Posted by Mateusz Jurczyk, Project Zero
This post is the third of a multi-part series capturing my journey from discovering a vulnerable little-known Samsung image codec, to completing a remote zero-click MMS attack that worked on the latest Samsung flagship devices. New posts will be published as they are completed and will be linked here when complete.
- [this post]
Introduction
In Part 2, I discussed how I managed to fuzz-test the Qmage codec on Google infrastructure at the turn of 2019/2020. It led to the discovery of a huge number of unique crashes, many of which manifested obvious memory corruption problems. After reporting them to Samsung on 28 January 2020, my attention turned to the idea of using some of the vulnerabilities to write an MMS exploit. There was evidence that the Samsung Messages app processed incoming bitmaps without any user interaction, so this seemed like the perfect opportunity to see just how realistic such an attack could be with a wide range of image parsing bugs to choose from. The prospect of developing a zero-click exploit running over the mobile network was new and thrilling to me, and it got me very excited to take the challenge.
The first step in the process was to identify the crashes that were not just high severity on paper, but were also the most convenient for exploitation in a real-life scenario. An ideal bug would be easy to work with (i.e. require a relatively simple structure of the Qmage file), and would provide full control over the memory corruption condition. In case of a heap buffer overflow, this would imply control over the allocation size, overflow size, overflow data, and possibly even the overflow offset (in a non-linear case). Such a bug would lay a strong foundation for any higher-order mechanisms that would have to be implemented in the exploit.
This blog post describes the additional crash triage I performed to find the most suitable bug for exploitation, followed by an analysis of how it was used to turn plain memory corruption into more useful primitives: control over the instruction pointer (PC), and the ability to "probe" the existence of memory ranges. In practice, I was simultaneously experimenting with the MMS protocol to get an initial feel of its design, capabilities and limitations. However, for the sake of clarity, I will limit the scope of this write-up to the low level exploitation details, and proceed to link the memory corruption with the MMS delivery channel in future posts. Let's get started!
Heap fundamentals in Android
The first observation to make is that a great majority of the identified crashes were heap-oriented. There were some instances of stack buffer overflows, but the stack cookie mitigation rendered them non-exploitable. There were also other cases such as reads from uninitialized stack-based pointers, but they didn't seem particularly useful, so in the end, I decided to focus on the 174 "write" crashes, all of which referenced out-of-bounds heap addresses. In principle, such bugs tend to provide the most flexibility in exploitation, as they can be used to corrupt a variety of objects in memory. So, if we are going to work with the Android heap, we should get familiar with the underlying allocator and its security properties.
The allocator currently used in all modern versions of Android is jemalloc (side note: this is going to change with the introduction of Scudo in Android 11). There were two main resources that I found especially useful when learning and experimenting with jemalloc:
I won't go into much detail regarding the internals of the allocator (you can find them in the above sources), but I would like to highlight the following properties that are most relevant to this research:
- Determinism: jemalloc behaves deterministically, at least to the extent observable by the attacker. For example, with a clean state of the heap, two subsequent allocations of the same size are positioned next to each other.
- Lack of inline metadata: metadata is stored separately from the allocation itself, so an overflow of one chunk (or "region", as it's called in jemalloc) immediately overwrites the data of the adjacent one, with no metadata in between.
- Division into size classes: allocations are grouped by size, so any two allocations can only be adjacent to each other if they fall into the same size "bin".
- Thread caches: a mechanism called "tcaches" improves locality by quickly reusing recently freed regions. This guarantees the predictability of some allocation patterns – for example, a malloc → free → malloc sequence of the same length will return the same address twice.
These characteristics can be favorable or disadvantageous depending on the specific bug and context around it. Overall, in this case, I think these properties added up to a "net positive" from the attacker's perspective, which is not great for user security. For this reason, I am really looking forward to seeing the hardened Scudo allocator enabled by default in Android 11.
Now that we have some background on the behavior we can expect from jemalloc, it's time to analyze the write-violation crashes in search of the most promising ones.
Finding the right bug
With all that we know about jemalloc, we can make a working assumption that if there are two malloc calls, and they can be made to be of a similar size, the second one can be corrupted by the first one with a forward overflow, because it is (usually) placed at a higher address. So in order to assess the usability of a crash, we need to determine:
- What region is overwritten by the bug?
