In November, we added the first new location for the Realtime Database outside the United States, in Belgium. Today, we are adding Singapore as well. We encourage any Firebase developer with a large userbase in Asia to consider using this new location to reduce latency.
All new and existing Firebase developers can create databases in Singapore. Developers on our paid plan can create multiple databases, even mixing databases in multiple locations within a single project.
We’re also announcing that all three locations — the United States, Belgium, and Singapore — are Generally Available. They are ready for your production data today.
Log into the Firebase console to create a database in Singapore, or check out our documentation to learn how to use our APIs to provision databases programmatically.
We’re delighted that the Realtime Database now has locations around the world, and we can’t wait to see what you build.
If you've ever built an app with Realtime Database you know that it's fast. When you combine the low-latency websocket connection with the local caching capabilities of the SDK, changes can feel pretty much instantaneous.
But have you ever wondered how fast your database operations are for your users in the real world? As a good app developer you need to collect real-world performance data to make sure that the experience of using your app in the real world matches your expectations! Many people in the tech industry call these field measurements Real User Monitoring (RUM) and they're considered the gold standard for measuring app performance and user experience. Firebase Performance Monitoring is a free and cross-platform service to help you collect and analyze RUM data for your app or website.
Firebase Performance Monitoring automatically measures common metrics like time to first paint and HTTP request performance. Because Realtime Database uses a long-running WebSocket connection rather than separate HTTP requests we'll need to use Custom Traces to monitor the performance of our database operations.
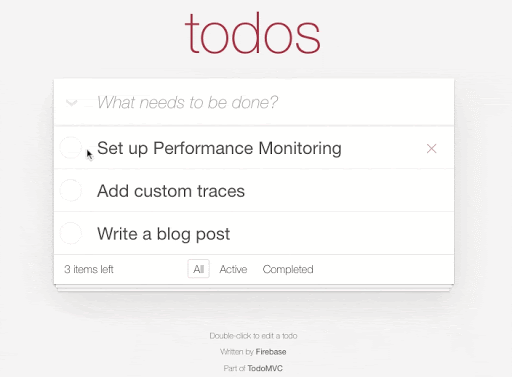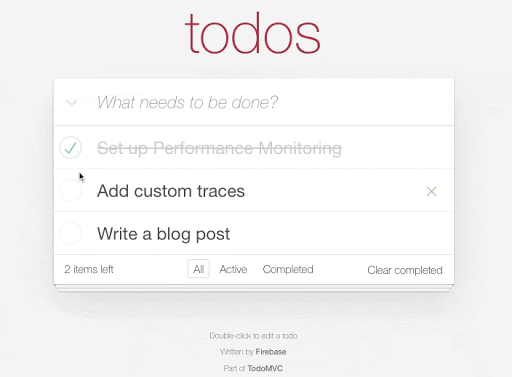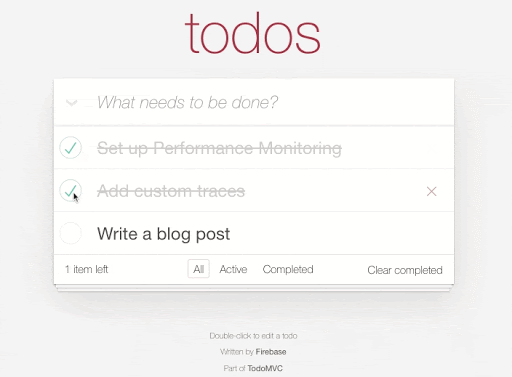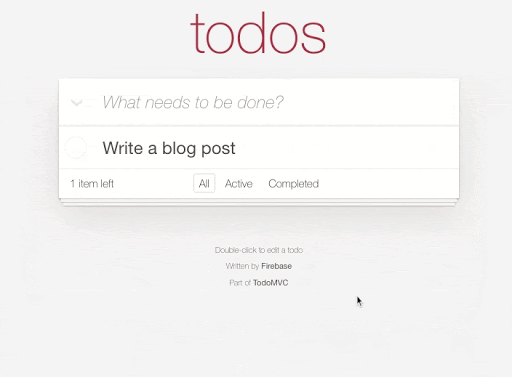
For this post we built a Firebase-powered implementation of the standard TodoMVC app in React using the ReactFire library:
Each time we add, update, or remove an item in our to-do list we're making a change in Realtime Database directly. For example here's the code to add a new todo item:
function App() { // Get an instance of Firebase Realtime Database using the 'reactfire' library const db = useDatabase(); // Load all the 'todos' from the database const todosRef = db.ref("todos"); const list = useDatabaseList(todosRef); // ... // Add a new todo to the database const handleAddTodo = (text) => { todosRef.push({ text, completed: false, }); }; // ... }
This operation appears to be instantaneous because the Realtime Database SDK immediately adds the new todo to the local listener while it waits for the backend to acknowledge, or reject, the write. But what if we want to find out how long it actually takes to commit the write on the server?
Let's add some code to measure how long this really takes. We'll create a new function called tracePromise to help us log a custom trace for any action which returns a Promise and then we'll add a simple custom trace called add-todo.
tracePromise
Promise
add-todo
function tracePromise(trace, promise) { trace.start(); promise.then(() => trace.stop()).catch(() => trace.stop()); } function App() { // Get and instance of Performance Monitoring using the 'reactfire' library const perf = usePerformance(); // ... const handleAddTodo = (text) => { const p = todosRef.push({ text, completed: false, }); // Use the 'tracePromise' helper to see how long this takes const trace = perf.trace("add-todo"); tracePromise(trace, p); }; // ... }
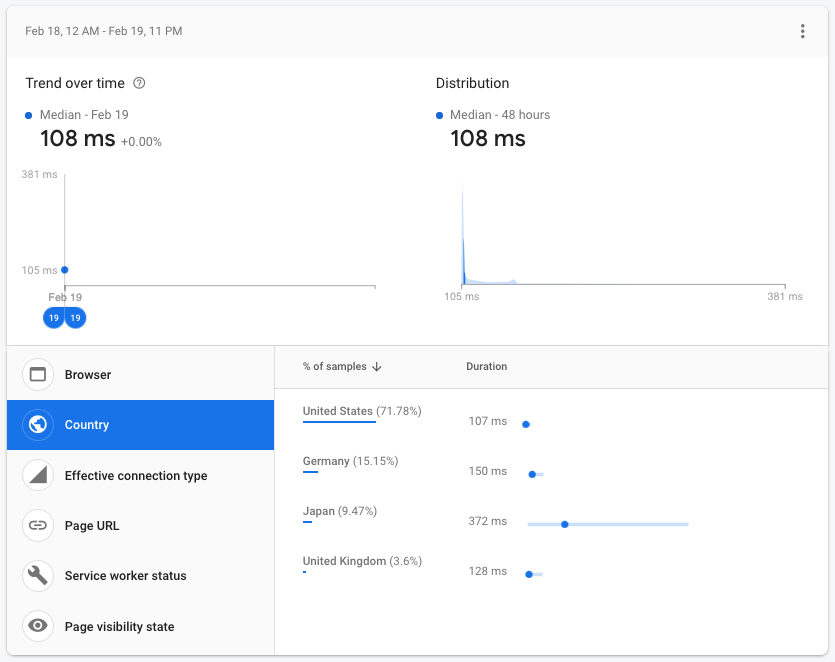
If we deploy this code and head to the Firebase console we can see that the "add-todo" operation takes about 100ms in most cases, with 160ms being the worst case.
If we break this down by country we can see that the operation is much faster for users in the US than in other countries:
This makes sense! Most Realtime Database instances are located in the United States, which can have an impact on latency for users around the world. Geographic latency increases can depend on physical distances as well as the network topology between two points.
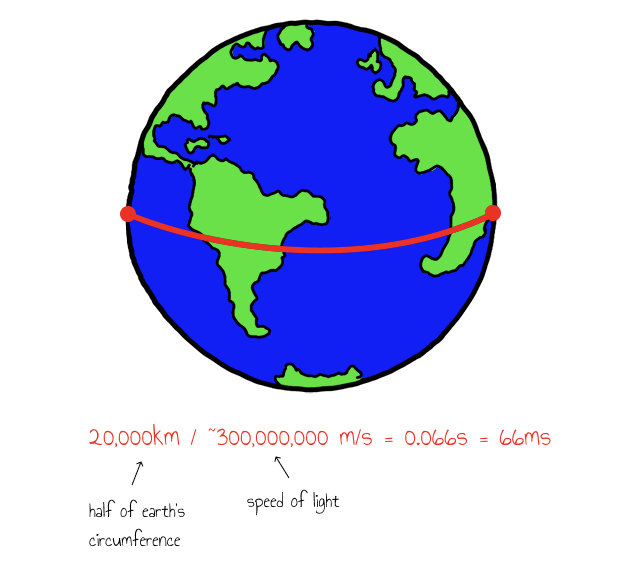
We don't often think about it when coding but data can only travel at the speed of light! For two points on opposite sides of the earth the speed of light alone adds 66ms of latency, and that's not including any of the actual network or processing latency along the way. This is why adding RUM to your app is so critical.
