Chinese search support: Improve query segmentation #3915
Comments
|
Thanks for providing. Could you please provide some example phrases and explain precisely what you would expect and what is happening? Note that we use
This might be related to the fact that segmentation is currently done during the build and not in the browser because Chinese support for |
|
Thank you for your prompt reply, I hope that when searching with two or more Chinese characters, all the results containing the keywords can be found, and the keywords can be highlighted correctly |



|
Thanks for coming back. I'm unable to understand or write Chinese, so I'll need actual text, not images. Please attach a |
|
Side note: the explicit separator configuration was not working because there were redundant backslashes, which I added to normalize escape sequences. However, this was wrong, as those escapes are not necessary for single quotes. I've corrected all instances in 33e65f7 and also improved the search separator for the community edition for Chinese. |
|
After setting the newly modified parameters, there is still the problem of missing results. Steps to reproduce the problem in the attached file are as follows :
My requirement is to achieve precise search, that is to say, when inputting "合同纠纷" to search, there is no need to segment "合同纠纷", but to find all consecutive occurrences of the string "合同纠纷" in all documents, and return the paragraph(or context) where the keyword is located and highlight "合同纠纷" in it. You may refer to the[teedoc](https://github.com/teedoc/teedoc) ,its search-plugin can be used as a reference.It can find all input keywords in all documents, and the search speed is very high. However, when it returns the hit results, all different results are mixed into one paragraph and the intercepted context is relatively short, which is inconvenient to read. I filed an issue under that project, the author replied that he has no plan to update the search plug-in recently. I am not specialized in computer-related work, and this is my first time using GitHub. If there is anything wrong, please forgive me |
|
Thanks for providing further information. The thing is – without segmenting, the search will treat non-whitespace separated content as whole words. You can still use a prefix wildcard and find words containing the characters, but it's probably not ideal. I'm not sure this can be fixed because we cannot segment in the browsers for the reasons stated. Somebody needs to port For this reason, you can do two things:
I know that this is not optimal, but please note that the new Chinese search is also still considered experimental. I'm very interested in improving it, and if we can find a way to segment in the browser, we can probably close the last usability gaps. |
|
Thank you for your explanation, segmenting the search query manually with whitespace did sovle the problem,but as you said,it is not optimal. I guess the author of teedoc should not have segmented the document or chose to split the document into single chinese character(the index.json structure is attached bellow), so that when you search for "abcd" ,teedoc will find all consecutive occurrences of "abcd", and then a fixed length characters before and after every "abcd" are intercepted as the result output . In this way, there will be some ambiguous results in the retrieval results, such as hitting “abc de”, but it can guarantee a 100% recall rate. On some occasions, such as finding regulations or contract terms, this is very important. I like the material theme very much, I hope the search plugin can support this search mode, I don't know if it can be achieved. Some of the above ideas may be layman or inaccurate, but I have tried my best to understand the technical issues, thank you for your patience again.
|

|
So, thanks again for the detailed explanation, especially in #3915 (comment) – it was very helpful in troubleshooting. I've improved the search recall rate by implementing a new segmentation approach that is based on the data of the search index. The idea is to train the segmenter with the segmentation markers that are present in the search index as a result of the build-time segmentation, in order to learn different ways of how a search query can be segmented. While the recall rate should now be close to optimal (meaning that all possible segmentations should now be present in the query that is sent against lunr), accuracy might have suffered. I'm still trying to learn about the best way to tackle this problem, but I think the new solution could already be a step into the right direction. It should be almost certainly better than segmenting the query at every character. For example, here are the segmentations for the examples you provided:
As already noted, accuracy might not be optimal. I'm still trying to understand whether it might be better to always use the longest match and throw away prefixes like Chinese search is still experimental. Let's improve it together! |
|
Thank you for your hard work. For your question, I believe returning the longest match is sufficient in most cases. According to my experience, single Chinese character may express different meanings in different words, and cannot help accurately locate the desired results. In my opinion,to the optimal, when searching for 违法行为, the search engine shall return all 5 results including违法行为 (now done), and do not return result which contains no 违法行为,but only contains 违(disobey), 法(law), 违法(illegal), 行(move), 为(for),行为(conduct)in it. That is to say, the searching experience is just the same as searching in Microsoft word or acrobat reader. |
|
Thanks for your feedback. Just to be clear, you're asking for the following behavior:
The tokens that are bold should be included, the others not, correct? |
|
The tokens that are bold should be included, the others not,but like this: |
The problem with these examples is that |
|
I've pushed the segment prefix omission logic in the last Insiders commit. I'll issue a release today, so the new Chinese search query segmentation can be tested appropriately 😊 The limitations from my last comment still apply, but I think the omission of prefixes greatly improves the accuracy. |
|
Released as part of 8.2.15+insiders-4.15.2! |
|
I just pushed another improvement to
The tokens in bold are added because they overlap, i.e. |
|
I tried the latest version and it seems to widen the range of matches and for me there is now too much noise to find what I'm looking for. Meilisearch's "phrase search" is exactly what I want, but due to jieba, it occasionally misses some results. #(meilisearch/meilisearch#1714). Thanks for your explanation, let me know that Chinese search is not as easy as I thought, I'll keep watching and participating in the test, looking forward to a better experience. |
|
We could revert the last change (adding overlapping matches), but I'd like to collect some feedback if other Chinese users also see it like that 😊 We could also make it configurable, but I'd be interested in other opions. |
|
When using google, people usually do not know what exactly they are looking for, so it is important to find all relevant documents with vague keywords. In other cases, such as searching in technical documents or legal documents, what the user want most is to distinguish the specific tokens with those similar ones, so the search engine should not (unless it’s smart enough) expand the querying tokens. Generally speaking, the current Chinese search is good for the first need in small documents, but not suitable for the second. In order to do accurate Chinese full-text search, I tried the following things:
Could you kindly let me know if the above two directions are correct ? |
|
Thanks for your input. Regarding exact phrase matching – this is supported in Material for MkDocs. Try searching for:
or
Other than that, could you provide a small Chinese text that shows your issue? You could put content in different sections and explain which query terms should find which section and which section should not be found by the search. |
|
Take the following content as an example:
|