- What are the other allocations that are requested between the overwritten allocation and the overflow, and are used after the overflow?
The SkCodecFuzzer test harness has an -l flag that enables the logging of all mallocs and frees to stderr at runtime. It can be used to match the address of the invalid memory access with the corresponding allocation, and see what other allocations are made in between. For example, if we take the signal_sigsegv_40064924d0_4336_c77562cdc52d1baed45ff05bc9ae2023.qmg sample and run it through the loader with the -l flag, we should see the following output (malloc stack traces were edited out for brevity):
Here, the invalid 0x408c125000 address is the same as the end of the third allocation requested after printing out the image characteristics. Its size of 28416 bytes coincides with 148 (width) × 192 (height), so we can presume that it is a pixel storage buffer and therefore has controlled length. There are two more allocations (highlighted in red) made after the overflown buffer and kept alive until the crash, so each of them could be the target of the memory corruption. In the call stack, we can also see that the problem occurs during RLE decoding, which is a well-known algorithm and thus would probably meet our criteria of being easy to work with. This is how a specific crash can be evaluated for exploitability.
Since I wished to explore the whole range of options and manually performing the same analysis on the other 173 unique "write" crashes seemed tedious, I wrote a quick bash script to generate and process the crash logs to match the invalid accessed addresses with corresponding heap regions. After sorting and deduplicating, they added up to a total of 23 unique overwritten allocation sites. I was not particularly interested in QMv1 crashes (the old format wasn't correctly handled by the Messages application), so I filtered them out from the results, leaving me with 17 allocations subject to overflow. That was a much more manageable number of cases to go through by hand.
After a brief analysis, I concluded that many of them were not optimal for my exploit, because they were temporary buffers, allocated and immediately overflown without any mallocs taking place in between. Taking advantage of such a bug would require an earlier allocation to be mapped above the buffer – a heap state that is possible, but harder to reliably achieve with the limited heap manipulation capabilities of the image codec. The remaining allocation sites that had some potential could be divided into four major groups:
After some consideration, I decided that option 1 (bitmap pixel buffer) was the most promising one, because:
- It was the earliest overflown malloc, making it possible to corrupt the widest range of subsequently allocated objects, including the Bitmap object.
- The size was controlled, and in the case of RLE and zlib decompression, the overflow length and data were controlled too. On top of it, I was familiar with both algorithms and thus didn't anticipate any problems constructing the exploit files.
To be specific, I started my experimentation with the e418c0496cb1babf0eba13026f4d1504 crash and the signal_sigsegv_4005d89b74_8686_6eea0420198397cc5c97563bceb04424.qmg sample. It generated the following report (malloc stack traces again edited out):
Here, we are overflowing the 1120-byte buffer (width × height × bpp; 40 × 7 × 4 = 1120), and can corrupt the three subsequent ones marked in red. The first (104 bytes) is the Bitmap structure, the second (24 bytes) is the RLE-compressed input stream, and the third (4120 bytes) is the RLE decoder context structure. The Bitmap object sounds the most useful, and since I have already mentioned it so many times, let's finally look into it to see how it works! We'll be operating on the assumption that if we adjust the Qmage dimensions such that the pixel buffer consumes 104 bytes (e.g. 13x2), then the two allocations will likely be adjacent on Android, giving us full (linear) control over the second region.
Enter the Android Bitmap object
First of all, it is important to note that the Bitmap object created by our test harness is not exactly the same as the one used in Android, because of a difference in the allocator objects used (SkBitmap::HeapAllocator vs GraphicsJNI's HeapAllocator). This is irrelevant for fuzzing, but makes a big difference in exploit development. In order to learn about the actual object being allocated on Android, we can use a simple Frida script that hooks the heap-related functions and logs all of their invocations with stack trace. If we attach it to the com.samsung.android.messaging process and send an MMS with the proof-of-concept image, we should see output similar to the following (I demangled some symbols and edited out argument definitions for brevity):
Here, we can again see the familiar highlighted allocations before the overflow occurs. The only difference is the size of the Bitmap object: it's 104 in our loader but 160 on Android. Unfortunately Frida didn't correctly unwind the stack for the malloc call, but based on the pixel buffer stack trace, we can figure out that it takes place in android::Bitmap::allocateHeapBitmap:
As expected, there is a calloc call for allocating pixel storage, followed by the creation of the Bitmap object itself. This is how the function prologue looks in Hex-Rays:

If we quickly change the Qmage file dimensions to 10x4, such that the pixel buffer becomes 160 (or any length between 129 and 160, which is the relevant jemalloc bin size), then we can use Frida to verify that the two Bitmap-related allocations are indeed adjacent:
The difference between 0x7b88feb8c0 and 0x7b88feb960 is 160 (0xA0), exactly the size of the first chunk, which means that we should be able to precisely overwrite the succeeding android::Bitmap object. This behavior is not 100% reliable and is hugely dependent on the preexisting heap state of the attacked app, but I found that it was reliable enough to enable successful, practical attacks. I will expand more on this in the next blog post in the series.