Well, the good news is that Realtime Database is now expanding to more regions around the world, beginning with the launch of our Belgium region in late 2020. A todo list app lends itself really well to sharding because each user's data is exclusively their own. So let's add a second Realtime Database instance to our app in the Belgium region, and assign each user to a random database instance to see what effect that has on our latency:
First we'll add a custom attribute to our Performance Monitoring traces so that we can filter the data by location later:
function getMyLocationCode() { // User's location could be stored in a URL param, cookie, localStorage, etc. // ... } function tracePromise(trace, promise) { // Add a custom attribute to the trace before starting it const location = getMyLocationCode(); trace.putAttribute("location", location); trace.start(); promise.then(() => trace.stop()).catch(() => trace.stop()); }
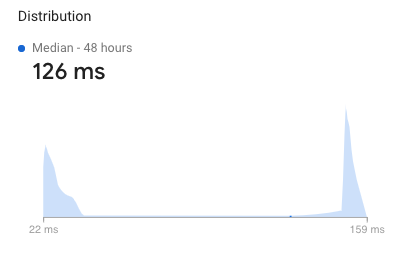
Now let's deploy these changes and wait for new user data to come in. After a few days we can see that our experiment worked! First we can see that our distribution now has two obvious peaks:
This is what we expected, because we're now randomly assigning users to one of two database instances. Depending on the one they get, it will either be close to them or far away.
If we look into the data more, we can see that our German users have a really fast connection to the Belgium instance! They're getting updates in as little as 22ms. That's a huge improvement over the 150ms+ they were getting when communicating with an instance in the US. While the local caching in the Firebase SDK will make the UI feel snappy either way, this will make a huge difference in the speed of collaborative or multi-device scenarios.
With this RUM data in hand we can be confident that adding a new database region can make our app faster. Next we'll need to find a way to detect the user location when they sign up and assign each account to the best region for them. For now we'll leave that as an exercise for the reader!
If you're ready to get started measuring performance in your own app, check out these links:
Today we launched TWO new features for the Firebase Realtime Database in beta.
First, we launched a new region for the Realtime Database, in Belgium, in addition to our existing region in the United States. If you would like to store your customer data in Europe, or if you’d like to reduce latency for customers in this part of the world, you can do so today.
Second, we launched a management API for the Realtime Database. With just a REST request you can list, create, update, delete, disable, and re-enable Realtime Database instances.
Once you upgrade your Firebase project to our pay as you go plan, it can contain many Realtime Database instances. You can use multiple database instances to scale beyond the limits of a single database instance, balance load, optimize performance, and more. You can even have a mix of database instances in the United States and Belgium in a single project.
Using the new API, adding another Realtime Database instance to a project is as simple as running curl. You can specify either us-central1 (United States) or europe-west1 (Belgium) for location-id.
curl
us-central1
europe-west1
location-id
curl -H "Content-Type: application/json" \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -X POST \ https://firebasedatabase.googleapis.com/v1beta/projects/{project-number}/locations/{location-id}/instances\?database_id\={my-new-database-id}
Let’s list the instances in our project to see if the new database shows up:
curl -H "Content-Type: application/json" \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ https://firebasedatabase.googleapis.com/v1beta/projects/{project-number}/locations/{location-id}/instances
We get this response, showing both our default Realtime Database instance (with type DEFAULT_DATABASE) and the new one we just created (type USER_DATABASE)
DEFAULT_DATABASE
USER_DATABASE
{ "instances": [ { "name": "projects/{project-number}/locations/{location-id}/instances/{default-database-id}", "project": "projects/{project-number}", "databaseUrl": "https://{default-database-id}.firebaseio.com", "type": "DEFAULT_DATABASE", "state": "ACTIVE" }, { "name": "projects/{project-number}/locations/{location-id}/instances/{my-new-database-id}", "project": "projects/{project-number}", "databaseUrl": "https://{my-new-database-id}.firebaseio.com", "type": "USER_DATABASE", "state": "ACTIVE" } ] }
You can use similar calls to disable, re-enable, and delete instances. Have a look at the documentation to learn more about the commands.
This API is available now, and we have enabled it on existing Firebase projects that have used the Realtime Database in the past month. If you ever use the Google Cloud console, you’ll see the API listed there as well. The Firebase console will soon let you create databases in Belgium as well.
We’re excited about these big advances for the Realtime Database, and we hope you are too!
Did you play the interactive Google Doodle for the Mexican card game “Lotería” last December? If not, you can still check it out here. Lotería is a multiplayer bingo-style game that supports up to five players per room. In the digitized Doodle version, you can play with random people around the world or create a private game with your friends.
The Lotería game was developed in JavaScript primarily by one engineer over a few months, and the game's usage jumped from no players to millions literally overnight. The multiplayer component that supported it all was built entirely with the Firebase Realtime Database, which meant we could spend more time developing a great user experience, and less time worrying about infrastructure. Let's look into how we did it!
/games/{gameId}/deal = {card, time, countDown}
To detect the winner, all players listen to another database location at /games/{gameId}/winner. When a player clicks “Lotería!” and has a valid winning pattern on their board, we write their ID to that location.
/games/{gameId}/winner.
Often, there’s a close tie, so we use Reference.transaction to ensure that only the first player to call, “Lotería!” is declared the winner. We do this by making sure that /games/{gameId}/winner doesn’t already have an existing value before we write anything to that location.
Reference.transaction
/games/{gameId}/winner
To create random public games, we utilized Cloud Functions for Firebase in conjunction with the Realtime Database.
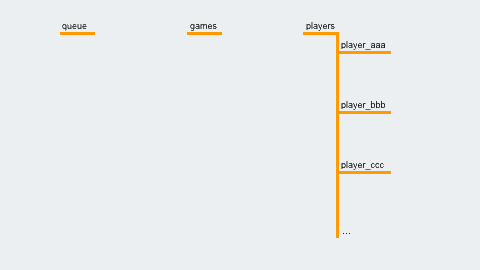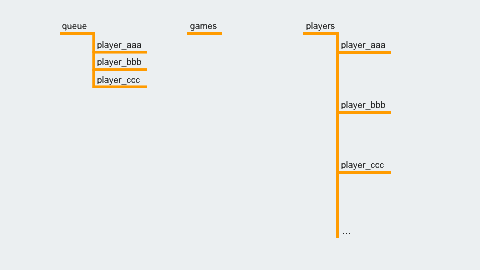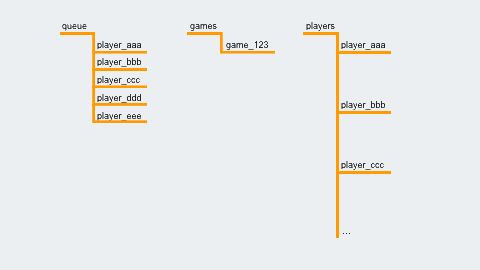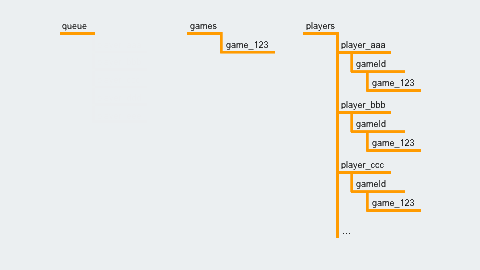
When a player selects “Random Match,” their player ID is written to the location /queue/. A Cloud Function is set up to trigger when a new entry is created, and it checks whether we have enough players to start a game. If so, it creates the game at /games/{gameId}, and writes the gameId to each player's entry, like so: /players/{playerId}/gameId = {gameId}
/queue/
/games/{gameId}
/players/{playerId}/gameId = {gameId}
Players listen to gameId on their own database entries, so they know when to transition to the gameplay screen.
gameId
Since there are a lot of players connecting simultaneously, and the Cloud Function is asynchronous, we once again used a transaction to ensure that players are removed from the queue and placed into games atomically. Making one game at a time atomically could create a bottleneck, so instead we create as many games as possible in one transaction.
Interactive Google Doodles get millions of players, so we needed to make sure that the database could handle the load. To do this, we sharded the database into multiple instances. Each instance can handle a limited amount of traffic, so we estimated how much traffic we expected to have. To do this, we wrote a load testing bot that could be run repeatedly and measured how much load this generated on a single instance. Then, we extrapolated that number to how many players we expected, which then gave us the number of instances we might need.