|
Thanks! I'll see how we can improve it. Reopening. |
|
Okay, now I understand what the problem is. If the text contains Sadly, nothing we can fix right now. AFAICT, this should have no drawback on recall, but accuracy is slightly degraded. |
|
Disappointed to hear this, but thank you for your patience and clear explanation |
|
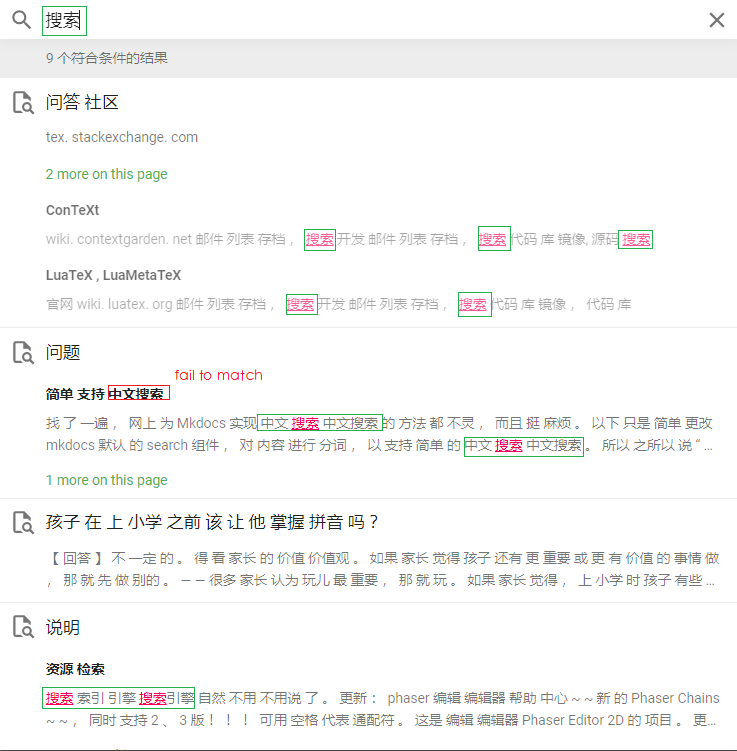
You can get as many words as you can from a string by seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造") # 搜索引擎模式
print(", ".join(seg_list)) |
|
Yes, we could theoretically use that part of the API, but the problem is that the search results will then contain all those words, as we use the |
Yes. However, on the searching results page, we are not reading text flow, but mainly concerned with the words matched. On my blog, for the body, I use
Perhaps it would be more appropriate to give users two toggle switches? |
|
Yes, we can add a flag to switch between Edit
You mean the user that is using your site? In the browser? That would mean we would need two search indexes, one which is cut for search, one which isn't. I'm sorry, but this is not practical, so I'm not for adding this functionality. It's also something that would only be needed for Chinese (AFAIK), so a very limited use case. |
|
BTW, note that now custom dictionaries for jieba are supported, which you can use to adjust segmentation. |
Contribution guidelines
I've found a bug and checked that ...
mkdocsorreadthedocsthemescustom_dir,extra_javascriptandextra_cssDescription
Using the new search plugin, there are a lot of omissions in Chinese results, and the highlight includes irrelevant content.
Expected behaviour
Fix Chinese segmentation bug
Actual behaviour
I add the code below,entering the chinese keywords “起诉”,and find only10+ results, also the entire paragraph where the keyword is located is highlighted.
When I remove the above code , the number of hit results increased to 200+ and highlighting are correct too, but I cannot find any results with keywords more than two Chinese characters.
Steps to reproduce
Package versions
Configuration
System information
The text was updated successfully, but these errors were encountered: