The GNOME Project is proud to announce the release of GNOME 47, ‘Denver’.
This release brings support for customizable Accent Colors, improved support for small screens, persistent remote sessions, and new-style dialog windows. Like many other core apps, Files has received improvements and now also used for file open and save dialogs. Once again, a whole slew of new apps have joined the GNOME Circle initiative: find GNOME apps for anything from currency conversion to resource monitoring.
To learn more about the changes in GNOME 47 you can read the release notes:
GNOME 47 will be available shortly in many distributions, such as Fedora 41 and Ubuntu 24.10. If you want to try it today, you can look for their beta releases, which will be available very soon:
We are also providing our own installer images for debugging and testing features. These images are meant for installation in a vm and require GNOME Boxes with UEFI support. We suggest getting Boxes from Flathub.
This six-month effort wouldn’t have been possible without the whole GNOME community, made of contributors and friends from all around the world: developers, designers, documentation writers, usability and accessibility specialists, translators, maintainers, students, system administrators, companies, artists, testers, the local GUADEC team in Denver, and last, but not least, our users.
GNOME would not exist without all of you. Thank you to everyone!
We hope to see some of you at GNOME Asia 2024 in Bengaluru, India!
Our next release, GNOME 48, is planned for March 2025. Until then, enjoy GNOME 47.
Greetings, gentle readers. Today, an update on recent progress in the
Whippet embeddable garbage
collection library.
feature-completeness
When I started working on Whippet, two and a half years ago already, I
was aiming to make a new garbage collector for
Guile. In the beginning I was just
focussing on proving that it would be advantageous to switch, and also
learning how to write a GC. I put off features like
ephemerons and heap
resizing
until I was satisfied with the basics.
Well now is the time: with recent development, Whippet is finally
feature-complete! Huzzah! Now it’s time to actually work on getting it
into Guile. (I have some performance noodling to do before then, adding
tracing support, and of course I have lots of ideas for different
collectors to build, but I don’t have any missing features at the
current time.)
heap resizing
When you benchmark a garbage collector (or a program with garbage
collection), you generally want to fix the heap size. GC overhead goes
down with more memory, generally speaking, so you don’t want to compare
one collector at one size to another collector at another size.
(Unfortunately, many (most?) benchmarks of dynamic language run-times
and the programs that run on them fall into this trap. Imagine you are
benchmarking a program before and after a change. Automatic heap sizing
is on. Before your change the heap size is 200 MB, but after it is 180
MB. The benchmark shows the change to regress performance. But did it
really? It could be that at the same heap size, the change improved
performance. You won’t know unless you fix the heap size.)
Anyway, Whippet now has an implementation of
MemBalancer.
After every GC, we measure the live size of the heap, and compute a new
GC speed, as a constant factor to live heap size. Every second, in a
background thread, we observe the global allocation rate. The heap size
is then the live data size plus the square root of the live data size
times a factor. The factor has two components. One is constant, the
expansiveness of the heap: the higher it is, the more room the program
has. The other depends on the program, and is computed as the square
root of the ratio of allocation speed to collection speed.
With MemBalancer, the heap ends up getting resized at every GC, and via
the heartbeat thread. During the GC it’s easy because it’s within the
pause; no mutators are running. From the heartbeat thread, mutators are
active: taking the heap lock prevents concurrent resizes, but mutators
are still consuming empty blocks and producing full blocks. This works
out fine in the same way that concurrent mutators is fine: shrinking
takes blocks from the empty list one by one, atomically, and returns
them to the OS. Expanding might reclaim paged-out blocks, or allocate
new slabs of blocks.
However, even with some exponentially weighted averaging on the speed
observations, I have a hard time understanding whether the algorithm is
overall a good thing. I like the heartbeat thread, as it can reduce
memory use of idle processes. The general square-root idea sounds nice
enough. But adjusting the heap size at every GC feels like giving
control of your stereo’s volume knob to a hyperactive squirrel.
Figure 5 from the MemBalancer paper
Furthermore, the graphs in the MemBalancer
paper are not clear to me: the paper
claims more optimal memory use even in a single-heap configuration, but
the x axis of the graphs is “average heap size”, which I understand to
mean that maximum heap size could be higher than V8’s maximum heap size,
taking into account more frequent heap size adjustments. Also, some
measurement of total time would have been welcome, in addition to the
“garbage collection time” on the paper’s y axis; there are cases where
less pause time doesn’t necessarily correlate to better total times.
deferred page-out
Motivated by MemBalancer’s jittery squirrel, I implemented a little
queue for use in paging blocks in and out, for the
mmc
and
pcc
collectors: blocks are quarantined for a second or two before being
returned to the OS via madvise(MADV_DONTNEED). That way if you
release a page and then need to reacquire it again, you can do so
without bothering the kernel or other threads. Does it matter? It
seems to improve things marginally and conventional wisdom says to not
mess with the page table too much, but who knows.
mmc rename
Relatedly, Whippet used to be three things: the project itself,
consisting of an API and a collection of collectors; one specific
collector; and one specific space within that collector. Last time I
mentioned that I renamed the whippet space to the nofl
space.
Now I finally got around to renaming what was the whippet collector as
well: it is now the mostly-marking collector, or
mmc.
Be it known!
Also as a service note, I removed the “serial copying collector”
(scc). It had the same performance as the parallel copying collector
with parallelism=1, and pcc can be compiled with GC_PARALLEL=0 to
explicitly choose the simpler serial grey-object worklist.
per-object pinning
The nofl space has always supported pinned objects, but it was never
exposed in the API. Now it is!
Of course, collectors with always-copying spaces won’t be able to pin
objects. If we want to support use of these collectors with embedders
that require pinning, perhaps because of conservative root scanning,
we’d need to switch to some kind of mostly-copying
algorithm.
safepoints without allocation
Another missing feature was a safepoint API. It hasn’t been needed up
to now because my benchmarks all allocate, but for programs that have
long (tens of microseconds maybe) active periods without allocation, you
want to be able to stop them without waiting too long. Well we have
that exposed in the API now.
removed ragged stop
Following on my article on ragged
stops,
I removed ragged-stop marking from mmc, for a nice net 180 line
reduction
in some gnarly code. Speed seems to be similar.
next up: tracing
And with that, I’m relieved to move on to the next phase of Whippet
development. Thanks again to NLnet
for their support of this work. Next up, adding fine-grained tracing,
so that I can noodle a bit on performance. Happy allocating!
I mentioned in my last status update post that I had just received a Fairphone 5. Here are my thoughts on it after a month of use.
The predecessor
For the last 4 years I’ve been using this as my main phone, the Oukitel WP5:
The WP5 was quite a device in 2020: for the retail price of 100€, I got a clean, up-to-date Android 10 OS, a battery that lasts a full week, and a metal case which allows the phone to double as a small battering ram.
However, taking a cue from the mainstream phone manufacturers, Oukitel never updated the OS beyond Android 10, making it a laughably insecure place to install bank apps these days. Also, in the last 4 years many Android teams somehow made their apps less efficient, so things that ran fine in 2020 are now frustratingly slow on the WP5.
The newcomer
When I was checking out the Fairphone 5 I saw various reviews and comments criticizing the camera and the loudspeaker. Having now used the phone for a month, I can guess that those commentators were not comparing the camera and loudspeaker against those on the Oukitel WP5, whose loudspeaker sounds like two bees buzzing around in a bucket.
For a mid range smartphone, the camera is excellent and the speaker sounds perfectly fine as well.
What’s good about the Fairphone 5?
After a month of regular use, I have no major complaints at all, everything about the phone is pretty good.
The battery lasts about two days under normal use, which is good enough for me. I deactivate location services unless actually navigating somewhere, which helps to save power (and avoids Google tracking my location all day). Fairphone’s own sales pitch claims one day of battery life but perhaps they tested with the GPS activated. The battery is actually swappable, unlike pretty much any other modern smartphone, so I did buy a second one but haven’t used it yet.
The Android 14 OS is great, everything works, with minimal crapware. There are regular updates, although the Linux kernel version is currently 5.4.242 from April 2023. I guess they are limited by the chipset manufacturer here as to what they can do, but I would like to see something that’s less than one year out of date.
It’s great to know that I could run postmarketOS on the Fairphone, if I wasn’t so attached to being able to make calls with my phone and use regular apps. Unfortunately, life in 2024 more or less requires various proprietary Android or iOS apps, unless you get a kick from accessing services in the least convenient way every time. Hopefully we’ll make some progress on this as a society over the next 10 years.
Talking of which, the “elevator pitch” of the Fairphone 5 is that it’s manufacturer supported for the next 10 years, which is way more than companies such as Apple, Google or Samsung are willing to provide for their phones. The 700€ price tag is much more reasonable if you figure that it’s 70€ a year. Let’s see how the phone holds up into the 2030s, but this is a huge selling point for me.
What’s not so good about the Fairphone 5?
I’m happy using this as my main phone but a few things piss me off. Firstly, it’s slightly too big. Older phones are just a much more comfortable size unless you have huge monkey paws. My hands aren’t even that small. This seems to be a problem in the wider mobile phone industry though. Anyway, soon enough phones will go back to being small enough that we can accidentally swallow them, as was forseen in Futurama.
There is a pricey protective case available from Fairphone, which bizarrely does not have any bevel to protect the screen when dropped on the floor. As a person who spends the day just dropping my stuff onto the floor repeatedly, I took the time to research alternative cases and got a more practical one off Aliexpress for a fraction of the price.
The fingerprint reader is built into the power button, which has some advantages, but it’s a lot more finnicky about reading fingerprints than the fingerprint reader on the back of the WP5. Also, if you’re left handed then there isn’t a comfortable way to unlock the phone with one hand. Again, I think many modern phones have this issue, not just the Fairphone 5.
Finally, it’s great that the phone has dual SIM support, which is kind of a dealbreaker when your life is split between two different countries, but I only noticed on receiving the phone that the 2nd SIM card is actually not a physical slot but an eSIM. I can get an eSIM from my Spanish phone provider but so far I’ve been too lazy to do that, or let’s just say I have higher priorities, so I still have one SIM card in the old phone. Probably a sensible design choice on the part of Fairphone but something to be aware of.
Should I buy a Fairphone 5?
If you’re looking for a good quality, mid range ethical phone, and you’re in Europe, then I can certainly recommend it. Consider that it works out at 70€ per year over 10 years, so it’s not really fair to compare it to other phones in the 700€ price range that will be declared obsolete by the manufacturer within 3 or 4 years.
It’s not as mind blowing as the latest iPhone and it’s not as cheap as a 70€ no-brand phone from Aliexpress, but I think it stands up on its own terms, even before you consider that Fairphone are doing more than any other company to avoid child slavery and conflict minerals during the phone production, and that there are significant CO² emissions associated with buying a new smartphone vs. keeping the same one running for a decade.
So far I’m very impressed with what Fairphone have managed to achieve here. Hopefully they aren’t too far away from world domination. Meanwhile, who is up for adding support in postmarketOS for the old Oukitel WP5?
The problem without plymouth and AMD GPUs is that the amdgpu driver is a really really big driver, which easily takes up to 10 seconds to load on older PCs. The delay caused by this may cause plymouth to timeout while waiting for the GPU to be initialized, causing it to fallback to the 3 dot text-mode boot splash.
There are 2 workaround for this depending on the PCs configuration:
1. With older AMD GPUs the radeon driver is actually used to drive the GPU but even though it is unused the amdgpu driver still loads slowing things down.
To check if this is the case for your PC start a terminal in a graphical login session and run: "lsmod | grep -E '^radeon|^amdgpu'" this will output something like this:
amdgpu 17829888 0 radeon 2371584 37
The second number after each is the usage count. As you can see in this example the amdgpu driver is not used. In this case you can disable the loading of the amdgpu driver by adding "modprobe.blacklist=amdgpu" to your kernel commandline:
2. If the amdgpu driver is actually used on your PC then plymouth not showing can be worked around by telling plymouth to use the simpledrm drm/kms device created from the EFI framebuffer early on boot, rather then waiting for the real GPU driver to load. Note this depends on your PC booting in EFI mode. To do this run:
This is a regular meson package and can be installed the usual way.
# Configure project in _build directory
meson setup --wipe --prefix=~/.local _build .
# Build and install in ~/.local
ninja -C _build install
How to use it
To add a Wayland compositor to your application all you have to do is create a CasildaCompositor widget. You can specify which UNIX socket the compositor will listen for clients connections or let it will choose one automatically.
compositor = casilda_compositor_new ("/tmp/casilda-example.sock");
gtk_window_set_child (GTK_WINDOW (window), GTK_WIDGET (compositor));
Once the compositor is running you can connect to it by specifying the socket in WAYLAND_DISPLAY environment variable.
Last cycle wasn’t particularly exciting, only featuring the new dialogs and a few smaller changes, but this one should be more interesting. So let’s look at what’s new.
Bottom sheet
Last cycle libadwaita got new dialogs, which can be presented as bottom sheets on mobile, and I mentioned that they will also be available as a standalone widget in future – so AdwBottomSheet exists and is public now.
As a standalone widget, bottom sheets work a bit differently from dialogs – they are persistent instead of being destroyed upon closing, more like the sidebar of AdwOverlaySplitView.
They also have a few new features, such as a drag handle, or a bottom bar presentation. This is useful for apps like music players.
AdwHeaderBar also integrates with bottom sheets – it hides the title when used in a bottom sheet with a drag handle.
Spinner
Libadwaita also has a new spinner widget – AdwSpinner. It both refreshes visuals and addresses various problems with GtkSpinner.
GtkSpinner is a really simple widget. Both the spinner itself and the animation are set in CSS. The spinner is just a symbolic icon, and the animation is a CSS animation. This approach has a few problems, however.
First, the old spinner has a gradient. Symbolic icons don’t actually support gradients, so it has to resort to dithering, as Jakub Steinerexplained in his blog a few years ago. This works well if the spinner is small enough (16×16 – 32×32), but becomes very noticeable at larger sizes. This means that the spinner didn’t work well for loading screens, or status pages.
Meanwhile, CSS animations are entirely disabled when system animations are off. Usually that makes sense, except here it means the spinner freezes, defeating the entire point of having it (indicating that the app isn’t frozen during long operations).
And, while CSS animations are pretty sophisticated, you can only do so much with a single element – so it’s literally a spinning icon. elementary OS does a more interesting thing – it spins it in steps, while the icon consists of 12 dashes, so it looks like they change color instead. Even then, more complex animations are impossible.
AdwSpinner avoids all of these issues. Since it’s in libadwaita and not in GTK, it can be more opinionated with regard to styling, so instead of using an icon and CSS, it’s just custom drawing. And since it’s not using CSS animations, it can keep spinning with animations off, and can animate in a more involved way than a simple spinning icon.
It still has a size limit – 64×64 pixels. While it can scale further, we don’t really need larger sizes and capping the size makes it easier to use – to make a loading screen using GtkSpinner, you have to set the :halign and :valign properties to CENTER, as well as :width-request and :height-request properties to 32. If you fail to do these steps, the spinner will either be too large, or too small respectively:
Meanwhile if you just put an AdwSpinner into a large bin, it will look right by default.
Oh, and GtkSpinner is invisible by default and you have to set the :spinning property to true as well. This made sense back in the age of foot and dinosaur spinners, where the spinner would stay in place when not animating, but that’s not really a thing anymore.
(though Nautilus wasn’t actually using GtkSpinner)
It also didn’t help that until this cycle, GtkSpinner would continue to consume CPU cycles even when not visible if the :spinning property is left enabled, so you had to start the spinner in the ::map signal and stop it in ::unmap. That is fixed now, but it was a major source of lag in, say, Epiphany in the past (which had a spinner in every tab, another spinner in every mobile tab switcher row and another one in the floating bar that shows URLs on hover, copied from Nautilus).
Spinner paintable
In addition to AdwSpinner, there’s also AdwSpinnerPaintable. It can be used with GtkImage, any other place that accepts paintables (such as status pages) or just manually drawn. It is a bit more awkward to use than the widget, as it needs to reference another widget in order to animate (since paintables cannot access the frame clock on their own), but it allows to use spinners in contexts that wouldn’t be possible otherwise.
AdwStatusPage even has a special style for spinner paintable – similar to the .compact style, but applied automatically.
Button row
Another widget we have now is AdwButtonRow – a list row that looks more or less like a button. It has a label, optionally icons on either side, and can use destructive and suggested style classes.
This pattern isn’t new – it has been used in mockups for a while (at least as early as 2021) – but it varied quite a bit between different mockups and implementations and so having a standard widget for it wasn’t viable. This cycle Jamie Gravendeel and kramo took time to standardize the existing designs into a tangible proposal – so it exists as a standard widget now.
Most of the time these rows aren’t meant to be linked together, so AdwPreferencesGroup has a new property :separate-rows. When enabled, the rows within will appear separately. This is mostly useful for button rows, but also e.g. entry rows. When not using AdwPreferencesGroup, the same effect can be achieved by using the .boxed-list-separate style class instead of .boxed-list.
Multi-layout view
Libadwaita 1.4 introduced AdwBreakpoint, which allowed to easily set properties on window size changes. However, a lot of apps need layout changes that can’t be expressed via simple properties – say, switching between a sidebar and a bottom sheet. While it is possible to do it programmatically anyway, it’s fairly involved and not a lot of apps went to those lengths.
Back then I also prototyped a widget for automatically reparenting children between different layouts via using a property mentioned a future widget for automatically reparenting children between different layouts, and now it’s finished and available for use as AdwMultiLayoutView.
It has changed somewhat since the prototype, e.g. it doesn’t dynamically create or destroy layouts anymore, just parents/unparents them, but the gist is still the same:
Put one or more AdwLayoutSlot into each layout, give them IDs
Define children matching those IDs
Then those children will be placed into the slots for the current layout. When you switch the layout, they will be reparented into slots from that layout instead.
So now it’s possible to define completely different layouts for desktop and mobile entirely via UI files.