However, there is a downside to having too many instances: if players are spread too thinly, it might take longer for enough to connect to one instance to start a game. To solve this problem, we created an entry in the default database instance called “shards.” This was a number that could be adjusted from 1 to the maximum number of shards we created. Clients read this value and only used shards in that range. Since the Doodle was only live on the Google homepage for a short time, we updated the shards value manually through the Firebase Console, setting it lower when there was less traffic, and higher when there were spikes. Naturally, this process could be automated for a longer-running application.
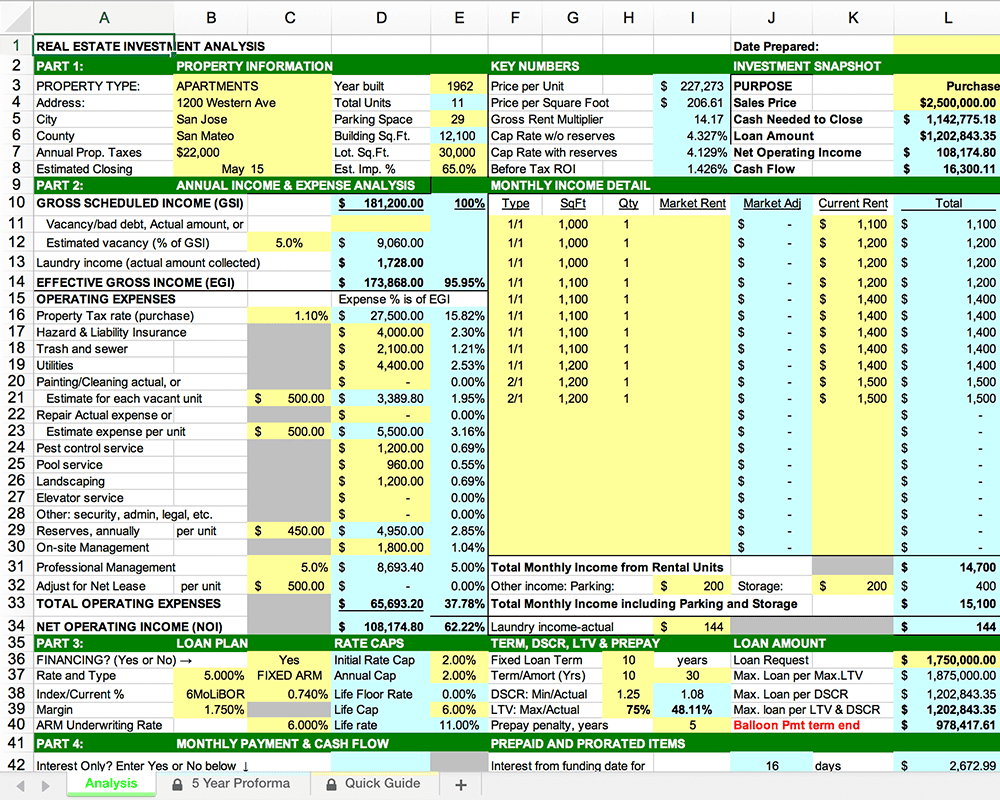
Real estate investing is a fantastic way to build a stream of passive income and grow your wealth. Numerous studies have pointed out that real estate investing has created more millionaires throughout history than any other form of investing (like this one and this one). So why don’t more people do it?
I asked myself this very question a few years ago after talking to a group of friends about the success I’ve had with real estate, and listening to their reasons why they think it’s out of their reach.
A common theme among them was that they viewed it as something too difficult to learn and master. There were too many steps, the learning curve was steep and there was a lot of room for mistakes for somebody just starting out, especially when analyzing the financial performance of potential investment properties.
Traditionally, most investors used spreadsheets to do the math - which works only if you know what and how you’re calculating something. But if you don’t know that, it’s very easy to make mistakes and overlook things. And no one wants to make mathematical errors before a huge purchase like an investment property.
Where do I even begin?!
And that’s when I had the idea to build DealCheck – a cloud-based, easy-to-use property analysis tool for real estate investors and agents. I wanted to create a platform that would help new investors learn the ropes and avoid costly mistakes, but at the same time provide the flexibility to perform more advanced analysis with a click of a button.
Making real estate investing easier and more accessible.
I was working as a front-end engineer at the time, so I knew I could build the UI myself, but what about the back-end, data storage, authentication, and a bunch of other things you need for a full-functioning cloud app?
I didn’t know anybody I could bring on as a co-founder, so I set out to research what technologies and platforms I could leverage to help me with the back-end and server infrastructure.
Firebase kept popping up again and again and I began to look at it in more detail. It was then recently acquired by Google and its collection of BaaS (backend-as-a-service) modules seemed to offer the exact solution I needed to build DealCheck.
I was especially impressed with the documentation for each feature and how well all of the different technologies could be tied together to create one unified platform.
It wasn’t long before I signed up and started building the first MVP of the app.
As the only developer on the project, I had limited time and resources to spend on building the back-end, so I set out to use every Firebase feature that was available at the time to my advantage.
My goal was actually to write as little server-side code as possible and instead focus on leveraging the different Firebase modules to solve three specific challenges:
The first one was authentication and user management. DealCheck’s users needed the ability to create their accounts so they can view and analyze properties on any device (more on that later). I wanted to have the ability to sign in with email, Facebook or a Google account.
Firebase Authentication was designed specifically for this purpose and I used it to handle pretty much the entire authentication flow. Out-of-the-box, it has support for all the major social networks, cross-network credential linking and the basic account management operations like email changes, password resets and account deletions.
There was no server-side code required at all – I just needed to build the UI on the front-end.
Email, Facebook and Google sign in powered by Firebase.
And as an added benefit, Firebase Authentication ties directly into the Realtime Database product to create a declarative permissions and access control framework that’s easy to implement and maintain. This helped me make sure user data was protected from unauthorized access, but also facilitate data sharing among users.
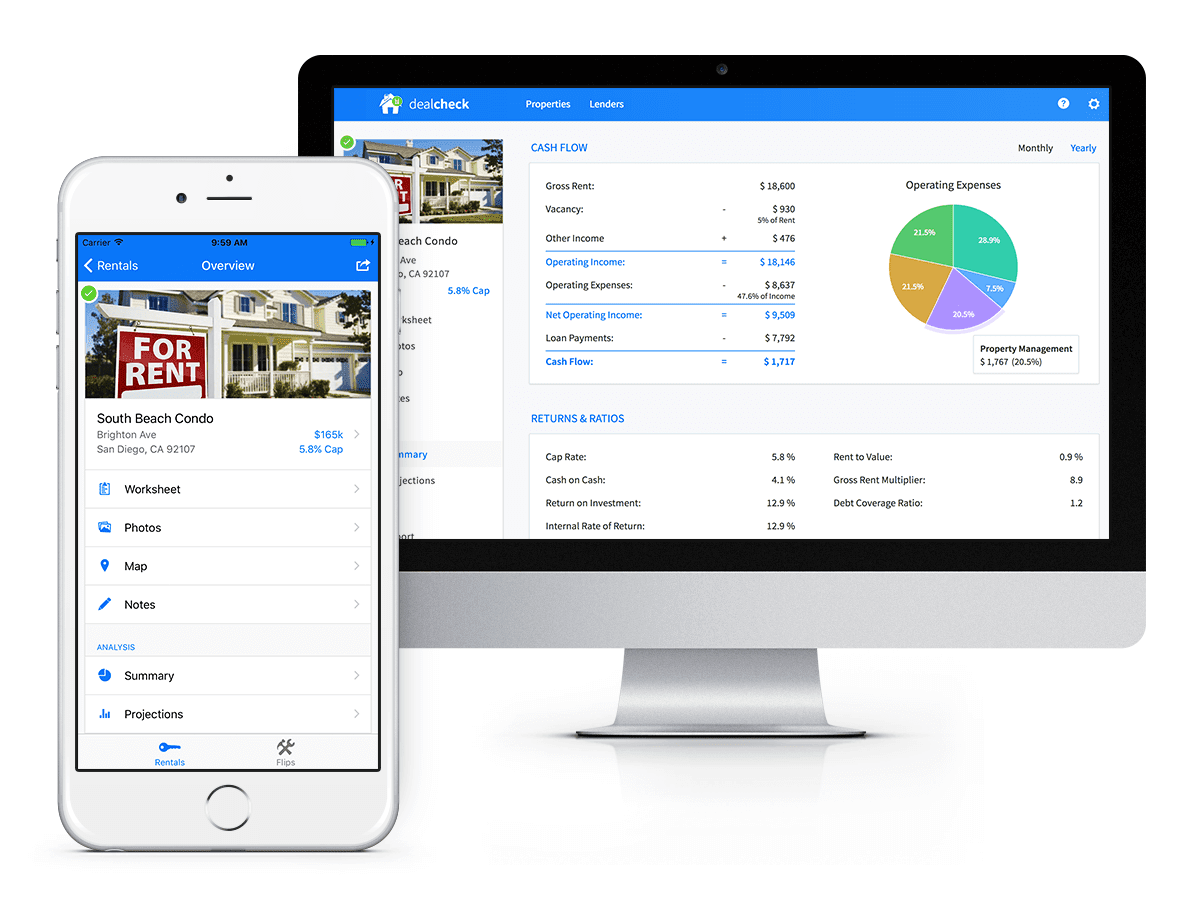
Next up was data storage. I knew that I wanted DealCheck’s users to be able to use the app and analyze properties online, on iOS and Android. So I needed a real-time, cloud-based database solution that could sync data across any device.
Syncing data across web and mobile is not easy!
Firebase Realtime Database is a NoSQL, JSON-based database solution that was designed exactly for this purpose, and I was actually surprised how great it worked. I used the official AngularJS bindings for Firebase on the front-end to read and write to it directly from the client.
I had to do some extra work on mobile to implement an offline mode with syncing after reconnections, but all-together the code required to make everything work was minimal.
As I mentioned, Firebase Authentication tied directly to the database to facilitate access control, so I really didn’t need to do anything extra there. And I was able to set up automatic daily backups of all the data with a click of a button.
Up to now, I had written exactly 0 lines of server-side code and everything was handled by the client directly. As DealCheck’s development progressed, however, I knew that I would need a server to handle some operations that could not be done in the client.
I wasn’t very experienced with server maintenance and DevOps, but fortunately the Firebase Cloud Functions product was able to solve all of my needs. Cloud Functions are essentially single-purpose functions that can be triggered (or executed) based on a specific HTTP request or events coming from the Authentication, Realtime Database or other Firebase products.
Each function can be run once based on a specific event trigger to perform its prescribed task. You don’t have to worry about provisioning a server instance or managing load – everything is done automatically for you by Firebase.
What’s even cooler, is that Cloud Functions can access the Realtime Database and Cloud Storage buckets of the same project, performing operations on them server-side, as needed.
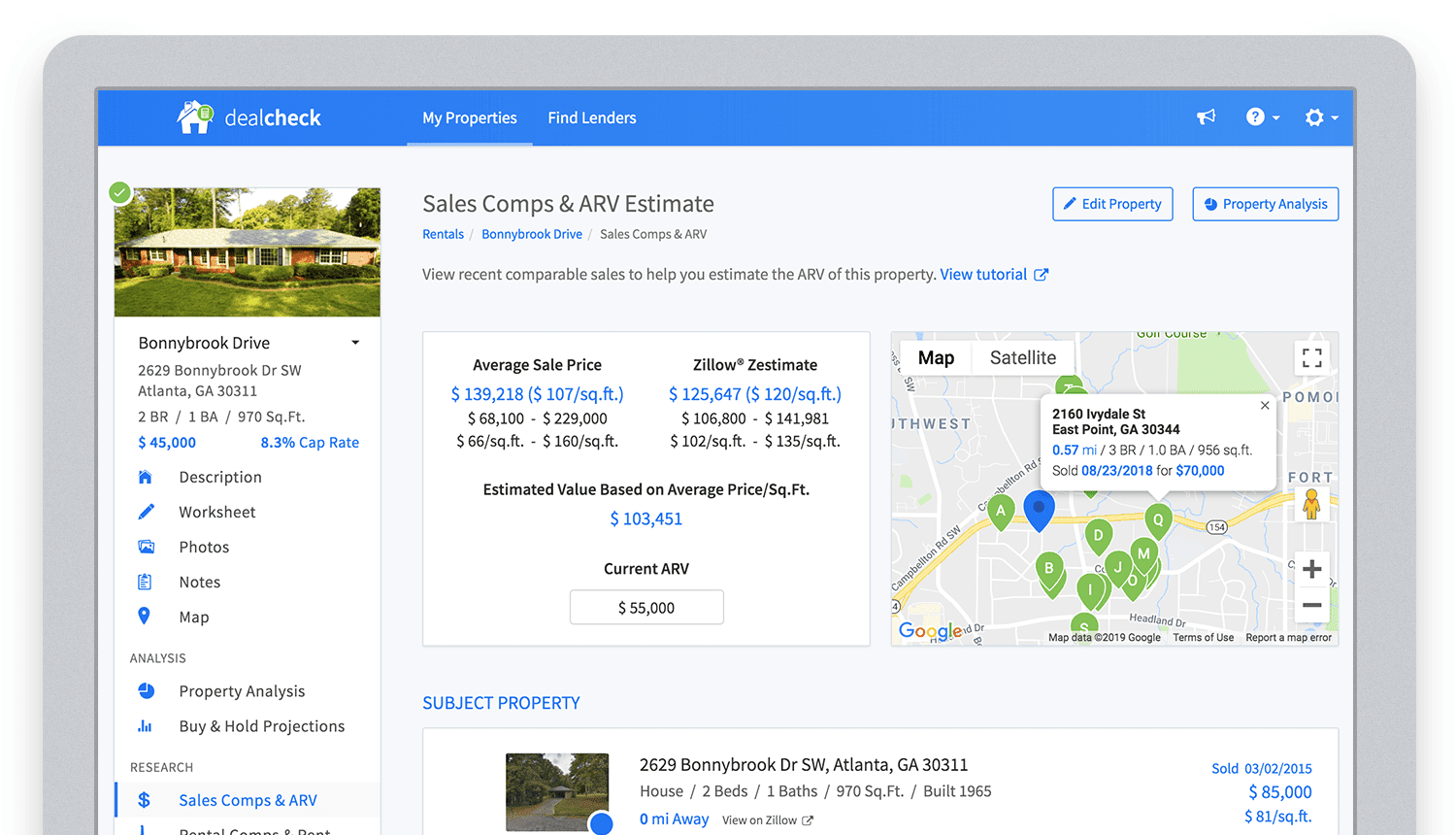
This is how DealCheck processes subscription payments through Stripe, validates Apple and Google Play mobile subscription receipts, integrates with third-party APIs and updates database records without user interaction.
Bringing in sales comparable data from third-party providers into DealCheck.
Cloud Functions became the “glue” that tied the entire back-end infrastructure together.
The first version of the DealCheck app was built and launched in less than 5 months with just me on the development team. I definitely don’t think that would have been possible without Firebase powering the back-end infrastructure. Maybe the project wouldn’t have ever launched at all.
While Firebase is awesome for quick MVP development, it’s definitely designed to power production applications at scale as well. As DealCheck grew from a small side-project to one of the most popular real estate apps with over 100k users, all of the Firebase products that we use scaled to support the increasing load.
Moreover, the fantastic interoperability of all Firebase modules allows us to develop and release new features much faster because of the reduced coding requirements and ease of configuration.
So next time you’re looking to build an ambitious project with a small team – take a look at how Firebase can help you reduce development time and provide a suite of powerful tools that scale as your business grows.
This is exactly how DealCheck grew from a simple idea to make property analysis easier and faster, to an app that is helping tens of thousands of people grow their wealth and passive income through real estate investing. It’s a truly awesome and fulfilling experience to see your work positively impact so many people and it wouldn’t have been possible without Firebase.
Today, we’re delighted to announce that we’ve doubled the concurrent connections limit for the Firebase Realtime Database from 100k to 200k. This takes effect today, for all existing databases and new projects. And while this level of scalability will be enough for the majority of projects out there, some of you might want to support even more concurrent users. For that, you might want to consider sharding your database.
Many kinds of apps can scale much higher by sharding their data across multiple Realtime Database instances in a single project. The 200k concurrent user limit applies to each individual database, so the total number of concurrent connections increases linearly as you add more instances.
Sharding is a good strategy to employ when each client interacts with isolated parts of the database. Imagine a virtual whiteboard app, which is the sort of high-frequency, low-latency collaboration app for which the Realtime Database really excels. Whiteboard sessions don’t interact with each other -- just with the handful of users that are drawing together. So they can be sharded across an unlimited number of instances. When multiple users create a session, your app could assign that session to a random shard; then the clients only need to be connected to that database in order to receive their realtime updates.
Most IoT apps can also take advantage of sharding. If you want to have a gigantic number of tiny sensors sending periodic updates, they probably don’t all need to write to the same RTDB instance. You can create lots of shards (we support up to 1000), and assign each sensor to a shard. If you're interested in working with multiple versions of the Realtime Database in the same project, make sure to check out our documentation.
