Build agentic RAG on Google Cloud databases with LlamaIndex
Hamsa Buvaraghan
AI Product Manager, Google Databases
Jerry Liu
Co-Founder/CEO, LlamaIndex
AI agents are revolutionizing the landscape of gen AI application development. Retrieval augmented generation (RAG) has significantly enhanced the capabilities of large language models (LLMs), enabling them to access and leverage external data sources such as databases. This empowers LLMs to generate more informed and contextually relevant responses. Agentic RAG represents a significant leap forward, combining the power of information retrieval with advanced action planning capabilities. AI agents can execute complex tasks that involve multiple steps that reason, plan and make decisions, and then take actions to execute goals over multiple iterations. This opens up new possibilities for automating intricate workflows and processes, leading to increased efficiency and productivity.
LlamaIndex has emerged as a leading framework for building knowledge-driven and agentic systems. It offers a comprehensive suite of tools and functionality that facilitate the development of sophisticated AI agents. Notably, LlamaIndex provides both pre-built agent architectures that can be readily deployed for common use cases, as well as customizable workflows, which enable developers to tailor the behavior of AI agents to their specific requirements.
Today, we're excited to announce a collaboration with LlamaIndex on open-source integrations for Google Cloud databases including AlloyDB for PostgreSQL and Cloud SQL for PostgreSQL.
These LlamaIndex integrations, available to download via PyPi llama-index-alloydb-pg and llama-index-cloud-sq-pg, empower developers to build agentic applications that can connect with Google databases. The integrations include:
In addition, developers can also access previously published LlamaIndex integrations for Firestore, including for Vector Store and Index Store.
Integration benefits
LlamaIndex supports a broad spectrum of different industry use cases, including agentic RAG, report generation, customer support, SQL agents, and productivity assistants. LlamaIndex's multi-modal functionality extends to applications like retrieval-augmented image captioning, showcasing its versatility in integrating diverse data types. Through these use cases, joint customers of LlamaIndex and Google Cloud databases can expect to see an enhanced developer experience, complete with:
-
Streamlined knowledge retrieval: Using these packages makes it easier for developers to build knowledge-retrieval applications with Google databases. Developers can leverage AlloyDB and Cloud SQL vector stores to store and semantically search unstructured data to provide models with richer context. The LlamaIndex vector store integrations let you filter metadata effectively, select from vector similarity strategies, and help improve performance with custom vector indexes.
-
Complex document parsing: LlamaIndex’s first-class document parser, LlamaParse, converts complex document formats with images, charts and rich tables into a form more easily understood by LLMs; this produces demonstrably better results for LLMs attempting to understand the content of these documents.
-
Secure authentication and authorization: LlamaIndex integrations to Google databases utilize the principle of least privilege, a best practice, when creating database connection pools, authenticating, and authorizing access to database instances.
-
Fast prototyping: Developers can quickly build and set up agentic systems with readily available pre-built agent and tool architectures on LlamaHub.
-
Flow control: For production use cases, LlamaIndex Workflows provide the flexibility to build and deploy complex agentic systems with granular control of conditional execution, as well as powerful state management.
A report generation use case
Agentic RAG workflows are moving beyond simple question and answer chatbots. Agents can synthesize information from across sources and knowledge bases to generate in-depth reports. Report generation spans across many industries — from legal, where agents can do prework such as research, to financial services, where agents can analyze earning call reports. Agents mimic experts that sift through information to generate insights. And even if agent reasoning and retrieval takes several minutes, automating these reports can save teams several hours.
LlamaIndex provides all the key components to generate reports:
-
Structured output definitions with the ability to organize outputs into Report templates
-
Intelligent document parsing to easily extract and chunk text and other media
-
Knowledge base storage and integration across the customer’s ecosystem
-
Agentic workflows to define tasks and guide agent reasoning
Now let’s see how these concepts work, and consider how to build a report generation agent that provides daily updates on new research papers about LLMs and RAG.
1. Prepare data: Load and parse documents
The key to any RAG workflow is ensuring a well-created knowledge base. Before you store the data, you need to ensure it is clean and useful. Data for the knowledge bases can come from your enterprise data or other sources. To generate reports for top research articles, developers can use the Arxiv SDK to pull free, open-access publications.
But rather than use the ArxivReader to load and convert articles to plain text, LlamaParse supports varying paper formats, tables, and multimodal media leading to improved accuracy of document parsing.
To improve the knowledge base’s effectiveness, we recommend adding metadata to documents. This allows for advanced filtering or support for additional tooling. Learn more about metadata extraction.
2. Create a knowledge base: storage data for retrieval
Now, the data needs to be saved for long-term use. The LlamaIndexGoogle Cloud database integrations support storage and retrieval of a growing knowledge base.
2.1. Create a secure connection to the AlloyDB or Cloud SQL database
Utilize the AlloyDBEngine class to easily create a shareable connection pool that securely connects to your PostgreSQL instance.
Create only the necessary tables needed for your knowledge base. Creating separate tables reduces the level of access permissions that your agent needs. You can also specify a special “publication_date” metadata column that you can filter on later.
Optional: Set up a Google Cloud embedding model. The knowledge base utilizes vector embeddings to search for semantically similar text.
2.2. Customize the underlying storage with the Document Store, Index Store, and Vector Store. For the vector store, specify the metadata field "publication_date" that you created previously.
