2013 has been an incredible year. We opened our beta to the public, launched iOS and Android SDKs, raised our first round of venture investment, doubled our team and took the beta label off Firebase -- and these are just a few!
As 2014 approaches, we wanted to take a moment to thank our amazing developers (that’s you!) for making Firebase what it is today. Your awesome apps and continued support make us excited to keep pushing Firebase forward every day. We hope you have a wonderful 2014 and we look forward to seeing what you build in the new year!
Here are the top highlights from the last year:
We’ve got some incredible things coming in early 2014, to get all the latest news you can follow us @Firebase on Twitter and join the Firebase conversation in our Google Group.
As always, we’re here to help however we can, so please don’t be shy!
Firebase is great for apps where data changes frequently, especially collaborative applications where users across the world are interacting with each other in realtime. We’ve seen some awesome collaborative drawing apps built with Firebase, and in this post we’d like to highlight Talkboard, an iPad app built by the team at Citrix. Talkboard is a beautifully designed app for whiteboarding and brainstorming ideas remotely. Below, Frederic Mayot from Citrix answers a few questions about building Talkboard and integrating Firebase.
How does Talkboard use Firebase?
We use Firebase to handle all our data, from user profiles to whiteboard data. The API was so simple that we implemented all the communications and data synchronization in a bit more than a week. Thanks to disk persistence, we allow our users to access and edit their projects and whiteboards anywhere, anytime, without worrying about being connected to the internet. Though very simple in its UI, Talkboard is a complex iOS application. However, we managed to model everything we needed with Firebase, including making the app secured and very responsive. The application is sending complex data structures representing the strokes at very high frame rates. We were very impressed to see such a low latency. This really enables the magic of showing the strokes being updated in real-time across devices.
What are some ways you've used Talkboard to collaborate at Citrix?
As soon as we got an initial version working, we used Talkboard to design Talkboard ;-) It is such an amazing experience to be able to draw in real-time with someone and be able to talk about it! The app makes it very easy to produce beautiful artifacts, even if you’re not a designer.
What is the coolest use case of Talkboard you've seen so far?
We’ve seen many different use cases and are still learning from our users. Talkboard is picking up in the education space but also with designers and all kinds of business users. To me, the most amazing thing is to see how people have fun when using the app for the first time.
Download Talkboard for your iPad now to start collaborating with co-workers and friends in realtime!
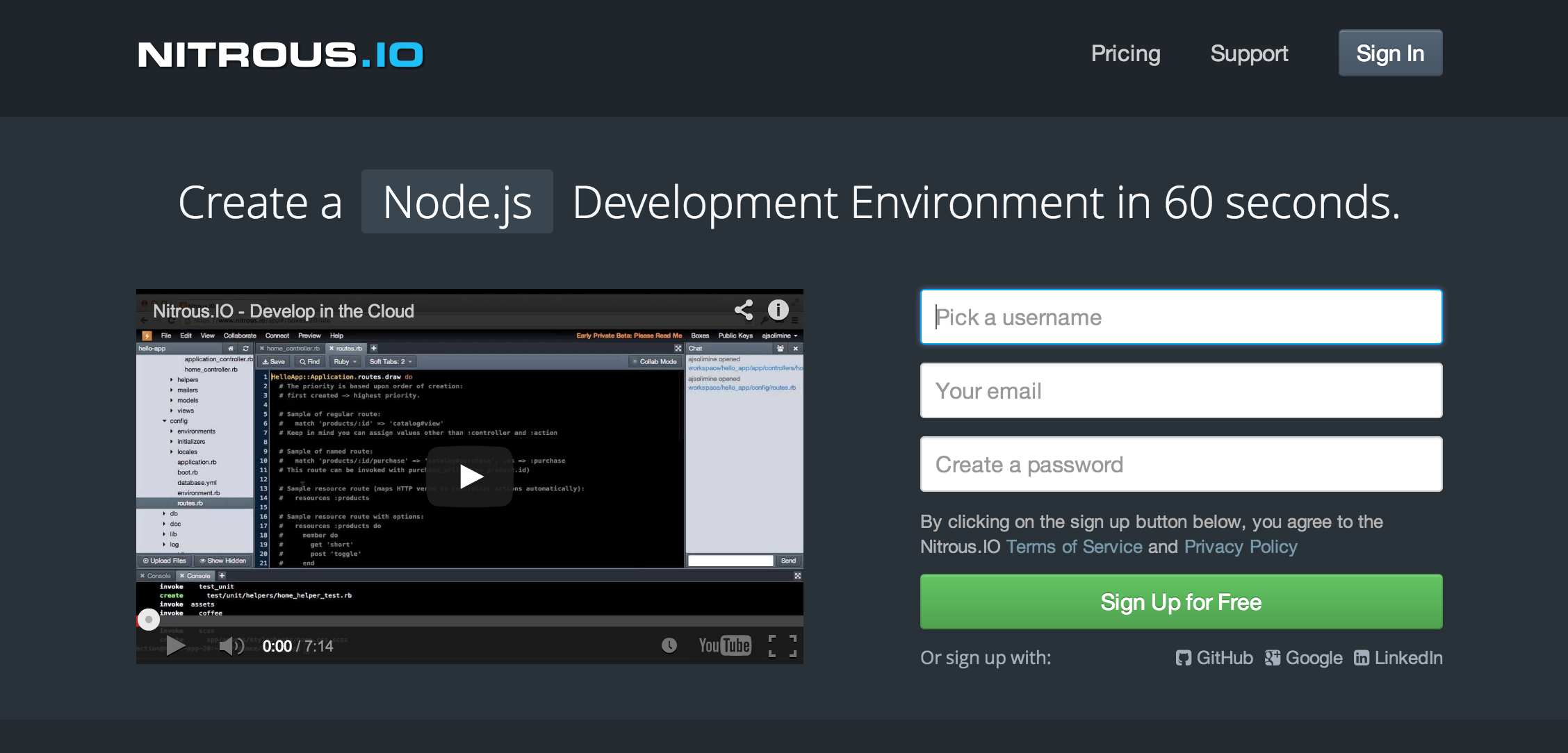
Peter, AJ and Arun are the co-founders of Nitrous.IO, a platform that enables developers to do their best work by easily creating and managing development environments in the cloud. The collaborative text editing features of Nitrous.IO are powered by Firepad, Firebase's open-source collaborative code and text editor.
What inspired you to build Nitrous.IO?
Configuring a development environment is a painful experience. Most people own multiple devices and installing and maintaining multiple development environments is a waste of time. Businesses often allocate a few days for every new hire for workstation setup and configuration and keeping an entire engineering team’s development environments in sync is a daunting task.
