; 2) the user was offered to save a new credential by the Android OS and chose to save it to their account.
When the user interacts with a credential by either filling it into a form or saving it for the first time, we use the same privacy preserving API that powers the feature in Chrome to check if the credential is part of the list of known compromised passwords tracked by Google.
This implementation ensures that:
For more information on how this API is built under the hood, check out this blog from the Chrome team.
Additional security features
In addition to Password Checkup, Autofill with Google offers other features to help you keep your data secure:
As always, stay tuned to the Google Security blog to keep up to date on the latest ways we’re improving security across our products.
Memory-safety vulnerabilities have dominated the security field for years and often lead to issues that can be exploited to take over entire systems.
A recent study found that "~70% of the vulnerabilities addressed through a security update each year continue to be memory safety issues.” Another analysis on security issues in the ubiquitous `curl` command line tool showed that 53 out of 95 bugs would have been completely prevented by using a memory-safe language.
Software written in unsafe languages often contains hard-to-catch bugs that can result in severe security vulnerabilities, and we take these issues seriously at Google. That’s why we’re expanding our collaboration with the Internet Security Research Group to support the reimplementation of critical open-source software in memory-safe languages. We previously worked with the ISRG to help secure the Internet by making TLS certificates available to everyone for free, and we're looking forward to continuing to work together on this new initiative.
It's time to start taking advantage of memory-safe programming languages that prevent these errors from being introduced. At Google, we understand the value of the open source community and in giving back to support a strong ecosystem.
To date, our free OSS-Fuzz service has found over 5,500 vulnerabilities across 375 open source projects caused by memory safety errors, and our Rewards Program helps encourage adoption of fuzzing through financial incentives. We've also released other projects like Syzkaller to detect bugs in operating system kernels, and sandboxes like gVisor to reduce the impact of bugs when they are found.
The ISRG's approach of working directly with maintainers to support rewriting tools and libraries incrementally falls directly in line with our perspective here at Google.
The new Rust-based HTTP and TLS backends for curl and now this new TLS library for Apache httpd are an important starting point in this overall effort. These codebases sit at the gateway to the internet and their security is critical in the protection of data for millions of users worldwide.
We'd like to thank the maintainers of these projects for working on such widely-used and important infrastructure, and for participating in this effort.
We're happy to be able to support these communities and the ISRG to make the Internet a safer place. We appreciate their leadership in this area and we look forward to expanding this program in 2021.
Open source security is a collaborative effort. If you're interested in learning more about our efforts, please join us in the Securing Critical Projects Working Group of the Open Source Security Foundation.
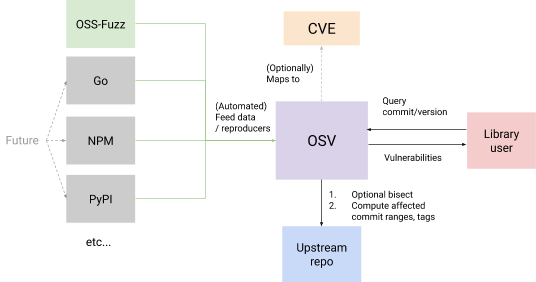
We are excited to launch OSV (Open Source Vulnerabilities), our first step towards improving vulnerability triage for developers and consumers of open source software. The goal of OSV is to provide precise data on where a vulnerability was introduced and where it got fixed, thereby helping consumers of open source software accurately identify if they are impacted and then make security fixes as quickly as possible. We have started OSV with a data set of fuzzing vulnerabilities found by the OSS-Fuzz service. OSV project evolved from our recent efforts to improve vulnerability management in open source ("Know, Prevent, Fix" framework).
Vulnerability management can be painful for both consumers and maintainers of open source software, with tedious manual work involved in many cases.