Of course, if you're looking for a powerful realtime database that scales without sharding, we still recommend our newer database, Cloud Firestore, for most new projects. It has the same magical realtime, offline, serverless functionality as the Realtime Database, but has been architected for higher reliability, has more powerful queries, and locations around the world.
Nonetheless, there are some use cases for which the Realtime Database is the right choice, even for new applications. That’s why we’re continuing to invest in making it even better for these purposes.
When should you pick the Realtime Database for a new project? The short answer is that if you are building an application that will have lots of tiny operations, the Realtime Database may be less expensive and more performant. For the whiteboarding app, you’d want to send lots of frequent little updates as the users draw on the whiteboard, and you’d want latency to be as low as possible. In the IoT case, performance may not be as important, but the Realtime Database may end up cheaper than Cloud Firestore if you are sending a massive stream of tiny writes.
Of course, you can use both Cloud Firestore and the Realtime Database together in the same project — we encourage it! For instance, you can use the Realtime Database to power the live whiteboard feature, but then persist the whiteboard contents to Firestore periodically to take advantage of its 99.999% availability and less expensive storage.
We hope you are excited about the increased scaling capabilities of the Realtime Database. And we also hope this guidance helps you decide between Cloud Firestore and the Realtime Database for new projects. As always if you have any questions, feel free to reach out on StackOverflow, or the firebase-talk discussion group.
When we think of scaling we usually imagine spiky charts of users hitting a database or processing computationally expensive queries. What we don't always think about it is deleting data. Handling large amounts of deletes is an important part of scaling a database. Imagine a system that's required to delete historical records at a specific deadline. If these records are hundreds of gigabytes in size, it will likely be difficult to delete them all without bogging the database down for the rest of its users. This exact scenario hasn't always been easy with the Firebase Realtime Database, but we're excited to say that it just got a lot easier.
Today, we're introducing a new way to efficiently perform large deletes!
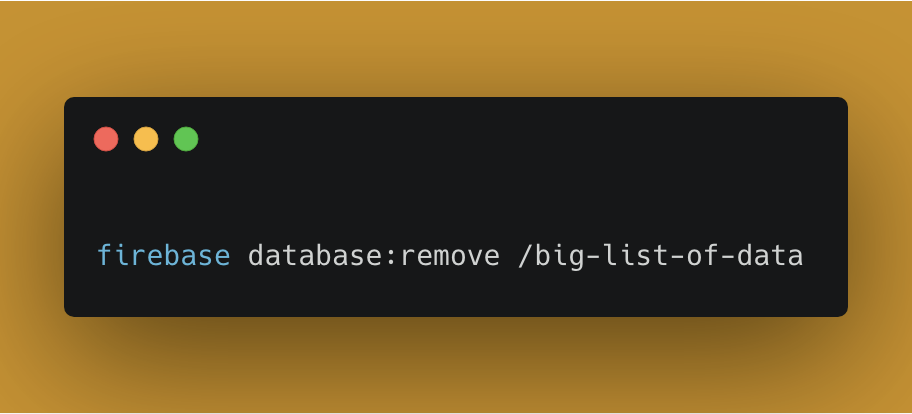
If you want to delete a large node, the new recommended approach is to use the Firebase CLI (> v6.4.0). The CLI automatically detects a large node and performs a chunked delete efficiently.
$ firebase database:remove /path/to/delete
Keep in mind that in order to delete a large node, the Firebase CLI has to break it down into chunks. This means that clients can see a partial state where part of the data is missing. Writes in the path that is being deleted will still succeed, but the CLI tool will eventually delete all data at this path. This behavior is acceptable if no app depends on this node. However, if there are active listeners within the delete path, please make sure the listener can gracefully handle partial documents.
If you want consistency and fast deletion, consider using a special field, a.k.a a tombstone to mark this document as hidden, and then run a cloud function cron job to asynchronously purge the data. You can use Firebase Rules to disallow access to hidden documents.
We've also added a configuration option (defaultWriteSizeLimit) to the Realtime Database that allows you to specify a write size limit. This limit allows you to prevent operations (large deletes and writes) from being executed on your database if they exceed this limit.
defaultWriteSizeLimit
You can use this option to prevent app code from accidentally triggering a large operation, which would make your app unresponsive for a time. For more detail, please see our documentation about this option.
You can check and update the configuration via the CLI tool (version 6.4.0 and newer). There are four available thresholds. You can pick appropriate threshold based on your application requirement
small
write
medium
large
unlimited
Note: The target time is not a guaranteed cutoff off. The estimated time may be off from the actual write time.
$ firebase database:settings:set defaultWriteSizeLimit unlimited --instance <database-name> $ firebase database:settings:get defaultWriteSizeLimit --instance <database-name>
For REST requests, you can override defaultWriteSizeLimit with the writeSizeLimit query parameter. In addition, REST queries support a special writeSizeLimit value:
writeSizeLimit
tiny
firebase database:remove
For example:
$ curl -X PUT \ "https://<database-name>.firebaseio.com/path.json?writeSizeLimit=medium"
The default defaultWriteSizeLimit for new databases is large. In order to avoid affecting existing apps, the setting will remain at unlimited for existing projects for now.
We do want to extend this protection to everyone. So this summer (June~August, 2019), will set defaultWriteSizeLimit to large for existing databases that have not configured defaultWriteSizeLimit. To avoid disruption, we will exclude any databases that have triggered at least one large delete in the past three months.
defaultWriteSizeLimit.
These controls can help you keep your apps responsive and your users happy. We suggest setting defaultWriteSizeLimit for your existing apps today.
Let us know what you think of this new feature! Leave a message in our Google group.
Here at Firebase, we work hard to keep your apps secure and protect your users. In keeping with that mission, we're proud to announce that we recently implemented Certificate Transparency for the Realtime Database.
Certificate Transparency makes it possible to detect SSL certificates that have been mistakenly issued by a certificate authority. It also makes it possible to identify certificate authorities that have gone rogue and are maliciously issuing certificates. These attack vectors are rare but serious ways of circumventing the protections that SSL/TLS grants to online communication.
Part of Certificate Transparency is the issuance of a Signed Certificate Timestamp (SCT), which Realtime Database responses now include. We have already been sending the SCT when browsers like Chrome requested it, but now it is always bundled in the response.
From today on, every connection from one of your users to your database will be protected by the SCT. Please be aware that the SCT creates a little more SSL overhead, so each response gets slightly larger. The percentage increase for your app is dependent on many factors, such as your average response size, and which clients your customers use. Since outgoing bandwidth (egress) is billed, you may see a slight bill increase as a result.
Certificate Transparency is a great enhancement to SSL/TLS, and we Firebasers are excited about what it means for the security of the internet going forward. We're delighted to bring this protection to you and your users.
At Firebase, we're committed to transparency and a thriving developer community, which is why we started open sourcing our SDKs last year. Today, we're continuing on that mission by open sourcing our first Firebase Android SDKs.
For this initial release, we are open sourcing our Cloud Firestore, Cloud Functions, Realtime Database, Storage, and FirebaseCommon SDKs. We intend to release more SDKs going forward, so don't forget to star or watch the repo.
The Firebase Android SDK source code can be found at https://github.com/firebase/firebase-android-sdk.
For the SDKs included in the repository, GitHub is the source of truth, though you can also find our project in the Google Open Source directory and on firebaseopensource.com. On GitHub, you'll be able to observe the progress of new features and bug fixes and build a local copy of the SDK on your development machine to preview upcoming releases. Our GitHub README provides more details on how you build, test, and contribute to our Android SDK.
As with our already available open-source iOS, Javascript, Node.js, Java, Python, Go and .NET SDKs, should you find issues in our code you can report them through the standard GitHub issue tracker. Your feedback is vital in shaping the future of Firebase and we look forward to hearing from you on GitHub!
Hey, welcome to part 3 in this series about using lifecycle-aware Android Architecture Components with Firebase Realtime Database. In part 1, we started with a simple Activity that uses database listeners to keep its UI fresh as data changes in the database. We converted that to use LiveData and ViewModel to remove the boilerplate of dealing with the listeners during the Activity lifecycle. Then, in part 2, we completely refactored away all mention of Realtime Database from the Activity, and implemented a performance enhancement. This optimization uses MediatorLiveData and some threading, for the case where data manipulation might be too expensive operation to perform on the main thread.