The Nitrous.IO Co-founders Peter, AJ and Arun had to work on multiple projects simultaneously in their past lives where each project had its own programming languages, databases, tools and libraries it depended on. Problems often arose when different versions or configurations of software were required to develop an application. Managing multiple development environments on a single machine is often impractical due to the fact that many software packages only allow a single version and configuration to be installed at a time, and syncing development environments across multiple computers is also a tedious and protracted process. We wasted countless hours of time and energy troubleshooting development environment issues, easily worth thousands of dollars of our time. We realized that if we could move environments to a central location (the cloud), we could create them, replicate them and share them much more easily than before.
There’s also the benefit of workspace accessibility. Peter always wanted to develop on his iPad (the crazy guy). We think the iPad is still in its infancy when it comes to fulfilling its potential as a powerful development machine, but we felt that with a cloud-based development platform, the iPad could become a powerful weapon in the developer’s arsenal. This prophecy has already come true - we have developers using Nitrous.IO on their iPads and other tablets, including engineers from well-known companies like Heroku.
In addition to feeling this need ourselves, we found that engineers at a number of companies, like Facebook and Quora are already developing on remote development servers, which are set up by teams solely dedicated to managing them. For most companies, however, it doesn’t make sense to dedicate a team to managing development environments. We think the future is in services like Nitrous.IO that make development environments much easier to manage across teams.
How does Nitrous.IO use Firepad?
Firepad enables Nitrous.IO users to collaboratively edit code in the browser in real time. This means that Pair Programming is as easy giving someone an URL that they can visit in any modern browser. It also means that cross functional teams can collaborate easily and iterate on their product faster. A developer can build something, and then discuss it with their Lead Designer in the Nitrous.IO IDE collaboratively. With the Nitrous.IO preview feature, they can have the application available on a public URL for the Design Lead to share with private beta users as soon as the developer has completed his work without waiting for a build and deploy cycle. A screenshot of our collaboration feature can be seen below.
We use Firepad to handle the Operational Transformation (basically handling the merges that occur on the document as multiple people edit the same text). Firepad also helps us to manage and display the cursor position of all users, undoing text, highlighting text and showing a username above the cursor, and when other users connect or disconnect to the document. Firepad saved us weeks of work, and helped us get the prototype of Nitrous.IO collaboration out in just a matter of days! A lot of people might spend months of their time developing something like this, but we were able to do it very quickly using Firepad.
What are some of the coolest uses of Nitrous.IO you've seen so far?
We are always excited and surprised by the many ways our customers use Nitrous.IO. Of course, we love it when the latest new framework or cool side project by our favorite celebrity developers are built on Nitrous but what really get us jazzed is when we get to introduce the world of web development to newcomers. We’re very pleased to be a key part of the teaching people who are new to web development. We have been a key part the Journeyman Project, Rails Bridge who teach women how to code in Rails, and Rails Girls Programs.
Are there any exciting features on your roadmap you can share?
We’re working on a few really powerful tools around sharing environments that we think are going to help developers become considerably more efficient with their workflow. We’ll be continuing to work on our collaboration features and deployment integration as well, so stay tuned to @nitrousio on Twitter to hear when we launch new features!
Do you have any advice for other developers building collaborative applications?
Before implementing certain features by yourself, you should definitely study the underlying data structure of Firepad. It will help you considerably when you want to do certain customizations like implementing cursor colors, highlighting text, user presence etc...
You should also consider using Firebase if you are extending your implementation of Firepad. We used Firebase to power the chat and file notifications within the feed window pane on our editor and it saved us a ton of time!
Aaron Wenger is the Co-founder of Survata, an online market research service built with Firebase and Angular.
Why did you decide to build Survata?
We built Survata to enable anyone to gather consumer opinions to educate their decision making. Before Survata, people who wanted survey data to guide a decision could either pay a market research firm to poll the general public or use SurveyMonkey to poll their friends and colleagues. For many uses, market research firms are too expensive and have too much bureaucracy; and friends and colleagues are often not representative of the group you need to poll. Survata lets anyone poll the general public at an affordable cost and with little overhead. Importantly, we still provide quality customer service and have an expert survey analyst work with all clients to ensure proper survey design. And that is where we use Firebase.
How does Survata use Firebase?
Survata uses Firebase in our survey creation tool and survey dashboards to facilitate communication between clients and our expert survey analysts. Firebase's real time synchronization lets the Survata analyst collaborate with and advise clients as the client is designing a survey. The Firebase solution replaced our previous solution built on email and Google documents. It has greatly streamlined the survey design process.
What other technologies does Survata use?
Our web app is built in AngularJS, using AngularUI components and AngularFire bindings. We use RequireJS to manage JavaScript dependencies. Our backend uses PHP and MySQL. We use Zapier web hooks to connect to a variety of third party web services. Our non-interactive web pages (and components of our web apps) are statically built from Mako templates and served as simple HTML.
What does the future of consumer research look like? Any exciting features in the pipeline for Survata?
In the coming years, market research will be decentralized and democratizated, as businesses embrace the do-it-yourself model in place of hiring expert firms. The new model - championed by Survata and others - will open market research to many companies and individuals to whom it has not been accessible to date. As to what we have in the pipeline, we will soon be offering the ability to poll individuals outside of the United States. And we are working hard on a set of tools to help clients not only gather survey data but also analyze and understand that data; we are using Firebase there too to let clients see data as we gather it.
Do you have any advice for other developers using Firebase?
Survata embraced AngularJS and Firebase together, and the two technologies have dramatically improved the speed at which we develop new features. I would suggest that anyone starting with Firebase also examine AngularJS, as Firebase's automatic model-server binding works nicely with AngularJS's model-DOM binding. I also advise that you read the AngularFire source code once you've worked with Firebase for a few weeks; it helps you understand the functional and performance implications of the magic synchronization. Specifically, it is important to understand when new data from Firebase causes creation of a new object instead of an update to an existing one.
In October Anant had the opportunity to speak at Realtime Conf - an amazing conference highlighting new technologies on the Open Web. Realtime Conf is not your typical tech conference, it follows an intricate storyline and each speaker is cast as a character in the plot.
The title this year was "Something Greater Than Artifice," you can check out the entire story here. Anant was cast as Quentin Cheshire, hailing from the country of West RTC. He spoke about the advantages of data synchronization over message passing when building distributed apps. You can watch his talk below and the slides are available here:
We were honored to participate in one of the world's best conferences on realtime technologies, and are looking forward to next year!
Ever since Thomas Boyt created a Firebase Ember Data adapter, our community started asking about an official Firebase integration for Ember. We're excited to release EmberFire today: official Firebase bindings for Ember Data! EmberFire makes it easy for developers to add a real-time backend to their Ember application with just a few lines of code. Check out the blog example, and then dive into code to wire up your app's Ember backend - no servers required.
As the Ember community grows, many companies (including Square, Zendesk, and Groupon) are using the framework to build ambitious, asynchronous web applications. A few weeks back, Tom and Yehuda from the Ember Core Team came by the Firebase offices and worked with us to develop a first-class integration for Firebase. Tom explains the benefits this integration will bring to developers:
“By freeing developers from the constraints of the backend, Firebase unlocks a whole new category of sophisticated, client-side JavaScript applications. Now, with first-class support for Ember.js, those developers can continue pushing the boundaries of what's possible in the browser by leaning on the strong architectural features of Ember that lead your app towards clean separation of concerns instead of messy spaghetti. (Let's also not forget terrific support for URLs out of the box.) Ember's always been about building ambitious web applications, and this collaboration with Firebase only strengthens that idea.”
We know Firebase's real-time data synchronization will be a great fit with Ember's opinionated front-end philosophy, so let's take a look at how it all works.
To begin using EmberFire, simply include the necessary libraries in your application. Note that our EmberFire bindings work only with Ember Data.
<!-- Don't forget to include Ember and its dependencies --> <script src="http://builds.emberjs.com/canary/ember-data.js"></script> <script src="https://cdn.firebase.com/js/client/1.0.17/firebase.js"></script> <script src="emberfire.js"></script>
Now you're ready to automatically sync your Ember models with data stored in Firebase. To start using EmberFire, simply create an instance of DS.FirebaseAdapter and DS.FirebaseSerializer in your app, like this:
DS.FirebaseAdapter
DS.FirebaseSerializer
App.ApplicationAdapter = DS.FirebaseAdapter.extend({ firebase: new Firebase('https://<my-firebase>.firebaseio.com') }); App.ApplicationSerializer = DS.FirebaseSerializer.extend();
With the adapter and serializer set up, you can now interact with the data store as you normally would with Ember. For example, calling find() with a specific ID will retrieve that record from Firebase. It will also start watching for updates and will update the data store automatically whenever anything is added or removed.
For more documentation, check out the EmberFire README.
Yehuda, Tom, and the rest of the Ember Core Team, who gave us invaluable input on multiple iterations of the bindings. We’d also like to thank everyone who helped us test early versions of EmberFire and gave excellent feedback to help us make the bindings top-notch.
This is just the beginning of our Ember integration, so we welcome your feedback and participation! Submit a pull request, or share your thoughts on Twitter or the Firebase Google Group. We can't wait to see what you build with Ember and Firebase.
Update (November 4, 2014): While this post still contains some useful and relevant information, we have released advanced query functionality which solves a lot of the problems this post discusses. You can read more about it in our queries blog post.
No WHERE clauses? No JOIN statements? No problem!
Coming from a SQL background as I did, it can take a while to grok the freedom of NoSQL data structures and the simplicity of Firebase's dynamic, real-time query environment.
Part 1 of this double-header will will cover some of the common queries we know and love and talk about how they can be converted to Firebase queries. Part 2 goes on to cover some advanced query techniques for Firebase and a solution for full-blown content searches.
So let's jump in. Here's what we're going to cover today:
This article relies heavily on the proper use of the following API calls, all of which are introduced in the documentation for Queries and Limiting Data:
This article also leans heavily on theory from Anant's authoritative post, Denormalizing is Normal. Where Anant's post covers a wide breadth and highly foundational concepts, this post serves more as a quick reference and recipe book.
We're going to work with the examples-sql-queries Firebase for all the examples. Feel free to browse the data and get a feel for the structure.
A lot of times in our docs, you'll see something like var ref = new Firebase(URL); and then later, ref.child('user/1'). But in our examples we use new Firebase('URL/child/path'). So which should you use? They are functionally equivalent; use the one that keeps your code simple to read and maintain.
var ref = new Firebase(URL);
ref.child('user/1')
new Firebase('URL/child/path')
Using a variable will be a bit DRYer if it's going to be referenced several times, but creating multiple Firebase instances does not incur any additional overhead as this is all optimized internally by the SDK.
Select a user by ID (WHERE id = x)
We'll start off with the basics and build from here. In Firebase queries, records are stored in a "path", which is simply a URL in the data hierarchy. In our sample data, we've stored our users at /user. So to retrieve record by it's id, we just append it to the URL:
new Firebase('https://example-data-sql.firebaseio.com/user/1').once('value', function(snap) { console.log('I fetched a user!', snap.val()); });
See it work
Find a user by email address (WHERE email = x)
Selecting an ID is all good and fine. But what if I want to look up an account by something that's not already part of the URL path?
Well this is where ordered data becomes our friend. Since we know that email addresses will be a common lookup method, we can call setPriority() whenever we add a new record. Then we can use that priority to look them up later.
new Firebase("https://examples-sql-queries.firebaseio.com/user") .startAt('kato@firebase.com') .endAt('kato@firebase.com') .once('value', function(snap) { console.log('accounts matching email address', snap.val()) });
Pretty cool and useful for most cases, but what if we can't use priorities? Or we need to search on more than one field? Well then it's time to employ some indices!
See this example, which uses index/ to link email addresses to user accounts.
Get messages posted yesterday (WHERE timestamp BETWEEN x AND y)
What if we'd like to select a range of data? Ordering data with priorities is quite useful for this as well:
new Firebase("https://examples-sql-queries.firebaseio.com/messages") .startAt(startTime) .endAt(endTime) .once('value', function(snap) { console.log('messages in range', snap.val()); });
Paginate through widgets (LIMIT 10 OFFSET 10)
First of all, let's make some assertions. Unless we're talking about a static data set, pagination behavior becomes very ambiguous. For instance, how do I define page numbers in a constantly changing data set where records are deleted or added frequently? How do I define the offset? The "last" page? If those questions are difficult to answer, then pagination is probably not the right answer for your use case.
Pagination for small, static data sets (less than 1MB) can be done entirely client side. For larger static data sets, things get a bit more challenging. Assuming we're writing append-only data, we can use our ordered data examples above and assign each message a page number or a unique incremental counter and then use startAt()/endAt().
// fetch page 2 of messages new Firebase("https://examples-sql-queries.firebaseio.com/messages") .startAt(2) // assumes the priority is the page number .endAt(2) .once('value', function(snap) { console.log('messages in range', snap.val()); });
But what if we're working with something like our widgets path, which doesn't have priorities? We can simply "start at" the last record on the previous page by passing null for a priority, followed by the last record id:
// fetch page 2 of widgets new Firebase("https://examples-sql-queries.firebaseio.com/widget") .startAt(null, lastWidgetOnPrevPage) .limitToFirst(LIMIT+1) // add one to limit to account for lastWidgetOnPrevPage .once('value', function(snap) { var vals = snap.val()||{}; delete vals[lastWidgetOnPrevPage]; // delete the extraneous record console.log('widgets on this page', vals); });
See it work or see a full pagination example
Join records using an id (FROM table1 JOIN table2 USING id)
Firebasers talk a lot about denormalization, which is great advice, but how do you put things back together once you've split them apart? Well, it's a great deal simpler than it might seem.