CSS variables and colors
I’ve already talked about this in a lot of detail in my last blog post, but GTK has a lot of new CSS goodies, and libadwaita 1.6 makes full use of them.
Libadwaita now provides CSS variables for all of its old named colors, with a docs page to go with it, as well as new variables: --dim-opacity, --disabled-opacity, --border-opacity and --window-radius.
This also allowed to have matching focus ring color on .destructive-action buttons, as well as matching accent color for the .error, .warning and .success style classes. And because overriding accent color for a specific widget is now possible, .opaque button style class has been deprecated in favor of overriding accent colors on .suggested-action. Meanwhile, the white accent color of .osd is now more reliable and automatically works for custom widgets, instead of trying (and often failing) to manually override it for every standard widget.
I mentioned that it might be possible to generate standalone accent/error/etc colors from their respective background colors. However, the question was how to make that automatic, so at the time we didn’t actually integrate that. Now it is integrated, though it’s not completely automatic – only for :root.
Specifically, there’s a new variable: --standalone-color-oklab, corresponding to the correct color transformation for the current style.
So, when overriding accent color for a specific widget, there is a bit of boilerplate to copy:
It’s still an improvement over calculating the color manually, both for light and dark styles (which a lot of apps didn’t do at all, resulting in poor contrast), so still worth it. Maybe one day we’ll be able to make it completely automatic – e.g. by ensuring that using variables with wildcards doesn’t regress performance.
Another big feature is system accent color support. While it’s not a strictly libadwaita change, this is the developer-facing part, so it makes sense to talk about it here.
Behind the scenes it’s using the settings portal which provides a standardized key for the system accent color. Many other environments support it as well, so libadwaita apps will follow their accent color preferences too, while non-GNOME apps that follow the preference will follow it on GNOME too. Note that while the portal exposes arbitrary sRGB colors, libadwaita will pick the closest color from a list of nine colors, as visible on the screenshot above. This is done in the Oklch color space, mostly based on hue, so should work even for really dull colors.
Accent colors are also supported when running on Windows and macOS, and like with the color scheme and high contrast, the libadwaita page in GTK inspector allows to toggle the system accent color now.
Apps are still free to set their own accent color. CSS always takes priority over the system accent.
A lot of people helped push this over the finish line, with particular thanks to Jamie Murphy, kramo and Jamie Gravendeel.
API
AdwStyleManager provides new properties for fetching the system color – :accent-color and :accent-color-rgb, as well as :system-supports-accent-colors for querying whether the system has accent color preferences – same as for color scheme.
The :accent-color property returns a color from the AdwAccentColor enum, so that individual colors can be special cased (say, when using bitmap assets). This color can be converted both to background color RGBA (using adw_accent_color_to_rgba()) and to standalone color (adw_accent_color_to_standalone_rgba()).
All of these colors use white foreground color, so there’s no API for fetching it, at least for now.
Note that :accent-color-rgba will still return the system color even if the app overrides its accent color using CSS. It only exists for convenience and is equivalent to calling adw_accent_color_to_rgba() on the :accent-color value.
While we still don’t have a general replacement for deprecated gtk_style_context_lookup_color(), the new accent color API can replace at least some of its uses.
On CSS side, there are new variables corresponding to each accent color: --accent-blue for blue and so on. Additionally, every system color, along with their standalone colors for both light and dark, is documented and can be used as a reference.
Destructive buttons
Having accent color that’s not always blue means having to rethink other style choices. In particular, .destructive-action buttons were just a red version of .suggested-action, same as in GTK3. This was already questionable from accessibility perspective, but breaks entirely with accent colors, since suggested buttons would look exactly same as a destructive ones with red accent. And so .destructive-action has a distinct style now, less prominent than suggested.
Alert dialogs
Old and new alert dialogs side by side
Another area that needed updates was AdwAlertDialog – it was also using color for differentiating suggested and destructive buttons.
Coincidentally, the alert dialog style went almost unchanged from GTK3 days, and looked rather out of place with the rest of the platform. So kramo came up with an updated design.
AdwMessageDialog and GtkAlertDialog received the same style, or at least an approximation – it’s not possible to replicate it entirely in GTK dialogs. Even though neither is recommended for use (when using libadwaita, anyway – nothing wrong with using GtkAlertDialog in plain GTK), regressing apps that aren’t fully up to date with the platform wouldn’t be very good.
Adapting apps
Accent colors are supported automatically, and in most cases apps don’t need any changes to make use of them. However, here’s a checklist to ensure it works well:
Make use of the accent color variables in custom CSS, like --accent-bg-color. Using the old named colors like @accent_bg_color works as well. Don’t assume accent color will be blue.
Conversely, don’t use accent color when you mean blue. We have variables like --blue-3 for that – or even --accent-blue.
When using accent color in custom drawing (say, drawing a graph), make sure to redraw it when AdwStyleManager:accent-color value changes – same as for color scheme and high contrast.
Deprecations
Last cycle we introduced new dialog widgets that are based on AdwDialog rather than GtkWindow. However, that happened right at the end of the cycle, without giving apps a lot of time to port their existing dialogs. Because of that, the old widgets (AdwMessageDialog, AdwPreferencesWindow, AdwAboutWindow) weren’t deprecated and I mentioned that they will be deprecated in future instead. So, they are now.
If you haven’t migrated to the new dialogs yet, see the migration guide for how to do so.
Other changes
As always, there are smaller changes that don’t warrant their own sections, so let’s look at those:
AdwWindow and AdwApplicationWindow now have a default minimum size (360×200 px), meaning you don’t have to set it manually to use breakpoints or dialogs anymore. Apps can still override it if they need a different size, but it works out of the box now.
GtkTextView now supports the .inline style class, removing its background and resetting its foreground color. This allows to use it in contexts like cards.
Future
As usual, there are changes that didn’t make it this cycle and will land the next cycle instead. Most notably, the old toggle groups branch by Maximiliano is finally finished and will land early next cycle.
Big thanks to STF for funding a lot of this work (GTK CSS improvements, bottom sheets, finishing multi-layout view and toggle groups, general maintenance), as well as people organizing the initiative and all contributors who made this release happen.
The GNOME Foundation is excited to announce that we have officially opened the search for a new Executive Director. This is an exciting time for our organization as we seek a dynamic leader to guide us into the future, continuing our mission to foster the growth of GNOME and the wider free software community.
As the cornerstone of our leadership team, the Executive Director will play a critical role in shaping the strategic direction of the Foundation, working closely with staff, community members, and partners to expand our reach and impact. The ideal candidate will have professional experience working with nonprofits, a strong passion for open-source software, a deep commitment to our community values, and the vision to drive the next phase of GNOME’s growth and development.
The position offers a unique opportunity to lead a pivotal project in the open-source ecosystem, collaborating with a global network of contributors and partners. Interested candidates can find more details on the role and how to apply on our careers page.
We encourage qualified individuals who share our vision of promoting software freedom and innovation to apply. We are looking forward to finding the next Executive Director who will carry forward the mission of the GNOME Foundation, driving positive change within the tech world and beyond.
This post is a digest of what happened in August in the STF team (a little late). You might have seen some updates from the team members directly earlier in TWIG! They say August is a productivity blackhole, but whoa look at this massive update!
I’m very grateful to the team for its dedication, and to the Sovereign Tech Fund who enables this work. The Foundation is preparing a crowdfunding platform to allow you to support this kind of work as well! More on this next month.
Encrypt user home directories individually
On Linux systems, users are traditionally managed in a specific file called /etc/passwd. It doesn’t make a difference between technical and human accounts. It also only stores very basic information about users, and can only be modified by root. It’s a very rigid users database.
AccountsService is a “temporary” daemon (since 2010) bringing to manage users and store more extensive information about them: profile picture, parental control settings, preferred session to log into, languages, etc. It manages /etc/passwd and its own database.
homed is a modern replacement for AccountsService. It provides encryption for user data, and paves the way for future exciting platform security and flexibility improvements.
Adrian worked with a user through some remote debugging about systemd-homed (systemd/systemd#33541 and following comments).
Modernize platform infrastructure
libadwaita
GTK is a popular development toolkit to create graphical apps in the free desktop. libadwaita is a library based on GTK providing the building blocks for modern GNOME applications.
Alice did libadwaita releases: 1.4.7, 1.5.3, 1.6.beta, and 1.6.rc. She also worked on Dialog fixes before beta (here and here), a CI fix as well as several reviews.
She shared thoughts on a common interface for platform libraries support in GTK in this issue.
She added crossfade support to the view stack so we can use it in contexts where you’d want an inline switcher
She switched inline stack switcher to view stack, renamed to inline view switcher
And she started reworking toggle group api. That work is still ongoing
inline view switcher now supports needs-attention/badges.
Alice also he gave the tests (including accessibility tests) some love to make sure libadwaita is as reliable as ever and implemented a new demo.
She reworked documentation to make her work easier to use
Finally she spent quite a bit of time on reviews for PRs have been merged (here, here, here, and here and quite a few more) and on PRs that have not.
Toggle groups should be ready, waiting for 47 to branch now.
Shell notifications
If you have followed Julian’s GUADEC talk about notifications on the free desktop, you know that the current situation is suboptimal. Fortunately, the design team and Julian are coming to the rescue, and are also working on grouped notifications to make them less in your face.
Julian rewrote glsl shader for fading notifications when a group is expanded. He looked into round clipping for mutter, which would be really nice for grouping. This will require a significant amount of non trivial work to do correctly.
Finally, he worked on notification grouping for GNOME Shell: after addressing the style suggestions he marked the notification grouping MR as ready.
Improve QA and development tooling
gjs bindings
Evan finished work on getting async support for GJS, compiling again and is debugging test failures.
Finally, GLib async support needs additional work to fix Windows CI (hopefully the last roadblock 🤞).
systemd-sysupdated
systemd-sysupdate is an update system allowing immutable systems to apply lightweight delta updates. It helps image-based systems support immutability, auto-updates, adaptability, factory reset, uniformity and providing a trust chain from the bootloader all the way up.
sysupdate is a CLI tool. In order to be able to use systemd-sysupdate, sturdier services are needed. sysupdated is a service that provides a dbus API for sysupdate.
systemd-repart is a tool that systemd runs on boot that non-destructively repartitions disks.
Adrian taught it to dynamically decide whether or not to create a separate boot partition. Depending on the existing layout of disk, repart will skip creating a dedicated boot partition if it can get away with it, which is one of the big missing features in repart before it can be an OS installer.
Improve the state and compatibility of accessibility
Joanie has been working on a metric tonne of updates in Orca. Most of the changes are rather technical and would be rather wordy in a TWIG update, but thanks Joanie for rejuvenating Orca!
Maintenance and modernization of security components
The free desktop standardises the storage and usage of secrets (such as passphrases or SSH keys) via the secrets specification. gnome-keyring was the backend implementation, and libsecret the client-side of said specification.
gnome-keyring and libsecret are written in C and lack maintenance. oo7 is a modern Rust client-side library that respects the secrets specification. Dhanuka is extending oo7 to implement the backend side of secrets management, and ultimately replace gnome-keyring, has been at it in August as well!
Secure APIs for Wayland/Flatpak
Flatpak
Georges handled Flatpak / Bubblewrap CVE-2024-42472, released xdg-dbus-proxy 0.1.6 with important fixes, coordinated more merges, and released Flatpak 1.16.0.
He also implemented a solution to the “impossible” Flatpak a11y issue (here, here and here). This accessibility issue revolved around the Flatpak sandbox preventing WebKit and Epiphany’s accessibility trees from being connected.
USB Portal
Flatpak doesn’t have USB permission. To access USB currently, the device=all permission must be used. This exposes all the devices on the machine.
We want to provide a way to allow selective access to USB devices from inside a sandbox like flatpak. This is access to the actual USB, not the devices build on top, like audio, input or mass storage.
Again, a massive massive thank you to the whole team who has been working on the STF grant, and our gratitude to the Sovereign Tech Fund who makes this possible. The team is working with all their heart to bring not only GNOME but also the free desktop as a whole forward.
Thanks to Jan-Michael Brummer (Volkswagen), Papers now supports signing documents with digital certificates! If you have a digital certificate stored in your computer or in an Smart Card, as those stored in the national IDs of some states like Estonia or Spain, you no longer need an additional program to digitally sign your documents! See the Merge Request description for a walk-through of the UX!
Version 1.2.0 of SemantiK is out now. It is a word-guessing game.
This new version includes the ability to download language packs. The first language pack to be available is the English language pack, which you can download on Flathub through your software center of choice.
The UI is still in French, but I’ll be adding a translated UI in the next version!
Introducing Casilda - A Wayland compositor widget!
A simple Wayland compositor widget for Gtk 4 which can be used to embed other processes windows in your Gtk 4 application.
It was originally created for Cambalache’s workspace using wlroots, a modular library to create Wayland compositors.
Following Wayland tradition, this library is named after my hometown in Santa Fe, Argentina
Pipeline version 2.0.0 was released. Pipeline lets you follow your favorite video creators, both on YouTube and PeerTube. Version 2.0.0 is a complete rewrite of the application, in order allow for easier maintenance, more features (some included in this version, some in future versions) and improve the user experience in general.
The highlights of this version are the ability to search YouTube and PeerTube for videos and channels and playing videos inside the application using the Clapper video player (while the option to play with any other external player is still available). Besides those highlights, the application should have feature-parity with previous releases of Pipeline. This includes in particular:
Displaying videos of your subscriptions in a single feed,
Filtering out unwanted videos, for example Shorts or videos from a series you don’t like,
Managing videos you want to watch later,
Importing your previous subscriptions from NewPipe or YouTube,
Download videos you want to watch offline.
You can get the latest release on Flathub, and feel free to chat with us in our Matrix room.
Software development without Linux is no longer possible within an automotive environment. Therefore Volkswagen Group IT created and maintains a Linux distribution for their developers and contributes to many upstream projects. Jan-Michael Brummer speaks at OpenSUSE 2024 (https://media.ccc.de/v/4486-linux-at-volkswagen/oembed) about the starting goal to integrate into the existing environment, and highlights their integration problems and solutions with contributing to upstream: libproxy, OneDrive (gvfs/goa), PKCS11 (Secrets / Web), Digital Signing (Papers), …
The GNOME Foundation has announced that hiring is open for its next Executive Director. Details about the position can be found on the GNOME Foundation website, at OpenSource Job Hub, and fossjobs.net. Please share the post with your networks and reach out to any candidates you might know.
In other Foundation news, the Board of Directors had its regular monthly meeting this week, where it focused on budget planning for the upcoming financial year. We are also pleased to announce that Richard Littauer, the Foundation’s current interim executive director, will be continuing in his position until the end of November.
Earlier this week, I attended the monthly board meeting and went through a very rough, preliminary draft of a budget for the Board. Not intended to be a working budget, this draft is just a starting point to begin discussion. While it is up to the Finance Committee to hammer this draft into something usable, this exercise of going over it with the board at large was useful in showing our directors the format and structure of our yearly budget, and in explaining what the groupings and categories cover. I am looking forward with the rest of the Finance Committee on the next steps.
That’s all for this week!
See you next week, and be sure to stop by #thisweek:gnome.org with updates on your own projects!
A couple of weeks ago, I went to see Alien: Romulus. While many of my friends were disappointed, I actually enjoyed it. In fact, it exceeded my expectations — mainly because I didn’t expect much! :)
Fede Alvarez delivered exactly what producer Ridley Scott asked of him, leaning heavily on the nostalgia of the original masterpiece while skirting the edge of a reboot. The world of Prometheus wasn’t ignored, but purposedly avoided referencing too deeply.
The dystopian world of corporate feudalism set a tone even darker than the original, to the point where the xenomorph didn’t seem like the worst thing that could happen. I’m still holding out hope for 90-minute movies as the gold standard, but the two-hour runtime was manageable—though my aging buttocks may disagree. The slow-burn first act was actually the most enjoyable part, as that’s where the fresh world-building took center stage. Even as the familiar plot unfolded, Alvarez delivered memorable suspense and action scenes.
Of course, it’s never going to feel the same as seeing Alien or Aliens as a teenager. I can’t fully dive into my minor criticisms without spoilers, but let’s just say the movie understood that “less is more” — except in one area. Other than that, Alien: Romulus proved that going to the movies can still be a pretty great experience.
I wrote a post about so called "M type" and "S type" processes in software development. Unfortunately it discusses the concept of human sexuality. Now, just to be sure, it does not have any of the "good stuff" as the kids might say. Nonetheless this blog is syndicated in places where such topics might be considered controversial or even unacceptable.
Thus I can't really post the text here. Those of you who are of legal age (whatever that means in your jurisdiction) and out of their own free will want to read such material, can access the PDF version of the article via this link.
It’s been a while since I’ve annoyed you by mentioning drones, but here we are with DJI’s latest creation—the Neo. DJI is a giant, soulless corporation, but they’ve made some clever design decisions with this drone. It’s a flying camera that works without a phone or remote, and for about half the price of a GoPro, you get a self-sufficient, button-operated flying cameraman. Take it out, push a button, and off it goes, capturing footage like it knows what it’s doing. It might also just simply be a response to the actually innovative HoverAir X1, just made extremely affordable.
The camera quality won’t blow you away, but it’s solid enough if you can overlook its overly-sharpened aesthetic. The Neo can even play the part of a lightweight cinewhoop or a poor man’s DJI Mini, though that’s only if you own DJI’s latest goggles and remotes—so there’s a bit of a catch. I bought it mainly for the fun shots you’re watching here, and while I’m not interested in keeping up with DJI’s endless upgrades, I must admit the little drone has charm and utility.
Neo’s Follow mode is a standout, tracking you accurately with just its camera feed and no fancy sensors. It tries to follow your path to avoid hitting anything. But beware the Direction Tracking mode in crowded areas—it has a habit of misjudging where you’re facing and wobbling about. The biggest hiccup I encountered? No gesture to make it return home, which left me standing under it after performing a Rocket shot, until the battery ran out. Luckily the pain lasted only about 10 minutes. Overall, it’s a great toy for hikes, casual outings, and occasional public embarrassment.