For consumers of open source software, it is often difficult to map a vulnerability such as a Common Vulnerabilities and Exposures (CVE) entry to the package versions they are using. This comes from the fact that versioning schemes in existing vulnerability standards (such as Common Platform Enumeration (CPE)) do not map well with the actual open source versioning schemes, which are typically versions/tags and commit hashes. The result is missed vulnerabilities that affect downstream consumers.
Similarly, it is time consuming for maintainers to determine an accurate list of affected versions or commits across all their branches for downstream consumers after a vulnerability is fixed, in addition to the process required for publication. Unfortunately, many open source projects, including ones that are critical to modern infrastructure, are under resourced and overworked. Maintainers don't always have the bandwidth to create and publish thorough, accurate information about their vulnerabilities even if they want to.
These challenges result in open source consumers not incorporating important security fixes promptly. OSV aims to:
Reduce the work required by maintainers to publish vulnerabilities, and
Improve the accuracy of vulnerability queries for downstream consumers by providing precise vulnerability metadata in an easy-to-query database (complementing existing vulnerability databases).
OSV aims to simplify the vulnerability reporting process for an open source package maintainer by accurately determining the list of affected versions and commits. This requires providing both the commits that introduce and fix the bugs. If that information is not available, OSV requires providing a reproduction test case and steps to generate an application build, and then it performs bisection to find these commits in an automated fashion. OSV takes care of the rest of the analysis to figure out impacted commit ranges (accounting for cherry picks) and versions/tags.
How OSV works
OSV automates the triage workflow for an open source package consumer by providing an API to query for vulnerabilities. A typical OSV workflow for a package consumer looks like the picture above:
A package consumer sends a query to OSV with a package version or commit hash as input.
curl -X POST -d \
'{"commit": "6879efc2c1596d11a6a6ad296f80063b558d5e0f"}' \
'https://api.osv.dev/v1/query?key=$API_KEY'
'{"version": "1.0.0", "package": {"name": "pkg", "ecosystem": "pypi"}' \
OSV looks up the set of vulnerabilities affecting that particular version and returns a list of vulnerabilities impacting the package. The vulnerability metadata is returned in a machine-readable JSON format.
The package consumer uses this information to either cherry-pick security fixes (based on precise fix metadata) or update to a later version.
OSV currently provides access to thousands of vulnerabilities from 380+ critical OSS projects integrated with OSS-Fuzz. We are planning to work with open source communities to extend with data from various language ecosystems (e.g. NPM, PyPI) and work out a pipeline for package maintainers to submit vulnerabilities with minimal work.
Our goal with OSV is to rethink and promote better, scalable vulnerability tracking for open source. In an ideal world, vulnerability management should be done closer to the actual open source development process, aided by automated infrastructure. Projects that depend on open source should be promptly notified and fixes uptaken quickly when a vulnerability is reported.
Despite the challenges of this unprecedented year, our vulnerability researchers have achieved more than ever before, partnering with our Vulnerability Reward Programs (VRPs) to protect Google’s users by discovering security and abuse bugs and reporting them to us for remediation. Their diligence helps us keep our users, and the internet at large, safe, and enables us to fix security issues before they can be exploited.