Firebase is a real-time sync platform. It's built for speed and efficiency. You don't need to worry about creating extra references, and can listen to as many paths as you'd like to retrieve your data:
var fb = new Firebase("https://examples-sql-queries.firebaseio.com/"); fb.child('user/123').once('value', function(userSnap) { fb.child('media/123').once('value', function(mediaSnap) { // extend function: https://gist.github.com/katowulf/6598238 console.log( extend({}, userSnap.val(), mediaSnap.val()) ); }); });
If you are anything like me, your perfectionist instincts will be kicking in about now, since our merge logic synchronously waits for the user data to load before grabbing media. It also gets a bit verbose if we add several paths to be joined. So let's expand this into a utility that will merge any number of paths asynchronously, and stick a fork in it:
See three paths merged in parallel
More Tools to Come
Part 2 of this post covers some advanced techniques for performing content searching (e.g. WHERE description IS LIKE '%foo%').
WHERE description IS LIKE '%foo%'
We're hard at work optimizing Firebase's search and querying features by combining the best aspects of patterns like map reduce with the simplicity and speed of our real-time tools. Look for more news on this in the next few months! In the mean time, we'd love to hear your feedback. Let us know in the comments or email firebase-support@google.com.
Update (June 23, 2014): This post is about GeoFire 1.0. We have since released GeoFire 2.0 which can be read about in a blog post here.
Location based services are hot. From a black car to the best sushi near you, your favorite apps use location tracking and localized search to bring the (relevant) world to your fingertips. Today we’re excited to release GeoFire - a geospatial library for Firebase that makes it easy for you to add real-time, location-based features to your app; with just a few GeoFire function calls, you can leverage your users’ locations too.
The What
Imagine you want to build an app to monitor airplanes in and around the San Francisco airport - the app finds planes entering and leaving the airport’s airspace, which is defined by a preset radius around the control tower, and keeps track of all planes that are within the airspace.
The app needs two location-based features:
Localized search, to find planes that are located within the preset radius from the tower. As planes enter and leave the airspace, the search results must change too. Real-time location tracking, to ensure plane locations in the app are up-to-date.
Implementing these features using just Firebase is non-trivial: you have to store the planes’ locations, represented as latitude-longitude pairs, implement distance calculation with latitude-longitude pairs, implement efficient location modification and re-calculation of distances, …and ten other things you’d rather not; so we built GeoFire for you.
The How
The GeoFire library provides functions to store data that you’d like to query by location, update location data, and perform location based searches that reflect location updates in real-time.
With Firebase and GeoFire, all you need to do to build the control tower app is:
Call GeoFire’s insertByLocWithId function to store the planes’ initial locations to Firebase. Call the updateLocForId function to update the planes’ locations as they move. Call the onPointsNearLoc function with the tower’s location and airspace radius to get the set of planes within the airspace. Any changes to the set are automatically reported in real-time, so the function need only be called once.
insertByLocWithId
updateLocForId
onPointsNearLoc
And that’s it, you’re done. Yup, that’s what we said - location-based anything is easy with GeoFire.
The But Really How
To store data by location in Firebase, GeoFire converts the latitude-longitude pair to a geohash. A geohash is an alphanumeric string which is generated by interleaving the bit representations of the latitude and the longitude coordinates of a location, and base32-encoding the result. Geohashes have a neat property that makes them suitable for geospatial queries like localized search: points with similar geohashes are guaranteed to be near each other. (It's worth noting that points that are near each other may not have similar geohashes though.)
The data for location querying is stored at its geohash in Firebase. To search for the nearest data points to a given location, GeoFire executes a series of a prefix queries over the geohashes; the set of prefixes queried depends on the search radius and the zoom resolution. This blog post provides a good introduction to the terminology and geohashing.
For location queries by client-provided id, GeoFire also inserts data at its id in Firebase. A simple double look-up or look-up+operation is all that’s needed to support the x-by-Id functions then.
The Fun and Profit
GeoFire makes it delightfully easy for you to add location-based features to your app. So go forth, treat your users to some of that localized love we all love!
As always, we’re all ears for feedback, comments and questions - reach out to us via the Firebase google group or Twitter!
We first told the world about Firebase on April 12th, 2012.
We were blown away with the response: 35,000 unique visitors and 3,000 developer sign-ups in the first 24 hours.
The enthusiasm hasn’t waned over the past 16 months and this momentum has brought us to today’s big announcement. We’re taking the ‘beta’ label off and are officially launching Firebase!
This means two things: (1) Firebase is ready for large, mission-critical applications and (2) Firebase is now a paid product.
We operate at serious scale. Firebase is trusted by some of the biggest companies, and every day we see large, polished apps being launched on Firebase. Here are some highlights:
To ensure the long-term sustainability of Firebase, we’re now a paid product. We have a large free tier that is great for development and small production apps. Our paid tiers start at $49 / mo, and we have Enterprise pricing available for apps that need to scale to millions of concurrent users and terabytes of data. You can see our pricing here.
Thank you!
We want to thank you all for your help. Developer feedback is the reason the Firebase API is so concise and powerful. Your support requests, one-on-one feedback at hackathons, and honest critiques have helped us immensely. Please keep giving us your feedback.
Here are some of the highlights from our time in beta:
Our progress so far has been made with a small and talented team. Now that we’ve raised our Series A we’ll be expanding our team to better serve if you. If you’re an exceptional engineer, designer, or community manager you should join us!
The Future
We’re building the easiest-to-use platform for building rich, modern applications. We get up every morning because we’re passionate about helping developers create extraordinary experiences for their users, and we’re just getting started on this mission. You’ll see some great new features coming soon, including advanced querying, expanded platform support, offline disk persistence, and improved debugging and analytics tools.
Thank you again for your support. Keep building amazing things!
We’re happy to announce a new feature that gives you more power and flexibility when writing your Security and Firebase Rules! Specifically, we’re expanding the operations you can use for validating string data. You can now use .length, .contains(), .beginsWith(), .endsWith(), .replace(), .toLowerCase(), and .toUpperCase() to examine and manipulate strings. Here are a few examples of what you can do with the new operations:
.length
.contains()
.beginsWith()
.endsWith()
.replace()
.toLowerCase()
.toUpperCase()
Ensure only a string of at least 10 characters can be written:
".validate": "newData.isString() && newData.val().length >= 10"
Allow read access only if auth.identifier ends in @company.com:
".read": "auth.identifier.endsWith('@company.com')”
Normalize an email address and check for its existence under /users/:
".read": "root.child('users').child(auth.email.replace('.', ',').toLowerCase()).exists()"
For full details and more examples, see the documentation. And let us know what you’d like to see next!
Today, we are happy to announce Firechat: multi-featured open source chat powered by Firebase. Firechat is simple and easily extensible, and is intended to give our developers a big head start when building chat products on Firebase.
Chat is one of the most fundamental use-cases for Firebase, and we know that designing and building full-featured chat from the ground-up can be time consuming. With Firechat, you get robust, secure chat that works out of the box, and a concise, documented foundation upon which you can customize and extend to meet your specific needs.
Out of the box, Firechat will work seamlessly with your existing authentication, or with Firebase Simple Login. Users can chat with other users via any number of public rooms listed, or public and private chat rooms they create. Users can also view the list of users active in any room, or across any room on the site, search them by name, mute users, or invite them to a chat room.