Soundtrack for the poorly edited video above comes from my 2024 weekly beats endeavors. Looks like I have enough material for a 2025 album. Stay tuned!
As it's now aproaching mid-September and the autumn release of GNOME, so is there also a new release of Maps approaching for GNOME 47.
Switch to Vector-based Map
The biggest change since last release is that we now use the vector-based map by default and the old raster map has also been retired since we wanted to move forward with things like enabling, and relying on clickable POIs directly in the map view so we could the remove the old tedious “What's here?” context menu doing a reverse geocoding to get details about a place (which is also a bit hit-and-miss with regards to how close to where you point the actual result is).
Apart from this other benefits we get (and this has already been mentioned in earlier posts) localized names (when tagged in OpenStreetMap) and finally a proper dark mode with our new GNOME map style.
Light (default) theme variant of the map in 47
Dark theme variant of the map in 47
Redesigned Search Bar
The “explore” button to open the search for nearby POIs by category menu has now been integrated into the entry to avoid a theme issue when using the linked button style where the rounded corners disappears on the “other side” when the results popover is showing.
Search bar with explore button
This also looks a bit sleeker I think…
Improved Public Transit Routing
Public transit routing is now using the Transitous project (https://transitous.org) to provide transit routing for new regions. And as this is a crowd sourcing initiativ you can also help out by adding additional missing GTFS feeds to the project and it should automatically get supported by Maps.
For the time being, the regions we already supported by third-party APIs (such as Resrobot for Sweden, and OpenData.ch for Switzerland) will still use those providers to avoid possible regressions. It also gives us some leeway to improve MOTIS (the backend used by Transitous). The implementation in Maps also lacks e.g. support for specifying via locations.
Showing some travel itinerary options in Prague
Showing a sample of an itinerary from Lund, Sweden to Hamburg, Germany
Showing a sample of an itinerary in Denver, Colorado
Some changes had to be made to our internal shield rendering library (we couldn't use the OSM Americana implementation directly, as we had to implement ours using Cairo rendering and so on) to support the new convenience shortcut for a “pill” shield shape, and also being able to define hard-coded route references “ref” directly in the shield definition rather than getting from the tile data.
Rochester Inner Loop in Rochester, New York, using a fixed “LOOP” reference label
And on that note, a funny bug I discovered during some testing is that we currently always assume the “pointsUp” attribute in the shield definitions would always default to true when not explicitly set, while the OSM Americana code has different defaults depending on the following shape. So specifically for the “fishhead” shape it should actually be false when not set. I guess this is a bit odd to assume different values depending on following JSON elements, but…
Highway shields in New Zeeland
It was a bit funny I discovered this bug when “browsing around“ in New Zeeland considering Northern Hemisphere-centric jokes about people “Down-under” walking upside-down 😀. But this actually also affects some highways in the US…
I guess this should be fixed before the 47.0 release.
Should your garbage collector be precise or conservative? The
prevailing wisdom is that precise is always better. Conservative GC can
retain more objects than strictly necessary, making GC slow: GC has to
more frequently, and it has to trace a larger heap on each collection.
However the calculus is not as straightforward as most people think, and
indeed there are some reasons to expect that conservative root-finding
can result in faster systems.
(I have made / relayed some of these arguments before but I feel like a
dedicated article can make a contribution here.)
problem precision
Let us assume that by conservative GC we mean conservative
root-finding, in which the collector assumes that any integer on the
stack that happens to be a heap address indicates a reference on the
object containing that address. The address doesn’t have to be at the
start of the object. Assume that objects on the heap are traced
precisely; contrast to BDW-GC which generally traces both the stack and
the heap conservatively. Assume a collector that will pin referents of
conservative roots, but in which objects not referred to by a
conservative root can be moved, as in Conservative
Immix or Whippet’s
stack-conservative-mmc
collector.
With that out of the way, let’s look at some reasons why conservative GC
might be faster than precise GC.
smaller lifetimes
A compiler that does precise root-finding will typically output a
side-table indicating which slots in a stack frame hold references to
heap objects. These lifetimes aren’t always precise, in the sense that
although they precisely enumerate heap references, those heap references
might actually not be used in the continuation of the stack frame. When
GC occurs, it might mark more objects as live than are actually live,
which is the imputed disadvantage of conservative collectors.
This is most obviously the case when you need to explicitly register
roots with some kind of handle API: the handle will typically be kept
live until the scope ends, but that might be an overapproximation of
lifetime. A compiler that can assume conservative stack scanning may
well exhibit more precision than it would if it needed to emit stack
maps.
no run-time overhead
For generated code, stack maps are great. But if a compiler needs to
call out to C++ or something, it needs to precisely track roots in a
run-time data
structure.
This is overhead, and conservative collectors avoid it.
smaller stack frames
A compiler may partition spill space on a stack into a part that
contains pointers to the heap and a part containing numbers or other
unboxed data. This may lead to larger stack sizes than if you could
just re-use a slot for two purposes, if the lifetimes don’t overlap. A
similar concern applies for compilers that partition registers.
no stack maps
The need to emit stack maps is annoying for a compiler and makes
binaries bigger. Of course it’s necessary for precise roots. But then
there is additional overhead when tracing the stack: for each frame on
the stack, you need to look up the stack map for the return
continuation, which takes time. It may be faster to just test if words
on the stack might be pointers to the heap.
unconstrained compiler
Having to make stack maps is a constraint imposed on the compiler.
Maybe if you don’t need them, the compiler could do a better job, or you
could use a different compiler entirely. A conservative compiler can sometimes have better codegen, for example by the use of interior pointers.
anecdotal evidence
The Conservative Immix
paper shows that conservative stack scanning can beat precise scanning
in some cases. I have reproduced these results with
parallel-stack-conservative-mmc compared to
parallel-mmc.
It’s small—maybe a percent—but it was a surprising result to me and I
thought others might want to know.
When it comes to designing a system with GC, don’t count out
conservative stack scanning; the tradeoffs don’t obviously go one way or the other, and conservative scanning might be the right engineering choice for your system.
Thank you to the translation teams for all the translation updates which happen in GNOME, particularly just before a release, like just now. It is really appreciated!
A wild new stable release of Cairo appeared! It’s super-effective at fixing build issues and bugs on a variety of platforms and toolchains. Thanks to Federico Mena, Cairo now generates static analysis and coverage reports as part of the CI pipeline; the coverage reports are published, so if you want to contribute to the Cairo project you can now find where your changes can be most effective.
There have been a lot of fixes and refactoring, notable changes:
Credential changes
For SSH repos ssh-agent will now be used by default. This makes it easier to use different keys with or without password protection. You can still configure a predefined ssh key in the settings.
It is now possible to use HTTPS repos with username and password. A userpass dialog will prompt for your credentials which can be stored in the gnome keyring. I was not able to test this feature myself, because I do not have access to a repository which allows HTTPS with password. But it seems to work.
File-manager plugin changes
A huge bottleneck, which caused nautilus to freeze up and worst case to crash has been fixed.
Unfortunately I found another issue with the update_file_info_full function, which I can reproduce on multiple distros. For the time being the turtle plugin uses update_file_info instead. This makes emblem calculation slower, but at least it runs stable again.
There is now a turtle emblem which will be shown for the repo main folder by default. The status emblem can be activated again in the settings. It is also possible to show both or none of them. This change further speeds up emblem calculation in folders with many (100+) repos, especially with the workaround mentioned above, and also makes submodules more visible.
After a long awaited couple of months, Parabolic has been rewritten in C++ and features a redesigned user interface! Users should expect a faster and more reliable downloader.
We encourage all Parabolic users to give this beta a try and iron out all issues before the stable release (targeted for next week).
Here’s the full changelog:
Parabolic has been rewritten in C++ for faster performance
The length of the kept download history can now be changed in the app’s preferences
Cookies can now be fetched from a selected browser in Preferences instead of selecting a TXT cookies file
Parabolic’s Keyring module was rewritten. As a result, all keyrings have been reset and will need to be reconfigured
Fixed validation issues with various sites
Fixed an issue where a specified video password was not being used
Is it hot in the Northern Hemisphere and cold in the Southern Hemisphere?
Weather O’Clock has been ported to GNOME Shell 47! With this new version, it is possible to customize the display of weather information, choosing whether it appears before or after the clock.
New updates for the Day Progress extension - circular indicators and GNOME 47!
Day Progress, the extension that lets you visualise how much time is left of your day has now been ported to support GNOME 47! There is now an (experimental) option to display the time elapsed/remaining as a circular (“pie”) indicator too. I haven’t run into any bugs with the new indicator style in my few days of testing but I’m still hesitant to call it stable, that’s why I have labelled it as ‘experimental’. You can download the extension at https://extensions.gnome.org/extension/7042/day-progress/ and the repository is available at https://github.com/ArcaEge/day-progress where you can also report any issues you find.
That’s all for this week!
See you next week, and be sure to stop by #thisweek:gnome.org with updates on your own projects!
The WebRTC nerds among us will remember the first thing we learn about WebRTC, which is that it is a specification for peer-to-peer communication of media and data, but it does not specify how signalling is done.
Or put more simply, if you want call someone on the web, WebRTC tells you how you can transfer audio, video and data, but it leaves out the bit about how you make the call itself: how do you locate the person you’re calling, let them know you’d like to call them, and a few following steps before you can see and talk to each other.
WebRTC signalling
While this allows services to provide their own mechanisms to manage how WebRTC calls work, the lack of a standard mechanism means that general-purpose applications need to individually integrate each service that they want to support. For example, GStreamer’s webrtcsrc and webrtcsink elements support various signalling protocols, including Janus Video Rooms, LiveKit, and Amazon Kinesis Video Streams.
However, having a standard way for clients to do signalling would help developers focus on their application and worry less about interoperability with different services.
(author’s note: the puns really do write themselves :))
As the names suggest, the specifications provide a way to perform signalling using HTTP. WHIP gives us a way to send media to a server, to ingest into a WebRTC call or live stream, for example.
Conversely, WHEP gives us a way for a client to use HTTP signalling to consume a WebRTC stream – for example to create a simple web-based consumer of a WebRTC call, or tap into a live streaming pipeline.
WHIP and WHEP
With this view of the world, WHIP and WHEP can be used both for calling applications, but also as an alternative way to ingest or play back live streams, with lower latency and a near-ubiquitous real-time communication API.
We know GStreamer already provides developers two ways to work with WebRTC streams:
webrtcbin: provides a low-level API, akin to the PeerConnection API that browser-based users of WebRTC will be familiar with
webrtcsrc and webrtcsink: provide high-level elements that can respectively produce/consume media from/to a WebRTC endpoint
At Asymptotic, my colleagues Tarun and Sanchayan have been using these building blocks to implement GStreamer elements for both the WHIP and WHEP specifications. You can find these in the GStreamer Rust plugins repository.
Our initial implementations were based on webrtcbin, but have since been moved over to the higher-level APIs to reuse common functionality (such as automatic encoding/decoding and congestion control). Tarun covered our work in a talk at last year’s GStreamer Conference.
Today, we have 4 elements implementing WHIP and WHEP.
Clients
whipclientsink: This is a webrtcsink-based implementation of a WHIP client, using which you can send media to a WHIP server. For example, streaming your camera to a WHIP server is as simple as:
whepclientsrc: This is work in progress and allows us to build player applications to connect to a WHEP server and consume media from it. The goal is to make playing a WHEP stream as simple as:
The client elements fit quite neatly into how we might imagine GStreamer-based clients could work. You could stream arbitrary stored or live media to a WHIP server, and play back any media a WHEP server provides. Both pipelines implicitly benefit from GStreamer’s ability to use hardware-acceleration capabilities of the platform they are running on.
GStreamer WHIP/WHEP clients
Servers
whipserversrc: Allows us to create a WHIP server to which clients can connect and provide media, each of which will be exposed as GStreamer pads that can be arbitrarily routed and combined as required. We have an example server that can
play all the streams being sent to it.
whepserversink: Finally we have ongoing work to publish arbitrary streams over WHEP for web-based clients to consume this media.
The two server elements open up a number of interesting possibilities. We can ingest arbitrary media with WHIP, and then decode and process, or forward it, depending on what the application requires. We expect that the server API will grow over time, based on the different kinds of use-cases we wish to support.
GStreamer WHIP/WHEP server
This is all pretty exciting, as we have all the pieces to create flexible pipelines for routing media between WebRTC-based endpoints without having to worry about service-specific signalling.
If you’re looking for help realising WHIP/WHEP based endpoints, or other media streaming pipelines, don’t hesitate to reach out to us!
GNOME is interested in participating in the Outreachy December-March cohort, and while we already have a few great projects, we are looking for experienced mentors with a couple more project ideas. Hurry up, we have until September 11 to conclude our list of ideas.
As of today, Mutter will style legacy titlebars (i.e. of X11 / Xwayland apps that don’t use client-side decorations) using Adwaita on GNOME.
Shadows match the Adwaita style as well, including shadows of unfocused windows. These titlebars continue to follow the system dark and light mode, even when apps don’t.
Should make using legacy apps a little less unpleasant
We have finally reached the final week of GSoC. It has been an amazing journey! Let’s summarize what was done, the current state of the project and what’s next.
Introduction
This summer, I had the opportunity to work as a student developer under the Google Summer of Code 2024 program with the GNOME Community. I focused on creating a web-based Integrated Development Environment (IDE) specifically designed for writing and executing SPARQL queries within TinySPARQL (formerly Tracker).
This user-friendly interface empowers developers by allowing them to compose and edit multiline SPARQL queries directly in a code editor, eliminating the need for the traditional terminal approach. Once a query is written, it can be easily executed via the HTTP SPARQL endpoint, and the results will be displayed in a visually appealing format, enhancing readability and user experience.
By lowering the barrier to entry for newcomers, boosting developer productivity with visual editing, and fostering collaboration through easier query sharing, this web IDE aims to significantly improve the experience for those using libtracker-sparql to interact with RDF databases.
I would like to express my sincere gratitude to my mentors, Carlos and Sam, for their guidance and support throughout the internship period. Their expertise was invaluable in helping me navigate the project and gain a deeper understanding of the subject matter. I would also like to thank my co-mentee Rachel, for her excellent collaboration and contributions to making this project a reality and fostering a fast-paced development environment.
I’m excited to announce that as the internship concludes, we have a functional web IDE that enables users to run SPARQL queries and view the results directly in their web browser. Here is the working demo of the web IDE that was developed from scratch in this GSoC Project.
Working of TinySPARQL Web IDE
What was done
This project was divided into two primary components: the backend C code, which enabled the web IDE to be served and run from the command line, and the frontend JavaScript code, which enhanced the web IDE’s visual appeal and added all user-facing functionalities. I primarily focused on the backend C side of the project, while Rachel worked on the frontend. Therefore, this blog post will delve into the backend aspects of the project. To learn more about the frontend development, please check out Rachel’s blog.
The work done by me, could be divided into three major phases:
Pre-Development Phase
During the pre-development phase, I focused on familiarizing myself with the existing codebase and preparing it for easier development. This involved removing support for older versions of libraries, such as Libsoup.
TinySPARQL previously supported both Libsoup 2 and Libsoup 3 libraries, but these versions had different function names and macros.
This compatibility requirement could significantly impact development time. To streamline the process, we decided to drop support for Libsoup 2.
The following merge requests document the work done in this phase:
In this phase, I extended the HTTP endpoint exposed by the tinysparql endpoint command to also serve the web IDE. The goal was to enable the endpoint to serve HTML, CSS, and JavaScript files, in addition to RDF data. This was a crucial step, as frontend development could only begin once the basic web IDE was ready.
During this phase, the HTTP module became more complex. To aid in debugging and diagnosing errors, we added a debugging functionality. By running TRACKER_DEBUG=http, one can now view logs of all GET and POST methods, providing valuable insights into the HTTP module’s behavior.
The following merge requests document the work done in this phase:
The web IDE added significant size (around 800KB-1MB) to the libtracker-sparql library. Since not all users might need the web IDE functionality, we decided to separate it from libtracker-sparql. This separation improves efficiency for users who won’t be using the web IDE.
To achieve this isolation, we implemented a dedicated subcommand tinysparql webide for the web IDE, allowing it to run independently from the SPARQL endpoint.
Here’s a breakdown of the process:
Isolating HTTP Code: I started by extracting the HTTP code from libtracker-sparql into a new static library named libtracker-http. This library contains the abstraction TrackerHttpServer over the Libsoup server, which can be reused in the tinysparql webide subcommand.
Creating a Subcommand: Following the isolation of the web IDE into its own library and the removal of relevant gresources from libtracker-sparql, we were finally able to create a dedicated subcommand for the web IDE. As a result, the size of libtinysparql.so.0.800.0 has been reduced by approximately 700KB.”
The following merge requests document the work done in this phase:
This is the web IDE we developed during the internship. Check out this demo video to see some of the latest changes in action.
TinySPARQL Web IDESPARQL Query successfully executedError handling
Future Work
Despite having a functional web IDE and completing many of the tasks outlined in the proposal (even exceeding the original scope due to the collaborative efforts of two developers), there are still areas for improvement.
I plan to continue working on the web IDE in the future, focusing on the following enhancements:
Multi-Endpoint Support: Implement a mechanism for querying different SPARQL endpoints. This could involve adding a text box input to the frontend for dynamically entering endpoint URLs or providing a connection string option when creating the web IDE instance from the command line.
Unified HTTP Handling: Implement a consistent HTTP handler for all cases, allowing TrackerEndpointHttp to handle requests both inside and outside the /sparql path.
SPARQL Extraction: Extract the SPARQL query from POST requests in TrackerEndpointHttp or pass the raw POST data in the ::request signal, enabling TrackerEndpointHttp to determine if it contains a SPARQL query.
Avahi Configuration: Move the Avahi code for announcing server availability or assign TrackerEndpointHttp responsibility for managing the content and type of broadcasted data.
CORS Configuration: Make CORS settings configurable at the API level, allowing for more granular control and avoiding the default enforcement of the * wildcard.
GUADEC Experience
One of the highlights of my GSoC journey was the opportunity to present my project at GUADEC, the annual GNOME conference. It was an incredible experience to share my work with a diverse audience of developers and enthusiasts. Be sure to check out our presentation on the TinySPARQL Web IDE, delivered by Rachel and me at GUADEC.
Final Remarks
Thank you for taking the time to read this. Your support means a great deal to me. This internship was a valuable learning experience, as it was my first exposure to professional-level C code and working with numerous libraries solely based on official documentation. I am now more confident in my skills than ever. I gained a deeper understanding of the benefits of collaboration and how it can significantly accelerate development while maintaining high code quality.
Add support for the latest GIR attributes and GI-Docgen formatting to Valadoc.
Overview
GSoC 2024 has come to an end, so it's time to wrap up. I got the opportunity to contribute to the Vala Project which consists of an awesome programming language called Vala, and it gives me immense sense of accomplishment to know that my work will be beneficial for Vala programmers. I spent the 12 weeks working through the codebase of the Vala compiler, adding features and making the necessary changes to achieve the project goals. It was a valuable experience and I have learnt a lot by working with talented mentors and peers. This has undoubtedly shaped my journey as a developer and I plan to continue working on the project.
Project Summary
This project aimed to add support for the latest features of GObject Introspection to the Vala compiler and Valadoc. The plan was to ensure that the Vala compiler (which generates Vala bindings for the GIR files) parses and utilizes the newer GIR attributes from the introspection data of GObject based C libraries, and outputs them in the generation of Vala GIRs. In Valadoc, this was to be implemented by parsing the GI-Docgen documentation format, and rendering working GI-Docgen links in the HTML documentation generated by Valadoc. Another important step in improving Valadoc was to redesign https://valadoc.org and give it a modernized look, making this one of the milestones that was expected to be acheived in the project.
Contributions (Merge requests)
To acheive these objectives, I opened the following merge requests:
Support for sync-func, async-func, and finish-func attributes for method. (Draft) [!393]
Add support for default-value attribute for property. [394]
libvaladoc: Parse backticks in gi-docgen markdown and display the enclosed text as monospaced. [!402]
libvaladoc: Modernize the HTML documentation pages generated by valadoc. [!403]
Redesign https://valadoc.org and make it mobile-responsive. [#419]
Future Plans
Although the coding period of GSoC 2024 is now over, I feel that this is just the beginning of my contributions to GNOME. We still have to implement support for working GI-Docgen links and many other features of GI-Docgen markdown to Valadoc. I will continue working to meet the project objectives, contribute more, and be more involved within the GNOME community. I got to learn a lot over the past 12 weeks and this has certainly made me a better contributor.
Mentor
I extend my heartfelt gratitude to my mentor Lorenz Wildberg for being a constant source of support and motivation throughout the internship. Their expertise and guidance helped me reach this far into the project and I hope to continue working on Vala and other GNOME projects in the coming months.
As I look back and reflect on my journey over the last 12 weeks, I am filled with gratitude for this opportunity and excitement for future work on Vala and related GNOME projects. I want to learn more about GTK, Vala and the GNOME development process so that I can make more impactful contributions and be a valuable member of the community. I had many interactions with numerous GNOME contributors and I'm grateful to each and every one of them for always being ready to guide and for their prompt replies to my doubts. I was a Linux user for a long time but never really used it as a power user until I started contributing to GNOME. I'm glad to say that now Linux will always be my preferred choice of an operating system :). My favourite part of working on this project was being part of a community that is diverse, inclusive, and incredibly welcoming to newcomers. I look forward to being a better GNOME contributor and guiding new contributors in GNOME.
TLDR: GSoC is ending soon and I’ve definitely learned a lot from my time here, if you’re interested in the code I’ve written for my GSoC project feel free to go straight to the end where I’ve linked all the MRs I’ve been involved
Hello GNOME community! Time flies and my time with GSoC working on a new Web-IDE for TinySPARQL is coming to a close. You might have seen my intro post about the project, or the lightning talk my colleague Demigod and I recorded together for GUADEC. In any case, I’m excited to show you guys our final product and talk about the next steps, both in terms of this project and my involvement with open source.
First of all, to reiterate the purpose of this project – we’ve been working the last few months to create a web-IDE to be used with TinySPARQL and LocalSearch for query testing in a more user-friendly environment, our main target audience being fellow developers that for any reasons need to interact with LocalSearch or TinySPARQL databases.
My main work during the last few months involved developing a lightweight TypeScript based UI while my colleague Demigod worked mostly on implementing the backend support necessary.
The first big hurdle of the project for me was figuring out how to include the TS code and necessary npm packages to the TinySPARQL codebase without creating bloat for what is supposed to be a very lightweight and low-level package. We ended up using webpack for bundling and then further compressing them into GResources such that only these GResources need to be included in our releases, to be served when a user starts up the web-ide. This quickly addressed my mentors’ concern about having to include npm packages in our releases and ensured we could work comfortably between the TS code and C backend without any troubles.
In terms of actual design and UX work, this went by relatively smoothly, though it did take quite a few feedback cycles to get it to its current state. Click here for a quick demo of the final product.
Just to go over some of the features that have been fully implemented on the web ide frontend:
code editor with full support for SPARQL syntax highlighting and common keyboard shortcuts
error highlighting at corresponding editor positions according to error messages returned by backend
query “bookmarking” via conversion to links
Neat table format for presenting query results, equipped with ontology prefix adaptations and directin linking to relevant documentations
Options to hide/show columns in result tables
Clear error reporting
And here are some features still in progress/waiting to be merged:
Options to query in other rdf formats: trig, turtle and JSON-LD
Examples box for referencing queries that may be useful for certain endpoints
Quick switching between different SPARQL endpoints from the Web IDE interface itself
In terms of future work, some more work needs to be done on our colour scheme as well as the presentation of query results in the other formats offered other than the default cursor format. There were also some discussions in earlier stages of planning about implementing autocomplete and other editor enhancements that we didn’t have enough time for, so there’s still definitely lots of room for improvement. Nonetheless I’m very satisfied and proud of what I’ve achieved in the past few months and will be looking forward to contributing to future improvements of this tool.
Regarding the overall learning experience, one of the most important thing I learned, in my opinoion, was how to keep my git history clean and work with multiple branches of code at the same time without creating conflicts. I feel like this would completely change the experience of whoever I work with in the future as well as myself when I need to go back to some old code. Other than that, I’ve also had little exposure outside web development and working with the GNOME ecosystem was definitely a nice challenge – I’m definitely a lot more confident about dabbling outside my area of expertise now.
Lastly, here’s a list of useful links to the work I’ve been doing over the summer. Thanks for reading this far
As my Outreachy internship comes to a close, I find myself reflecting on the journey with a sense of gratitude. What began with a mix of excitement and fear has turned into a rewarding experience that has shaped my skills, confidence, and passion for open-source contributions.
Overcoming Initial Fears
When I first started, I had some doubts and fears — among them was whether I would fit into the open-source community, I worried that my skills might not translate well to user research, an area I was eager to explore but had limited experience in. However, those fears quickly disappeared as I got myself into the supportive and inclusive GNOME community. I learned that the community values diverse contributions and that there is always room for growth and learning.
Highlights of the Internship
This internship has been a significant period of growth for me. I’ve developed a stronger understanding of user research methodologies, particularly the importance of crafting neutral questions to avoid bias. This was a concept I encountered early in the internship, and it has since become a cornerstone of my research approach. Additionally, I’ve sharpened my ability to analyze and interpret user feedback, which will be invaluable as I continue to pursue UI/UX design.
Beyond technical skills, I’ve also grown in terms of communication. Learning how to ask the right questions, listen actively, and engage with feedback constructively has been crucial. These skills have given me the confidence to interact more effectively within the open-source community.
Mentorship and Project Achievements
My mentors, Allan Day and Aryan Kaushik played a critical role in my development throughout this internship. Their guidance, patience, and willingness to share their expertise made a great difference. They encouraged me to think critically about every aspect of the user research process, helping me to grow not just as a researcher, but as a contributor to the open-source community.
As for my project, I’m proud of the progress I’ve made. I successfully conducted a series of user research exercises and gathered insights that will help improve the usability of some GNOME Apps. However, my work isn’t finished yet — I’m currently in the process of finalizing the usability research report. This report will be a little resource for the GNOME design team, providing detailed findings and recommendations that will guide future improvements.
Throughout this journey, I’ve leaned heavily on the core values I outlined at the start of the internship: Adventure, Contribution, and Optimism. These values have been my compass, guiding me through challenges and reminding me of the importance of giving back to the community. The adventure of stepping into a new field, the joy of making meaningful contributions, and the optimism that every challenge is an opportunity for growth — these principles have been central to my experience.
Reflecting on My Core Values
As I wrap up my time with Outreachy, I feel both proud of what I’ve learned and excited for what lies ahead. I plan to continue my involvement in open-source projects. The skills and confidence I’ve gained during this internship will undoubtedly serve me well in future projects. Additionally, inspired by the mentorship I received, I hope to help mentor others and help them navigate their journeys in open-source contributions.
Finally, this internship has been a transformative experience that has expanded my skill set, deepened my passion for user-focused design, and strengthened my commitment to open-source work. I’m grateful for the opportunity and look forward to staying connected with the GNOME community as I continue to grow and contribute.
Hey everybody, this is another iteration of my previous posts. It’s been a while since I published any updates about my project.
Before I begin with the updates I’d like to thank all of the people who helped me get this far into the project, it wouldn’t have been as engaging and enjoyable of a ride without your support.
For someone reading this blog for the first time, I am Bharat Tyagi. I am a Computer Science major and I have been contributing to the GNOME Project (Workbench in particular) under Google Summer of Code this year.
Since the updates until Week 3 have already been written in greater detail I will only briefly cover them in this report and focus more on the more recent ones.
Project Title
My project is subdivided into three parts:
Port existing demos to Vala
Redesign the Workbench Library and make QoL improvements
Add code search into Workbench
Mentors
Sonny Piers, Andy Holmes
Part 1:
Workbench has a vast library of demos covering every use case for developers or users who would like to learn more about the GTK ecosystem and how each component is connected and works together in unison.
The demos are available in many programming languages including JavaScript, Python, Vala, Rust, and now TypeScript (Thanks to Vixalien for bringing this to Workbench :) ). The first part of my project was to port around 30 demos into Vala. This required me to learn many functions, signals, and how widgets use them to relay information. Since I ported over 30 demos, I’ll mention a few that were fun to port and the list of all the ports that I made, if you’d like a more in-depth review of the process, the Week 3 update is where you should go!
Map (Libshumate)
Maps and CSS gradients don’t just look cool, their code was also fun to port. Support for maps is provided by libshumate, sourcing the world view from OSM (Open Street Map), and supports functions like dragging across the map showing the location for latitudes and longitudes entered, and allowing you to put markers at any point on the map.
CSS Gradients
CSS Gradients allows you to create custom gradients and generate their CSS as the parameters are generated
Session Monitor and Inhibit was another interesting demo to port, as the name goes it allows you to monitor changes and inhibit the desktop from changing state, based on the current state of your application.
You could use the demo for some interesting warnings
After all the ports were done, I moved to make changes to the library
Part 2:
The second part of this project was to redesign the library and bring about quality-of-life improvements.
Sonny prepared a roadmap, including some changes that had already been made, to help break the project down into actionable targets.
Since we wanted to include some filtering based on both language and category, the first step was to move away from the current implementation of the demo rows based on Adw.PreferencesWindow and related widgets, which are easy to use but don’t provide the necessary flexibility.
So I removed their usage with something more universal and that would allow us to reimplement populating the demos. Adw.PreferenceWindow was replaced with Adw.Window,Adw.PreferencesRowwithAdw.ActionRow, and Adw.PreferencesGroup and Page were replaced with simpler Gtk.ScrolledWindow with nested Gtk.Boxand Label
This is how the library looked after these changes
Not much different right? That's a good sign :)
With these out of the way, we could work on making the current search more prominent. Since the search bar was activated by using the search button on the top left of the Library, there were a few people who were unaware of a search being present at all. To resolve this I shifted the search bar inside the library making it directly accessible and quicker to search.
The subsequent code also needed new logic so only the searched demos were visible. I used hash maps to store the currently visible categories and widgets depending on the search term.
//set the widget to be visible if it exists in the map category_map.forEach((category_widget, category_name) => { category_widget.visible = visible_categories.has(category_name); });
Getting the search to function as expected was relieving as it took a few iterations and changes to polish it enough to merge them. I am happy to report the search works just as expected now
See the search in action!
With these minor improvements, we were ready to add filtering to the demos based on the language and categories.
The logic for filtering was inspired by Sonny’s previous approach towards adding this feature (here if you want to check it out). We have two dropdowns one for the category and one for languages. The filtering was done based on the input provided in all of the three widgets (Search, Language dropdown, and Category dropdown), if and only if the search term matches all three of these, the result would be displayed.
//filtering logic const is_match = category_match && language_match && (search_term === "" || search_match); //set visibility if the term matches all three entry_row.visible = is_match; if (is_match) { results_found = true; visible_categories.add(category_check[category_index]); //also add it to the visible categories map }
This was super close to how we wanted the filtering to work. Here is the final result :D
It works!!If you’ve reached this far into the post, this cookie is for you
These are the commits for this part of the project for anyone curious
Having completed the filtering for our Library, now comes in the third part of my project which was to implement code search. Since we have a bunch of demos, storing and accessing search terms efficiently is a challenge. Sonny, Angelo, and I had a meeting to discuss code search which would then build up the starting point for the feature
Andy and I looked at a few options that could be used to implement this feature, majorly focusing on tools that provide working with large amounts of data. TinySPARQL is one such engine, but it is more preferred for files and directories which is not our goal. We need an API that can interact with the sqlite database and run text searches on it.
There are two major libraries under GNOME, libgomand libgda. libgom is an object-relational mapping library, which allows you to map database tables to GObjects and then run operations on those objects. This is in hindsight simpler than libgda, but it doesn't directly provide text-search functionalities on its own like libgda does.
As of writing this article, I have ported a demo example that makes use of libgom and performs a simple text/ID-based search on a single table. This can be scaled to bigger databases like our Library itself, but it starts showing limitations when it comes to more search functions.
Here is a screengrab of the demo, ported into Modern Gjs (GNOME JavaScript) :)
The example this demo is based on was written over 7 years ago
Now that we’ve seen the demo, let's have a look at the libgom magic that is happening in the background
First, we create a custom class that represents an object with properties id and url that we want to store in our table
We then, initialize the database using Gom.Adapter which also opens an SQLite database (for the simplicity of the demo, we’re only storing the contents in memory). A table is set up and mapped to the ItemClass that we previously created. The id field is set as the Primary key.
Once all the preliminary setup is done, I added the logic for basic text searching using a handy filter function in Gom
I use this to filter out the elements, store them in filtered_items, and display them in the table itself, voila
The PR is approved but yet to be merged, it will take some time before it reaches your Workbench. But if you would like to tinker around and make improvements to it, this is the PR
The plan right now is to implement search into the Library first using libgom and then later moving to libgda which is more versatile and provides full-text search functionalities using SQL queries without having to route them through GObjects.
Acknowledgments and Learnings
I am very thankful for the insights and guidance of my mentors, Andy and Sonny. They were quick to jump in whenever I encountered a blocker. They are awesome people with a strong passion for what they do, it’s been an honor to be able to contribute however little I was able to. I strive to be at their level someday.
This summer has been fruitful and fun for me. The most important thing I learned is to be curious and always ask questions.
A big thank you to Diego and Lorenz for reviewing all of the ports and providing much necessary improvements!
For the readers, I am pleasantly surprised that you were able to reach the end without scrolling away, thank you so much for tuning in and taking out time to read through. I hope this was just as fun for you to read as it was for me to write it :D
I’ll continue to stay in touch with everyone I have met and talked to during these few months because they are simply awesome!
I am pleased to announce a new development release of Cambalache, version 0.91.3, getting us one step closer to the stable release for GNOME 47.
What’s new:
Support 3rd party libraries
Improved Drag&Drop support
Streamline headerbar
Ported treeview to column view
Several bug fixes
3rd party libraries
Cambalache now loads 3rd party catalogs from Load catalogs from GLib.get_system_data_dirs()/cambalache/catalogs and ~/.cambalache/catalogs
These catalog files are generated from Gir data with tools/cambalache-db.py script. Currently this is an internal tool which means it needs some work and documentation to make it easier to use but you can see an example of how its used internally here
So what is a catalog anyway?
A catalog is a XML file with all the necessary data for cambalache to produce UI files with widgets from a particular library, this includes the different GTypes, with their properties, signals and everything else except the actual object implementations.
Runtime objects are created in the workspace by loading the GI namespace specified in the catalog.
So please, feel free to contact me on matrix if you are interested in adding support for a 3rd party library.
Improved Drag&Drop support
After the extensive rework done porting the main widget hierarchy from GtkTreeView to GtkColumnView and implementing several GListModel interfaces to avoid maintaining multiple lists I was able to reimplement and extend Drag&Drop code so now its possible to drop widgets in different parents.
Long version: When UEFI Secure Boot was specified, everyone involved was, well, a touch naive. The basic security model of Secure Boot is that all the code that ends up running in a kernel-level privileged environment should be validated before execution - the firmware verifies the bootloader, the bootloader verifies the kernel, the kernel verifies any additional runtime loaded kernel code, and now we have a trusted environment to impose any other security policy we want. Obviously people might screw up, but the spec included a way to revoke any signed components that turned out not to be trustworthy: simply add the hash of the untrustworthy code to a variable, and then refuse to load anything with that hash even if it's signed with a trusted key.
Unfortunately, as it turns out, scale. Every Linux distribution that works in the Secure Boot ecosystem generates their own bootloader binaries, and each of them has a different hash. If there's a vulnerability identified in the source code for said bootloader, there's a large number of different binaries that need to be revoked. And, well, the storage available to store the variable containing all these hashes is limited. There's simply not enough space to add a new set of hashes every time it turns out that grub (a bootloader initially written for a simpler time when there was no boot security and which has several separate image parsers and also a font parser and look you know where this is going) has another mechanism for a hostile actor to cause it to execute arbitrary code, so another solution was needed.
And that solution is SBAT. The general concept behind SBAT is pretty straightforward. Every important component in the boot chain declares a security generation that's incorporated into the signed binary. When a vulnerability is identified and fixed, that generation is incremented. An update can then be pushed that defines a minimum generation - boot components will look at the next item in the chain, compare its name and generation number to the ones stored in a firmware variable, and decide whether or not to execute it based on that. Instead of having to revoke a large number of individual hashes, it becomes possible to push one update that simply says "Any version of grub with a security generation below this number is considered untrustworthy".
So why is this suddenly relevant? SBAT was developed collaboratively between the Linux community and Microsoft, and Microsoft chose to push a Windows update that told systems not to trust versions of grub with a security generation below a certain level. This was because those versions of grub had genuine security vulnerabilities that would allow an attacker to compromise the Windows secure boot chain, and we've seen real world examples of malware wanting to do that (Black Lotus did so using a vulnerability in the Windows bootloader, but a vulnerability in grub would be just as viable for this). Viewed purely from a security perspective, this was a legitimate thing to want to do.
(An aside: the "Something has gone seriously wrong" message that's associated with people having a bad time as a result of this update? That's a message from shim, not any Microsoft code. Shim pays attention to SBAT updates in order to avoid violating the security assumptions made by other bootloaders on the system, so even though it was Microsoft that pushed the SBAT update, it's the Linux bootloader that refuses to run old versions of grub as a result. This is absolutely working as intended)
The problem we've ended up in is that several Linux distributions had not shipped versions of grub with a newer security generation, and so those versions of grub are assumed to be insecure (it's worth noting that grub is signed by individual distributions, not Microsoft, so there's no externally introduced lag here). Microsoft's stated intention was that Windows Update would only apply the SBAT update to systems that were Windows-only, and any dual-boot setups would instead be left vulnerable to attack until the installed distro updated its grub and shipped an SBAT update itself. Unfortunately, as is now obvious, that didn't work as intended and at least some dual-boot setups applied the update and that distribution's Shim refused to boot that distribution's grub.
What's the summary? Microsoft (understandably) didn't want it to be possible to attack Windows by using a vulnerable version of grub that could be tricked into executing arbitrary code and then introduce a bootkit into the Windows kernel during boot. Microsoft did this by pushing a Windows Update that updated the SBAT variable to indicate that known-vulnerable versions of grub shouldn't be allowed to boot on those systems. The distribution-provided Shim first-stage bootloader read this variable, read the SBAT section from the installed copy of grub, realised these conflicted, and refused to boot grub with the "Something has gone seriously wrong" message. This update was not supposed to apply to dual-boot systems, but did anyway. Basically:
1) Microsoft applied an update to systems where that update shouldn't have been applied 2) Some Linux distros failed to update their grub code and SBAT security generation when exploitable security vulnerabilities were identified in grub
The outcome is that some people can't boot their systems. I think there's plenty of blame here. Microsoft should have done more testing to ensure that dual-boot setups could be identified accurately. But also distributions shipping signed bootloaders should make sure that they're updating those and updating the security generation to match, because otherwise they're shipping a vector that can be used to attack other operating systems and that's kind of a violation of the social contract around all of this.
It's unfortunate that the victims here are largely end users faced with a system that suddenly refuses to boot the OS they want to boot. That should never happen. I don't think asking arbitrary end users whether they want secure boot updates is likely to result in good outcomes, and while I vaguely tend towards UEFI Secure Boot not being something that benefits most end users it's also a thing you really don't want to discover you want after the fact so I have sympathy for it being default on, so I do sympathise with Microsoft's choices here, other than the failed attempt to avoid the update on dual boot systems.
Anyway. I was extremely involved in the implementation of this for Linux back in 2012 and wrote the first prototype of Shim (which is now a massively better bootloader maintained by a wider set of people and that I haven't touched in years), so if you want to blame an individual please do feel free to blame me. This is something that shouldn't have happened, and unless you're either Microsoft or a Linux distribution it's not your fault. I'm sorry.
This blog post summarizes the discussions and action items from the Infrastructure and Release Engineering workshop held at Flock 2024 in Rochester, New York, USA.
This post is also an experiment in using AI generated summaries to provide useful, at-a-glance summaries of key Fedora topics. Parts of this content may display inaccurate info, including about people, so double-check with the source material.
Standards for OpenShift app deployments: There’s a need for consistency in deploying applications to OpenShift. The group discussed creating best practices documentation and addressing deployment methods across various applications.
Infra SIG packages: The workshop reviewed the “infra-sig” package group and identified a need to:
Find owners for orphaned packages.
Onboard new maintainers using Packit.
Remove inactive members from the group.
Release engineering packages: The group agreed to add a list of release engineering packages to the infra-sig for better management.
Proxy network: Discussion about potentially migrating the proxy network from httpd to nginx or gunicorn remained inconclusive. Further discussion is needed.
AWS management with Ansible: The feasibility of managing AWS infrastructure with Ansible is uncertain due to limitations with the main Amazon account.
Onboarding improvements: The group discussed ways to improve the onboarding process for new contributors, including documentation updates, marketing efforts, and “Hello” days after each release.
OpenShift apps deployment info: A tutorial on deploying applications to OpenShift was presented and will be incorporated into the documentation.
Future considerations: The group discussed upcoming challenges like GitLab Forge migration, Bugzilla migration, and a new Matrix server.
Retiring wiki pages: The group needs to decide where to migrate user-facing documentation from the wiki. Additionally, someone needs to review and archive/migrate/delete existing wiki pages in the “Category:Infrastructure” section.
Datagrepper access for CommOps: A solution was proposed to provide CommOps with access to community metrics data by setting up a separate database in AWS RDS and populating it with recent Datagrepper dumps.
ARA in infrastructure: While AWX deployment offers similar reporting features, setting up ARA remains an option if someone has the time and interest.
AWX deployment: Roadblocks related to the public/private Ansible repository structure were identified. A proof of concept using AWX will be pursued to determine if repository restructuring is necessary.
Zabbix integration: The group discussed moving forward with Zabbix to replace Nagios. Action items include setting up a bot channel for alerts, adjusting alerts based on comparison with Nagios, and considering an upgrade to the next LTS version.
Action Items
Create comments in each application playbook explaining its deployment method.
Move all apps using deploymentconfig to deployment with OpenShift 4.16.
Look into deploying Advanced Cluster Security (ACS) for improved visibility into container images.
Create a “best practices” guide for deploying applications in OpenShift clusters.
Find individuals interested in helping with orphaned packages and onboarding new maintainers for the infra-sig package group.
Create a list of release engineering packages for inclusion in the infra-sig.
Continue discussions on migrating the proxy network and managing AWS infrastructure with Ansible.
Update onboarding documentation, implement marketing strategies for attracting contributors, and organize “Hello” days for new members.
Archive/migrate/delete wiki pages in the “Category:Infrastructure” section.
Work on tickets to set up a separate database for CommOps Datagrepper access.
Investigate the feasibility of setting up ARA in infrastructure.
Stand up a proof of concept for AWX deployment and discuss potential repository restructuring.
Set up a Zabbix bot channel for alerts, adjust alerts based on comparisons with Nagios, and consider upgrading to the next LTS version.
Overall, the workshop was a success, with productive discussions and a clear list of action items to move forward.
Note: The workshop lacked remote participation due to network limitations. The source material encourages readers to express interest in helping with the action items.
Meson has had togglable options from almost the very beginning. These split into two camps. The first one is "common options" like optimizations, warning level, language standard version and so on. The second one is "per project" options that are specific to each project, such as which backend to use. For a long time things were quite nice but as people started using subprojects more and more, the need to configure common options on a per-subproject basis became more and more important.
Meson added a limited way of setting some options per subproject, but it was never really felt like a proper integrated solution. Doing it properly turns out to have a lot of requirements because you want to be able to:
Override any shared option for any subproject
Do this at runtime from the command line
You want to unset any override given
Convert existing per-project settings to the new override format
Provide an UI that is readable and sensible
Do all of this without needing to edit subproject build files
The last one of these is important. It means that you can use deps directly (i.e. from WrapDB) without any local patches.
What benefits do you get out of it?
The benefits are most easily seen via examples. Let's say you are developing a program that uses a dependency that does heavy number crunching. You need to build that (and only that) subproject with optimizations enabled, otherwise your development experience is intolerably slow. This is done by defining an augment, like so:
meson configure -Acruncher:optimization=2
A stronger version of this would be to compile all subprojects with optimizations but the top level project without them. This is how you'd do it:
This scheme permits you to do all sorts of useful things, like disable -Werror on specific projects, build some subprojects with a different language version (such as gnu99), compiling LGPL deps as shared libraries and everything else as a static library, and so on.
Implementing
This is a big internal change. How big? Big! This is the largest refactoring operation I have done in my life. It is big enough that it took me over two years of procrastination before I managed to gather enough strength to start work on this. Pretty much all of my Meson work in the last six months or so has been spent on this one issue. The feature is still not done, but the merge request already has 80 commits and 1700+ new lines and even that is an understatement. I have chopped off bits of the change and merged them on their own. All in all this meant that the schedule for most days of my summer vacation went like this:
Wake up
Work on Meson refactoring branch until fed up
Work on my next book until fed up
Maybe do something else
Sleep
FTR I don't recommend this style of working for anyone else. Or even to myself. But sometimes you just gotta.
The main reason this change is so complex lies in the architecture. In existing code each built target "knew" the option settings needed for it (options could and can be overridden in build files on a per-target basis). This does not work any more. Instead the code needs one place that encapsulates all option data and provides methods like "what is the value of option X when building target Y in subproject Z". Option code was everywhere, so changing this meant touching the entire code base and that the huge change blob must be landed in master atomically.
The only thing that made this change even remotely feasible was that Meson has an extensive test suite. The main code changes were done months ago, and all work since then has gone into making existing unit tests pass. They still don't pass, so work continues. Without this test suite there would have been hundreds of regressing projects, people would be angry and everyone would pin their Meson to an old version and refuse to update. These are the sorts of breakages that kill projects dead. So, write tests, even if it does not seem fun. Without them every project will eventually end up in a fork in the road where the choice is between "death by stagnation" and "death by breaking end users". Most projects are not Python 3. They probably won't survive a similar level of breakage.
Refactoring, types and Python
Python is, at the same time, my favourite programming language and very much not my favourite programming language. Python in the small is nice, readable, wonderful and productive. As the project size grows, the lack of static types becomes aggravating and eventually you end up debugging cases like "why does this argument that should be a dict is an array one out of 500 times at random". Types make these problems go away and make refactoring easy.
But not always.
For this very specific case the complete lack of types actually made the refactoring easier. Meson currently supports more than one hundred different compilers. I needed to change the way compiler classes work, but I did not know how. Thus I started by just using the GNU C compiler. I could change that (and its base class) as much as I wanted without having to care about any other compiler class. As long as I did not use any other compiler their code was not called and it did not matter that their method signatures were completely different. In a static language all type changed would need to be done up front just to make the dang thing compile.
Still, you can have my types when you drag them from my cold, dead fingers. But maybe this is something for language designers of the future to consider. It would be kind of cool to have a strictly typed language where you could add a compiler flag to say "convert all variables into Python style variant dictionaries and make all type checks, method invocations etc work at runtime". Yes, people would abuse the crap out of this feature, but the same can be said about every new feature.
When will this land?
It is not done yet, so we don't know. At the earliest this will be in the next release, but more likely in the one after that.
If you like trying out new things and living dangerously, you can try the code from this MR. Be sure to post comments on that page if you do.
This blog post has been floating around as a draft for several years. It eventually split off into a presentation at GUADEC 2022, titled Offline learning with GNOME and Kolibri (YouTube). In that presentation, Manuel Quiñones and I explained how Endless OS reaches a unique audience by providing Internet-optional learning resources, and we provided an overview of our work with Kolibri. This post goes into more detail about the technical implementation of the Kolibri desktop app for GNOME, and in particular how it integrates with Endless OS.
Integrating a flatpak app with an immutable OS
In Endless OS, way back with Endless OS 4 in 2021, we added Kolibri, an app created by Learning Equality, as a new way to discover educational content. Kolibri has a rich library of video lessons, games, documents, e-books, and more; as well as tools for guided learning – both for classrooms, and for families learning at home. The curation means it is safe and comfortable to freely explore. And all of this works offline, with everything stored on your device.
Making this all come together was an interesting challenge, but looking back on it with Endless OS 6 alive and well, I can say that it worked out nicely.
The Kolibri app for GNOME
Learning Equality designed Kolibri with offline, distributed learning in mind. While an organization can run a single large Kolibri instance that everyone reaches with a web browser, it is equally possible for a group of people to use many small instances of Kolibri, where those instances connect with each other intermittently to exchange information. The developers are deeply interested in sneaker net-style use cases, and indeed Kolibri’s resilience has allowed it to thrive in many challenging situations.
Despite using Django and CherryPy at its heart, Kolibri often presents itself as a desktop app which expects to run on end user devices. Behind the scenes, the existing Windows and MacOS apps each bundle a Kolibri server, running it in the background for as long as the desktop app is running.
We worked with Learning Equality to create a new Kolibri app for GNOME. It uses modern GTK with WebKitGTK to show Kolibri itself. It also includes a desktop search provider, so you can search for Kolibri content from anywhere.
The Kolibri GNOME app is distributed as a flatpak, so its dependencies are neatly organized, it runs in a well-defined sandbox, and it is easy to install it from Flathub. For Endless OS, using flatpak means it is trivial to update Kolibri independent from Endless OS’s immutable base system.
Kolibri Daemon
But Endless OS doesn’t just include Kolibri. One of my favourite parts of Endless OS is it provides useful content out of the box, which is great for people with limited internet access. So in addition to Kolibri itself, we want a rich library of Kolibri content pre-installed. And with so much already there, ready to be used, we want it to be easy for people to search for that content right away and start Kolibri for the first time.
If we add more users, each with their own Kolibri content, we can imagine the size of that database becoming a problem.
This becomes both a technical challenge and a philosophical challenge. Normally, each desktop user has their own instance of Kolibri, with its own hidden directory full of content. Because it is a flatpak, it normally doesn’t see the rest of the system unless we explicitly give it permission to, and every time we do that we need to think carefully about what it means. Should we really grant a WebView the ability to read and write /run/media? We try to avoid it.
At the same time, we want a way to create new apps which use content from Kolibri, so that library of pre-installed content is visible up front, from the apps grid. But it would beexpensive if each of these apps ran its own instance of Kolibri. And whatever solution we employ, we don’t want to diverge significantly from the Kolibri people are using outside of Endless OS.
To solve these problems, we split the code which starts and stops the Kolibri service into a separate component, kolibri-daemon. The desktop app (kolibri-gnome) and the search provider each communicate with kolibri-daemon using D-Bus.
The desktop app communicates through kolibri-daemon, instead of starting Kolibri itself.
This design is exactly what happens when you start the Kolibri app from Flathub. And with the components neatly separated, on Endless OS we add eos-kolibri, which takes it a step further: it adds a kolibri system user and a service which runs kolibri-daemon on the D-Bus system bus. The resulting changes turn out to be straightforward, because D-Bus provides most of what we need for free.
Kolibri on Endless OS is almost the same, except kolibri-daemon is run by the Kolibri system user.
With this in place, every user on the system shares the same Kolibri content, and it is installed to a single well-known location: /var/lib/kolibri. Now, pre-installing Kolibri content is a problem we can solve at the system level, and in the Endless OS image builder. Independent from the app itself.
Channel apps
Now that we have solved the problem of Kolibri content being duplicated, we can come back to having multiple apps share the same Kolibri service. In Endless OS, we want users to easily see the content they have installed, and we do this by adding launchers to the apps grid.
First, we need to create those apps. If someone has installed content from a Kolibri channel like TED-Ed Lessons or Blockly Games, we want Kolibri to generate a launcher for that channel.
But remember, Kolibri on Endless OS is an unprivileged system service. It can’t talk to the DynamicLauncher portal. That belongs to the user’s session, and we want these launchers to be visible before a user ever starts Kolibri in their own session. Kolibri also can’t be creating files in /usr/share/applications. That would be far too much responsibility.
Instead, we add a Kolibri plugin to generate desktop entries for channels. The desktop entries refer to the Kolibri app using a custom URI scheme, a layer of indirection because Kolibri (potentially inside a flatpak) is unaware of how the host system launches it. The URI scheme provides enough information to start in a channel-specific app mode, instead of in its default configuration.
Finally, instead of placing the desktop entry files in one of the usual places, we place them in a well-known location inside Kolibri’s data directory. That way the channel apps are available, but not visible by default.
In Endless OS, the channel launchers end up in /var/lib/kolibri/data/content/xdg, so in our system configuration we add that directory to XDG_DATA_DIRS. This turns out to be a good choice, because it is trivial to start generating search providers for those apps, as well.
Kolibri channels along with other Education apps in Endless OS.
Search providers
To make sure people can find everything we’ve included in Endless OS, we add as many desktop search providers as we can think of, and we encourage users to explore them. The search bar in Endless OS is not just for apps.
That means we need a search provider for Kolibri. It’s a simple enough problem. We extended kolibri-daemon‘s D-Bus interface with its own equivalents for the GNOME Shell search provider interface. It is capable of reading directly from Kolibri’s database, so we can avoid starting an HTTP server. But we also want to avoid dealing with kolibri-daemon as much as possible. It is a Python process, heavy with web server stuff and complicated multiprocessing code. And, besides, the daemon could be connecting to the D-Bus system bus, and the shell only talks to search providers on the session bus. That’s why the search provider itself is a separate proxy application, written in C.