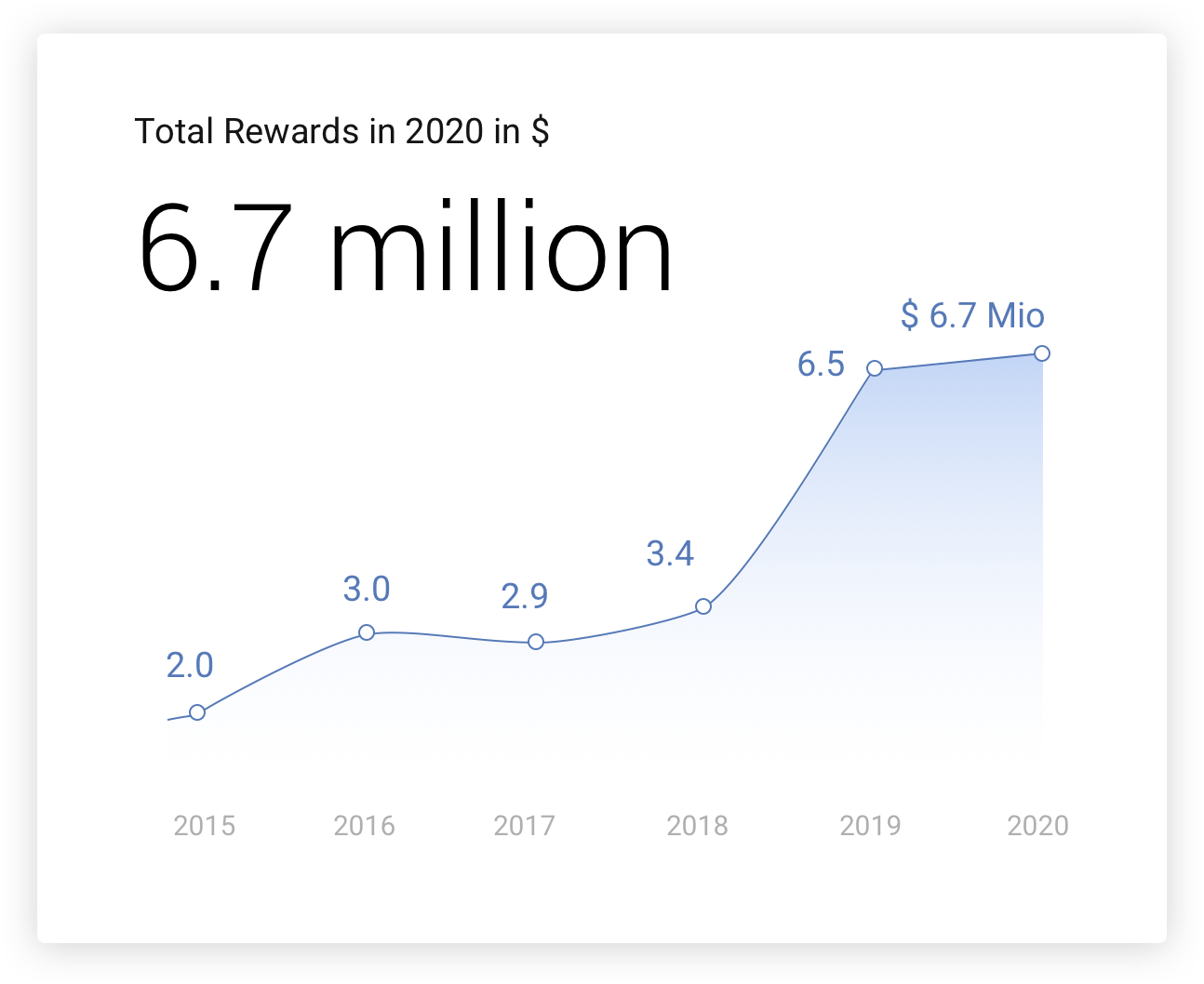
The incredibly hard work, dedication, and expertise of our researchers in 2020 resulted in a record-breaking payout of over $6.7 million in rewards, with an additional $280,000 given to charity. We’d like to extend a big thank you to our community of researchers for collaborating with us. It’s your excellent work that brings our programs to life, so we wanted to take a moment to look back on last year’s successes.
Our rewards programs span several Google product areas, including Chrome, Android, and the Google Play Store. As in past years, we are sharing our 2020 Year in Review statistics across all of these programs.
