Hi, Firestore developers. We are pleased to announce that with the latest version of the client SDKs, you are able to use Firestore data bundles in your mobile and web applications! Data bundles can make certain types of Firestore applications much faster or less expensive.
That's great! Just one tiny little follow-up question: What are data bundles?
So essentially, data bundles are serialized groups of documents -- either individual documents, or a number of documents that you've retrieved using a specific query.
You can save these data bundles onto a CDN or your favorite object storage service, and then load them from your client applications. Once they've been loaded on to your client, your clients can read them in from your local cache like any other locally-cached Firestore data.
Well that just sounds like a database query with extra steps. Why would I want to do this?
The biggest reason is that by having your clients read common queries from a bundle on a CDN and then querying specifically against that cached data, you can avoid making extra calls against the Firestore database. If your application has a substantial number of users, this can lead to some cost savings, and could potentially be faster, too.
But to be clear, data bundles are an advanced feature and probably not something you should be considering until your application has a pretty sizable user base.
So what kinds of documents make sense to put into bundles?
The best kinds of bundles are ones where a majority of your users will be reading in all of the documents in that bundle, the number of documents is on the smaller side, and the contents of that data doesn't change too frequently.
Some good examples for this might be:
Data bundles are not good for:
I just had an idea: What if I were to stuff my entire database into a bundle, load that bundle onto my client, and then just query my entire database using only my cache?
That's a terrible idea.
Remember, the Firestore cache is not particularly fast when it comes to searching through large amounts of data. Overloading your cache by asking it to store a lot of documents that your users won't ever use is a good way of slowing your application to an unusable state. You should really only be leveraging data bundles to load up documents that most, if not all, of your users will be reading in.
Also, keep in mind that with bundles, you have to load in the entire bundle of documents when you load up a bundle, whereas with a normal document query, you're only downloading the documents that have changed from your local cache. So from a data usage perspective, stuffing too many documents into a bundle can be quite heavy.
Gotcha. So how would I implement these?
You can read the documentation for all the details, but in general, the process will work something like this:
So, once they're loaded, I can query them like normal data?
Yes. They'll be merged in with your locally cached data and you can make use of them like you would any other cached data. The data bundle also remembers the names of the queries you used to generate the bundle, so you can refer to these queries by name instead of re-creating them in code.
And how do I make sure I'm querying bundled data without incurring any additional Firestore costs?
The best way is to force your client to use the cached data. When you make a document request or database query, you're able to add an option like {source: 'cache'} that directs your client to only use the cached data, even if the network is available.
{source: 'cache'}
Tell me more about these "named queries" -- are these different from regular queries?
Not really -- the trick to using bundles effectively is that you want to make sure the query you're requesting on the client is exactly the same as the query that generated the bundle you've loaded. You could certainly do this in code, but by using a named query, you're ensuring that the client will always make the same query that generated the bundle in the first place. There's less room for error that way.
This also means that you can modify the server query that generates the bundle and, assuming you're still using the same name, the client will also use this new query without your needing to update any of the client code.
Notice that the version number has changed, but the client can continue to run the "seed-data" named query
What if I wanted to include data bundles alongside the rest of my local application data when I publish it to app stores? That way, if a user opens my app for the first time and is offline, I can read in the bundle and use that as starter data for my application.
Yes; that can be another great use of bundles. The process is the same, except you'll be reading in the bundle using a local call. Just be aware of the warnings above -- Firestore wasn't designed to be an "offline-first" database, so try to only load in as much data as you'll need to make sure your application is functional. If you overload your cache with too much information, you'll slow it down too much.
Okay, I think I'm ready to start using data bundles in my application.
Great! As always, feel free to ask questions on Stack Overflow if you need help, or reach out to us on the Cloud Firestore Discussion list if you have any other suggestions. Happy coding!
A few months ago, we released Firestore for Games into open alpha. Thanks to all of your feedback, today, we're happy to announce that Cloud Firestore for Games is now publicly available in beta for C++ and Unity developers.
Firestore is a new performant and scalable serverless database option from Firebase for all your game development needs. It can help you add guilds to your latest mobile game, build a backend for your next big turn-based game, or add realtime chat. It’s also a key component of Firebase Extensions like Translate Text and Trigger Email, making it easier than ever to deploy pre-built complex workflows to your games.
Cloud Firestore is Google’s next generation cloud NoSQL database. It’s fast, reliable, and ready to scale for whatever workload you send its way. For the past two years it’s been generally available for the Web, iOS, and Android, and now it’s available for game developers as well.
Cloud Firestore exists alongside our existing Realtime Database. We’ll continue to support Realtime Database because it still works great for when you need to share data quickly with lots of players in near realtime. With Firestore you get more advanced queries on your data, 99.999% guaranteed uptime, and support for up to a million concurrent players -- all whilst remaining fast enough for many of your gaming backend needs. If you need more help deciding which database is right for you, check out this helpful guide.
Even though Firestore has been generally available for some time, the existing SDKs were built with the workflows and tools favored by app and web developers. Although game developers working in languages like JavaScript, Kotlin, and Swift would have no problem adopting the existing development kits, you would’ve had to jump through hoops to access them from Unity or C++. However, here at Firebase and Google, we want to make it easy for game developers to build, release, and operate games. So, we've built SDKs that bring game developers the same levels of convenience that app developers enjoy.