Since it’s built on Firebase, Firechat is built using only client-side code. Additionally, it is fully secure, relying upon Firebase’s authentication and declarative Security and Firebase Rules to ensure that only the right users can read or write data when you want them to.
Ready to learn more? Check out a live demo, complete with documentation, integration information, and annotated source code at firebase.github.io/firechat.
When you’re ready to start building, star / fork the repo on GitHub, and let us know what you build! We’d love to hear your feedback, questions, and feature requests, so don’t hesitate to get in touch.
Today, we are excited to announce full support for Java and Android! Now, Android developers can easily add real-time features to their applications without worrying about networking, scaling, or writing complicated server code.
Three months ago we launched native Firebase support for iOS and OSX devices. This was our first step into the world of mobile and we were thrilled with the reception. Now, with the new Java / Android SDK, we natively support more than 90% of all smart phones in the world.
Now that Firebase is supported on the web and both major mobile platforms, it's a perfect fit for building cross-platform applications. Each platform creates and consumes the same data type (JSON), and changes written to Firebase on one platform will show up seamlessly on any other.
Firebase's synchronization-based API is especially powerful in mobile applications. The SDK transparently handles caching, reconnecting, and data merging. Apps built with Firebase will remain responsive even when a device is offline, and changes will be synced back to the Firebase servers when a network becomes available again.
Our Java SDK can be used from your backend as well to allow you to synchronize and modify data directly from your servers. This lets you perform additional data processing, trigger events when certain data changes occur, and even mirror your Firebase data in other kinds of data stores.
You can get started using the Firebase Java SDK by following the steps in the Java / Android Quickstart Guide. In addition, check out the sample applications available on GitHub: Chat and Shared Drawing.
We're excited to see the apps you build, and we can't wait for those "pull to refresh" buttons to become a thing of the past.
To get updates on new SDKs as well as new versions of existing SDKs, follow @FirebaseRelease.
This post will teach you how to build a fully working presence system using Firebase.
Imagine you have some exciting news you really want to share with a friend. You jump on your favorite social network, open the friends list, and quickly scan for your friend's name. There's a red dot next to it indicating that she's busy - no matter - this is important! You double click to open a chat window...
A lot of us do this little routine every day. Knowing if somebody is currently online or offline is called "presence" and is a pretty basic feature in most collaborative applications (such as chat). What most of us don't realize, however, is that while the feature may appear simple, building the infrastructure to support it from scratch can be very difficult.
Have no fear! Firebase makes adding presence to your application very easy.
A presence system is simply a way of sharing your status with other users. At a basic level, this status could be something simple like whether a given user is currently online or offline. Firebase is great at doing exactly that - sharing state.
The naïve approach - Online / Offline State
The first step when building a presence system is for each client to be able to detect when it is online and offline. Firebase provides a convenient way to do this via the special .info/connected path. Great!
var amOnline = new Firebase('https://<demo>.firebaseio.com/.info/connected'); var userRef = new Firebase('https://<demo>.firebaseio.com/presence/' + userid); amOnline.on('value', function(snapshot) { if (snapshot.val()) { // User is online. userRef.set(true); } else { // User is offline. // WARNING: This won't work! See an explanation below. userRef.set(false); } });
Simple enough, right? The 'value' callback is automatically triggered by Firebase whenever the connection state changes (e.g. a user loses their internet connection) and we can set a boolean value for each user as appropriate.
This won't work in practice though - can you figure out why?
When the user goes offline, our callback will be triggered, but by then it's too late to notify other clients because we aren't connected to the network anymore.
Online / Offline State Done The Right Way
So what do we do? We can solve the offline problem by utilizing a special feature in Firebase known as onDisconnect - a function that tells the Firebase server to do something when it notices a client isn't connected anymore.
This is exactly what we want - we need to instruct the Firebase server to set the user's presence boolean to false when it detects that the client went offline:
false
var amOnline = new Firebase('https://<demo>.firebaseio.com/.info/connected'); var userRef = new Firebase('https://<demo>.firebaseio.com/presence/' + userid); amOnline.on('value', function(snapshot) { if (snapshot.val()) { userRef.onDisconnect().remove(); userRef.set(true); } });
Notice how much smaller this code is. The nice thing about onDisconnect() is that Firebase will automatically handle all of the nasty corner cases for you, like unclean disconnects.
onDisconnect()
A few points to note here:
We don't need to handle an else case. We simply use onDisconnect() to setup a trigger every time the user comes online.
else
The onDisconnect() call is before the call to set() itself. This is to avoid a race condition where you set the user's presence to true and the client disconnects before the onDisconnect() operation takes effect, leaving a ghost user.
set()
The call to onDisconnect().remove() is made every time the user comes online. This is because onDisconnect() operations are performed only once.
onDisconnect().remove()
We store the presence bit for a user independently on a top-level key instead of with the user record itself. This lets us quickly obtain a list of users who are currently online or offline without having to enumerate all user records. This is an example of denormalization, an important principle we've discussed earlier.
There's no special code in the callback for when the user goes offline. This isn't necessary as onDisconnect() will ensure that the presence bit will be updated when the client disconnects.
Hello, are you there? (Idle Status)
You're telling your friend the good news and are having a great conversation. 10 minutes later, you notice your friend isn't responding anymore. Perhaps she had to leave her desk... wouldn't it be great if you were notified somehow that the user had become "idle"?
It's easy to add features like this if we store text instead of a boolean. To detect the idle state of a user, we'll make use of a library called idle.js:
<script src='https://www.firebase.com/js/libs/idle.js'></script> <script> var amOnline = new Firebase('https://<demo>.firebaseio.com/.info/connected'); var userRef = new Firebase('https://<demo>.firebaseio.com/presence/' + userid); amOnline.on('value', function(snapshot) { if (snapshot.val()) { userRef.onDisconnect().set('☆ offline'); userRef.set('★ online'); } }); document.onIdle = function () { userRef.set('☆ idle'); } document.onAway = function () { userRef.set('☄ away'); } document.onBack = function (isIdle, isAway) { userRef.set('★ online'); } </script>
Last seen at...
Let's say you want to share the news with another friend, but notice he's currently offline. Well, there's a big difference between someone being offline for the last 5 minutes and 5 hours. I almost always want to know when a friend was last seen online.
You can make use of Firebase's server-side timestamp feature to implement this. We can store the boolean value true when a particular user is online but set it to a timestamp when the user disconnects via use of onDisconnect and Firebase.ServerValue.Timestamp:
true
onDisconnect
Firebase.ServerValue.Timestamp
var amOnline = new Firebase('https://<demo>.firebaseio.com/.info/connected'); var userRef = new Firebase('https://<demo>.firebaseio.com/presence/' + userid); amOnline.on('value', function(snapshot) { if (snapshot.val()) { userRef.onDisconnect().set(Firebase.ServerValue.TIMESTAMP); userRef.set(true); } });
In your UI, you can now obtain the last time a particular user was online:
var userRef = new Firebase('https://<demo>.firebaseio.com/presence/' + userid); userRef.on('value', function(snapshot) { if (snapshot.val() === true) { // User is online, update UI. } else { // User logged off at snapshot.val() - seconds since epoch. } });
Session History
I can always tell that a friend is having a busy day if he comes online for 10 minutes at a time and keeps going offline. Wouldn't it be cool if we could keep a log of every user's session and know how long each session lasted?