Android
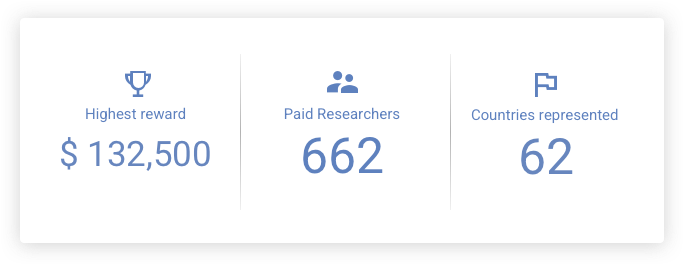
2020 was a fantastic year for the Android VRP, and in response to the valiant efforts of multiple teams of researchers, we paid out $1.74M in rewards. Following our increase in exploit payouts in November 2019, we received a record 13 working exploit submissions in 2020, representing over $1M in exploit reward payouts. Some highlights include:
In addition, we launched a number of pilot rewards programs to guide security researchers toward additional areas of interest, including Android Auto OS, writing fuzzers for Android code, and a reward program for Android chipsets. And in 2021, we'll be working on additional improvements and exciting initiatives related to our programs.
Chrome
Chrome has also seen a record year of VRP payouts! We increased our reward amounts in July 2019, and as a result, 2020 has seen us pay out 83% more than 2019, totalling $2.1M across 300 bugs.
In 2019, 14% of our payouts were for V8 bugs. This decreased to just 6% in 2020. At the end of 2020, we announced a further bonus reward for clearly exploitable V8 bugs, so we expect to see this amount increase again in 2021.
Google Play
It’s been another stellar year for the Google Play Security Rewards Program! This year, we expanded the criteria for qualifying Android apps to include apps utilizing the Exposure Notification API and performing contact tracing to help combat Covid-19. We also increased our maximum bounty award amount to $20,000 for qualifying vulnerabilities.
In 2020, the Google Play Security Rewards Program and Developer Data Protection Reward Program awarded over $270,000 to Android researchers around the world.
Abuse Program
Beyond typical security vulnerabilities, we remain interested in research focused on abuse-related risks.
The Abuse program released an official definition describing what an abuse risk is and how abuse-related reports are assessed. We also announced increased rewards for reports focused on abuse-related methodologies. These efforts led to a huge spike of abuse-related reports. In fact, we received more than twice as many reports in 2020 as in 2019, a level of growth we’ve never seen before. The fantastic work of our researchers in 2020 allowed us to identify and fix over 100 issues across more than 60 different products.
Research Grants
Besides reward payouts, in 2020 we also awarded over $400,000 in grants to more than 180 security researchers around the world, which is a record for this program. More than a third of these grants were awarded in response to the Covid-19 crisis, to extend our support to researchers and enable them to continue with their work. Our researchers got back to us with over 200 reports which resulted in more than 100 identified vulnerabilities.
"The point is, the value of these research grants is not $1337, $500 or $5000 etc. It is priceless!" – Research Grantee
Looking Forward
Finally, because of the ongoing Covid-19 pandemic and related restrictions on travel last year, we couldn’t keep our tradition of meeting our bug hunters in person and organizing events like ESCAL8, where we can engage with our incredible community of researchers. Like everyone else, we are full of hope that 2021 will allow us to meet in person again, and celebrate the 10 year VRP anniversary and the fantastic work our researchers have contributed during this time.
We look forward to another year of working with our security researchers to make Google, Android, Chrome and the Google Play Store safer for everyone. Follow us on @GoogleVRP to keep tabs on the latest.
Thank you to Mike Antares, Adam Bacchus, Dirk Göhmann, Amy Ressler, Martin Straka, Adrian Taylor and Jan Keller for their contributions to this post.