The Beta tag means that we believe that the Firestore SDKs for Unity and C++ are now stable enough that game developers can confidently use them in shipping games. Bugs and small API tweaks may crop up here and there as more developers pick it up, but Firestore is now a viable option when starting new game projects.
A big improvement that alpha testers might notice is that the new libraries have full feature parity with the platform specific Firestore SDKs. This includes many features alpha testers have asked for, such as OnSnapshotsInSync and support for the Blob data type. All transforms (like incrementing values) and query types (like "array-contains-any") are now implemented as well. We’ve also worked to make Firestore more consistent with the other Unity Firebase SDKs by ensuring that events fire on the main thread and adding more consistency to error reporting.
OnSnapshotsInSync
Since we’ve seen that many game developers tend to target multiple platforms with a single codebase, we’ve ensured that every feature in Firestore SDK C++ SDK works identically on iOS, Android, Windows, Mac, and Linux. This means that you can develop your game logic on a desktop computer with access to the entire Firestore for games feature set, and remain confident that it will continue to function on your target device. We've also fully opened sourced the C++ SDK so you can easily build, debug, and port your code to wherever you need.
This Firestore beta, like the alpha, ships with the standard Firebase C++ and Unity SDKs. To use it, simply ensure you’re using the latest Firebase SDK either by downloading the C++ zip or the Unity zip. Remember, if you come across any bugs, report them to us through our support channel or on the C++ or Unity issue pages.
Hi, Firebase developers!
In what might be my shortest (but most exciting) blog post this year, we wanted to let you know that Cloud Firestore now has support for not-equal queries. This means you can now query, for example, all documents in a "Projects" collection where the project's status field is not equal to the value "completed"
status
"completed"
On a similar note, Cloud Firestore also supports not-in queries, where you can query for documents where fields are not in a list of values. So you can, for example, find all documents in a "Projects" collection where the status isn't equal to "completed" or "dropped" with a single query.
not-in
"dropped"
Note that neither of these calls will allow you to fetch documents where this field doesn't exist. If a field is completely missing from a document, it will not be returned in your query results.
Notice that project 4593 does not get included in the results, because it has no owner field
When it comes to combining these not-equal operators with others in the same query, they have many of the same restrictions as other inequality operators (<, >=, etc.). You can't use a != operator against two different fields, for instance. Similarly, you can't use a != query on one field and then sort by a second field. And combining a != query in one field with a == query in another field requires your creating a composite index. Make sure to check out the official documentation for all the details.
<
>=
!=
==
This functionality is currently supported by the iOS, Android and Web client libraries, as well as the Node.js and Java server-side SDKs. Support for C++ and other server libraries is coming soon.
We hope this new addition makes it a little easier to develop Cloud Firestore-powered applications, and as always, if you have questions, please feel free to reach out on StackOverflow.
Happy coding!
Hello, Cloud Firestore developers! We wanted to let you know about some useful new querying features we've added to Cloud Firestore this week. Starting with… in queries!
in
With the in query, you can query a specific field for multiple values (up to 10) in a single query. You do this by passing a list containing all the values you want to search for, and Cloud Firestore will match any document whose field equals one of those values.
in queries are a good way to run simple OR queries in Cloud Firestore. For instance, if the database for your E-commerce app had a customer_orders collection, and you wanted to find which orders had a "Ready to ship", "Out for delivery" or "Completed" status, this is now something you can do with a single query, like so:
customer_orders
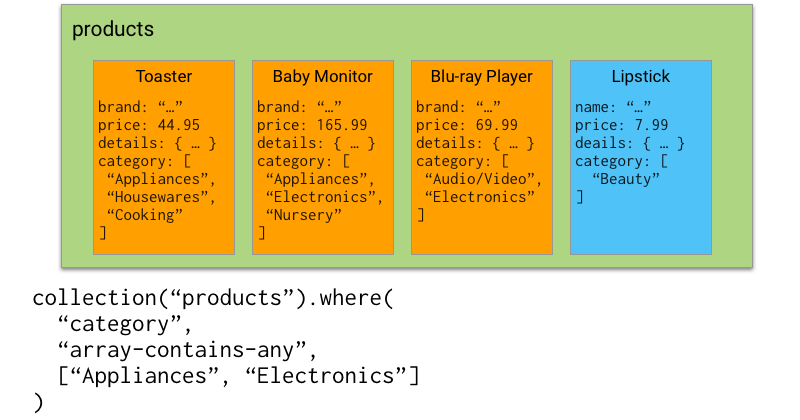
We've launched another feature similar to the in query, the array-contains-any query. This feature allows you to perform array-contains queries against multiple values at the same time.
array-contains-any
array-contains
For example, if your app had a products collection, and those documents contained an array of categories that every item belongs in, you could now look for items that were in the "Appliances" or "Electronics" category, by passing these values into a single array-contains-any query.
Note that the baby monitor document will only be returned once in your query, even though it matches with multiple categories.