It's finally time to look at the android::Bitmap layout in memory. Currently, the class is defined in frameworks/base/libs/hwui/hwui/Bitmap.h in the Android source tree. Some of its private fields are visible there, but their volume surely doesn't sum up to 160 bytes. This is because the code makes heavy use of C++ inheritance, so android::Bitmap inherits from SkPixelRef → SkRefCnt → SkRefCntBase. After untangling the above chain of classes and figuring out the alignment requirements for each field, I arrived at the following layout:
We can immediately spot a number of interesting fields such as the vtable, pointer to backing pixel storage, bitmap dimensions, a raw function pointer (freeFunc), and pointers to other C++ objects such as SkColorSpace, GraphicBuffer and SkImage. The class clearly has the potential to supply many useful exploitation primitives. Let's go ahead and test some initial ideas to see how the code behaves in contact with a corrupted Bitmap object.
Building code execution primitives
In order to start experimenting with the heap corruption, we have to construct a test case that will be easy to adjust for different tests. For building editable binary files for testing file format parsers, I usually use nasm. It allows me to write code-like .asm sources file that specify the values of respective header fields with the db/dw/dd/… pseudo-instructions, may include comments, and can be quickly "compiled" to raw binary form. This is what I also used here, to craft the proof-of-concept Qmage file from scratch, based on the signal_sigsegv_4005d89b74_8686_6eea0420198397cc5c97563bceb04424.qmg sample and reverse engineering the codec in libhwui.so. This is where the debug symbols from old builds of libQmageDecoder.so I dug up earlier in the recon phase (as discussed in Part 1) proved very useful.
The nasm source code of the Qmage file I used for experimentation can be found here. It consists of the following logical parts:
- File header specifying a QG1.2 format version (equivalent to 2.0, as explained in Part 2) and 4x10 bitmap dimensions.
- A zlib-compressed color table with all 0x41's.
- A required \xFF\x00 marker, followed by the 0x06 RLE compression type.
- A RLE-compressed stream of 161-320 bytes: the first 160 to fill out the pixel buffer, followed by 1-160 bytes depending on what portion of the android::Bitmap object we intend to overwrite.
- A trailing \xFF\x00 marker.
Notably, the RLE compression used in Qmage is not the simple one we know from BMP files. Based on the structure of the code and some RLE-related symbols (init_process_run, process_run, init_process_run_dec, process_run_dec), we can deduce that it is probably a MELCODE scheme. For our purposes, though, it's not much more complicated. If we intend to take a data blob and wrap it with the RLE structure while actually not reducing its size (similar to how zlib compression level 0 works), it's a matter of adding a simple prefix and suffix. For example, a compressed 8-byte string "ABCDEFGH" takes the following form:
The little-endian 0x0000000E value indicates the length of the overall compressed stream, 0x00000008 specifies the number of runs – in this case, length of the decompressed data, then there is the raw data and finally N÷4 bytes 0xAA, each of which signifies four runs, one-byte each. With that out of the way, we can proceed to testing potential code execution primitives.
The first idea is to overwrite the vtable pointer and see if/where the code crashes. Since it's the first field in memory, we only have to write 8 bytes past the end of the pixel buffer. If we set them to AAAAAAAA and send such a file via MMS, we should see the following crash:
There is an access to the controlled 0x4141414141414141 address in Bitmap_destruct. The code accessing the pointer is as follows:
As expected, we get an arbitrary vtable call. It is a great first primitive to confirm, and it is direct evidence that everything seems to be working according to plan. Of course at this point, we don't know where any code is located (to redirect execution there), or even where our controlled data is situated (to set up our fake vtable). However, let's focus on one thing at a time. What's important is that the vtable call is controlled by the value of the consecutive fRefCnt field, so we may choose to trigger it or not by setting the reference counter to a small or large integer.