Executive Summary:
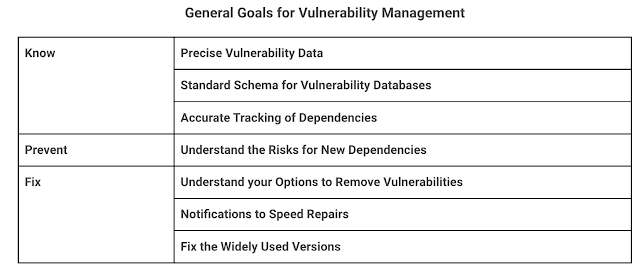
The security of open source software has rightfully garnered the industry’s attention, but solutions require consensus about the challenges and cooperation in the execution. The problem is complex and there are many facets to cover: supply chain, dependency management, identity, and build pipelines. Solutions come faster when the problem is well-framed; we propose a framework (“Know, Prevent, Fix”) for how the industry can think about vulnerabilities in open source and concrete areas to address first, including:
The following framework and goals are proposed with the intention of sparking industry-wide discussion and progress on the security of open source software.
Due to recent events, the software world gained a deeper understanding about the real risk of supply-chain attacks. Open source software should be less risky on the security front, as all of the code and dependencies are in the open and available for inspection and verification. And while that is generally true, it assumes people are actually looking. With so many dependencies, it is impractical to monitor them all, and many open source packages are not well maintained.
It is common for a program to depend, directly or indirectly, on thousands of packages and libraries. For example, Kubernetes now depends on about 1,000 packages. Open source likely makes more use of dependencies than closed source, and from a wider range of suppliers; the number of distinct entities that need to be trusted can be very high. This makes it extremely difficult to understand how open source is used in products and what vulnerabilities might be relevant. There is also no assurance that what is built matches the source code.
Taking a step back, although supply-chain attacks are a risk, the vast majority of vulnerabilities are mundane and unintentional—honest errors made by well-intentioned developers. Furthermore, bad actors are more likely to exploit known vulnerabilities than to find their own: it’s just easier. As such, we must focus on making fundamental changes to address the majority of vulnerabilities, as doing so will move the entire industry far along in addressing the complex cases as well, including supply-chain attacks.
Few organizations can verify all of the packages they use, let alone all of the updates to those packages. In the current landscape, tracking these packages takes a non-trivial amount of infrastructure, and significant manual effort. At Google, we have those resources and go to extraordinary lengths to manage the open source packages we use—including keeping a private repo of all open source packages we use internally—and it is still challenging to track all of the updates. The sheer flow of updates is daunting. A core part of any solution will be more automation, and this will be a key theme for our open source security work in 2021 and beyond.
Because this is a complex problem that needs industry cooperation, our purpose here is to focus the conversation around concrete goals. Google co-founded the OpenSSF to be a focal point for this collaboration, but to make progress, we need participation across the industry, and agreement on what the problems are and how we might address them. To get the discussion started, we present one way to frame this problem, and a set of concrete goals that we hope will accelerate industry-wide solutions.
We suggest framing the challenge as three largely independent problem areas, each with concrete objectives:
A related but separate problem, which is critical to securing the supply chain, is improving the security of the development process. We’ve outlined the challenges of this problem and proposed goals in the fourth section, Prevention for Critical Software.
Knowing your vulnerabilities is harder than expected for many reasons. Although there are mechanisms for reporting vulnerabilities, it is hard to know if they actually affect the specific versions of software you are using.
Goal: Precise Vulnerability Data
First, it is crucial to capture precise vulnerability metadata from all available data sources. For example, knowing which version introduced a vulnerability helps determine if one's software is affected, and knowing when it was fixed results in accurate and timely patching (and a reduced window for potential exploitation). Ideally, this triaging workflow should be automated.
Second, most vulnerabilities are in your dependencies, rather than the code you write or control directly. Thus, even when your code is not changing, there can be a constant churn in your vulnerabilities: some get fixed and others get added.1
Goal: Standard Schema for Vulnerability Databases
Infrastructure and industry standards are needed to track and maintain open source vulnerabilities, understand their consequences, and manage their mitigations. A standard vulnerability schema would allow common tools to work across multiple vulnerability databases and simplify the task of tracking, especially when vulnerabilities touch multiple languages or subsystems.
