Getting data into Splunk Enterprise
To begin onboarding and working with data in Splunk Enterprise review the following steps:
- Decide on the objective you want to achieve using Splunk Enterprise.
- Identify the data you need in Splunk Enterprise to help you complete that objective.
- Use Splunk Lantern’s Use Case Explorers for Security, Observability and Platform to discover new applications for your data.
If you have any questions regarding data onboarding, check out the Getting Data In section in our community or contact your account team.
Learning the basics
Use these scripted learning paths to master the basics. These use a sample dataset, so you can get learning quickly.
Understanding getting data in processes
Review the following resources before onboarding your data.
- 4 main ways to Get Data In. Watch this Tech Talk to learn about getting data in from any Linux or Windows host, how to create lossless syslog ingress or TCP data ingress over any port from any custom application or use case, and using APIs to send or receive data.
- What data can I index? The Splunk platform can index any and all IT, streaming, machine, and historical data. To set this up, you would point the Splunk platform at a data source, fill out information about that source, and then that source becomes a data input. The Splunk platform indexes the data stream and transforms it into a series of events that you can view and search right away - no structuring necessary.
- Get started with Getting Data In. Use this documentation to guide your data onboarding process.
Onboarding your data
To help guide your data onboarding, check out Splunk's five-step process to build best-practice data onboarding workflows. These guidelines can help you streamline data requests, define the use case, validate data, and properly communicate the availability of new data.
Getting data in using forwarders
Universal forwarders are the most common way to get data in, by streaming data from your machine to a data receiver. They provide reliable, secure data collection from remote sources and forward that data into Splunk software for indexing and consolidation. Universal forwarders can scale to tens of thousands of remote systems, collecting terabytes of data.
How to deploy the Universal Forwarder:
- Download Splunk Universal Forwarder.
- Install a universal forwarder for Windows or Linux.
- Enable a receiver to send data to Splunk Enterprise.
- Start the universal forwarder.
Getting data in - Windows
Watch the video below to learn how to get Windows data into Splunk Enterprise. To get started, you can either install a Windows universal forwarder using an installer or the command line. The installer is recommended for larger deployments, and the command line is recommended for smaller deployments.
Getting data in - Linux
Watch the video below to learn how to get Linux data into Splunk Enterprise. To get started, install a *nix universal forwarder software on a *nix host, such as Linux, Solaris, or Mac OS X. The documentation link assumes that you plan to install directly onto the host, rather than use a deployment tool. This type of deployment is best suited for small deployments, proof-of-concept test deployments and system image or virtual machine for eventual cloning.
Ingest Actions
Ingest Actions is a user interface that enables customers to quickly and easily configure data flows and control the volume, format and destination of data. It is accessible from the Splunk Enterprise and Splunk Cloud Platform Search and Reporting UI as an option in the administrative drop down.
Use Ingest Actions to filter, mask, and route data at ingest and at the edge, using only simple clicks - no writing command lines or hand-writing stanzas in configuration files. This feature allows you to cut through the noise, detangling the data that's mission critical from that which needs to be archived.
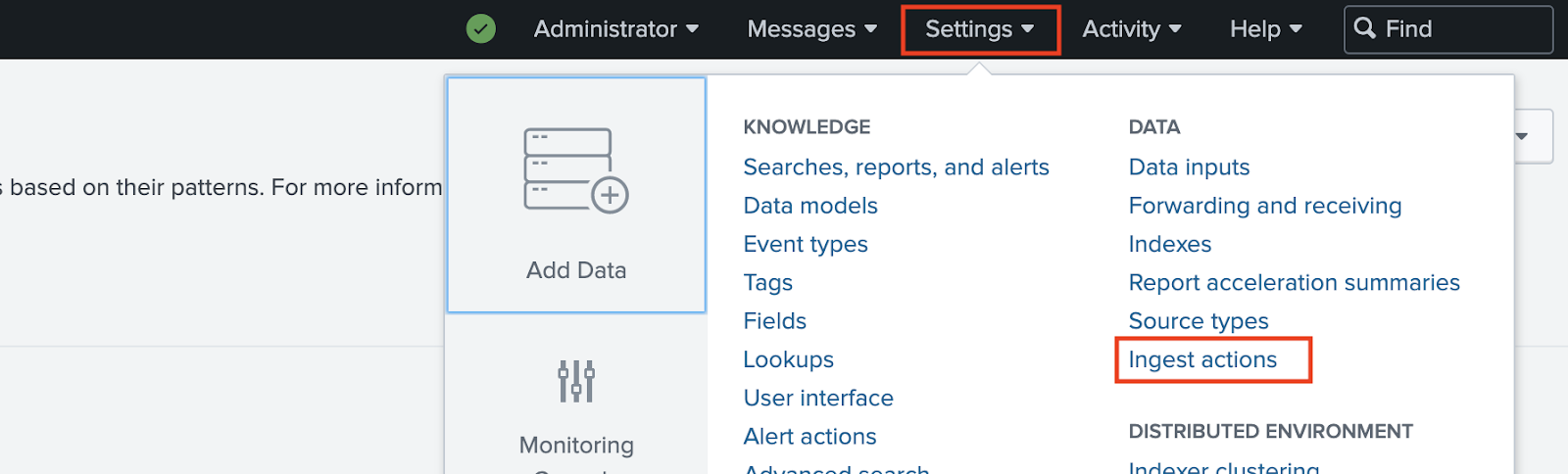
The Ingest Actions page can be found in Splunk Web under Settings > Data > Ingest actions. This feature allows you to dynamically preview and build rulesets using sample data. You simply click to add a new rule, specify what needs to be redacted, and the expression you want to mask it with.