Firebase makes that easy too. We can simply create a new entry in the user's presence 'log' every time they come online by using the convenient push() function and storing the current timestamp. Then, by using an onDisconnect operation, we can record the end time as well:
push()
var amOnline = new Firebase('https://<demo>.firebaseio.com/.info/connected'); var userRef = new Firebase('https://<demo>.firebaseio.com/presence' + userid); amOnline.on('value', function(snapshot) { if (snapshot.val()) { var sessionRef = userRef.push(); sessionRef.child('ended').onDisconnect().set(Firebase.ServerValue.TIMESTAMP); sessionRef.child('began').set(Firebase.ServerValue.TIMESTAMP); } });
Now, by enumerating all the children of https://<my-firebase>.firebaseio.com/presence/<userid> you can display a record of all the user's past sessions. The time at which each session began is stored at https://<my-firebase>.firebaseio.com/presence/<userid>/<sessionid>/began.
https://<my-firebase>.firebaseio.com/presence/<userid>
https://<my-firebase>.firebaseio.com/presence/<userid>/<sessionid>/began
That's It!
You now have a fully working presence system. Don't forget to check out the presence example of the code listed in this blog post. We've also updated our documentation on managing presence to include information on the server timestamps feature. Let us know via email, our Google Group, or comment on this blog if you're building something similar or have found other ways to build a presence system with Firebase.
It’s been two months since we launched Firepad, our open-source collaborative code and rich-text editor built on Firebase. Our mission has always been to empower devs with powerful collaborative editing features at their fingertips. Today we’re excited to announce two new features that make Firepad even more powerful.
List Support
Ordered and unordered lists have been the #1 feature request since we launched Firepad. They have been on our roadmap since the beginning, but there were a number of technical challenges to be solved before we could add them. I'm happy to report these challenges are behind us, and we now have rich support for ordered and unordered lists with arbitrary nesting. Take a look:
HTML Import
Until now, there was no easy way to get existing HTML content into Firepad. This often made it difficult to integrate Firepad into your application if you had existing content stored as HTML. With the advent of list support, we’ve also added HTML import functionality. Just use the firepad.setHtml() method on the API!
What’s Next?
We’re continuing to invest in improving Firepad’s rich-text features as well as evolving the docs and API to make sure that Firepad can be easily integrated into new and existing apps by developers of any skill level. We’d love to hear what you want to see next! Email us or open an issue on GitHub.
If you're in town for WWDC, we'd love to have you over at the Firebase offices for our very first ever WWDC Office Hours. Earlier this year we joined the Apple ecosystem by taking the covers off of the Firebase Objective-C client and it's been a fun ride! (If you haven't already, take a look at our Xcode templates that makes it easy to get started with Firebase).
Come by and meet the Firebase team and other developers building realtime apps.
Firebase WWDC Office Hours Meetup
188 King St. PH8San Francisco CA,94107United Statesdirections
I'm happy to be representing Firebase all week at WWDC. If you're around and want to chat about apps and APIs, you can find me on Twitter @vikrum5000 or drop me an email at vikrum@firebase.com.
We love hackathons, so it shouldn't come as a surprise that we were at AngelHack SF this past weekend. The event was a great success - Firebase was the most-used API at the event, with 22 teams using it to power their hack. Picking winners for our sponsor prizes was really hard!
We spent Saturday morning chatting with various teams and introducing them to some of our newer tools that could help them build their hack. For instance, Firepad is a real-time collaborative text editor that's trivial to embed; and Feed the Fire is a service that makes it very easy to consume RSS or Atom feeds with just a few lines of client-side JavaScript.
We held a breakout session on Saturday evening, where participants could come in and ask questions about Firebase and get help with building their app. The session lasted a whole 90 minutes (much longer than we anticipated), and included building a chat app from scratch without any plugins as a challenge. That part only took 20 minutes, you can see the result here.
The teams started work at 12:30 PM on Saturday and many pulled all-nighters working until code freeze at 12:30 PM on Sunday. 24 hours isn't a lot of time, but we were blown away by some of the apps people managed to build. Here are the winners of our sponsor prizes:
"Get a second pair of eyes on your email". Our first prize went to BlingMail, a browser extension that makes it easy to work on email drafts collaboratively. They won an iPad Mini and Firebase credit worth $5000.
"Code with Friends". Our second prize went to Coderang, a suite of online tools that makes pair programming in various languages a breeze. The author won Firebase credit worth $2500.
"Real Time Professional Collaboration". Our third prize went to RealCollab, an online collaboration tool which includes video conferencing, shared document editing and a shared whiteboard. The team won Firebase credit worth $1000.
Last, but not least, the grand prize winner of AngelHack SF was Liveabetes, which also used Firebase to power its backend. All in all, AngelHack SF was a great success and the whole team had a great time. We look foward to seeing some of you at the next event!
Update (October 3, 2014): Firebase Simple Login has been deprecated and is now part of the core Firebase library. Use these links to find the updated documentation for the web, iOS, and Android clients.
This post was featured as a guest post on the PhoneGap blog.
Many developers have been using Firebase in their PhoneGap applications since our beta launch nearly a year ago. We know many of you encountered some rough edges, so we've put a lot of work into making sure the experience of developing with PhoneGap and Firebase is a smooth one.
Today, we're announcing that the Adobe PhoneGap / Apache Cordova platform is fully-supported by Firebase and works out of the box to offer the full suite of functionality that Firebase provides on the web.
Aligned Philosophies
At Firebase, we're big believers in the power and flexibility in writing applications entirely using client-side code without managing your own servers. PhoneGap embodies this same philosophy in enabling developers to write mobile applications for a broad suite of devices using only client-side JavaScript.
PhoneGap goes further by providing rich APIs for accessing native device features, such as geolocation services or the device camera, that previously required writing device-specific code in the native platform language.
Getting Started
With Firebase, you no longer need to store all of your data locally on the device itself or manually sync it with a remote server using AJAX and your own authentication logic. Firebase makes it easy to enable real-time data synchronization in your PhoneGap application with a simple JavaScript include.
Ready to start building? Head to our web quickstart guide.
What's New
Firebase Simple Login is now fully supported in PhoneGap with the release of PhoneGap 2.3.0, making use of the InAppBrowser for OAuth-based authentication. You can now use Facebook, Twitter, GitHub, and password-based authentication in your PhoneGap application purely with a script include, free from the hassle of configuring application domains or bundle IDs. To see it in action, clone our sample repo and head to the documentation for Firebase Simple Login.