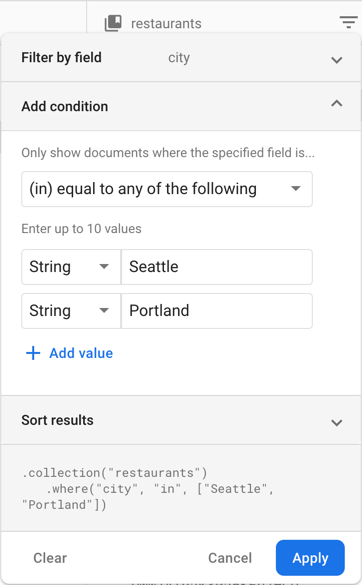
These queries are also supported in the Firebase console, which gives you the ability to try them out on your dataset before you start modifying your client code.
This also seems like a good time to remind you that you can apply filters directly in the Firebase console. Neat, huh?
Security rule behavior for these queries is pretty straightforward. Cloud Firestore will look at each potential value passed in for your in or array-contains-any operation and make sure your query would be allowed for that value. If any value is not allowed, the entire query fails.
For example, if your project was set up with these security rules…
match /projects/{project} { allow read: if resource.data.status != "secret"; ... }
This request would work…
db.collection("projects").where("status", "in", ["public", "unlisted"]);
...but this entire request would fail, because it's possible that our query will return documents that are forbidden in our security rules.
db.collection("projects").where("status", "in", ["public", "unlisted", "secret"]);
Not sure why we couldn't just send you back the allowed documents? Make sure to review the 'Rules are not filters' section of this video.
While we're excited to have you unlock the potential of in queries and array-contains-any queries, you should know about a few important limitations:
I think there's a lot of exciting things you can do now with in queries, and we're looking forward to hearing what new functionality you've added to your apps. So make sure you've upgraded your client libraries to the latest versions to take advantage of the new features, check out the documentation, and happy databasing!
Today, we’re delighted to announce that we’ve doubled the concurrent connections limit for the Firebase Realtime Database from 100k to 200k. This takes effect today, for all existing databases and new projects. And while this level of scalability will be enough for the majority of projects out there, some of you might want to support even more concurrent users. For that, you might want to consider sharding your database.
Many kinds of apps can scale much higher by sharding their data across multiple Realtime Database instances in a single project. The 200k concurrent user limit applies to each individual database, so the total number of concurrent connections increases linearly as you add more instances.
Sharding is a good strategy to employ when each client interacts with isolated parts of the database. Imagine a virtual whiteboard app, which is the sort of high-frequency, low-latency collaboration app for which the Realtime Database really excels. Whiteboard sessions don’t interact with each other -- just with the handful of users that are drawing together. So they can be sharded across an unlimited number of instances. When multiple users create a session, your app could assign that session to a random shard; then the clients only need to be connected to that database in order to receive their realtime updates.
Most IoT apps can also take advantage of sharding. If you want to have a gigantic number of tiny sensors sending periodic updates, they probably don’t all need to write to the same RTDB instance. You can create lots of shards (we support up to 1000), and assign each sensor to a shard. If you're interested in working with multiple versions of the Realtime Database in the same project, make sure to check out our documentation.
Of course, if you're looking for a powerful realtime database that scales without sharding, we still recommend our newer database, Cloud Firestore, for most new projects. It has the same magical realtime, offline, serverless functionality as the Realtime Database, but has been architected for higher reliability, has more powerful queries, and locations around the world.
Nonetheless, there are some use cases for which the Realtime Database is the right choice, even for new applications. That’s why we’re continuing to invest in making it even better for these purposes.
When should you pick the Realtime Database for a new project? The short answer is that if you are building an application that will have lots of tiny operations, the Realtime Database may be less expensive and more performant. For the whiteboarding app, you’d want to send lots of frequent little updates as the users draw on the whiteboard, and you’d want latency to be as low as possible. In the IoT case, performance may not be as important, but the Realtime Database may end up cheaper than Cloud Firestore if you are sending a massive stream of tiny writes.
Of course, you can use both Cloud Firestore and the Realtime Database together in the same project — we encourage it! For instance, you can use the Realtime Database to power the live whiteboard feature, but then persist the whiteboard contents to Firestore periodically to take advantage of its 99.999% availability and less expensive storage.
We hope you are excited about the increased scaling capabilities of the Realtime Database. And we also hope this guidance helps you decide between Cloud Firestore and the Realtime Database for new projects. As always if you have any questions, feel free to reach out on StackOverflow, or the firebase-talk discussion group.
This article originally appeared in the Firebase Developer Community blog.
We like saying lots of impressive things about Cloud Firestore's performance -- "performance scales with the size of the result set, not the underlying data set", and that "it's virtually impossible to create a slow query." And, for the most part, this is true. You can query a data set with billions upon billions of records in it, and get back results faster than your user can move their thumb away from the screen.
But with that said, we occasionally hear from developers that Cloud Firestore feels slow in certain situations, and it takes longer than expected to get results back from a query. So why is that? Let's take a look at some of the most common reasons that Cloud Firestore might seem slow, and what you can do to fix them.
Probably the most common explanation for a seemingly slow query is that your query is, in fact, running very fast. But after the query is complete, we still need to transfer all of that data to your device, and that's the part that's running slowly.
So, yes, you can go ahead and run a query of all sales people in your organization, and that query will run very fast. But if that result set consists of 2000 employee documents and each document includes 75k of data, you have to wait for your device to download 150MB of data before you can see any results.
The best way to fix this issue is to make sure you're not transferring down more data than you need. One simple option is to add limits to your queries. If you suspect that your user only needs the first handful of results from your employee list, add a limit(25) to the end of your query to download just the first batch of data, and then only download further records if your user requests them. And, hey, it just so happens I have an entire video all about this!
limit(25)
If you really think it's necessary to query and retrieve all 2000 sales employees at once, another option is to break those records up into the documents that contain only the data you'll need in the initial query, and then put any extra details into a separate collection or subcollection. Those other documents won't get transferred on that first fetch, but you can request them later as your user needs them.
Having smaller documents is also nice in that, if you have a realtime listener set up on a query and a document is updated, the changed document gets sent over to your device. So by keeping your documents smaller, you'll also have less data transferred every time a change happens in your listeners.
So Cloud Firestore's offline cache is pretty great. With persistence enabled, your application "just works", even if your user goes into a tunnel, or takes a 9-hour plane flight. Documents read while online will be available offline, and writes are queued up locally until the app is back online. Additionally, your client SDK can make use of this offline cache to avoid downloading too much data, and it can make actions like document writes feel faster. However Cloud Firestore was not designed as an "offline first" database, and as such, it's currently not optimized for handling large amounts of data locally.
So while Cloud Firestore in the cloud indexes every field in every document in every collection, it doesn’t (currently) build any of those indexes for your offline cache. This means that when you query documents in your offline cache, Cloud Firestore needs to unpack every document stored locally for the collection being queried and compare it against your query.
Or to put it another way, queries on the backend scale with the size of your result set, but locally, they kinda scale with the size of the data in the collection you're querying.
Now, how slow local querying ends up being in practice depends on your situation. I mean, we're still talking about local, non-network operations here, so this can (and often is) faster than making a network call. But if you have a lot of data in one single collection to sort through, or you're just running on a slow device, local operations on a large offline cache can be noticeably slower.
First, follow the best practices mentioned in the previous section: add limits to your queries so you're only retrieving the data that you think your users will need, and consider moving unneeded details into subcollections. Also, if you followed the "several subcollections vs a separate top level collection" discussion at the end of my earlier post, this would be a good argument for the "several subcollections" structure, because the cache only needs to search through the data in these smaller collections.
Second, don't stuff more data in the cache than you need. I've seen some cases where developers will do this intentionally by querying a massive number of documents when their application first starts up, then forcing all future database requests to go through the local cache, usually in a scheme to reduce database costs, or make future calls faster. But in practice, this tends to do more harm than good.
Third, consider reducing the size of your offline cache. The size of your cache is set to 100MB on mobile devices by default, but in some situations, this might be too much data for your device to handle, particularly if you end up having most of your data in one massive collection. You can change this size by modifying the cacheSizeBytes value in your Firebase settings, and that's something you might want to do for certain clients.
Fourth, try disabling persistence entirely and see what happens. I generally don't recommend this approach -- as I mentioned earlier, the offline cache is pretty great. But if a query seems slow and you don't know why, re-running your app with persistence turned off can give you a good idea if your cache is contributing to the problem.
So zig-zag merge joins, in addition to being my favorite algorithm name ever, are very convenient in that they allow you to coalesce results from different indexes together without having to rely on a composite index. They essentially do this by jumping back and forth between two (or more) indexes sorted by document ID and finding matches between them.
But one quirk about zig-zag merge joins is that you can run into performance issues where both sets of results are quite large, but the overlap between them is small. For example, imagine a query where you were looking for expensive restaurants that also offered counter service.
restaurants.where('price', '==', '$$$$').where('orderAtCounter', '==', 'true')
While both of these groups might be fairly large, there's probably very little overlap between them. Our merge join would have to do a lot of searching to give you the results you want.
So if you notice that most of your queries seem fast, but specific queries are slow when you're performing them against multiple fields at once, you might be running into this situation.
If you find that a query across multiple fields seems slow, you can make it performant by manually creating a composite index against the fields in these queries. The backend will then use this composite index in all future queries instead of relying on a zig zag merge join, meaning that once again this query will scale to the size of the result set.
While Cloud Firestore has more advanced querying capabilities, better reliability, and scales better than the Firebase Realtime Database, the Realtime Database generally has lower latency if you're in North America. It's usually not by much, and in something like a chat app, I doubt you would notice the difference. But if you have an app that's reliant upon very fast database responses (something like a real-time drawing app, or maybe a multiplayer game), you might notice that the Realtime Database feels… uhh… realtime-ier.
If your project is such that you need the lower latency that the Realtime Database provides (and you're anticipating that most of your customers are in North America), and you don't need some of the features that Cloud Firestore provides, feel free to use the Realtime Database for those parts of your project! Before you do, I would recommend reviewing this earlier blog post, or the official documentation, to make sure you understand the full set of tradeoffs between the two.