Goal: Accurate Tracking of Dependencies
Better tooling is needed to understand quickly what software is affected by a newly discovered vulnerability, a problem made harder by the scale and dynamic nature of large dependency trees. Current practices also often make it difficult to predict exactly what versions are used without actually doing an installation, as the software for version resolution is only available through the installer.
It would be ideal to prevent vulnerabilities from ever being created, and although testing and analysis tools can help, prevention will always be a hard problem. Here we focus on two specific aspects:
Goal: Understand the Risks for New Dependencies
The first category is essentially knowing about vulnerabilities at the time you decide to use a package. Taking on a new dependency has inherent risk and it needs to be an informed decision. Once you have a dependency, it generally becomes harder to remove over time.
Knowing about vulnerabilities is a great start, but there is more that we can do.
Many vulnerabilities arise from lack of adherence to security best practices in software development processes. Are all contributors using two-factor authentication (2FA)? Does the project have continuous integration set up and running tests? Is fuzzing integrated? These are the types of security checks that would help consumers understand the risks they’re taking on with new dependencies. Packages with a low “score” warrant a closer review, and a plan for remediation.
The recently announced Security Scorecards project from OpenSSF attempts to generate these data points in a fully automated way. Using scorecards can also help defend against prevalent typosquatting attacks (malevolent packages with names similar to popular packages), since they would score much lower and fail many security checks.
Improving the development processes for critical software is related to vulnerability prevention, but deserves its own discussion further down in our post.
The general problem of fixing vulnerabilities is beyond our scope, but there is much we can do for the specific problem of managing vulnerabilities in software dependencies. Today there is little help on this front, but as we improve precision it becomes worthwhile to invest in new processes and tooling.
One option of course is to fix the vulnerability directly. If you can do this in a backwards-compatible way, then the fix is available for everyone. But a challenge is that you are unlikely to have expertise on the problem, nor the direct ability to make changes. Fixing a vulnerability also assumes the software maintainers are aware of the issue, and have the knowledge and resources for vulnerability disclosure.
Conversely, if you simply remove the dependency that contains the vulnerability, then it is fixed for you and those that import or use your software, but not for anyone else. This is a change that is under your direct control.
These scenarios represent the two ends of the chain of dependencies between your software and the vulnerability, but in practice there can be many intervening packages. The general hope is that someone along that dependency chain will fix it. Unfortunately, fixing a link is not enough: Every link of the dependency chain between you and the vulnerability needs to be updated before your software will be fixed. Each link must include the fixed version of the thing below it to purge the vulnerability. Thus, the updates need to be done from the bottom up, unless you can eliminate the dependency altogether, which may require similar heroics and is rarely possible—but is the best solution when it is.
Goal: Understand your Options to Remove Vulnerabilities
Today, we lack clarity on this process: what progress has been made by others and what upgrades should be applied at what level? And where is the process stuck? Who is responsible for fixing the vulnerability itself? Who is responsible for propagating the fix?
Goal: Notifications to Speed Repairs
Eventually, your dependencies will be fixed and you can locally upgrade to the new versions. Knowing when this happens is an important goal as it accelerates reducing the exposure to vulnerabilities. We also need a notification system for the actual discovery of vulnerabilities; often new vulnerabilities represent latent problems that are newly discovered even though the actual code has not changed (such as this 10-year old vulnerability in the Unix utility sudo). For large projects, most such issues will arise in the indirect dependencies. Today, we lack the precision required to do notification well, but as we improve vulnerability precision and metadata (as above), we should also drive notification.
So far, we have only described the easy case: a sequence of upgrades that are all backwards compatible, implying that the behavior is the same except for the absence of the vulnerability.
In practice, an upgrade is often not backward compatible, or is blocked by restrictive version requirements. These issues mean that updating a package deep in the dependency tree must cause some churn, or at least requirement updates, in the things above it. The situation often arises when the fix is made to the latest version, say 1.3, but your software or intervening packages request 1.2. We see this situation often, and it remains a big challenge that is made even harder by the difficulty of getting owners to update intervening packages. Moreover, if you use a package in a thousand places, which is not crazy for a big enterprise, you might need to go through the update process a thousand times.
Goal: Fix the Widely Used Versions
It’s also important to fix the vulnerability in the older versions, especially those in heavy use. Such repair is common practice for the subset of software that has long-term support, but ideally all widely used versions should be fixed, especially for security risks.
Automation could help: given a fix for one version, perhaps we can generate good candidate fixes for other versions. This process is sometimes done by hand today, but if we can make it significantly easier, more versions will actually get patched, and there will be less work to do higher in the chain.
To summarize, we need ways to make fixing vulnerabilities, especially in dependencies, both easier and more timely. We need to increase the chance that there is a fix for widely used versions and not just for the latest version, which is often hard to adopt due to the other changes it includes.
Finally, there are many other options on the “fixing” front, including various kinds of mitigations, such as avoiding certain methods, or limiting risk through sandboxes or access controls. These are important practical options that need more discussion and support.
The framing above applies broadly to vulnerabilities, regardless of whether they are due to bad actors or are merely innocent mistakes. Although the suggested goals cover most vulnerabilities, they are not sufficient to prevent malicious behavior. To have a meaningful impact on prevention for bad actors, including supply-chain attacks, we need to improve the processes used for development.
This is a big task, and currently unrealistic for the majority of open source. Part of the beauty of open source is its lack of constraints on the process, which encourages a wide range of contributors. However, that flexibility can hinder security considerations. We want contributors, but we cannot expect everyone to be equally focused on security. Instead, we must identify critical packages and protect them. Such critical packages must be held to a range of higher development standards, even though that might add developer friction.
Goal: Define Criteria for “Critical” Open Source Projects that Merit Higher Standards
It is important to identify the “critical” packages that we all depend upon and whose compromise would endanger critical infrastructure or user privacy. These packages need to be held to higher standards, some of which we outline below.
It is not obvious how to define “critical” and the definition will likely expand over time. Beyond obvious software, such as OpenSSL or key cryptographic libraries, there are widely used packages where their sheer reach makes them worth protecting. We started the Criticality Score project to brainstorm this problem with the community, as well collaborating with Harvard on the Open Source Census efforts.
Goal: No Unilateral Changes to Critical Software
One principle that we follow across Google is that changes should not be unilateral—that is, every change involves at least an author and a reviewer or approver. The goal is to limit what an adversary can do on their own—we need to make sure someone is actually looking at the changes. To do this well for open source is actually quite a bit harder than just within a single company, which can have strong authentication and enforce code reviews and other checks.
Avoiding unilateral changes can be broken down into two sub-goals:
Goal: Require Code Review for Critical Software
Besides being a great process for improving code, reviews ensure that at least one person other than the author is looking at every change. Code reviews are a standard practice for all changes within Google.
Goal: Changes to Critical Software Require Approval by Two Independent Parties
To really achieve the “someone is looking” goal, we need the reviewer to be independent from the contributor. And for critical changes, we probably want more than one independent review. We need to sort out what counts as “independent” review, of course, but the idea of independence is fundamental to reviews in most industries.
Goal: Authentication for Participants in Critical Software
Any notion of independence also implies that you know the actors—an anonymous actor cannot be assumed to be independent or trustworthy. Today, we essentially have pseudonyms: the same person uses an identity repeatedly and thus can have a reputation, but we don’t always know the individual’s trustworthiness. This leads to a range of subgoals:
Goal: For Critical Software, Owners and Maintainers Cannot be Anonymous
Attackers like to have anonymity. There have been past supply-chain attacks where attackers capitalized on anonymity and worked their way through package communities to become maintainers, without anyone realizing this “new maintainer” had malicious intent (compromising source code was eventually injected upstream). To mitigate this risk, our view is that owners and maintainers of critical software must not be anonymous.
It is conceivable that contributors, unlike owners and maintainers, could be anonymous, but only if their code has passed multiple reviews by trusted parties.