The second eye-catching field that can be likely abused to hijack code execution is the freeFunc function pointer in the mPixelStorage union:
We can check where the pointer is used by running a quick cs.android.com search. As it turns out, it is called in the Bitmap::~Bitmap destructor:
If we look at the broader context of the code, the destructor may provide the attacker with an assortment of primitives, depending on the value of the mPixelStorageType enum: arbitrary munmap+close, arbitrary free, and another arbitrary vtable call (through the mPixelStorage.hardware.buffer pointer). However, I find the freeFunc pointer the most useful, especially in a potential one-shot scenario where we try to take over control of the app with a single, specially crafted MMS message. Conveniently, the function also takes two arguments, which we may control – or in fact, must control, because reaching the freeFunc field with a linear overflow is only possible after overwriting both address and context.
The only problem with this technique is that the Bitmap destructor itself is called through the vtable at offset 0, the one that we have to corrupt in order to get to the deeper fields in the class. Therefore, we can only use it in our exploit if we leave the vtable pointer intact after the overflow. This, in turn, requires the knowledge of the libhwui.so base address. At this point in the story, we don't know how we could leak such information yet, but exploitation gadgets like this are worth writing down even if we don't have all the pieces of the puzzle to make use of them yet.
To make sure that we're reading the code right, we should confirm the behavior in practice. We can construct a Qmage sample that overwrites the full 160 bytes of the Bitmap object with a marker 0x41 byte, and then fine-tune a few specific fields for the experiment:
- vtable set to its original value, in my case 0x7cbbdfc4e0 (0x7cbb632000 base address + 0x7ca4e0 offset)
- fRefCnt set to 1
- mPixelStorageType set to 0 (External)
- mPixelStorage.external.address set to 0xaaaa...aaa.
- mPixelStorage.external.context set to 0xbbbb...bbb.
- mPixelStorage.external.freeFunc set to 0xcccc...ccc.
If we send it via MMS, we should see the following crash in logcat:
As the crash report shows, we control the instruction pointer (PC) and two 64-bit arguments (registers X0 and X1).
In summary, we have two powerful primitives for hijacking the control flow at our disposal – an indirect one through a corrupted vtable pointer, and a direct one through the freeFunc function pointer (with knowledge of the libhwui.so location). This brings us much closer to the ultimate goal of executing arbitrary code. The biggest unsolved problem is now ASLR – since the locations of all important memory regions (stack, heap, shared objects) are randomized, we are completely in the dark as to where we could redirect any kind of pointer. It is time to see if the android::Bitmap object has anything to offer in terms of leaking address space information or otherwise defeating ASLR.
Building an ASLR oracle primitive
In most publicly documented exploitation scenarios, ASLR is bypassed in a highly interactive environment, where the communication between the exploit and the attacked software goes both ways. Examples include JavaScript exploits vs. web browser engines, user-mode exploits vs. OS kernels, and remote exploits vs. network daemons. In all these cases, the leaked address of some object in memory is typically received by the exploit in full, and the "ASLR bypass" problem boils down to enticing the target to transmit the address to the client as part of a standard data exchange.
The circumstances are largely different for exploits delivered via MMS. Here, all communications are realized through one or more mobile network operators, and it is (mostly) a one way protocol. As a result, a remote attacker gets very little visibility into what happens on the victim's phone, let alone being able to disclose some complex information such as a 64-bit address in one go. Notably, the same problem was already encountered by Samuel Groß when exploiting an iPhone iMessage CVE-2019-8641 vulnerability in 2019. In his research, Samuel managed to work around it by making use of message delivery receipts. Depending on how they are implemented, they may be abused to construct a rudimentary 1-bit communication channel going back to the attacker, potentially carrying some kind of address-related information. In case of iMessage, it conveyed the output of an ASLR oracle, indicating if a given absolute address was mapped in memory and had some specific properties. I highly recommend reading the relevant "Remote iPhone Exploitation Part 2: Bringing Light into the Darkness – a Remote ASLR Bypass" post on the Project Zero blog.