Update (April 2, 2015): While this post still contains some useful and relevant information, we have since released advanced query functionality and added documentation on best practices for structuring data in Firebase.
This is the second in a series of blog posts on Architecting your application with Firebase.
One of the questions users frequently ask us is — "How do I query my Firebase data for X?" — where X often resembles a SQL query. This is a natural question, especially when coming to Firebase from a relational database background.
Firebase essentially has two ways to query for data: by path and by priority. This is more limited than SQL, and there's a very good reason for that — our API is carefully designed to only allow operations we can guarantee to be fast. Firebase is a real-time and scalable backend, and we want to enable you to build great apps that can serve millions of users without compromising on responsiveness.
This makes it important to think about how you will need to access your data and then structure it accordingly. This blog post will help you do that!
Primitives
Firebase comes with two powerful query mechanisms which you should be familiar with. See our Data Structure and Query docs for details, but as a reminder:
You can query data by its location. You can think of the location as being a primary index (In SQL terms, ref.child('/users/{id}/') is roughly equivalent to SELECT * from users WHERE user_id={id}). Firebase automatically sorts data by location, and you can filter the results with startAt, endAt, and limit.
ref.child('/users/{id}/')
SELECT * from users WHERE user_id={id}
You can query data by its priority. Every piece of data in Firebase can be given an arbitrary priority, which you can use for whatever you want. You can think of this as a secondary index. You might, for example, store timestamps representing a user's date-of-birth as priority and then query for users born after 2000 with ref.child('users').startAt(new Date('1/1/2000').getTime()).
ref.child('users').startAt(new Date('1/1/2000').getTime())
With these two primitives in mind, we can start thinking about how to structure your data.
Structure is important
Before writing any code for a Firebase app, I spend some time thinking about how I'm going to structure the data. The benefit of this is two-fold — first, it makes it much easier to reason about Security and Firebase Rules when the time comes; and second, it forces me to think about the queries my app will need. A well designed tree structure is crucial to an elegant app.
The best way to learn is by doing, so let's take an example. We're going to design the data structure for a site that lets you post links and comment on them (think Hacker News or Reddit).
We'll discuss how this app would be designed if it were backed by a SQL database first and then approach the same problem in a Firebase friendly way. If you aren't familiar with SQL or just want to know how to structure the data in Firebase, feel free to skip the section on SQL!
In a SQL world
If you were writing this application with a SQL backend, you will probably have a table of users:
CREATE TABLE users ( uid int auto_increment, name varchar, bio varchar, PRIMARY KEY (uid) );
a table of posted links:
CREATE TABLE links ( id int auto_increment, title varchar, href varchar, submitted int, PRIMARY KEY (id), FOREIGN KEY (submitted) REFERENCES users(uid) );
and finally, a table of posted comments:
CREATE TABLE comments ( id int auto_increment, author int, body varchar, link int, PRIMARY KEY (id), FOREIGN KEY (author) REFERENCES users(uid), FOREIGN KEY (link) REFERENCES links(id) );
Rendering the home page of the site would require you to get a list of the latest links submitted:
SELECT * FROM links ORDER BY id DESC LIMIT 20
Displaying all the comments (latest first) for a particular link would be something like:
SELECT * FROM comments WHERE link = {link_id} ORDER BY id DESC
Whenever you want to display user information (on the user profile page, or the user name under a comment), you'll fetch that from the users table:
SELECT * FROM users WHERE uid = {user_id}
Let's say you also want to display all the comments made by a particular user on their profile page. That's easy:
SELECT * FROM comments WHERE author = {user_id}
Notice that we will be accessing comments in two different ways (by link_id and by author). We'll see the implications this has with Firebase momentarily.
link_id
author
You'd also have a set of INSERT statements whenever a comment is posted, a link is submitted, or a new user signs up. This should cover most aspects of the app (the devil is in the details, you need to sanitize all the incoming data and so on, but let's ignore all that for now).
INSERT
In a Firebase world
If I had to write the same app using Firebase, I might start by simply replicating the structure I came up with for the SQL version. Let's have three top-level keys, one each for users, links and comments:
users
links
comments
{ users: { user1: { name: "Alice" }, user2: { name: "Bob" } }, links: { link1: { title: "Example", href: "http://example.org", submitted: "user1" } }, comments: { comment1: { link: "link1", body: "This is awesome!", author: "user2" } } }
Rendering the home page is easy enough, you simply fetch the last 20 links submitted using a limitToLast() query:
limitToLast()
var ref = new Firebase("https://awesome.firebaseio-demo.com/links"); ref.limitToLast(20).on("child_added", function(snapshot) { // Add link to home page. }); ref.limitToLast(20).on("child_removed", function(snapshot) { // Remove link from home page. });
Notice that we're already seeing the benefits of using Firebase. By handling child_added and child_removed events, the home page will automatically update in real-time as items are added without the user touching the refresh button!
child_added
child_removed
Now what happens when you want to retrieve all the comments associated with a particular link? In SQL, each comment had a reference to the link it was tied to, and you could use WHERE link = {link_id} to retrieve them, but Firebase has no WHERE query. As structured, we can only access the comment if we know its comment ID, which we do not.
WHERE link = {link_id}
WHERE
This is the crux of a Firebase-friendly data structure: you sometimes need to denormalize your data. In this case, to enable retrieving the list of comments for a link, I'll explicitly store that list with each link:
{ links: { link1: { title: "Example", href: "http://example.org", submitted: "user1", comments: { comment1: true } } } }
Now you can simply fetch the list of comments for any given link and render them:
var commentsRef = new Firebase("https://awesome.firebaseio-demo.com/comments"); var linkRef = new Firebase("https://awesome.firebaseio-demo.com/links"); var linkCommentsRef = linkRef.child(LINK_ID).child("comments"); linkCommentsRef.on("child_added", function(snap) { commentsRef.child(snap.key()).once("value", function() { // Render the comment on the link page. )); });
We also wanted to display a list of comments made by every user on their profile page. So we do something similar:
{ users: { user2: { name: "Bob", comments: { comment1: true } } } }
Duplicating data like this can be counter-intuitive to many developers. However, in order to build truly scalable applications, denormalization is almost a requirement. Essentially, we are optimizing our data reads by writing extra data at write-time. Consider that disk space is cheap, but a user's time is not.