Remember that even in the most perfect situation, if your Cloud Firestore instance is hosted in Oklahoma, and your customer is in New Delhi, you're going to have at least 80 milliseconds of latency because of that whole "speed of light" thing. And, realistically, you're probably looking at something more along the lines of a 242 millisecond round trip time for any network call. So, no matter how fast Cloud Firestore is to respond, you still need time for that response to travel between Cloud Firestore and your device.
First, I'd recommend using realtime listeners instead of one-time fetches. This is because using realtime listeners within the client SDKs gives you a lot of really nice latency compensation features. For instance, Cloud Firestore will present your listener with cached data while it's waiting for the network call to return, giving you the ability to show results to your user faster. And database writes are applied to your local cache immediately, which means that you will see these changes reflected nearly instantly while your device is waiting for the server to confirm them.
Second, try to host your data where the majority of your customers are going to be. You have the option of selecting your Cloud Firestore location when you first initialize your database instance, so take a moment to consider what location makes the most sense for your app, not just from a cost perspective, but a performance perspective as well.
Third, consider implementing a reliable and cheap global communication network based on quantum entanglement, allowing you to circumvent the speed of light. Once you've done that, you probably can retire off of the licensing fees and forget about whatever app you were building in the first place.
So the next time you run into a Cloud Firestore query that seems slow, take a look through this list and see if you might be hitting one of these scenarios. While you're at it, don't forget that the best way to see how well your app is performing is to measure its performance out in the wild in real-life conditions, and Firebase Performance Monitoring is a great way of doing that. Consider adding Performance Monitoring to your app, and setting up a custom trace or two so you can see how your queries perform in the wild.
Hey, there Firebase developers. Did you hear the exciting news? Last month at Google I/O, we announced support for collection group queries in Cloud Firestore! Let's dig into this new feature a little more, and see if we answer some of your burning questions…
Q: So, what are collection group queries and why should I care?
In Cloud Firestore, your data is divided up into documents and collections. Documents often point to subcollections that contain other documents, like in this example, where each restaurant document contains a subcollection with all the reviews of that restaurant.
In the past, you could query for documents within a single collection. But querying for documents across multiple collections wasn't possible. So, for instance, I could search for all reviews for Tony's Tacos, sorted by score, because those are in a single subcollection.
But if I wanted to find reviews for all restaurants where I was the author, that wasn't possible before because that query would span multiple reviews collections.
reviews
But with collection group queries, you're now able to query for documents across a collection group; that is, several collections that all have the same name. So I can now search for all the reviews I've written, even if they're in different collections.
Q: Great! So how do I use them?
The most important step in using a collection group query is enabling the index that allows you to run a query in the first place. Continuing our example, if we want to find all reviews that a particular person has written, we would tell Cloud Firestore, "Go index every author field in every single reviews collection as if it were one giant collection."
author
You can do this manually by going to the Firebase Console, selecting the "Index" tab for Cloud Firestore, going to the "Single Field" section, clicking the "Add exemption" button, specifying you want to create an exemption for the "reviews" collection with the "author" field and a "collection group" scope, and then enabling ascending and/or descending indexes.
But that's a lot of steps, and I tend to be pretty lazy. So, instead, I like enabling collection group indexes the same way I enable composite indexes. First, I'll write the code for the collection group query I want to use and attempt to run it. For example, here's some sample code I might write to search for all reviews where I'm the author.
var myUserId = firebase.auth().currentUser.uid; var myReviews = firebase.firestore().collectionGroup('reviews') .where('author', '==', myUserId); myReviews.get().then(function (querySnapshot) { // Do something with these reviews! })
Notice that I'm specifying a collectionGroup() for my query instead of a collection or document.
collectionGroup()
When I run this code, the client SDK will give me an error message, because the collection group index hasn't been created yet. But along with this error message is a URL I can follow to fix it.
Following that URL will take me directly to the console, with my collection group index ready to be created.
Once that index has been created, I can go ahead and re-run my query, and it will find all reviews where I'm the author.
If I wanted to search by another field (like rating), I would need to create a separate index with the rating field path instead of the author field.
rating
Q: Any gotchas I need to watch out for?
Why, yes! There are three things you should watch out for.
First, remember that collection group queries search across all collections with the same name (e.g., `reviews`), no matter where they appear in my database. If, for instance, I decided to expand into the food delivery service and let users write reviews for my couriers, then suddenly my collection group query would return reviews both for restaurants and for couriers in the same query.
This is (probably) not what I want, so the best thing to do would be to make sure that collections have different names if they contain different objects. For example, I would probably want to rename my courier review collections something like courier_reviews.
courier_reviews.
If it's too late to do that, the second best thing would be to add something like an isCourier Boolean field to each document and then limit your queries based on that.
isCourier
Second, you need to set up special security rules to support queries. You might think in my example that if I had a security rule like this:
I would be able to run this collection group query. After all, all of my review documents would fall under this rule, right? So why does this fail?
Well if you've seen our video on Cloud Firestore security rules, you would know that when it comes to querying multiple documents, Cloud Firestore needs to prove that a query would be allowed by the security rules without actually examining the underlying data in your database.