Kolibri returning search results in GNOME Shell.
But in Endless OS, we don’t just need one search provider, either. We want one for each of those channel apps we generated. So, I mentioned that our Kolibri plugin generates a search provider to go with each desktop file. Of course, loading and searching through Kolibri’s sqlite database is already expensive once, so it would be absurd to do it for every channel that is installed. That’s a lot of processes!
Fortunately, those search providers are all the same D-Bus service, with a different object path for each Kolibri channel. That one D-Bus service receives a lot of identical search queries for a lot of different object paths, but at least the system is only starting one process for it all. In the search provider code, I added a bespoke task multiplexer, which allows the service to run a single search in kolibri-daemon for a given query, then group the results and return them to different invocations from the shell.
Kolibri returning search results through several channel apps in Endless OS.
It is a complicated workaround, but it means search results appear in distinct buckets with meaningful names and icons. For our purpose in Endless OS, it was definitely worth the trouble.
User accounts
There was one last wrinkle here: Kolibri kept asking people to set it up, make a user account (with a password!), and sign in. It is, after all, a standalone learning app with a big complicated database that keeps track of learning progress and understands how to sync content between devices. But this isn’t a great experience if you’re just here to watch that lecture about cats.
What we want is for Kolibri to already know who is accessing it. They’re already signed in as a desktop user. And most of the time, we want to blaze right through that initial “set up your device” step, or at least make it as smooth as possible.
To do that, we added an interface in kolibri-daemon so the desktop app can get an authentication token to use over HTTP. On the other side, kolibri-daemon privately communicates with Kolibri itself to verify an authentication token, and it communicates with logind to build a profile for the authenticating user.
It was ugly at first, with a custom kolibri-desktop-auth-plugin which sat on top of Kolibri’s authentication system. But after some iteration, upstream Kolibri now has its own understanding of desktop users. On the surface, it uses Kolibri’s app interface plugin for platform integration. With the newest version of Kolibri we have been able to solve authentication in a way that I am properly happy with.
My favourite part of the feature has been seeing it come together with Kolibri’s first run wizard. Given a working authentication token, Kolibri knows to skip creating an initial user account, leaving only some simple questions about how the user is planning to use Kolibri; independently or connecting to an existing classroom.
That’s it!
It has been great to work on the Kolibri desktop app, and I expect to take some of the approaches and lessons here over to other projects. It is the first big new Python desktop app I have worked with, and it was interesting using some modern Python tools in tandem with the GNOME ways of doing things. The resulting codebase has some fun details:
The source repository includes a Flatpak manifest, so it builds and runs out of the box in GNOME Builder. As soon as that was working, I used Builder for everything.
Meson is truly indispensable for this kind of thing. We’re sharing build configuration between a bunch of Python modules, all sorts of configuration and data files, and a pair of C projects – one of which is imported by a Python module using GObject introspection. This all works (in a mere 577 lines of meson.build, if you’re counting) because the build system is language-agnostic, and I love it for that. I know that isn’t a lot to ask, but the go-to for Python is decidedly not language-agnostic, and I do not love it.
We added pre-commit to automatically clean up source files and run quick tests against them. It doesn’t actually require you have a Python codebase, but it is written in Python and I think people are afraid of how Pythony it looks? It’s really convenient, and it does a good job taking care of the usual nightmare of setting up a virtual environment to run all its tools. I often don’t bother with the actual git hook part, and instead I remember to run the thing manually, and we use the pre-commit github action to be sure.
At some point, I added Python type hinting to every part of the project. This tremendously improved the development experience with Builder, and it allowed me to add a mypy pre-commit hook to catch mistakes.
I got annoyed at the problem of needing to write release notes in the appdata file before knowing what the next release is called, so I devised a fun scheme where we add notes under "{current_version}+next", and then bump-my-version (another tool that looks very Pythony but everyone should use it) knows to mark that release entry as released, setting the date and version appropriately. I wish it didn’t involve regex, but as a concept it has been nice to use. I was tempted to write a pre-commit hook which actually insists on an up to date “next release” entry in appdata, but I should find another project to try it with.
With that said, a better workflow probably involves appstream-util news-to-appdata.
Managing history in WebKit can be tricky because the BackForwardList is read-only. That was an issue with the Kolibri app because we (with our UI consisting almost entirely of a WebView) need to communicate about Kolibri’s state before its HTTP server is running. Kolibri upstream provides a static HTML loading screen for this purpose, which is fine, but now we have this file in our WebView’s back / forward list. I solved it by swapping between different WebViews, and later showing one in a dialog just for Kolibri’s setup wizard. At first, that was all to keep the history stack organized, but at the same time I found it made the app feel a little less like a web browser in a trench coat. We can switch from the loading WebView to the real thing with a nice crossfade, and only when the UI is actually for real finished loading.
This whole project uses a lot of GObject throughout. At some point I finally read the pygobject manual and found myself happily doing property binding, signals and async functions and all those good things from Python. It was a much better experience than earlier in the project’s life where there was a type of angry mishmash between vanilla Python and GObject. (The thing that really freed this up was when I moved a lot of D-Bus code over to a C helper library with gdbus-codegen, which allowed me to delete the equivalent duplicative Python code, and also introduced a bunch more GObject). It’s easy to see why GObject works best with a language that doesn’t carry its own big standard library, but I was happy with how productive I could be in Python once I started actively preferring GObject, especially with the various magic helpers provided by PyGObject. In a future starting-from-scratch project, I would be tempted to make that a rule when adding imports and writing new classes.
I have to admit I got carried away with certain aspects of this. In the end there is a certain discontent to be had spending creative energy on what is, from many angles, a glorified web browser. It’s frustrating when the web stack leads us to treat an application as a black box behind an HTTP interface, which makes integration difficult: boot it up (in its own complex runtime environment which is heroically not a Docker container); wait until it is ready (Kolibri is good at this, but sometimes you’re just watching a file or polling some well-known port); authenticate; ask it (over HTTP) some trivial question that amounts to a single SQL command; return None. But look at that nice framework we’re using!
At the same time, it isn’t lost on me that a software stack like Kolibri’s simply is a popular choice for a cross-platform app. It’s worth understanding how to work with it in a way that still does the best we can to be useful, efficient, and comfortable to use.
Beyond all the tech stuff, I want to emphasize that Kolibri is an exceptionally cool project. I truly admire what Learning Equality are doing with it, and if you’re interested in offline-first content, data sovereignty, or just open source learning in general, I highly recommend checking it out – either our app on Flathub, or at learningequality.org/kolibri.
Most end-user platforms have something they call an intent system or something
approximating the idea. Implementations vary somewhat, but these often amount
to a high-level desktop or application action coupled to a URI or mime-type.
There examples of fancy URIs like sms:555-1234?body=on%20my%20way that can do
intent-like things, but intents are higher-level, more purposeful and certainly
not restricted to metadata shoehorned into a URI.
I'm going to approach this like the original proposal by David Faure and the
discussions that followed, by contrasting it with mime-types and then
demonstrating what the files for some real-world use cases might look like.
Let's start with the mime-apps Specification. For desktop environments
mime-types are, most of all, useful for associating content with applications
that can consume it. Once you can do that, the very next thing you want is
defaults and fallback priorities. Now can you double-click stuff to have your
favourite application open it, or right-click to open it with another of your
choice. Hooray.
We've also done something kind of clever, by supporting URI handlers with the
special x-scheme-handler/* mime-type. It is clever, it does work and it was
good enough for a long time. It's not very impressive when you see what other
platforms are doing with URIs, though.
Moving on to the Implements key in the Desktop Entry Specification, where
applications can define "interfaces" they support. A .desktop file for an
application that supports a search interface might look like this:
The last line is a list of interfaces, which in this case is the D-Bus interface
used for the overview search in GNOME Shell. In the case of the
org.freedesktop.FileManager1 interface we could infer a default from the
preferred inode/directory mime-type handler, but there is no support for
defining a default or fallback priority for these interfaces.
While researching URI handlers as part of the work funded by the STF, Sonny
reached out to a number developers, including Sebastian Wick, who has been
helping to push forward sandboxing thumbnailers. The proposed intent-apps
Specification turns out to be a sensible way to frame URI handlers, and other
interfaces have requirements that make it an even better choice.
In community-driven software, we've operated on a scratch-an-itch priority
model for a very long time. At this point we have several, arguably critical,
use cases for an intent system. Some known use cases include:
Default Terminal
This one should be pretty well known and a good example of when you might
need an intent system. Terminals aren't really associated with anything, let
alone a mime-type or URI scheme, so we've all been hard-coding defaults for
decades now. See the proposed terminal-intent Specification for details.
Thumbnailers
If C/C++ are the languages responsible for most vulnerabilities, thumbnailers
have to be high on the list of application code to blame. Intents will allow
using or providing thumbnailing services from a sandboxed application.
URI Handler
This intent is probably of interest to the widest range of developers, since
it allows a lot freedom for independent applications and provides assurances
relied on by everything from authentication flows to personal banking apps.
Below is a hypothetical example of how an application might declare it can
handle particular URIs:
While the Desktop Entry specification states that interfaces can have a named
group like above, there are no standardized keys shared by all interfaces. The
Supports key proposed by Sebastian is important for both thumbnailers and URI
handlers. Unlike a Terminal which lacks any association with data, these need
the ability to express additional constraints.
So the proposal is to have the existing Implements key work in tandem with
the intentapps.list (similar to the MimeType key and mimeapps.list), while
the Supports key allows interfaces to define their own criteria for defaults
and fallbacks. Below is a hypothetical example of a thumbnailer's .desktop
file:
The Supports key will always be a list of strings, but the values themselves
are entirely up to the interface to define. To the intent system, these are
simply opaque tags with no implicit ordering. In the URI handler we may want
this to be a top-level domain to prevent things like link hijacking, while
thumbnailers want to advertise which mime-types they can process.
In the intentapps.list below, we're demonstrating how one could insist that a
particular format, like sketchy SVGs, are handled by Loupe:
We're in a time when Linux users need to do things like pass an untrusted file
attachment, from an unknown contact, to a thumbnailer maintained by an
indepedent developer. So while the intent-apps Specification itself is
superficially quite simple, if we get this right it can open up a lot of
possibilities and plug a lot of security holes.
First a bit of context for the GLib project, which is comprised of three main
parts: GLib, GObject and GIO. GLib contains things you'd generally get from a
standard library, GObject defines the OOP semantics (methods/properties/signals,
inheritance, etc), and GIO provides reasonably high-level APIs for everything
from sockets and files to D-Bus and Gio.DesktopAppInfo.
The GLib project as a whole contains a substantial amount of the XDG
implementations for the GLib/GTK-lineage of desktop environments. It also
happens to be the layer we implement a lot of our cross-platform support, from
OS-level facilities like process spawning on Windows to desktop subsystems like
sending notifications on macOS.
Fig. 1. A GLib Maintainer
The merge request I drafted for the initial implementation received what
might look like Push Back, but this should really be interpreted as a Speed
Bump. GLib goes a lot of places, including Windows and macOS, thus we need
maintainers to make prudent decisions that allow us to take calculated risks
higher in the stack. It may also be a sign that GLib is no longer the first
place we should be looking to carry XDG implementations.
Something that you may be able to help with, is impedance-matching our
implementation of the intent-apps Specification with its counterparts in the
Apple and Microsoft platforms. Documentation is available (in varying quality),
but hands-on experience would be a great benefit.
Last year, I was invited by Sonny Piers to co-mentor for both Google Summer
of Code and Outreachy, which was really one the best times I've had in the
community. He also invited a couple of us Workbenchers from that period to
the kick-off meeting for this year's projects.
Recently, he asked if I could step in and help out with this year's programs.
This is a very unfortunate set of circumstances to arise during an internship
program, but regardless, I'm both honored and thrilled.
I think there's good chance you've run into one of our mentees this year,
Shem Angelo Verlain (aka vixalien). He's been actively engaging in the GJS
community for some time and contributing to better support for TypeScript,
including his application Decibels which is in incubation to become a part of
GNOME Core. His project to bootstrap TypeScript support in Workbench is going
to play an important role in its adoption by our community.
Our other mentee, Bharat Atbrat, has a familiar origin story. It started as an
innocent attempt to fix a GNOME Shell extension, turned into a merge request
for GNOME Settings, rolled over into porting Workbench demos to Vala and it's
at this point one admits to oneself they've been nerd-sniped. Since then, Bharat
has been porting more demos to Vala and working on an indexed code search for
the demos. As a bonus, we will get a GOM demo that's being used to prototype
and test searching capabilities.
The release notes are not yet finalized for GNOME 47, but there are few
highlights worth mentioning.
There have been several improvements to the periodic credential checks, fixing
several false positives and now notifying when an account needs to be
re-authenticated. The notification policy in GNOME 47.beta turned out overly
aggressive, so it has been amended to ensure you are notified at most once per
account, per session.
Fig. 2. Entirely Reasonable Notification Policy
For Kerberos users, there is rarely any exciting news, however after
resurrecting a merge request by Rishi (a previous maintainer) and some help,
we now support Linux's general notification mechanism as a very efficient
alternative to the default credential polling. If you're using your Kerberos or
Fedora account on a laptop or GNOME Mobile, this may improve your battery life
noticeably.
The support for Mail Autoconfig and improved handling of app passwords for
WebDAV accounts will ship in GNOME 47. The DAV discovery and Mail Autoconfig
will form the base of the collection provider, but this won't ship until
GNOME 48. Aside from time constraints, this will allow a cycle to shake out
bugs while the existing pieces are stitched together.
The Microsoft 365 provider has enabled support for email, calendar and
contacts, thanks to more work by Jan Michael-Brummer and Milan Crha. This
is available in GNOME OS Nightly now, so it's great time to get in some
early testing. We've made progress on verifying our application to supports more
organizational accounts and, although this is not constrained by our release
schedule, I expect it to be resolved by GNOME 47.
Many thanks again to the Sovereign Tech Fund and everyone who helped make it
possible. I would also like to express my appreciation to everyone who helps me
catch up on the historical context of the various XDG and GLib facilities. Even
when documentation exists, it can be extremely arduous to put the picture
together by yourself.
(The issues described in this post have been fixed, I have not exhaustively researched whether any other issues exist)
Feeld is a dating app aimed largely at alternative relationship communities (think "classier Fetlife" for the most part), so unsurprisingly it's fairly popular in San Francisco. Their website makes the claim:
Can people see what or who I'm looking for? No. You're the only person who can see which genders or sexualities you're looking for. Your curiosity and privacy are always protected.
which is based on you being able to restrict searches to people of specific genders, sexualities, or relationship situations. This sort of claim is one of those things that just sits in the back of my head worrying me, so I checked it out.
First step was to grab a copy of the Android APK (there are multiple sites that scrape them from the Play Store) and run it through apk-mitm - Android apps by default don't trust any additional certificates in the device certificate store, and also frequently implement certificate pinning. apk-mitm pulls apart the apk, looks for known http libraries, disables pinning, and sets the appropriate manifest options for the app to trust additional certificates. Then I set up mitmproxy, installed the cert on a test phone, and installed the app. Now I was ready to start.
What became immediately clear was that the app was using graphql to query. What was a little more surprising is that it appears to have been implemented such that there's no server state - when browsing profiles, the client requests a batch of profiles along with a list of profiles that the client has already seen. This has the advantage that the server doesn't need to keep track of a session, but also means that queries just keep getting larger and larger the more you swipe. I'm not a web developer, I have absolutely no idea what the tradeoffs are here, so I point this out as a point of interest rather than anything else.
Anyway. For people unfamiliar with graphql, it's basically a way to query a database and define the set of fields you want returned. Let's take the example of requesting a user's profile. You'd provide the profile ID in question, and request their bio, age, rough distance, status, photos, and other bits of data that the client should show. So far so good. But what happens if we request other data?
graphql supports introspection to request a copy of the database schema, but this feature is optional and was disabled in this case. Could I find this data anywhere else? Pulling apart the apk revealed that it's a React Native app, so effectively a framework for allowing writing of native apps in Javascript. Sometimes you'll be lucky and find the actual Javascript source there, but these days it's more common to find Hermes blobs. Fortunately hermes-dec exists and does a decent job of recovering something that approximates the original input, and from this I was able to find various lists of database fields.
So, remember that original FAQ statement, that your desires would never be shown to anyone else? One of the fields mentioned in the app was "lookingFor", a field that wasn't present in the default profile query. What happens if we perform the incredibly complicated hack of exporting a profile query as a curl statement, add "lookingFor" into the set of requested fields, and run it?
Oops.
So, point 1 is that you can't simply protect data by having your client not ask for it - private data must never be released. But there was a whole separate class of issue that was an even more obvious issue.
Looking more closely at the profile data returned, I noticed that there were fields there that weren't being displayed in the UI. Those included things like "ageRange", the range of ages that the profile owner was interested in, and also whether the profile owner had already "liked" or "disliked" your profile (which means a bunch of the profiles you see may already have turned you down, but the app simply didn't show that). This isn't ideal, but what was more concerning was that profiles that were flagged as hidden were still being sent to the app and then just not displayed to the user. Another example of this is that the app supports associating your profile with profiles belonging to partners - if one of those profiles was then hidden, the app would stop showing the partnership, but was still providing the profile ID in the query response and querying that ID would still show the hidden profile contents.
Reporting this was inconvenient. There was no security contact listed on the website or in the app. I ended up finding Feeld's head of trust and safety on Linkedin, paying for a month of Linkedin Pro, and messaging them that way. I was then directed towards a HackerOne program with a link to terms and conditions that 404ed, and it took a while to convince them I was uninterested in signing up to a program without explicit terms and conditions. Finally I was just asked to email security@, and successfully got in touch. I heard nothing back, but after prompting was told that the issues were fixed - I then looked some more, found another example of the same sort of issue, and eventually that was fixed as well. I've now been informed that work has been done to ensure that this entire class of issue has been dealt with, but I haven't done any significant amount of work to ensure that that's the case.
You can't trust clients. You can't give them information and assume they'll never show it to anyone. You can't put private data in a database with no additional acls and just rely on nobody ever asking for it. You also can't find a single instance of this sort of issue and fix it without verifying that there aren't other examples of the same class. I'm glad that Feeld engaged with me earnestly and fixed these issues, and I really do hope that this has altered their development model such that it's not something that comes up again in future.
(Edit to add: as far as I can tell, pictures tagged as "private" which are only supposed to be visible if there's a match were appropriately protected, and while there is a "location" field that contains latitude and longitude this appears to only return 0 rather than leaking precise location. I also saw no evidence that email addresses, real names, or any billing data was leaked in any way)
After many months, I finally found the time to finish the GNOME desktop/application settings migration in the Linux Desktop Migration Tool and made another release. It basically involves exporting the dconf keys on the source machine and importing writable keys on the destination machine. I’ve also added some extra code to handle the desktop background. If the dconf key points to a picture that is not present on the destination machine, the picture is copied as well. Be it a custom background, or a system provided one that is no longer shipped (in case you’re doing the migration between OSes of different versions).
The list of migrations the tool can do is already fairly long:
Migrate data in XDG directories (Documents, Pictures, Downloads…) and other arbitrary directories in home.
WordPress.com has recently allowed blogs to Enter the Fediverse, so you can now follow my writings on Mastodon and other places. Click the new ‘Follow’ button in the sidebar, or paste this succinct Fediverse address:
This blog is more serious writing about technology, you can also follow @[email protected] which is mostly music, art and needless complaints over things I can’t change.
Reflections on GUADEC 2024
I was lucky enough to attend GNOME’s 2024 conference in Denver. I had a great time, saw many people I haven’t seen this decade, and it was also my first trip into the USA beyond the easternmost parts of the east coast.
I have a more thoughts about this year’s event which are complex and contradictory and better discussed face to face. Sometimes you have to hold multiple conflicting thoughts in your head at once. I’ve written some of these thoughts down below.
The world is huge … like really big. Denver is a full EIGHT timezones away from Berlin, right? If you get up at 9AM in Denver then it’s already 5PM in Berlin, and it’ll be 6PM by the time you’ve brushed your teeth. How can you unite two groups of people across such a big time gap?
Having tried it, my feeling that a “federated” event split across different locations at the same time is not a replacement for a single, global in-person event. The community splits according to the geographical distribution of its members, roughly following Conway’s Law.
Travelling back from Denver to Santiago de Compostela took me about 50 hours in the end. It was supposed to be less but there was a 5 hour delay in Denver due to a shortage of air traffic controllers in Newark, which led to missing a connection to Madrid, the next day some bad weather added two more hours of delay, and then the trains from Madrid were largely full so I couldn’t get back home until early evening.
I kind of enjoy travel chaos (and my feeling is that as a society, we’ll only reduce our dependence on air travel if and when it becomes frustratingly inconvenient to use).
I feel lucky that I don’t have to do this kind of trip very frequently. I have more appreciation now for the significant effort people go through to get to events in Europe.
Some benefits to holding a GUADEC in the USA. Inspirational keynotes by local speakers, both Ryan Sipes’ story of Thunderbird, and Stephanie Taylor who is the force behind Google Summer of Code. Meeting contributors who don’t travel to Europe. Media coverage of the GNOME Foundation AGM, in a good way.
I think we missed an opportunity to make more of the event. Involving “the local community” in a summer event is always tricky, as during the summer holidays, “casual” attendees such as students and hobbyists are mostly on holiday. They aren’t usually looking for new software conferences they might attend. That said, GNOME would definitely would benefit from more hands focused on communication outside the project, what we often call “marketing” and “engagement”. It’s a difficult and often thankless task and we have to pay someone to do it. (With all the endless money we have, of course).
I did mention the thing about multiple conflicting ideas at once, right?
Let’s not pretend that a video conference or a hybrid BOF is the same as an in-person meetup. Once you’ve sung karaoke with someone, or explored Meow Wolf, or camped in the desert in Utah together, your relationship is richer than when you only interacted via Gitlab pull requests and BigBlueButton. You have more empathy and you can resolve conflicts better.
Evan Welsh doing a great job of herding gnomes along the river
Let’s keep exploring new ways to collaborate. Regional events and hybrid events. And accept that these will form bubbles. If you live near members of the GNOME design team and meet in-person with them, you’re going to be able to influence GNOME’s design, more easily than if you live on a continent such as Africa where (to my knowledge) you can’t meet any existing design team members without leaving your continent. If you have a friend who maintains Nautilus it’s going to be easier to get up to speed with Nautilus development yourself, compared to if you’re starting from scratch and you live in a timezone that’s 10 hours offset from Europe.
We want to rethink technical governance in GNOME, which currently somewhat resembles the 15th century Feudal system. (See also, Tobi’s less flippant explanation of how decisions are made). Let’s keep geography in mind when we discuss this. And let’s also think how we can balance out the implicit advantage you get for being based in a certain place, and how we can grow local communities in places that don’t currently have them. I suspect this effort will need to be larger than just the GNOME project, and we can’t be the only community thinking about this stuff.
The USA is just as crazy as you imagine from its TV output. I was ready for beautiful scenery, long car journeys, no pavements, icy air conditioning, unhealthy food and franchises inside of franchises inside of franchises. I was genuinely surprised how hot it gets everywhere — even during my unwanted stopover in Newark the weather was 35° humid heat. And I wasn’t ready for disposable plates, cups and cutlery at every hotel breakfast. I’ve stayed in very cheap and very expensive hotels in many places, and all of them manage to wash and reuse the plates.
Delicious snacks at Meow Wolf, Denver
I want to see the single location, in-person GUADEC continuing while it’s still possible to do it. Count how many plane tickets were bought this year to attend GNOME events, and compare it to the number of flights taken just by Elon Musk’s private jet. It’s great that we avoided a few dozen plane tickets compared to last year but I’m yet to see a noticeable impact on the airline industry; while the impact on the GNOME project of splitting the community into two physical locations was very noticeable indeed.
We should alternate in-person GUADEC with more radically decentralized events, under a different name. We need to continue developing those as well. Like it or not there are big changes coming in society as the world gets increasingly hot. Tobi outlined all this very well in 2022. Nobody knows exactly what will happen of course, but you can expect that building resilience to change will be worthwhile, to put it verymildly. The key is for this to be something positive rather than a negative. The creation of something new rather than the loss of something we fondly remember. I mean, you can’t claim “GUADEC” is a particularly great name
It’s easy to write about this stuff in a blog post of course, harder to put into practice, and actually it wasn’t even easy to write…. this has taken me three hours.
Fairphone 5
I was going to write more stuff here but it turns out I had a lot to say about GNOME this month. At FOSDEM 2024, which I could easily attend in-person because I’m European, I saw a great talk by Luca from Fairphone, and decided my next phone would be a Fairphone 5. And I just got one. More on that next month, I guess.
I attended GUADEC 2024 last month in Denver, Colorado. I thought I’d write about some of the highlights for me.
It was definitely the smallest GUADEC I’ve been to, and it was unusual in some other ways too, such as having several hybrid presentations, with remote and in-person presenters sharing the stage. That took some adjusting, but it worked well, even if I missed some of the energy of past events. (I shared some thoughts about hybrid GUADEC on a Discourse thread).
I felt this GUADEC was really defined by the keynotes. They were great!
First, we had Ryan Stipes from Thunderbird telling us all about Thunderbird’s journey from a somewhat neglected but well-loved side project and on to a thriving self-funded community project: Thunderbird, The Death and Rebirth of an OSS Project (YouTube). He had a lot to say about the value of metrics to measure the impact of certain features and target platforms, which really resonated with people. (It is interesting to note, for instance, there appear to be more Thunderbird users using Windows 8.1 than Linux). He also had a lot to say about the success Thunderbird had just being direct and asking users for money.
Much of this success comes from Thunderbird doing a good job telling its own story. People clearly understand what Thunderbird is doing for them. And there was plenty of talk for the next few days: what does it mean for GNOME to own its story?
I also really enjoyed Stephanie Taylor’s keynote, all about Google Summer of Code (which started 20 years ago now!): Google Summer of Code 20 years of OSS Mentorship (YouTube). It just made me super happy as a GSoC alumni (one of thousands!) to see that program continuing to do so much good, and how much mentorship in open source has grown over the years.
Scott Jenson’s presentation, How can GNOME explore bigger concepts? (YouTube), is another really important watch. Scott’s advice about breaking free from traps like constraint thinking really resonated with me, especially his suggestion to, at first, treat the software like it is magic and see where that leads.
That approach reminds me of how software improves in implementation, as well. It is natural for a codebase to start off with a whole bunch of “do magic” stub functions, then slowly morph into a chaotic mess until finally it turns into something that actually might just work. And getting to that last step usually involves deleting a lot of code, after it turns out you never needed all that much magic. But you have to be patient with the chaos to get there. You have to believe in it.
Speaking of magic, there is so much around GNOME that is exciting right now, so I spent some time just being excited about things.
Eitan Isaacson talked about Spiel, a modern speech synthesis system: The Whole Spiel – A New Speech Synthesis API (YouTube). I loved his examples showing how it is important to satisfy several very different use cases for speech synthesis. While one user may value the precision of eSpeak at chipmunk speed, another user would prefer their computer talks like a human. And if we can get speech synthesis working well for non-accessibility reasons, there’s a real curb cut effect that should benefit everyone, including people who are just starting to use accessibility tools.
I went to the newest edition of Jonathan Blandford and Federico Mena Quintero’s presentation about Crosswords, GNOME Crosswords, Year Three (YouTube). It was abridged due to the format, but I especially enjoyed learning about the MVC-like data model for the application. It would be neat to see more GNOME apps using the same pattern.
There was a lot to learn about GNOME OS and OpenQA testing. The process for a new developer to get into hacking on a GNOME system component tends to be really awkward – particularly if that developer doesn’t want to mess up their host system. So You’re always breaking GNOME (YouTube) got me pretty excited about what’s coming with GNOME OS and sysext, as well as for testing in general. The OpenQA workshop on Monday was also well attended. Some people were unclear what openqa.gnome.org was doing, or what it can do for them. Just stepping through some conveniently broken tests and fixing them together was an excellent way to demystify the thing.
Much of this work is being helped along with the Sovereign Tech Fund. This is the GUADEC where a lot of that is up for show, and I think it’s amazing to see so many quiet but high impact projects finally getting the attention (and funding) they deserve.
Outside of the event, it was great hanging out around Denver with all sorts of GNOME folks. I loved how many restaurants were perfectly happy to accommodate giant mobs of people. We saw huge mountains, the Colorado Rockies winning a baseball game, surprisingly good karaoke, and some very unique bars. On the last day, a large contingent of us headed to Meow Wolf, which was just a ridiculously fun way to spend a few hours. It reminded me of a point and click adventure game in the style of Myst and Riven, in all the best ways.
I was also suitably impressed by the 35 minute walk from where I was staying, around Empower Field, over the South Platte River, under some giant highway … which was actually entirely pleasant, for North America. This part of Denver has plenty of pedestrian bridges, which are both nice to walk along and really helpful to guide pedestrians through certain areas, so for me the obvious walking routes were completely different from (and as efficient as) the obvious driving routes.
The GUADEC dinner was, for me, the ideal GUADEC dinner. It was right there at the venue, at the same brewery people had been going to every day – but this time with free tacos! I truly appreciated the consistency there, for Denver has good beer and good tacos. I also appreciated that we were set up both inside and outside, at nice big tables with plenty of room for people to sit. It helped me to feel comfortable, and it was great for people who were there with families (which meant I got to meet said families!). It reminded me of the GUADEC 2022 taco party. An event like this really shines when people are moving around, and there was a lot of it here.
It turns out I didn’t take many pictures this year, but the official ones are better anyway. I did, however, take far too many pictures from the train ride home: I rode Amtrak, mostly for fun, on California Zephyr from Denver to Sacramento; then Coast Starlight from Sacramento to Seattle; and the smaller Cascades train from Seattle to Vancouver. It was beautiful, and seriously I think everyone should have the opportunity to try an overnight roomette on the Zephyr. My favourite part was sitting in the spacious observation car watching the world go by, getting only the tiniest amount of work done. I found tons of fun people to talk to, which I don’t usually do, but something about that space made it oddly comfortable. Everyone there was happy and sociable and relaxed. And I guess I was still in conference mode.
I returned home refreshed and excited for where GNOME is heading, especially with new progress around accessibility and developer tools. And with plenty of ideas for little projects I can work on this year.
Thanks to all the awesome people who make GUADEC happen, as well as my employer, Endless OS Foundation, for giving me the opportunity to spend several work days meeting people from around the GNOME community and wandering around Denver.
It's been a busy year, and our platform and developer community-building efforts are paying off. Let's take a look at what we've been up to over the last six months, and measure its effect.
We're back with some new milestones thanks to the continued growth of Flathub as an app store and the incredible work of both our largely volunteer team and our growing app developer community:
Over 1,000 apps have been verified by their developers on Flathub, including 70% of the top 30 most popular apps. Developers of verified apps are ultimately in charge of their own app listings, and their updates are delivered directly to Flathub users while passing our automated testing and human review of things like permission changes.
Over 100 apps are now passing our quality guidelines that include checks like icon contrast on both light and dark backgrounds, quality screenshots, and consistent app naming and descriptions so users get a better experience browsing Flathub. These guidelines are what enable us to curate and display visually appealing and consistent banners on the new home page, for example.
This means that between late February and July, the developers of over 100 apps went out of their way to improve—and sometimes make significant changes to—their apps' metadata to get ready for these new guidelines and features on Flathub. We're proud of these developers who have gone above and beyond, and we look forward to even more apps opting in over time.
Developers, if you'd like to see your app featured on the home page, please ensure you are following these guidelines! We've heard from app developers that getting your app featured not only gives a bump in downloads, but can also bring an increase in contributions to your project if it's open source.
Six months ago we passed one million active users based on a simple if conservative estimate of updates to a common runtime version we had served. Using that same methodology, we now estimate we have over 4 million active users!
As a reminder, this data is publicly available and anyone can check our work. In fact, I personally would love if we could work with a volunteer from the community to automate this statistic so we don't have to do manual collation each time. If you're interested, check out this GitHub issue.
Those users have been busy, too: to date we have served over two billion downloads of different apps to people using different Linux flavors all around the world. This is a huge community of people trusting Flathub as their source of apps for Linux.
Thank you to our download-happy community of users who have put their trust in Flathub as their source of apps on Linux. Thank you to all of the developers of those apps, and in particular those developers who have chosen to follow the quality guidelines to help make Flathub a more consistent and engaging space. And thank you to every contributor to Flathub itself whether you are someone who fixed a typo in the developer documentation, helped translate the store, contributed mockups and design work, or spent countless hours keeping everything running smoothly.
As a grassroots effort, we wouldn't have become the Linux app store without each and every one of you. ❤️
Everything is better in color. Even better if it is HDR.
Seven-color and twelve-color color circles from 1708, attributed to Claude Boutet
In this post, we’ll provide an overview of what is happening with color in GTK, without diving too deeply into the weeds of colorimetry and color science.
The high-level goals of this effort are to enable proper handling of HDR content and color-managed workflows.
In the beginning, sRGB
Up until now, colors in GTK were always assumed to be in the sRGB color space. The omnipresent GdkRGBA struct is defined as specifying an sRGB color.
sRGB was a great thing 20 years ago, but there world is moving on to other color spaces that include a wider range of hues (such as Display-P3) or a bigger dynamic range (such as BT.2100-PQ).
After having this on our agenda for quite a while (initial investigations into this topic happened in 2021), we’re finally moving ahead with landing the foundations for a more colorful future.
Coming soon: GdkColorState
Earlier this year, we’ve merged some great work by Alice to support modern color syntax and color spaces in our CSS engine. Having expressive colors in CSS is great, but it can’t really shine if all our rendering machinery still requires colors to be specified in sRGB.
So over the past month or two, we’ve added support for doing our rendering in well-defined color spaces, and introduced an object representing these. It is called GdkColorState (don’t ask me why the name changed from space to state).
As of now, GdkColorState can represent sRGB and BT.2100-PQ, as well as their linearized variants. You cannot yet do much with these objects, they are mainly used internally by our renderers.
One thing you can already do though, is trying out how rendering in a linear color space will look, by setting the
GDK_DEBUG=linear
environment variable.
This is a change that we need to do eventually, to produce correct and understandable results, in particular when working with HDR content.
Doing all our compositing in a linear color state does look subtly different though, so want to delay this change until all of the surrounding work is done, and do it at beginning of a development cycle to give everybody time to adjust.
New protocols
The Wayland color management protocol has been a long time in the making, but it is hopefully close to leaving the experimental phase — kwin already has support for it, and there is a mutter branch as well.
We have added support for the xx-color-management-v4 protocol, so we get the preferred color state from the compositor (if it is supports that protocol), and we can tell it about the color state of the frames that we produce.
It is unlikely that your compositor will prefer an HDR color state like BT.2100-PQ today (unless you find the hidden switch to turn on experimental HDR support), but you can try how things look when GTK is rendering in that color state by setting the
GDK_DEBUG=hdr
environment variable.
Note that this doesn’t make HDR content appear on your screen — we do our rendering in HDR and translate the final frame back to sRGB as the last step. Making HDR content appear on your screen requires a compositor that accepts such content.
In the future: More color states and linear compositing
We still have a long todo list to fully develop color support in GTK.
The highlights include
More color states (including OKLCH for better gradients and YUV for video content)
Color state aware rendering api (GdkColor, and new GtkSnapshot APIs)
Passing CSS color state information down to the renderer
Propagating color state information from gstreamer (for HDR, among other things)
Switching to linear compositing
A few of these will hopefully make it in time for the GTK 4.16 release.
Last I mentioned I was doing an ABI cleanup of libspelling as it was really just a couple hour hack that got used by people.