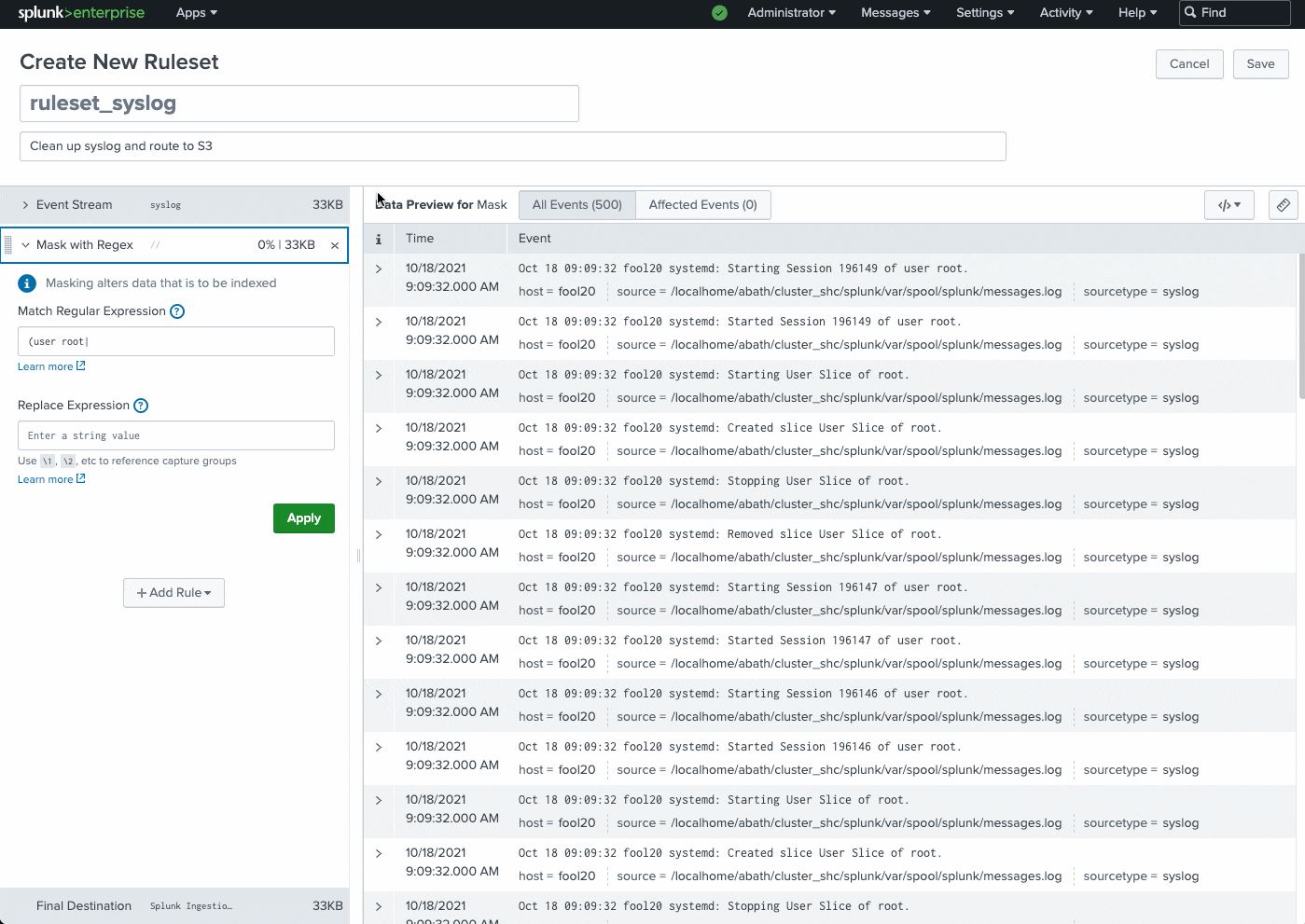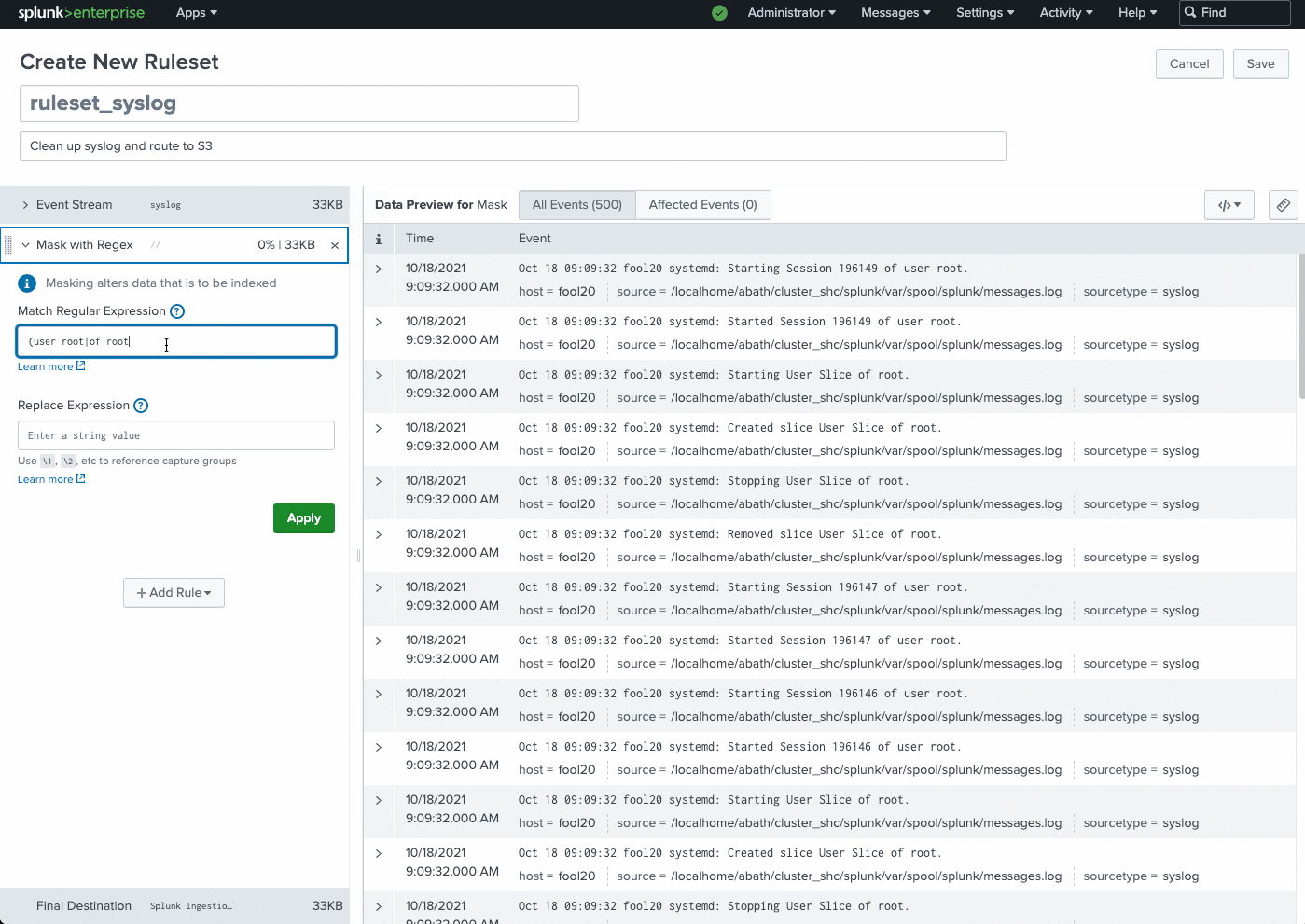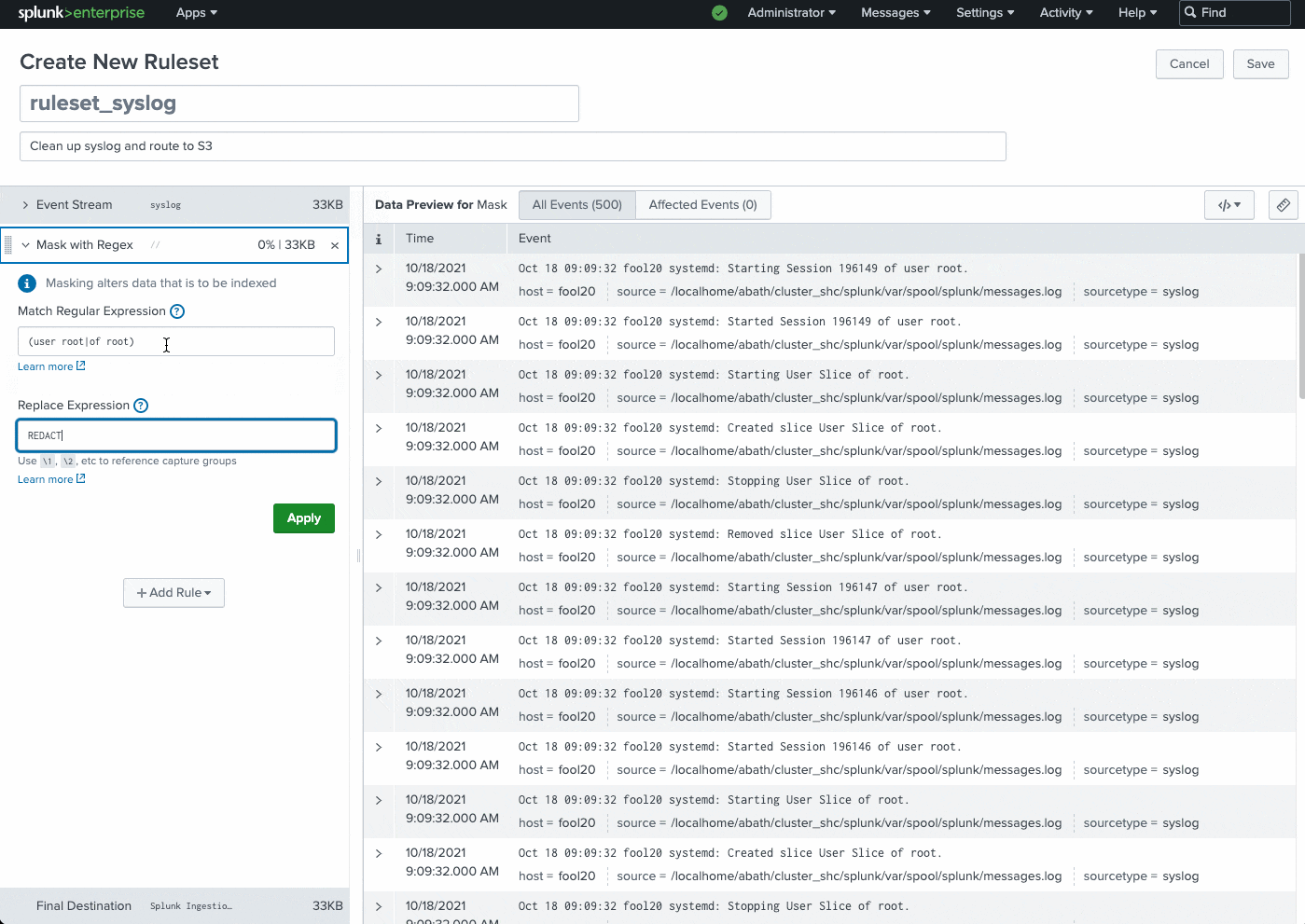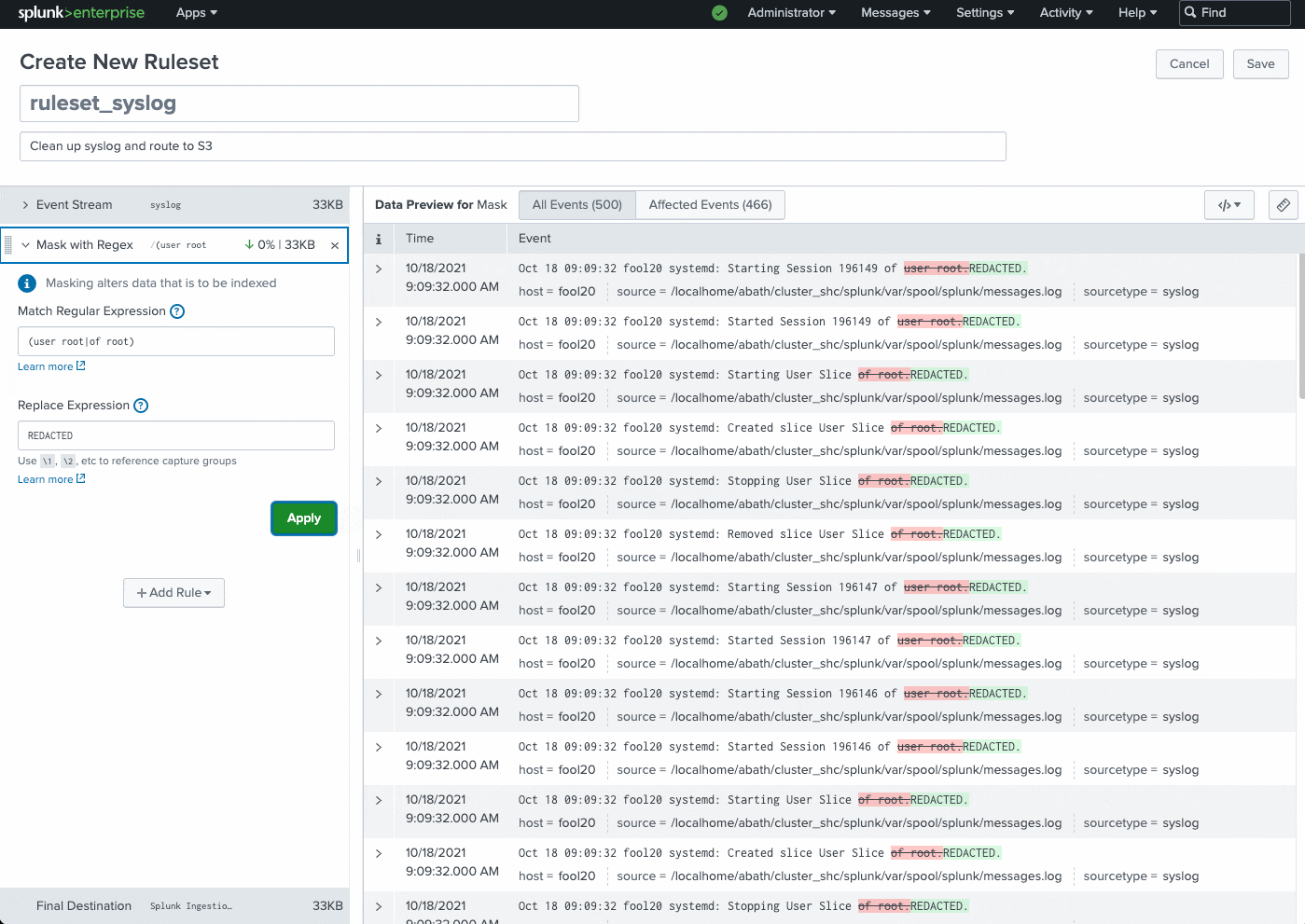
Common use cases: instantly route data to external S3-compliant destinations for archival or audit purposes, remove sensitive information (PII data, user names, etc.), remove IP addresses, filter DEBUG logs, and much more.
Additional resources
- Tech Talk: Getting data into Splunk
- .conf23 talk: Avoiding the dreaded “We’ve onboarded all our data, now what?”
- .conf23 talk: GDI with Data Management Experience (DMX) - ingesting, processing, filtering, masking, routing and managing your data
- .Conf talk: Starting your Splunk journey - Get your data in | Slide deck
- Docs: How to forward data to Splunk Enterprise