The mechanics of the MMS protocol will be discussed in detail in the next post, but for the sake of the storyline I will reveal that MMS also supports delivery receipts. What's more, some SMS/MMS apps such as Samsung Messages do allow the disclosure of information on whether or not the process crashed while processing the incoming message. In turn, this opens up the opportunity to leak partial information about the address space, if we can tie the crash/no crash outcome to the process memory layout. That's where the corrupted Bitmap object comes into play again.
The most basic idea for how to achieve that is by overwriting a pointer with an absolute address whose readability (or writability) we intend to test. In theory, if the address is unmapped, the access will crash, and if it is mapped, the read or write will succeed and the app will stay alive. In practice, things are not so simple, because the process may also crash while operating on the data read from the tested address. So for example, the vtable pointer is not a great candidate for an ASLR oracle, because keeping the process alive would not only require it to point to a readable region, but it would also need to contain the address of a function semi-compatible with the original destructor. Such an oracle would realistically hardly ever return true, which makes it of little use to us.
Luckily, the Bitmap object also contains a few other pointers we can try to target. To start off, we can overwrite its whole area with all 0x41's and see how the process crashes, to determine which pointers are accessed, where, and how. The experiment should yield the following result:
The stack trace indicates that the crash occurs while accessing the color space, which is represented by the mInfo.fColorSpace pointer. It might be promising for an oracle, but let's see what happens if it's set to an address of readable memory containing only zeros:
Unfortunately, the app crashes again, this time due to a failed color space sanity check performed by the TransferParameters method. This means that that pointer is not the perfect gadget for us either, because zeros in memory are exceedingly common, and it would be preferable to distinguish unmapped memory from mapped zero'ed memory in the ASLR oracle output.
The advantage of the last crash report is that it gives us a very clean Java call stack, indicating exactly where the bitmap-related operations occur. It is shown below in full, up until the Messages app method that loads the bitmap delivered in MMS:
We can see that Samsung has a helper ImageUtil class for working with bitmaps, and that unfortunately some symbols in the app are obfuscated (i.e. the ui.model.l.at.a method name). Since the Messages app is not open source, we have to decompile it in order to examine the relevant code. The APK can be found in the /system/priv-app/SamsungMessages_11/SamsungMessages_11.apk file, and my decompiler of choice is jadx.
Lifetime of a Bitmap
When we dig into the Java code, it becomes evident that the lifetime of the Bitmap object is somewhat complex, and it may be subjected to a few transformations. Let's take it step by step:
- The initial Bitmap is created through BitmapFactory.decodeStream call ImageUtil.loadBitmapFromStream:

- The bitmap is then subjected to scaling:

- The scaling is in fact optional, and only happens if the bitmap dimensions are greater than the intended ones:

- Lastly, in the com.samsung.android.messaging.ui.model.l.at.a method, if the bitmap configuration is not ARGB_8888, it is converted to such encoding:

In a nutshell, step 1 is where the bitmap is allocated, decoded, and overflown, and steps 2 and 3 are where the corrupted object is used, and where we should look for the desired ASLR oracle primitive.