Part of that was to make way for performing spellchecking off the GTK thread. That just landed in today’s libspelling 0.3.0 release. In one contrived benchmark, spellchecking a 10,000 line document was 8x faster. YMMV.
One of the reasons it’s faster is we don’t need to use the GtkTextIter API. Pango provides all the things we need to do that without the PangoLayout overhead. So we just skip right past that and implement iterators off-thread.
I also extracted the GtkTextBuffer adapter so that we may add a GtkEditable adapter in the future. Internally, the adapters provide a series of callbacks to the SpellingEngine.
You might wonder what happens if you make an edit that collides with a region being spellchecked off thread? The answer is quite simple, it checks for collisions and either adapts by adjusting offsets or discards irreconcilable collisions.
Both Text Editor and Builder have been migrated to using libspelling instead of its ancestor code. If you’re running nightly Flatpak of those, take a crack at it and report bugs.
We all think we’re smart enough to not be tricked by a phishing attempt, right? Unfortunately, I know for certain that I’m not, because I entered my GitHub password into a lookalike phishing website a year or two ago. Oops! Fortunately, I noticed right away, so I simply changed my unique, never-reused password and moved on. But if the attacker were smarter, I might have never noticed. (This particular attack website was relatively unsophisticated and proxied only an unauthenticated view of GitHub, a big clue that something was wrong. Update: I want to be clear that it would have been very easy for the attacker to simply redirect me to the real github.com after stealing my credentials, in which case I would not have noticed the attack and would not have known to change my password.)
You might think multifactor authentication is the best defense against phishing. Nope. Although multifactor authentication is a major security improvement over passwords alone, and the particular attack that tricked me did not attempt to subvert multifactor authentication, it’s actually unfortunately pretty easy for phishers to defeat most multifactor authentication if they wish to do so:
Multifactor authentication based on phone calls is also insecure (because SIM swapping isn’t going away; determined attackers will steal your phone number if it’s an obstacle to them)
Multifactor authentication based on authenticator apps (using TOTP or HOTP) is much better in general, but still fails against phishing. When you paste your one-time access code into a phishing website, the phishing website can simply “proxy” the access code you kindly provided to them by submitting it to the real website. This only allows authenticating once, but once is usually enough.
Fortunately, there is a solution: passkeys. Based on FIDO2 and WebAuthn, passkeys resist phishing because the authentication process depends on the domain of the service that you’re actually connecting to. If you think you’re visiting https://example.com, but you’re actually visiting a copycat website with a Cyrillic а instead of Latin a, then no worries: the authentication will fail, and the frustrated attacker will have achieved nothing.
The most popular form of passkey is local biometric authentication running on your phone, but any hardware security key (e.g. YubiKey) is also a good bet.
target.com Is More Secure than Your Bank!
I am not joking when I say that target.com is more secure than your bank (which is probably still relying on SMS or phone calls, and maybe even allows you to authenticate using easily-guessable security questions):
target.com is introducing passkeys!
Good job for supporting passkeys, Target.
It’s probably perfectly fine for Target to support passkeys alongside passwords indefinitely. Higher-security websites that want to resist phishing (e.g. your employer’s SSO service) should consider eventually allowing only passkeys.
No Passkeys in WebKitGTK
Unfortunately for GNOME users, WebKitGTK does not yet support WebAuthn, so passkeys will not work in GNOME Web (Epiphany). That’s my browser of choice, so I’ve never touched a passkey before and don’t actually know how well they work in practice. Maybe do as I say and not as I do? If you require high security, you will unfortunately need to use Firefox or Chrome instead, at least for the time being.
Why Was Michael Visiting a Fake github.com?
The fake github.com appeared higher than the real github.com in the DuckDuckGo search results for whatever I was looking for at the time. :(
As part of my effort to reduce Mutter dependencies, I finally found some time to focus on removing Cairo now that we can have a Wayland only build. Since the majority of the remaining usages are related to fonts, we would need to move CoglPango to be part of GNOME Shell's libst.
Merging Cally
Moving CoglPango also necessitates moving ClutterText and its corresponding accessibility implementation object, CallyText. The accessibility implementation is an object that inherits from AtkObject and can implement various interfaces to describe the type it corresponds to.
Once you initialize accessibility inside Mutter, the first step is to set up the AtkUtil implementation, which overrides the get_root and returns a CallyRoot instance. The remaining types register an AtkObjectFactory using the provided macros.
Allowing Atk to know which type to instantiate in case it encounters a CLUTTER_TYPE_CLONE, for example. That usually happens when you call atk_gobject_accessible_for_object(actor), which creates an instance of CallyActor using cally_actor_new. Although, the factories are nice, they don't allow out-of-tree AtkObject implementations. But wait, how is GNOME Shell accessible then?
Inside GNOME Shell StWidget, the widget abstraction, overrides the ClutterActorClass.get_accessible virtual function and replaces the default behavior that would call atk_gobject_accessible_for_object to:
Getting the corresponding accessibility type GType from another StWidgetClass.get_accessible_type virtual function
Create an instance of that type using g_object_new (T->get_accessible_type())
Call atk_object_initialize on it
Keep a weak reference to it
After "upstreaming" both StWidgetClass.get_accessible_type and their override of ClutterActorClass.get_accessible to become the default behavior, I managed to completely get rid of the factories. The remainder of the migration was mostly renaming things and trying to emit accessibility state changes when the Clutter type updated its state where possible.
Now that my branches of Mutter and GNOME Shell are working, I decided to test whether the reshuffling I did has caused any regressions. Unfortunately, Accerciser from the Fedora Rawhide repositories doesn't start due to a Python forward compatibility issue.
I remembered that Georges Basile Stavracas Neto started a re-implementation in C, called Elevado, so between fixing Accerciser or adding some missing features I wanted in Elevado, the choice was easy.
Current accessibility tree
And few hours later, I had managed to add some meaningful accessible names to various objects.
Accessibility tree from local development
Now that I have confirmed that my changes didn't break any obvious thing, my weekend fun is over.


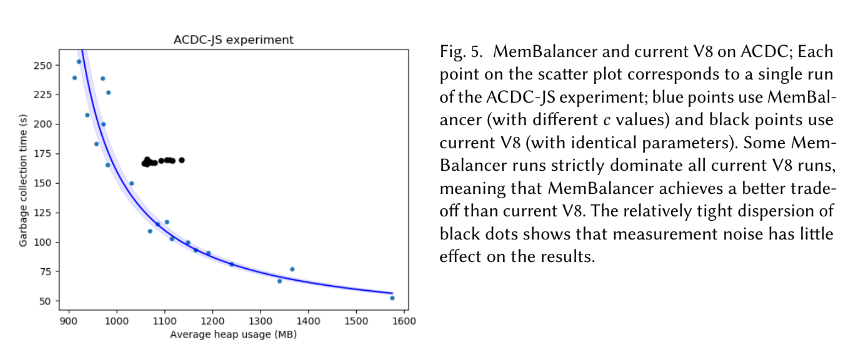














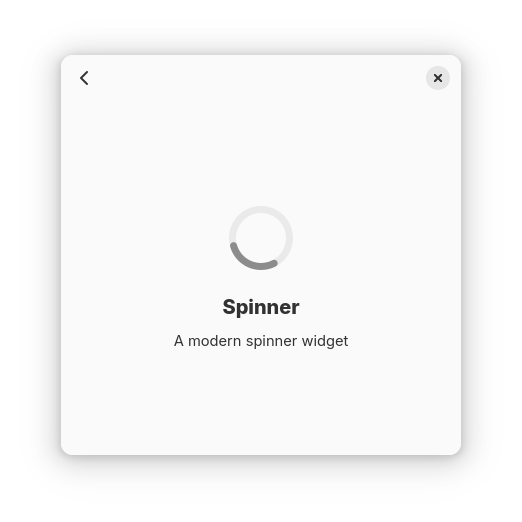



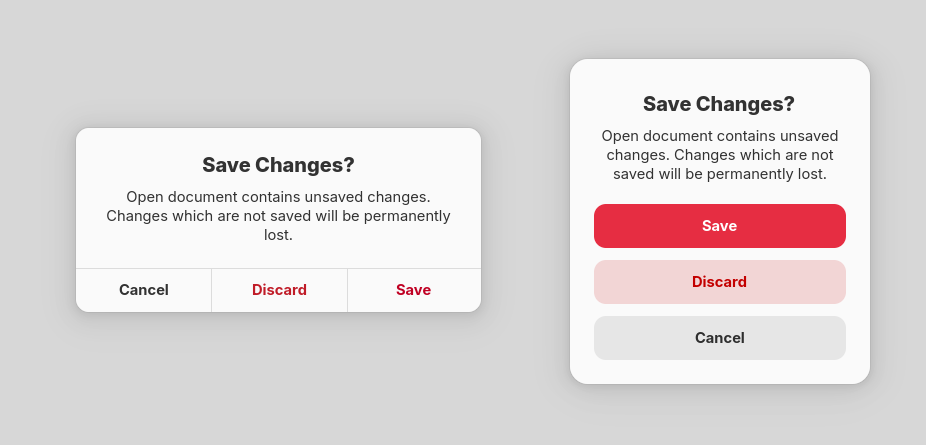
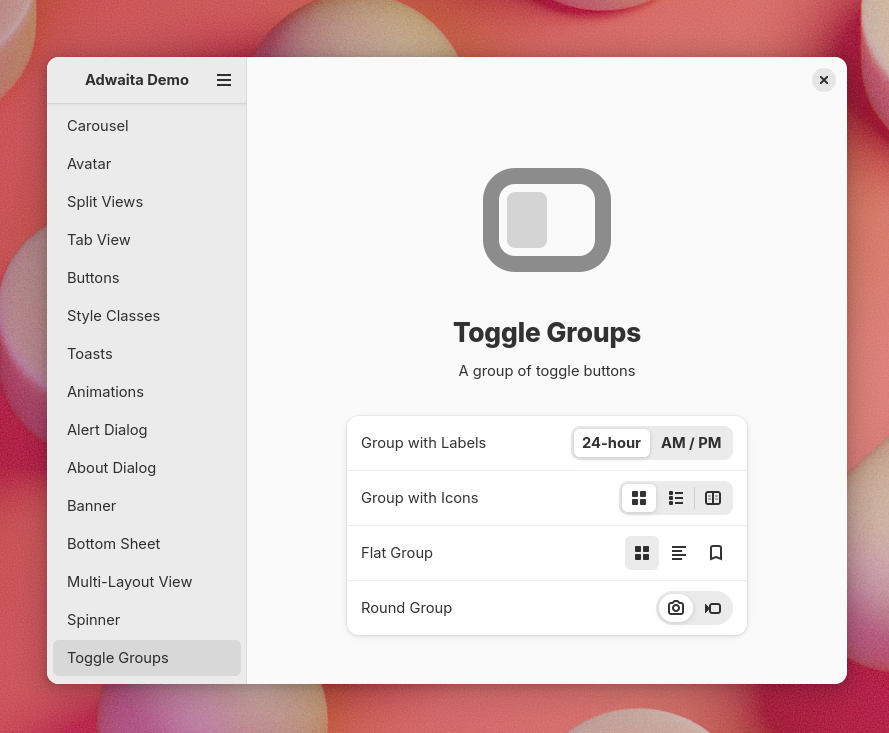



























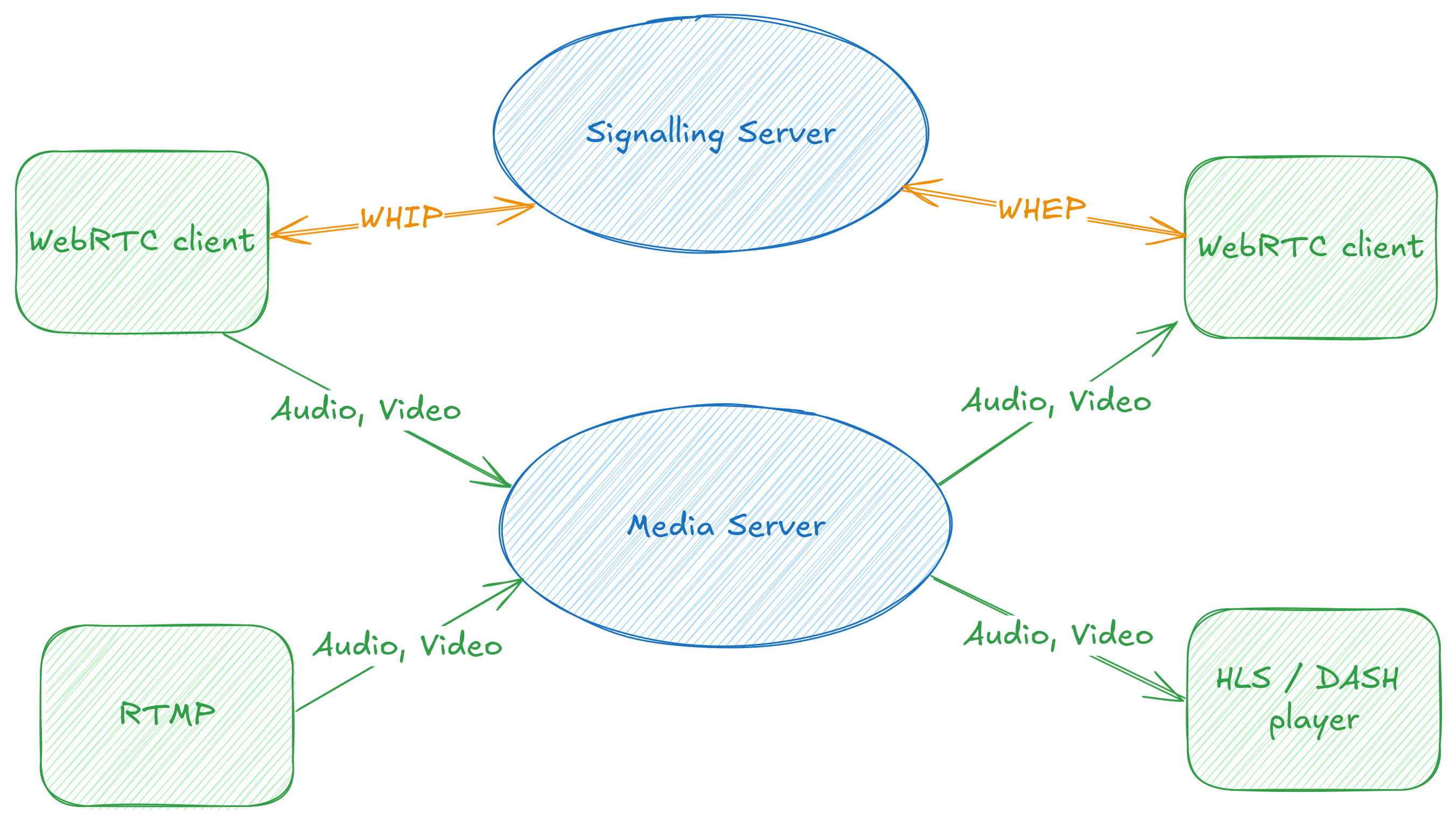





































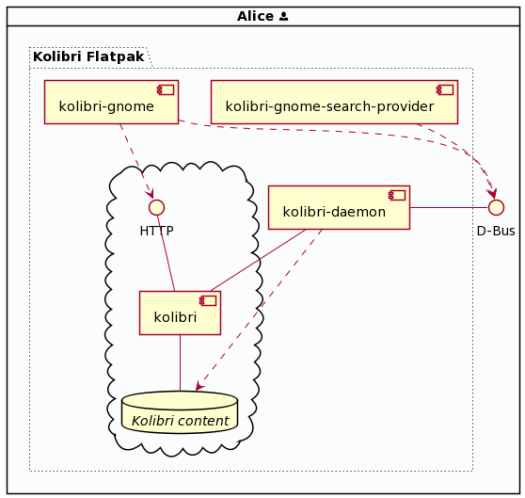
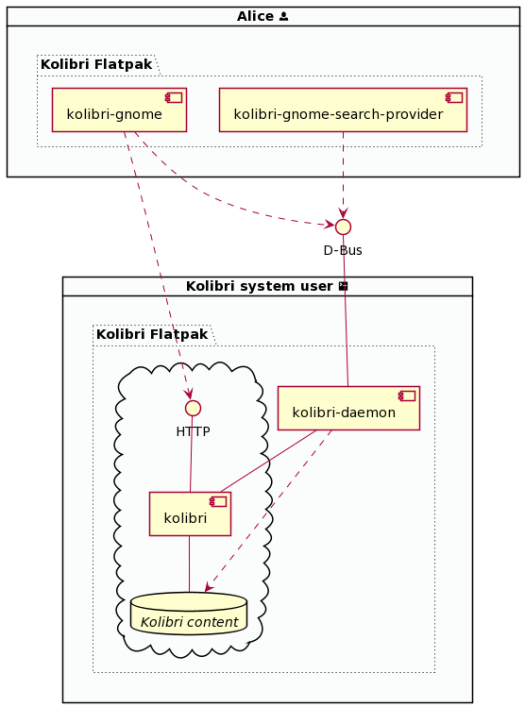

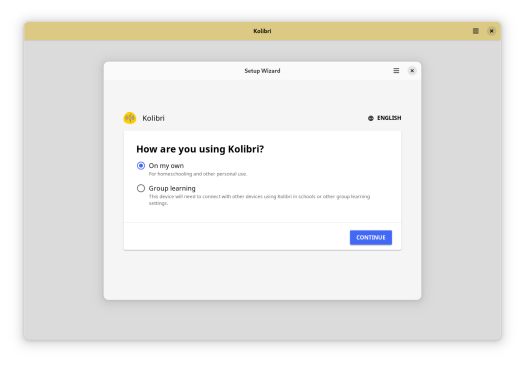


























{kind=link}