MediatorLiveData
There's one more optimization that can be applied in the code. It could have a large impact on performance, depending on how much data your database listeners are receiving. It has to do with how our FirebaseQueryLiveData implementation deals with the database listener during its onActive() and onInactive() methods. Here it is again:
FirebaseQueryLiveData
onActive()
onInactive()
public class FirebaseQueryLiveData extends LiveData<DataSnapshot> { private static final String LOG_TAG = "FirebaseQueryLiveData"; private final Query query; private final MyValueEventListener listener = new MyValueEventListener(); public FirebaseQueryLiveData(Query query) { this.query = query; } public FirebaseQueryLiveData(DatabaseReference ref) { this.query = ref; } @Override protected void onActive() { query.addValueEventListener(listener); } @Override protected void onInactive() { query.removeEventListener(listener); } private class MyValueEventListener implements ValueEventListener { @Override public void onDataChange(DataSnapshot dataSnapshot) { setValue(dataSnapshot); } @Override public void onCancelled(DatabaseError databaseError) { Log.e(LOG_TAG, "Can't listen to query " + query, databaseError.toException()); } } }
The key detail to note here is that a database listener is added during onActive() and removed during onInactive(). The Activity that makes use of FirebaseQueryLiveData executes this code during its onCreate():
onCreate()
HotStockViewModel viewModel = ViewModelProviders.of(this).get(HotStockViewModel.class); LiveData<DataSnapshot> liveData = viewModel.getDataSnapshotLiveData(); liveData.observe(this, new Observer<DataSnapshot>() { @Override public void onChanged(@Nullable DataSnapshot dataSnapshot) { if (dataSnapshot != null) { // update the UI here with values in the snapshot } } });
The observer here follows the lifecycle of the Activity. LiveData considers an observer to be in an active state if its lifecycle is in the STARTED or RESUMED state. The observer transitions to an inactive state if its lifecycle is in the DESTROYED state. The onActive() method is called when the LiveData object has at least one active observer, and the onInactive() method is called when the LiveData object doesn't have any active observers. So, what happens here when the Activity is launched, then goes through a configuration change (such as a device reorientation)? The sequence of events (when there is a single UI controller observing a FirebaseQueryLiveData) is like this:
Activity
LiveData
I've bolded the steps that deal with the database listener. You can see here the Activity configuration change caused the listener to be removed and added again. These steps spell out the cost of a second round trip to and from the Realtime Database server to pull down all the data for the second query, even if the results didn't change. I definitely don't want that to happen, because LiveData already retains the latest snapshot of data! This extra query is wasteful, both of the end user's data plan, and and counts against the quota or the bill of your Firebase project.
There's no easy way to change the way that the LiveData object becomes active or inactive. But we can make some guesses about how quickly that state could change when the Activity is going through a configuration change. Let's make the assumption that a configuration change will take no more than two seconds (it's normally much faster). With that, one strategy could add a delay before FirebaseQueryLiveData removes the database listener after the call to onInactive(). Here's an implementation of that, with a few changes and additions to FirebaseQueryLiveData:
private boolean listenerRemovePending = false; private final Handler handler = new Handler(); private final Runnable removeListener = new Runnable() { @Override public void run() { query.removeEventListener(listener); listenerRemovePending = false; } }; @Override protected void onActive() { if (listenerRemovePending) { handler.removeCallbacks(removeListener); } else { query.addValueEventListener(listener); } listenerRemovePending = false; } @Override protected void onInactive() { // Listener removal is schedule on a two second delay handler.postDelayed(removeListener, 2000); listenerRemovePending = true; }
Here, I'm using a Handler to schedule the removal of the database listener (by posting a Runnable callback that performs the removal) on a two second delay after the LiveData becomes inactive. If it becomes active again before those two seconds have elapsed, we simply eliminate that scheduled work from the Handler, and allow the listener to keep listening. This is great for both our users and our wallets!
Handler
Runnable
Are you using lifecycle-aware Android Architecture components along with Firebase in your app? How's it going? Join the discussion of all things Firebase on our Google group firebase-talk.
Welcome to part 2 of this blog series on using lifecycle-aware Android Architecture Components (LiveData and ViewModel) along with Firebase Realtime Database to implement more robust and testable apps! In the first part, we saw how you can use LiveData and ViewModel to simplify your Activity code, by refactoring away most of the implementation details of Realtime Database from an Activity. However, one detail remained: the Activity was still reaching into the DataSnapshot containing the stock price. I'd like to remove all traces of the Realtime Database SDK from my Activity so that it's easier to read and test. And, ultimately, if I change the app to use Firestore instead of Realtime Database, I won't even have to change the Activity code at all.
ViewModel
DataSnapshot
Here's a view of the data in the database:
and here's the code that reads it out of DataSnapshot and copies into a couple TextViews:
// update the UI with values from the snapshot String ticker = dataSnapshot.child("ticker").getValue(String.class); tvTicker.setText(ticker); Float price = dataSnapshot.child("price").getValue(Float.class); tvPrice.setText(String.format(Locale.getDefault(), "%.2f", price));
The Realtime Database SDK makes it really easy to convert a DataSnapshot into a JavaBean style object. The first thing to do is define a bean class whose getters and setters match the names of the fields in the snapshot:
public class HotStock { private String ticker; private float price; public String getTicker() { return ticker; } public void setTicker(String ticker) { this.ticker = ticker; } public float getPrice() { return price; } public void setPrice(float price) { this.price = price; } public String toString() { return "{HotStock ticker=" + ticker + " price=" + price + "}"; } }
Then I can tell the SDK to automatically perform the mapping like this:
HotStock stock = dataSnapshot.getValue(HotStock.class)
After that line executes, the new instance of HotStock will contain the values for ticker and price. Using this handy line of code, I can update my HotStockViewModel implementation to perform this conversion by using a transformation. This allows me to create a LiveData object that automatically converts the incoming DataSnapshot into a HotStock. The conversion happens in a Function object, and I can assemble it like this in my ViewModel:
HotStock
ticker
price
HotStockViewModel
Function
// This is a LiveData<DataSnapshot> from part 1 private final FirebaseQueryLiveData liveData = new FirebaseQueryLiveData(HOT_STOCK_REF); private final LiveData<HotStock> hotStockLiveData = Transformations.map(liveData, new Deserializer()); private class Deserializer implements Function<DataSnapshot, HotStock> { @Override public HotStock apply(DataSnapshot dataSnapshot) { return dataSnapshot.getValue(HotStock.class); } } @NonNull public LiveData<HotStock> getHotStockLiveData() { return hotStockLiveData; }
The utility class Transformations provides a static method map() that returns a new LiveData object given a source LiveData object and a Function implementation. This new LiveData applies the Function to every object emitted by the source, then turns around and emits the output of the Function. The Deserializer function here is parameterized by the input type DataSnapshot and the output type HotStock, and it has one simple job - deserialize a DataSnapshot into a HotStock. Lastly, we'll add a getter for this new LiveData that emits the transformed HotStock objects.
Transformations
map()
Deserializer
With these additions, the application code can now choose to receive updates to either DataSnapshot or HotStock objects. As a best practice, ViewModel objects should emit objects that are fully ready to be consumed by UI components, so that those components are only responsible for displaying data, not processing data. This means that HotStockViewModel should be doing all the preprocessing required by the UI layer. This is definitely the case here, as HotStock is fully ready to consume by the Activity that's populating the UI. Here's what the entire Activity looks like now:
public class MainActivity extends AppCompatActivity { private TextView tvTicker; private TextView tvPrice; @Override protected void onCreate(@Nullable Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(R.layout.activity_main); tvTicker = findViewById(R.id.ticker); tvPrice = findViewById(R.id.price); HotStockViewModel hotStockViewModel = ViewModelProviders.of(this).get(HotStockViewModel.class); LiveData<HotStock> hotStockLiveData = hotStockViewModel.getHotStockLiveData(); hotStockLiveData.observe(this, new Observer() { @Override public void onChanged(@Nullable HotStock hotStock) { if (hotStock != null) { // update the UI here with values in the snapshot tvTicker.setText(hotStock.getTicker()); tvPrice.setText(String.format(Locale.getDefault(), "%.2f", hotStock.getPrice())); } } }); } }
public class MainActivity extends AppCompatActivity { private TextView tvTicker; private TextView tvPrice; @Override protected void onCreate(@Nullable Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(R.layout.activity_main); tvTicker = findViewById(R.id.ticker); tvPrice = findViewById(R.id.price); HotStockViewModel hotStockViewModel = ViewModelProviders.of(this).get(HotStockViewModel.class);
hotStockLiveData.observe(this, new Observer() { @Override public void onChanged(@Nullable HotStock hotStock) { if (hotStock != null) { // update the UI here with values in the snapshot tvTicker.setText(hotStock.getTicker()); tvPrice.setText(String.format(Locale.getDefault(), "%.2f", hotStock.getPrice())); } } }); } }
All the references to Realtime Database objects are gone now, abstracted away behind HotStockViewModel and LiveData! But there's still one potential problem here.
All LiveData callbacks to onChanged() run on the main thread, as well as any transformations. The example I've given here is very small and straightforward, and I wouldn't expect there to be performance problems. But when the Realtime Database SDK deserializes a DataSnapshot to a JavaBean type object, it uses reflection to dynamically find and invoke the setter methods that populate the bean. This can become computationally taxing as the quantity and size of the objects increase. If the total time it takes to perform this conversion is over 16ms (your budget for a unit of work on the main thread), Android starts dropping frames. When frames are dropped, it no longer renders at a buttery-smooth 60fps, and the UI becomes choppy. That's called "jank", and jank makes your app look poor. Even worse, if your data transformation performs any kind of I/O, your app could lock up and cause an ANR.
onChanged()
If you have concerns that your transformation can be expensive, you should move its computation to another thread. That can't be done in a transformation (since they run synchronously), but we can use something called MediatorLiveData instead. MediatorLiveData is built on top of a map transform, and allows us to observe changes other LiveData sources, deciding what to do with each event. So I'll replace the existing transformation with one that gets initialized in the no-arg constructor for HotStockViewModel from part 1 of this series:
private final FirebaseQueryLiveData liveData = new FirebaseQueryLiveData(HOT_STOCK_REF); private final MediatorLiveData<HotStock> hotStockLiveData = new MediatorLiveData<>(); public HotStockViewModel() { // Set up the MediatorLiveData to convert DataSnapshot objects into HotStock objects hotStockLiveData.addSource(liveData, new Observer<DataSnapshot>() { @Override public void onChanged(@Nullable final DataSnapshot dataSnapshot) { if (dataSnapshot != null) { new Thread(new Runnable() { @Override public void run() { hotStockLiveData.postValue(dataSnapshot.getValue(HotStock.class)); } }).start(); } else { hotStockLiveData.setValue(null); } } }); }
Here, we see that addSource() is being called on the MediatorLiveData instance with a source LiveData object and an Observer that gets invoked whenever that source publishes a change. During onChanged(), it offloads the work of deserialization to a new thread. This threaded work is using postValue() to update the MediatorLiveData object, whereas the non-threaded work when (dataSnapshot is null) is using setValue(). This is an important distinction to make, because postValue() is the thread-safe way of performing the update, whereas setValue() may only be called on the main thread.
addSource()
Observer
postValue()
setValue()
NOTE: I don't recommend starting up a new thread like this in your production app. This is not an example of "best practice" threading behavior. Optimally, you might want to use an Executor with a pool of reusable threads (for example) for a job like this.
Executor
Now that we've removed Realtime Database objects from the Activity and accounted for the performance of the transformation from DataSnapshot to HotStock, there's still another performance improvement to make here. When the Activity goes through a configuration change (such as a device reorientation), the FirebaseQueryLiveData object will remove its database listener during onInactive(), then add it back during onActive(). While that doesn't seem like a problem, it's important to realize that this will cause another (unnecessary) round trip of all data under /hotstock. I'd rather leave the listener added and save the user's data plan in case of a reorientation. So, in the next part of this series, I'll look at a way to make that happen.
/hotstock
I hope to see you next time, and be sure to follow @Firebase on Twitter to get updates on this series! You can click through to part 3 right here.
This year at Google I/O 2017, the Android platform team announced the availability of Android Architecture Components, which provides libraries that help you design robust, testable, and maintainable apps. Among all the tools it offers, I'm particularly impressed by the way it helps you manage the lifecycle of your app's activities and fragments - a common concern for Android developers.
In this blog series, I'll explore how these libraries can work together with the Firebase Realtime Database SDK to help architect your app. The way client apps read data from Realtime Database is through listeners that get called with updates to data as it's written. This allows you to easily keep your app's UI fresh with the latest data. It turns out that this model of listening to database changes works really well Android Architecture Components. (Also note that the information here applies equally well to Firestore, which also delivers data updates to client apps in real time.)
Android apps that use Realtime Database often start listening for changes during the onStart() lifecycle method, and stop listening during onStop(). This ensures that they only receive changes while an Activity or Fragment is visible on screen. Imagine you have an Activity that displays the ticker and most recent price of today's hot stock from the database. The Activity looks like this:
onStart()
onStop()
Fragment
public class MainActivity extends AppCompatActivity { private static final String LOG_TAG = "MainActivity"; private final DatabaseReference ref = FirebaseDatabase.getInstance().getReference("/hotstock"); private TextView tvTicker; private TextView tvPrice; @Override protected void onCreate(@Nullable Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(R.layout.activity_main); tvTicker = findViewById(R.id.ticker); tvPrice = findViewById(R.id.price); } @Override protected void onStart() { super.onStart(); ref.addValueEventListener(listener); } @Override protected void onStop() { ref.removeEventListener(listener); super.onStop(); } private ValueEventListener listener = new ValueEventListener() { @Override public void onDataChange(DataSnapshot dataSnapshot) { // update the UI here with values in the snapshot String ticker = dataSnapshot.child("ticker").getValue(String.class); tvTicker.setText(ticker); Float price = dataSnapshot.child("price").getValue(Float.class); tvPrice.setText(String.format(Locale.getDefault(), "%.2f", price)); } @Override public void onCancelled(DatabaseError databaseError) { // handle any errors Log.e(LOG_TAG, "Database error", databaseError.toException()); } }; }
It's pretty straightforward. A database listener receives updates to the stock price located at /hotstock in the database, and the values are placed into a couple TextView objects. For very simple cases like this, there's not a problem. But if this app becomes more complex, there's a couple immediate issues to be aware of:
TextView
1. Boilerplate
There's a lot of standard boilerplate here for defining a DatabaseReference at a location in the database and managing its listener during onStart() and onStop(). The more listeners involved, the more boilerplate code will clutter this code. And a failure to remove all added listeners could result in data and memory leaks - one simple mistake could cost you money and performance.
DatabaseReference
2. Poor testability and readability
While the effect of the code is straightforward, it's difficult to write pure unit tests that verify the logic, line by line. Everything is crammed into a single Activity object, which becomes difficult to read and manage.
Digging into the libraries provided by Architecture Components, you'll find there are two classes in particular that are helpful to address the above issues: ViewModel and LiveData. If you haven't read about how these work, please take a moment to read about ViewModel and LiveData to learn about them. I'll also be extending LiveData, so take a look there as well. It's important to understand the way they interact with each other, in addition to the LifecycleOwner (e.g. an Activity or Fragment) that hosts them.
LifecycleOwner
Extending LiveData with Firebase Realtime Database
LiveData is an observable data holder class. It respects the lifecycle of Android app components, such as activities, fragments, or services, and only notifies app components that are in an active lifecycle state. I'll use it here to listen to changes to a database Query or DatabaseReference (note that a DatabaseReference itself is a Query), and notify an observing Activity of those changes so it can update its UI. These notifications come in the form of DataSnapshot objects that you'd normally expect from the database listener. Here's a LiveData extension that does exactly that:
Query
public class FirebaseQueryLiveData extends LiveData<DataSnapshot> { private static final String LOG_TAG = "FirebaseQueryLiveData"; private final Query query; private final MyValueEventListener listener = new MyValueEventListener(); public FirebaseQueryLiveData(Query query) { this.query = query; } public FirebaseQueryLiveData(DatabaseReference ref) { this.query = ref; } @Override protected void onActive() { Log.d(LOG_TAG, "onActive"); query.addValueEventListener(listener); } @Override protected void onInactive() { Log.d(LOG_TAG, "onInactive"); query.removeEventListener(listener); } private class MyValueEventListener implements ValueEventListener { @Override public void onDataChange(DataSnapshot dataSnapshot) { setValue(dataSnapshot); } @Override public void onCancelled(DatabaseError databaseError) { Log.e(LOG_TAG, "Can't listen to query " + query, databaseError.toException()); } } }
With FirebaseQueryLiveData, whenever the data from the Query given in the constructor changes, MyValueEventListener triggers with a new DataSnapshot, and it notifies any observers of that using the setValue() method on LiveData. Notice also that MyValueEventListener is managed by onActive() and onInactive(). So, whenever the Activity or Fragment associated with this LiveData object is on screen (in the STARTED or RESUMED state), the LiveData object is "active", and the database listener will be added.
MyValueEventListener
The big win that LiveData gives us is the ability to manage the database listener according to the state of the associated Activity. There's no possibility of a leak here because FirebaseQueryLiveData knows exactly when and how to set up and tear down its business. Note that we can reuse this class for all kinds of Firebase queries. This FirebaseQueryLiveData class is a very reusable class!
Now that we have a LiveData object that can read and distribute changes to the database, we need a ViewModel object to hook that up to the Activity. Let's take a look at how to do that.
Implementing a ViewModel to manage FirebaseQueryLiveData
ViewModel implementations contain LiveData objects for use in a host Activity. Because a ViewModel object survives Activity configuration changes (e.g. when the user reorients their device), its LiveData member object will be retained as well. The lifetime of a ViewModel with respect to its host Activity can be illustrated like this:
Here's a ViewModel implementation that exposes a FirebaseQueryLiveData that listens to the location /hotstock in a Realtime Database:
public class HotStockViewModel extends ViewModel { private static final DatabaseReference HOT_STOCK_REF = FirebaseDatabase.getInstance().getReference("/hotstock"); private final FirebaseQueryLiveData liveData = new FirebaseQueryLiveData(HOT_STOCK_REF); @NonNull public LiveData<DataSnapshot> getDataSnapshotLiveData() { return liveData; } }
Note that this ViewModel implementation exposes a LiveData object. This allows the Activity that uses HotStockViewModel to actively observe any changes to the underlying data under /hotstock in the database.
Using LiveData and ViewModel together in an Activity
Now that we have LiveData and ViewModel implementations, we can make use of them in an Activity. Here's what the Activity from above now looks like after refactoring to use LiveData and ViewModel:
public class MainActivity extends AppCompatActivity { private TextView tvTicker; private TextView tvPrice; @Override protected void onCreate(@Nullable Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(R.layout.activity_main); tvTicker = findViewById(R.id.ticker); tvPrice = findViewById(R.id.price); // Obtain a new or prior instance of HotStockViewModel from the // ViewModelProviders utility class. HotStockViewModel viewModel = ViewModelProviders.of(this).get(HotStockViewModel.class); LiveData<DataSnapshot> liveData = viewModel.getDataSnapshotLiveData(); liveData.observe(this, new Observer<DataSnapshot>() { @Override public void onChanged(@Nullable DataSnapshot dataSnapshot) { if (dataSnapshot != null) { // update the UI here with values in the snapshot String ticker = dataSnapshot.child("ticker").getValue(String.class); tvTicker.setText(ticker); Float price = dataSnapshot.child("price").getValue(Float.class); tvPrice.setText(String.format(Locale.getDefault(), "%.2f", price)); } } }); } }
It's about 20 lines of code shorter now, and easier to read and manage!
During onCreate(), it gets a hold of a HotStockViewModel instance using this bit of code:
HotStockViewModel viewModel = ViewModelProviders.of(this).get(HotStockViewModel.class);
ViewModelProviders is a utility class from Architecture Components that manages ViewModel instances according to the given lifecycle component. In the above line, the resulting HotStockViewModel object will either be newly created if no ViewModel of the named class for the Activity exists, or obtained from a prior instance of the Activity before a configuration change occurred.
ViewModelProviders
With an instance of HotStockViewModel, the Activity response changes to its LiveData by simply attaching an observer. The observer then updates the UI whenever the underlying data from the database changes.
So, what's the advantage to doing things this way?
ValueEventListener
If you look at the new Activity implementation, you can see that most of the details of working with Firebase Realtime Database have been moved out of the way, into FirebaseQueryLiveData, except for dealing with the DataSnapshot. Ideally, I'd like to remove all references to Realtime Database altogether from the Activity so that it doesn't have to know or care where the data actually comes from. This is important if I ever want to migrate to Firestore - the Activity won't have to change much, if at all.
There's another subtle issue with the fact that each configuration change removes and re-adds the listener. Each re-add of the listener effectively requires another round trip with the server to fetch the data again, and I'd rather not do that, in order to avoid consuming the user's limited mobile data. Enabling disk persistence helps, but there's a better way (stay tuned to this series for that tip!).
We'll solve these two problems in future posts, so stay tuned here to the Firebase Blog by following @Firebase on Twitter! You can click through to part 2 right here.
A long while back, David East wrote a handy blog post about using the Firebase CLI to read and write your Firebase Realtime Database. The CLI has evolved a lot since then, so I'd like to share some of what's changed (and new!).
When I first started working with Realtime Database, I'd spend a fair amount of time in the Firebase console manually entering some data to work with. It's kinda fun to make changes there, then see them immediately in my app! But I soon discovered that it's kind of repetitive and time consuming to test like that. Instead, I could write a program to make the changes for me, but that wasn't a very flexible option. For easy reading and writing of data in my database, I found that the Firebase CLI is the best option for me. So, I'll share some of what it does here and how it can come in handy. All my examples will be using the Bash shell - you may have to modify them for other shells.
The Firebase CLI requires you to set aside a project directory, log in, and select a project that you want to work with, so be sure to follow the instructions to get set up with your existing project.
To write data from the command line use the firebase database:set command:
firebase database:set
firebase database:set /import data.json
The first argument to database:set is the path within the database to be written (here, /import), and the second is the JSON file to read from. If you don't have a file, and would rather provide the JSON on the command line, you can do this also with the --data flag:
/import
--data
firebase database:set /import --data '{"foo": "bar baz"}'
Notice that the JSON is quoted for the command line with single quotes. Otherwise, the space between the colon and "bar" would fool your shell into thinking that there are two arguments there. You can't use double quotes to quote this JSON string either, because JSON uses those quotes for its own strings. Escaping JSON for a unix command line can be tricky, so be careful about that! (For further thought: what if there was a single quote in one of the JSON strings?)
Also, you can pipe or redirect JSON to stdin. So, if you have a program that generates some JSON to add to your database, you can do it like this:
echo '{"foo": "bar baz"}' | firebase database:set /import --confirm
Notice that the --confirm flag is passed here to prevent the command from asking if you're OK potentially overwriting data. Piping to stdin won't work without it!
--confirm
The database:set command is great for initially populating your database with a setup script. If you run automated integration tests, the CLI is a handy way of scripting the initialization of your test environment.
database:set
It's also super handy for quickly triggering Cloud Functions database triggers, so you don't have to type in stuff at the command prompt every time you have something complicated to test.
Reading data from your database with the Firebase CLI is similarly easy. Here's how you fetch all the data under /messages as a JSON blob:
/messages
firebase database:get /messages
To save the output to a file, you can use a shell redirect, or the --output flag:
firebase database:get /messages > messages.json firebase database:get /messages --output messages.json
You'll notice the JSON output is optimized for space, which makes it hard to read. For something a little easier on the eyes, you can have the output "pretty-printed" for readability:
firebase database:get /messages --pretty
You can also sort and limit data just like the Firebase client APIs.
firebase database:get /messages --order-by-value date
To see all the options for reading and sorting, be sure to see the CLI help (all Firebase CLI commands share their usage like this):
firebase database:get --help
You've probably used the Realtime Database push function to add data to a node in your database. You can do the same with the CLI:
firebase database:push /messages --data '{"name":"Doug","text":"I heart Firebase"}'
This will create a unique push id under /messages and add the data under it. (Did you know that push IDs recently switched from starting with "-K" to "-L"?)
If you want to update some values at a location without overwriting that entire location, use database:update:
database:update
firebase database:update /users/-L-7Zl_CiHW62YWLO5I7 --data '{"name":"CodingDoug"}'
For those times when you need to remove something completely, there is database:remove. This command will blow away your entire database, unconditionally, kinda like rm -rf /. Be careful with this one:
database:remove
rm -rf /
firebase database:remove / --confirm
Sometimes you might want to simply copy the contents of your database from one project to another (for example, your development environment to staging). This is really easy by piping the stdout of database:get to the stdin of database:set:
database:get
firebase --project myproject-dev database:get / | \ firebase --project myproject-staging database:set / --confirm
Note here the use of --project to specify which Firebase project is to be used for reading and writing. This is your project's unique id in the Firebase console.
--project
If you find yourself repeating a set of commands, it's probably time to make a bash function. Save your function to your .bash_profile and you'll be able to access them from anywhere in your shell command line.
Do you often copy data between databases? The function below makes it easy:
function transfer_to() { local src_db="${1}" local dest_db="${2}" local path="${3:-/}" firebase database:get --project "$src_db" "$path" | firebase --project "$dest_db" database:set "$path" --confirm }
To use the function just call the transfer_to command (as if it were any other command) with the names of the project to copy to and from:
transfer_to myproject-dev myproject-staging
The command line is one of the most versatile tools in an engineer's toolbox. What are you doing with the CLI? We'd love to hear from you, so please shout out to us on Twitter. If you have any technical questions, post those on Stack Overflow with the firebase tag. And for bug reports and feature requests, use this form.