I spent quite some time looking at the image-related Skia code and experimenting with various values of the Bitmap fields. Eventually, I discovered a perfect technique for probing arbitrary addresses to check if they are readable. The primitive is located in step 3 (bitmap conversion to ARGB_8888), so the first order of business is to disable the scaling in step 2. Assuming that we're starting off with a blob of 160 bytes 0x41 again, we should adjust:
- fWidth (offset 0x0c) → 0x1
- fHeight (offset 0x10) → 0x1
While we're at it, it will make our life easier later if we make the second set of dimensions sane too:
- mInfo.fWidth (offset 0x60) → 0x1
- mInfo.fHeight (offset 0x64) → 0x1
Then, we need to make sure that we pass the rowBytes checks (1, 2) in SkBitmap::setInfo by setting it to a sensible value:
- fRowBytes (offset 0x20) → 0x1000
If mInfo.fColorSpace is non-NULL, it will be dereferenced, so we have to zero it out:
- mInfo.fColorSpace (offset 0x58) → 0x0
This gets us past the copying/sanity checking of the basic properties of the bitmap, and into the pixel copying logic under android.graphics.Bitmap.copy → Bitmap_copy → bitmapCopyTo → SkPixmap::readPixels → SkConvertPixels → swizzle_or_premul. To be able to use the swizzle_or_premul conversion routine, the color type needs to be either RGBA_8888 (4) or BGRA_8888 (6), and since it cannot be the former due to the Bitmap.Config check in Java code, there is only one option left:
- mInfo.fColorType (offset 0x68) → 0x6
Finally, we arrive at the following loop:
That's where the BGRA to RGBA conversion takes place. In the above snippet, the values of most variables originate from the overwritten android::Bitmap object:
- dstInfo.height() == mInfo.height
- dstInfo.width() == mInfo.width
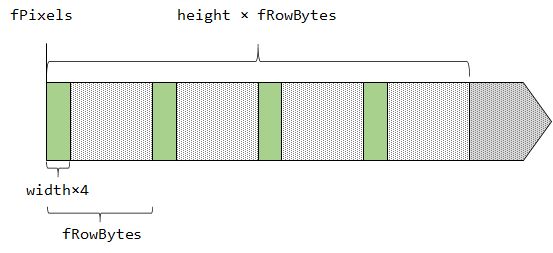
- srcPixels == fPixels
- srcRB == fRowBytes
So in other words, for each row of the bitmap, the code copies width×4 bytes from a controlled pointer, and moves the pointer by fRowBytes. This is also illustrated below:
This conversion logic gives us enormous flexibility in terms of the addresses we can trigger accesses to, and importantly, the data being read is just pixel colors, which are completely neutral to the control flow of the code. In the most basic scenario, we can leave the current state of the corrupted fields and make just two more changes:
- fPixels (offset 0x18) → start of the probed address range
- mInfo.fHeight (offset 0x64) → number of pages to probe
This will cause Skia to read four bytes in 0x1000 byte intervals, in mInfo.fHeight iterations, starting from the fPixels address. It is equivalent to probing the readability of an arbitrary continuous memory area – if all pages are mapped and readable, the loop will complete successfully and the app will stay alive; otherwise, it will crash while trying to access the first non-readable page in the tested range.
As always, we should confirm the behavior on a real device. We can start off with setting fPixels to an invalid address such as 0xccc...ccc, and sending the sample via MMS:
A sigsegv is indeed generated upon a read from the bad address in the color conversion function. Let's try something more complex. On my test device, the last mapping in the address space of the com.samsung.android.messaging process is a stack:
To verify that our oracle primitive touches each page in the given area, we can set fPixels to 0x7fdfb10000 (eight pages before the end of the stack), and mInfo.fHeight to 10. As a result, we should see the following crash:
The fault address lies directly after the stack mapping, which indicates that the loop successfully executed eight iterations, and failed during the ninth, when it went out of bounds. This completes our quest for a suitable ASLR oracle primitive, as it ultimately shows that we can now remotely trigger memory reads of a highly-controllable set of addresses in the context of the attacked Messages app.
Summary
To recap, we have analyzed the available memory corruption bugs based on pseudo-ASAN crash reports, and decided to work with a linear heap overflow present in RLE decompression. The overflown buffer is a pixel storage allocation associated with an android::Bitmap object, and thanks to some useful jemalloc properties (determinism, size bins, lack of inline metadata), we found a way to reliably corrupt the relevant Bitmap object itself.
The Bitmap class is non-trivial, and it provides a variety of useful primitives when corrupted. In order to hijack the control flow, we can provoke a call from an arbitrary vtable pointer, or cause a direct call to a controlled function pointer with two arguments, if we know the address of libhwui.so. Furthermore, in the context of a potential ASLR bypass, we can prompt accesses from a controlled memory range, which may trigger a crash or not depending on the readability of the region. This is as good as we're going to get with regards to low-level exploitation capabilities.
With solid foundations laid down for the attack, we can shift our attention to some important higher level issues, such as:
- How to programmatically send MMS messages?
- How to (ab)use the MMS protocol to leak information on whether the Messages app crashed upon the receipt of a message?
- Even with the presence of a potential side channel, how to disclose the full addresses of data and/or code in an effective and timely manner?
- Finally, how to convert the currently known RCE primitives to achieve actual arbitrary code execution?
Finding the answers to these questions will be the subject of the upcoming blog posts in the series.
No comments:
Post a Comment