2.3 Add the parsed documents to the knowledge base and build a Vector Store Index.
You can use other LlamaIndex index types like a Summary Index as additional tools to query and combine data.
2.4. Create tools from indexes to be used by the agent.
3. Prompt: create an outline for the report
Reports may have requirements on sections and formatting. The agent needs instructions for formatting. Here is an example outline of a report format:
4. Define the workflow: outline agentic steps
Next, you define the workflow to guide the agent’s actions. For this example workflow, the agent tries to reason what tool to call: summary tools or the vector search tool. Once the agent has reasoned it doesn’t need additional data, it can exit out of the research loop to generate a report.
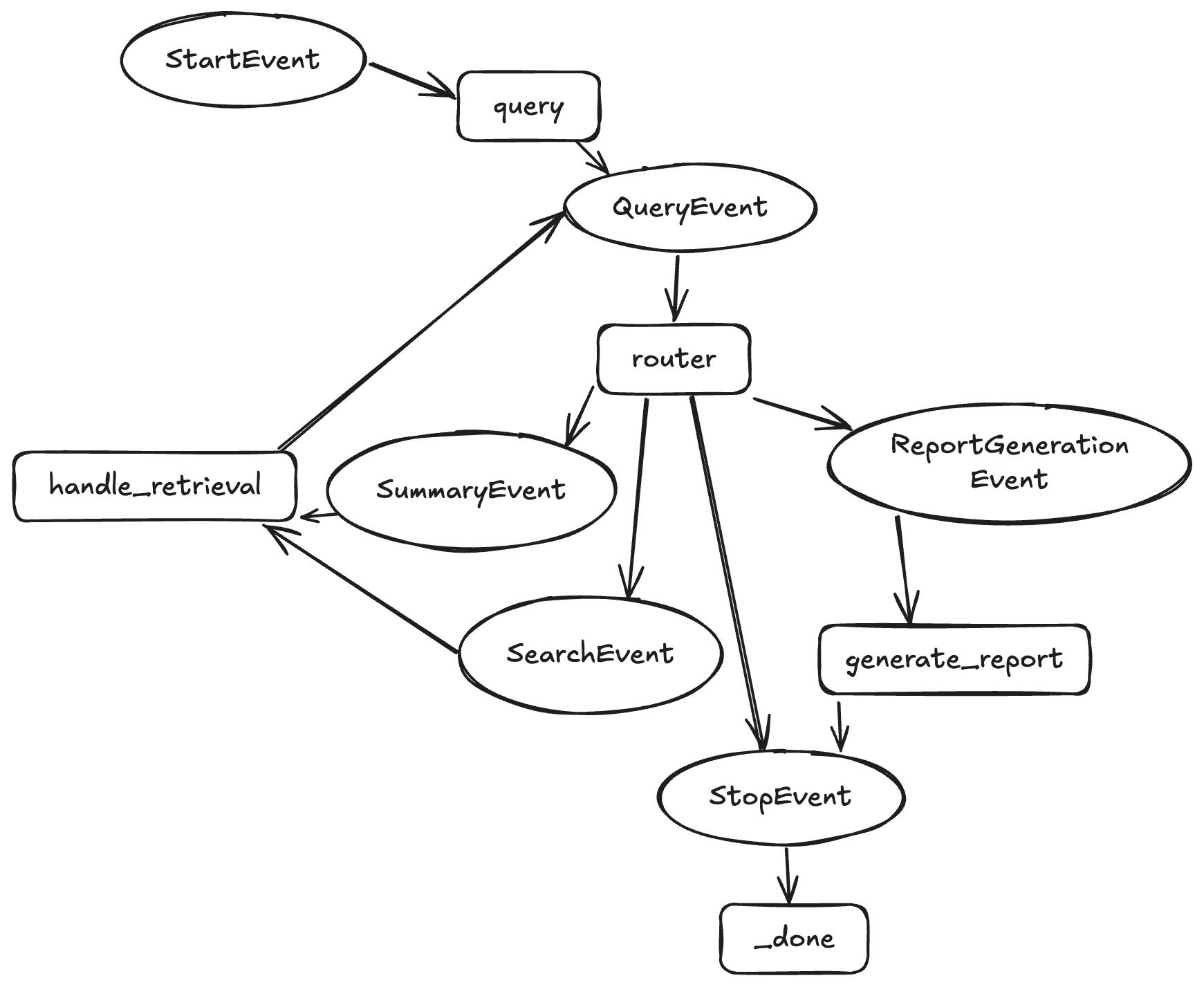
LlamaIndex Workflows provides an easy to use SDK to build any type of workflow:
5. Generate reports: run the agent
Now that you’ve set up a knowledge base and defined an agent, you can set up automation to generate a report!
There you have it! A complete report that summarizes recent research in LLM and RAG techniques. How easy was that?
Get started today
In short, these LlamaIndex integrations with Google Cloud databases enables application developers to leverage the data in their operational databases to easily build complex agentic RAG workflows. This collaboration supports Google Cloud’s long-term commitment to be an open, integrated, and innovative database platform. With LlamaIndex's extensive user base, this integration further expands the possibilities for developers to create cutting-edge, knowledge-driven AI agents.
Ready to get started? Take a look at the following Notebook-based tutorials:
-
AlloyDB
-
Cloud SQL for PostgreSQL
Find all information on GitHub at github.com/googleapis/llama-index-cloud-sql-pg-python and github.com/googleapis/llama-index-alloydb-pg-python.