And the issue with my collection group query is that there's no guarantee it will only return documents in the restaurants → reviews collection. Remember, I could just as easily have a couriers → reviews collection, or a restaurant → dishes → reviews collection. Cloud Firestore has no way of knowing unless it examines the results of the data set.
So the better way to do this is to declare that any path that ends with "reviews" can be readable based on whatever security rules I want to implement. Something like this:
Note that this solution requires using version 2 of the security rules, which changes the way recursive wildcards work.
Third, keep in mind that these collection group indexes are counted against the 200 index exemptions limit per database. So before you start creating collection group indexes willy-nilly, take a moment and ask yourself what queries you really want to run, and just create indexes for those. You can always add more later.
Q: Can I do collection group queries for multiple fields?
Yes. If you're doing equality searches across multiple fields, just make sure you have an index created for each field with a collection group scope.
If you're combining an equality clause with a greater-than-or-less-than clause, you'll need to create a composite index with a collection group scope. Again, I find it's best to just try to run the query in the code and follow the link to generate the index. For instance, trying to run a collection group query for all reviews that I wrote with a rating of 4 or higher gave me a URL that opened this dialog box.
Q: It still seems like I could do all of this in a top-level collection. How are collection group queries better?
So this question is based on the idea that one alternative to creating collection group queries is to not store data hierarchically at all, and just store documents in a separate top level collection.
For instance, I could simply keep my restaurants and my reviews as two different top-level collections, instead of storing them hierarchically.
With this setup, I can still search for all reviews belonging to a particular restaurant…
As well as all reviews belonging to a particular author…
And you'll notice that with the separate top level collection, I no longer need to use one of my 200 custom indexes to create this query.
So, why go with the subcollection setup? Are collection group queries needed at all? Well, one big advantage to putting documents into subcollections is that if I expect that I'll want to order restaurant reviews by rating, or publish date, or most upvotes, I can do that within a reviews subcollection without needing a composite index. In the larger top level collection, I'd need to create a separate composite index for each one of those, and I also have a limit of 200 composite indexes.
Also, from a security rules standpoint, it's fairly common to restrict child documents based on some data that exists in their parent, and that's significantly easier to do when you have data set up in subcollections.
So when should you store things in a separate top level collection vs. using subcollections? If you think you have a situation where you're mostly going to be querying documents based on a common "parent" and only occasionally want to perform queries across all collections, go with a subcollection setup and enable collection group queries when appropriate. On the other hand, if it seems like no matter how you divide up your documents, the majority of your queries are going to require a collection group query, maybe keep them as a top level collection.
But if that's too hard to figure out, I would say that you should pick the solution that makes sense to you intuitively when you first think about your data. That tends to be the correct answer most of the time.
Hope that helps you get more comfortable with collection group queries! As always, if you have questions, feel free to check out our documentation, or post questions on Stack Overflow.
This week, we’re returning to Google I/O for the 4th year in a row to share how we’re making Firebase better for all app developers, from the smallest one-person startup to the largest enterprise businesses. No matter how many times we take the stage, our mission remains the same: to help mobile and web developers succeed by making it easier to build, improve, and grow your apps. Since launching Firebase as Google’s mobile development platform at I/O 2016, we’ve been continuously amazed at what you’ve built with our tools. It is an honor to help you on your journey to change the world!
For example, in Uganda, a start-up called Teheca is using Firebase to reduce the mortality rate of infants and new mothers by connecting parents with nurses for post-natal care. Over in India where smartphones are quickly replacing TVs as the primary entertainment source, Hotstar, India’s largest video streaming app, is using Firebase with BigQuery to transform the viewing experience by making it more social and interactive. Here’s how they’re doing it, in their own words:
Stories like these inspire us to keep making Firebase better. In fact, we’ve released over 100 new features and improvements over the last 6 months! Read on to learn about our biggest announcements at Google I/O 2019.
New translation, object detection and tracking, and AutoML capabilities in ML Kit
Last year, we launched ML Kit, bringing Google's machine learning expertise to mobile developers in a powerful, yet easy-to-use package. It came with a set of ready-to-use on-device and cloud-based APIs with support for custom models, so you could apply the power of machine learning to your app, regardless of your familiarity with ML. Over the past few months, we’ve expanded on these by adding solutions for Natural Language Processing, such as Language Identification and Smart Reply APIs. Now, we’re launching three more capabilities in beta: On-device Translation API, Object Detection & Tracking API, and AutoML Vision Edge.
The On-device Translation API allows you to use the same offline models that support Google Translate to provide fast, dynamic translation of text in your app into 58 languages. The Object Detection & Tracking API lets your app locate and track, in real-time, the most prominent object in a live camera feed. With AutoML Vision Edge, you can easily create custom image classification models tailored to your needs. For example, you may want your app to be able to identify different types of food, or distinguish between species of animals. Whatever your need, just upload your training data to the Firebase console and you can use Google’s AutoML technology to build a custom TensorFlow Lite model for you to run locally on your user's device. And if you find that collecting training datasets is hard, you can use our open source app which makes the process simpler and more collaborative.