It is also conceivable that we could have “verified” identities, in which a trusted entity knows the real identity, but for privacy reasons the public does not. This would enable decisions about independence as well as prosecution for illegal behavior.
Goal: Strong Authentication for Contributors of Critical Software
Malicious actors look for easy attack vectors, so phishing attacks and other forms of theft related to credentials are common. One obvious improvement would be the required use of two-factor authentication, especially for owners and maintainers.
Goal: A Federated Model for Identities
To continue the inclusive nature of open source, we need to be able to trust a wide range of identities, but still with verified integrity. This implies a federated model for identities, perhaps similar to how we support federated SSL certificates today—a range of groups can generate valid certificates, but with strong auditing and mutual oversight.
Discussions on this topic are starting to take place in the OpenSSF’s Digital Identity Attestation Working Group.
Goal: Notification for Changes in Risk
We should extend notifications to cover changes in risk. The most obvious is ownership changes, which can be a prelude to new attacks (such as the recent NPM event-stream compromise). Other examples include discovery of stolen credentials, collusion, or other bad actor behavior.
Goal: Transparency for Artifacts
It is common to use secure hashes to detect if an artifact has arrived intact, and digital signatures to prove authenticity. Adding “transparency” means that these attestations are logged publicly and thus document what was intended. In turn, external parties can monitor the logs for fake versions even if users are unaware. Going a step further, when credentials are stolen, we can know what artifacts were signed using those credentials and work to remove them. This kind of transparency, including the durable public logs and the third-party monitoring, has been used to great success for SSL certificates, and we have proposed one way to do this for package managers. Knowing you have the right package or binary is similar to knowing you are visiting the real version of a web site.
Goal: Trust the Build Process
Ken Thompson's Turing Award lecture famously demonstrated in 1984 that authentic source code alone is not enough, and recent events have shown this attack is a real threat. How do you trust your build system? All the components of it must be trusted and verified through a continuous process of building trust.
Reproducible builds help—there is a deterministic outcome for the build and we can thus verify that we got it right—but are harder to achieve due to ephemeral data (such as timestamps) ending up in the release artifact. And safe reproducible builds require verification tools, which in turn must be built verifiably and reproducibly, and so on. We must construct a network of trusted tools and build products.
Trust in both the artifacts and the tools can be established via “delegation”, through a variant of the transparency process described above called binary authorization. Internally, the Google build system signs all artifacts and produces a manifest that ties it to the source code. For open source, one or more trusted agents could run the build as a service, signing the artifact to prove that they are accountable for its integrity. This kind of ecosystem should exist and mostly needs awareness and some agreements on the format of attestations, so that we can automate the processes securely.
The actions in this section are great for software in general, and are essentially in use today within Google, but they are heavier weight than usual for open source. Our hope is that by focusing on the subset of software that is critical, we can achieve these goals at least for that set. As the tooling and automation get better, these goals will become easier to adopt more widely.
The nature of open source requires that we solve problems through consensus and collaboration. For complex topics such as vulnerabilities, this implies focused discussion around the key issues. We presented one way to frame this discussion, and defined a set of goals that we hope will accelerate industry-wide discourse and the ultimate solutions. The first set of goals apply broadly to vulnerabilities and are really about enabling automation and reducing risk and toil.
However, these goals are not enough in the presence of adversaries or to prevent “supply chain” attacks. Thus we propose a second set of goals for critical software. The second set is more onerous and therefore will meet some resistance, but we believe the extra constraints are fundamental for security. The intention is to define collectively the set of “critical” software packages, and apply these higher standards only to this set.
Ideally, depended-upon versions should be stable absent an explicit upgrade, but behavior varies depending on the packaging system. Two that aim for stability rather than fast upgrades are Go Modules and NuGet, both of which by default install upgrades only when the requirements are updated; the dependencies might be wrong, but they only change with explicit updates. ↩