Considerations
Let's discuss some consequences of a structure like this. You will need to ensure that every time some data is created (in this case, a comment) it is put in the right places:
functon onCommentSubmitted(comment) { var root = new Firebase("https://awesome.firebaseio-demo.com"); var id = root.child("/comments").push(); id.set(comment, function(err) { if (!err) { var name = id.key(); root.child("/links/" + comment.link + "/comments/" + name).set(true); root.child("/users/" + comment.author + "/comments/" + name).set(true); } }); }
(If you want to be notified when both the set methods have completed, consider using a library like TameJS to compose multiple asynchronous operations.)
set
You'll also need to think about how you want to handle deletion and modification of comments. Modification of comments is easy: just set the value of the comment under /comments to the new content. For deletion, simply delete the comment from /comments — and whenever you come across a comment ID elsewhere in your code that doesn't exist in /comments, you can assume it was deleted and proceed normally:
/comments
function deleteComment(id) { var url = "https://awesome.firebaseio-demo.com/comments/"; new Firebase(url + id).remove(); } function editComment(id, comment) { var url = "https://awesome.firebaseio-demo.com/comments/"; new Firebase(url + id).set(comment); }
Firebase does all it can to make these kinds of operations effecient. For example, if you've already fetched the content of a comment for a link's page, and subsequently navigate to the profile page of the user that made the comment, refetching the value will be fast since it'll be returned from the local cache.
If you're looking for a full-featured example that applies these techniques, please take a look at Firefeed. Firefeed is a twitter clone that uses denormalization to build a complex application entirely client side.
Please don't hesitate to get in touch with us if you have any questions or want to discuss the appropriate architecture for your own app. We're available on Email, Twitter, Facebook, Stack Overflow and Google+.
Today we’re really excited to announce Firepad, a Firebase-powered open source collaborative text editor.
Firepad provides true collaborative editing, complete with intelligent OT-based merging and conflict resolution. It’s full-featured and has support for both rich text and code editing. Some of its features include cursor position synchronization, undo / redo, text highlighting, user attribution, presence detection, and version checkpointing.
Firepad is powered by Firebase, so it’s built entirely with client-side code. You can add it to any application simply by adding the JavaScript code to your project. You don’t need to configure servers or write any server-side code. For example, the Firepad website itself is composed entirely of static content and is served from GitHub Pages.
Since it’s powered by Firebase, Firepad provides all of the features you would normally expect from a Firebase app: low latency updates, offline mode support, first-class security controls, automatic scaling, and easy data accessibility. Firepad stores the full revision history of your document in a Firebase database, so it’s easy to integrate Firepad documents into larger apps. Your data is available in all of the normal ways: through client libraries, the REST API, and your App Dashboard.
We’ve put particular effort into providing an easy-to-use JavaScript API for Firepad so that you can integrate it into your apps. Firepad is based on the powerful CodeMirror editor, so you’ll have access to all of its APIs as well.
We Heard You Loud and Clear
After our launch last year we saw a slew of activity around Firebase and real-time text editing. It quickly became apparent that this was the primary use-case for many of our developers. After seeing at least a dozen separate implementations, we thought it was time to lend a hand.
Building a correctly-implemented, full-featured collaborative text editor is a difficult task, even with the help of Firebase. Since our team already had some expertise in this area (It helped that I previously led the editor team for Visual Studio at Microsoft), we decided that the best approach would be to build our own complete version as an open source project. This way our developers could start their projects from a solid foundation without needing to take the time to build their own.
What’s the Big Deal?
High-quality collaborative document editing has so far been the domain of only a select few (generally large) companies. With Firepad, we aim to change that. Our goal is to enable any developer to build a high quality collaborative experience, whether her company is as big as Google or not.
We’re already off to a good start. Socrates.io, Atlassian, and Action.io have put Firebase into production, and many more apps are in the works. If you want collaborative editing in your app, now is a good time to give it a try. There’s no server software to write or infrastructure to set up; just drop in the JavaScript and go.
Credit Where Credit is Due
Firepad was not built from scratch. We depend on the CodeMirror editor to actually render the document. We chose CodeMirror as we believe it has the best API of any open source editor.
We also borrowed from the code and concepts of ot.js. Thank you Tim Baumann!
Our launch of Firepad today is just the beginning. We will continue to actively develop Firepad to ensure it remains the best way to add real-time collaboration to your text editing app.
We hope the community will help us on this mission. Firepad is on Github, and all of the code is MIT-licensed, so feel free to fork and play to your heart’s content. We’ve even included a test suite to help you catch any bugs. And, if you build something great, please send us a pull request!
One area where we expect to see significant interest is in extending our support for rich text. Our rich text operational transform code is designed to be easily extended, so if you want to add additional formatting options, just jump in and give it a try. We’ll soon be adding new features here as well, including bulleted lists, text alignment options, and more.
We look forward to seeing what you build! As always, we love feedback, so please get in touch with your thoughts, comments, and suggestions.
You can try Firepad live in your browser, read the documentation, and more at Firepad.io.
Updates
See coverage in Wired, TechCrunch, GigaOm, and TechCocktail.
Firepad now support the Ace editor! Read about getting started with Ace in the Firepad documentation.
Follow @firebase
Today, we are happy to announce AngularFire: Firebase bindings for AngularJS that will make it even easier for developers to write rich, real-time web applications using the two technologies. Check out a live demo - we updated the Angular example from todomvc.com to be real-time. We also made it so you don't need a server for your Angular app, all in just a few lines of code!
Firebase + Angular.js = unimaginable developer bliss— Mark Nutter (@marknutter) February 21, 2013
Firebase + Angular.js = unimaginable developer bliss
“ AngularJS was originally developed in 2009 by Miško Hevery and Adam Abrons as the software behind an online JSON storage service, that would have been priced by the megabyte, for easy-to-make applications for the enterprise. ”
It was not surprising then, that we found it remarkably easy to integrate Firebase with Angular. We're pleased to say that the two technologies fit together very elegantly.
How does AngularFire work?
First, you'll need to include the AngularFire JS include, as well as Firebase:
<script src="angularFire.js" type="text/javascript"></script> <script src="https://cdn.firebase.com/libs/angularfire/0.5.0/angularfire.min.js" type="text/javascript"></script>
Then, declare the 'firebase' module as a dependency for your app:
var myapp = angular.module('myapp', ['firebase']);
Finally, bind a Firebase URL to a model in your controller:
myapp.controller('MyCtrl', ['$scope', '$firebase', function MyCtrl($scope, $firebase) { var ref = new Firebase('https://<my-firebase>.firebaseio.com/items'); $scope.items = $firebase(ref); } ]);
Now, any changes made to the model referenced by $scope.items (a regular JS array) will automatically be synchronized to Firebase - and therefore also show up on all your other clients. That's it!
$scope.items
We also have another mode of operation for cases where you want to be more explicit about when to sync model changes to Firebase. Check out the AngularFire website for more information.
These bindings would not have been possible without the help of Peter Bacon Darwin. Peter is an active member of the Angular community and had written the first ever Firebase/Angular integration library. We look forward to continuing working with him on making AngularFire ever better!
We'd also like to thank Benny Lichtner, Tom Saffell and Geoff Goodman for their invaluable feedback on early versions of AngularFire. The Angular community has also been immensely helpful to us, and we look forward to working with you all!
Join our Firebase + Angular Google Group to share your feedback or ask questions, and check out AngularFire on GitHub to file issues and pull requests!
[1] AngularJS Development History, Wikipedia