Customers like IKEA, Fishbrain, and Lose It! are already using ML Kit’s capabilities to enhance their app experiences. Here’s what they had to say:
"We’re working with Google Cloud to create a new mobile experience that enables customers, wherever they are, to take photos of home furnishing and household items and quickly find that product or similar in our online catalogue. The Cloud Vision Product Search API provided IKEA a fast and easy way to index our catalogue, while ML Kit’s Object Detection and Tracking API let us seamlessly implement the feature on a live viewfinder on our app. Google Cloud helps us make use of Vision Product Search and we are very excited to explore how this can help us create a better and more convenient experience for our customers.” - Susan Standiford, Chief Technology Officer of Ingka Group, a strategic partner in the IKEA franchise system and operating IKEA in 30 markets.
“Our users are passionate about fishing, so capturing and having access to images of catches and species information is central to their experience. Through AutoML Vision Edge, we’ve increased the number of catches logged with species information by 30%, and increased our species recognition model accuracy from 78% to 88%..”- Dimitris Lachanas, Android Engineering Manager at Fishbrain
“Through AutoML Vision Edge, we were able to create a highly predictive, on-device model from scratch. With this improvement to our state-of-the-art food recognition algorithm, Snap It, we’ve increased the number of food categories our customers can classify in images by 21% while reducing our error rate by 36%, which is huge for our customers.” - Will Lowe Ph.D., Director of Data Science & AI, Lose It!
Performance Monitoring now supports web apps
Native mobile developers have loved using Firebase Performance Monitoring to find out what parts of their app are running slower than they expect, and for which app users. Today, we’re excited to announce that Performance Monitoring is available for web apps too, in beta, so web developers can understand how real users are experiencing their app in the wild.
By pasting a few lines of code to their site, the Performance Monitoring dashboard will track and visualize high level web metrics (like page load and network stats) as well as more granular metrics (like time to first paint and first input delay) across user segments. The Performance Monitoring dashboard will also give you the ability to drill down into these different user segments by country, browser, and more. Now, you can get deep insight into the speed and performance of your web apps and fix issues fast to ensure your end users have a consistently great experience. By adding web support to one of our most popular tools, we’re reaffirming our commitment to make app development easier for both mobile and web developers.
Brand new audience builder in Google Analytics for Firebase
Google Analytics for Firebase provides free, unlimited, and robust analytics so you can measure the things that matter in your app and understand your users. A few weeks ago, we announced advanced filtering in Google Analytics for Firebase, which allows you to filter your Analytics event reports by any number of different user properties or audiences at the same time.
Today, we’re thrilled to share that we’ve completely rebuilt our audience system from scratch with a new interface. This new audience builder includes new features like sequences, scoping, time windows, membership duration, and more to enable you to create dynamic, precise, and fresh audiences for personalization (through Remote Config) or re-engagement (through Cloud Messaging and/or the new App campaigns).
For example, if you wanted to create a "Coupon users" audience based on people who redeem a coupon code within your app, and then complete an in-app purchase within 20 minutes, this is now possible with the new audience builder.
In addition to the three big announcements above, we’ve also made the following improvements to other parts of Firebase.
Support for collection group queries in Cloud Firestore
In January, we graduated Cloud Firestore - our fully-managed NoSQL database - out of beta into general availability with lower pricing tiers and new locations. Now, we’ve added support for Collection Group queries. This allows you to search for fields across all collections of the same name, no matter where they are in the database. For example, imagine you had a music app which stored its data like so:
This data structure makes it easy to query the songs by a given artist. But until today, it was impossible to query across artists — such as finding the longest songs regardless of who wrote them. With collection group queries, Cloud Firestore now can perform these searches across all song documents, even though they're in different collections. This means it’s easier to organize your data hierarchically, while still being able to search for the documents you want.
Cloud Functions emulator
We’ve also been steadily improving our tools and emulator suite to increase your productivity for local app development and testing. In particular, we’re releasing a brand new Cloud Functions emulator that can also communicate with the Cloud Firestore emulator. So if you want to build a function that triggers upon a Firestore document update and writes data back to the database you can code and test that entire flow locally on your laptop, for much faster development.
Configurable velocity alerts in Crashlytics
Firebase Crashlytics helps you track, prioritize, and solve stability issues that erode app quality, in real time. One of the most important alerts within Crashlytics is the velocity alert, which notifies you when an issue suddenly increases in severity and impacts a significant percentage of your users. However, we recognize that every app is unique and the one-size-fits-all alerting threshold might not be what’s best for you and your business. That’s why you can now customize velocity alerts and determine how often and when you want to be alerted about changes to your app’s stability. We’re also happy to announce that we’ve expanded Crashlytics to include Unity and NDK support.
Improvements to Test Lab
Firebase Test Lab makes it easy for you to test your app on real, physical devices, straight from your CLI or the Firebase console. Over the past few months, we’ve released a number of improvements to Test Lab. We’ve expanded the types of apps you can run tests on by adding support for Wear OS by Google and Android App Bundles. We’ve also added ML vision to Test Lab’s monkey action feature so we can more intelligently simulate where users will tap in your app or game. Lastly, we’ve made your tests more reliable with test partitioning, flaky test detection, and the robo action timeline, which tells you exactly what the crawler was doing while the test was running.
Greater control over Firebase project permissions
Security and data privacy remain part of our top priorities. We want to make sure you have control over who can access your Firebase projects, which is why we’ve leveraged Google Cloud Platform’s Identity & Access Management controls to give you finer grained permission controls. Right from the Firebase console, you can control who has access to which parts of your Firebase project. For example, you can grant access to a subset of tools so team members who run notification campaigns aren’t able to change your Firebase database’s security rules. You can go even further and use the GCP console to create custom roles permitting access to only the actions your team members are required to take.
More open-sourced SDKs
To make Firebase more usable and extensible, we’re continuing to open source our SDKs and accepting contributions from the community. We are committed to giving you transparency and flexibility with the code you integrate into your mobile and web apps. Most recently, we open sourced our C++ SDK.
In case you missed the news at Cloud Next 2019, here’s a quick recap of the updates we unveiled back in April:
In addition to making Firebase more powerful, we’ve also been hard at work bringing the best of Fabric into Firebase. We know many of you have been waiting for more information on this front, so we have outlined our journey in more detail here.
We’re continuing to invest in Firebase and as always, we welcome your feedback! With every improvement to Firebase, we aim to simplify your app development workflows and infrastructure needs, so you can stay focused on building amazing user experiences. To get a sneak peek at what’s next, join our Alpha program and help us shape the future
Hey there, Firebase developers!
Well, Cloud Next 2019 is upon us, and if you happen to be one of the several thousand people descending upon Moscone Center this year and want to get your fill of Firebase knowledge, you're in luck! There are a bunch of great sessions the Firebase team is putting on throughout the conference. And if you want to talk to any of us in person, swing on by the App Dev zone in the expo area. We'll be at the Firebase booth from now until Thursday the 11th.
But if you're not able to make it to beautiful downtown San Francisco this year, never fear! You can still find out everything that's new with Firebase in this blog post, so read on!
For those of you who are Google Cloud Platform customers, we are pleased to announce that the GCP support plan now includes support for Firebase products. This means that if you are using any of the paid GCP support packages, you can get the same high-quality support that you've come to expect from GCP for Firebase products as well. This includes target response times as quick as 15 minutes, technical account management (for enterprise customers), phone support, and much more.
Now if you're not a paying GCP customer, don't worry -- free community support isn't going anywhere. But for many of our larger customers who were interested in a more robust paid support experience, this new option is welcome news. To find out more, you can check out the support pages on the GCP site as well as the Firebase Support Guide.
One of the new GCP products that we announced at this year's Cloud Next is Cloud Run, a fully managed compute platform that lets you run stateless containers which you can invoke via HTTP requests. And we're happy to announce that you can use Cloud Run in conjunction with Firebase Hosting.
Why do you care? Because Firebase Hosting isn't just good for hosting static sites. You can run microservices on top of Hosting as well. In the past, you did this by connecting your Hosting site with Cloud Functions for Firebase, which meant that you had to write all of your code in Node.js. But now that you can deploy stateless servers through Cloud Run and have Hosting talk to them, you can build your microservices in anything from Python to Ruby to Swift.
This is a pretty deep topic which deserves its own blog post, so keep an eye out for that in the next couple of days. Or check out the documentation if you want to get started today.
In the past, you could filter your event reports in Google Analytics for Firebase by a single user property (or audience). So you could quickly answer questions like how many iOS 12 users were signing up for your newsletter. But up until now, you couldn't filter by more than one different user property at once. So if you wanted to find out how many iOS 12 users on iPad Pros were signing up for your newsletter, that wasn't really possible.
Well, we're happy to announce that you'll be able to filter your Analytics event reports by any number of different user properties or audiences -- both ones defined by Firebase as well as custom user properties -- at the same time. So if you want to find out how many iOS 12 users with iPad Pros who prefer dogs over cats signed up for your newsletter, that's now something you can see directly within the Firebase console.
This change is currently rolled out to a small number of users, and will be available to everybody over the next few weeks. This will apply automatically to all of your data going back to December of 2018 when it becomes available, so hop on over to the Firebase console and give it a try!
About 9 months ago ago, we gave developers the ability to create nicer looking domains for their Dynamic Links. So instead of having Dynamic Links with domains that looked like a8bc7w.app.goo.gl, you could set them to something much nicer, like example.page.link.
a8bc7w.app.goo.gl
example.page.link
We improved upon this feature to give you the ability to create dynamic links with any custom domain you own. So if you want to create a link with a domain like www.example.com, this is now something you can do with Dynamic Links.
www.example.com
The one caveat here is that your site needs to be hosted using Firebase Hosting. If migrating your primary domain over to Firebase Hosting isn't feasible, you can easily setup a subdomain of your site instead. For instance, maybe you can't move all of www.example.com to Firebase Hosting, but you could pretty easily set up links.example.com on Firebase Hosting, and use that for your Dynamic Links moving forward.
links.example.com
To find out more about custom domains in Dynamic Links and to get started, make sure to check out the documentation.
Of course, we're always rolling out new features and improvements to the Firebase platform, and with I/O happening just next month, maybe we'll have something more to talk about in May 😉. There's only one way to find out: Attend I/O in person, or keep reading the Firebase blog! (Okay, that's two ways. Counting was never a strong suit of mine.)