Tailor your search engine with AI-powered hybrid search in Spanner
Chao Tian
Software Engineer, Spanner
Jagan R. Athreya
Group Product Manager, Spanner
Search is at the heart of how we interact with the digital ecosystem, from online shopping to finding critical information. Enter generative AI, and user expectations are higher than ever. For applications to meet diverse user needs, they need to deliver fast, accurate and contextually relevant results, regardless of how queries are framed. For example:
-
Online shoppers expect to find "waterproof hiking boots with ankle support" just as easily as a specific "SummitEdge Pro" model.
-
Legal professionals need to pinpoint precise case citations or explore nuanced legal concepts with varied search terms.
-
Doctors require precision when searching for critical patient information. A doctor looking for “allergy to penicillin” must locate the record accurately, whether the information is labeled as “drug sensitivities” or misspelled as “peniciln”.
Spanner, Google’s always-on multi-model database with virtually unlimited scale, addresses these challenges with AI-powered hybrid search capabilities. Spanner allows developers to combine vector search, full-text search, and machine learning (ML) model reranking capabilities in a unified platform directly integrated with the operational data store, using a familiar SQL interface.
In this post, we will explore how you can build a customized search engine for an ecommerce marketplace using Spanner.
Building a tailored search engine on Spanner
For ecommerce – along with many other industries – a single search method often falls short, resulting in dissatisfied users, incomplete information, or lost revenue. Keyword search excels at precision but struggles with alternate phrasing or natural language; vector search captures semantics but may overlook specific terms. Combining the strengths of both would enable organizations to deliver a more effective search experience.
SpanMart, a hypothetical ecommerce marketplace, allows users to search for products using keywords or natural language. Its products table supports multiple search methods with two specialized columns and associated indexes:
-
A
description_tokenscolumn: This is a tokenized version of thedescriptioncolumn, breaking down the text into individual terms. A search index (products_by_description) on this column accelerates full-text search, acting like an inverted index in information retrieval. -
An
embeddingcolumn: This stores vector representations of the product descriptions, capturing semantic meaning rather than individual words. Similar descriptions are mapped close together in the “embedding space”. These embeddings are generated using models like Vertex AI Embeddings. A vector index (products_by_embedding) organizes these embeddings using a ScaNN tree structure for efficient semantic searches.
Here’s how the products table and its indexes are defined Spanner:
With these components in place, SpanMart can build an intelligent search pipeline that integrates:
- Vector search for semantic relevance.
- Full-text search for precise keyword matching.
- Result fusion for combining the results from different retrieval methods.
- ML model reranking for advanced result refinement.
This pipeline operates entirely within Spanner, where the operational data is stored. By avoiding integration with separate search engines or vector databases, Spanner eliminates the need for multiple technical stacks, complex ETL pipelines, and intricate application logic for inter-system communication. This reduces architectural and operational overhead and avoids potential performance inefficiencies.
The diagram below illustrates a high-level overview of how these components work together in Spanner.

Combining the power of vector and full-text search
When a user searches for products on SpanMart, the system first uses the embedding model to convert the user query into a vector that captures its semantic meaning. Then, SpanMart can build two queries:
These two queries excel in different scenarios and complement each other. For instance, when a user searches for a specific product model number, such as “Supercar T-6468”, the full-text search query can accurately find the exact model, while the vector search query suggests similar items. Conversely, for more complex natural language queries, such as “gift for an 8-year-old who enjoys logical reasoning but not a toy”, full-text search may struggle to yield useful results, whereas vector search can provide a relevant list of recommendations. Combining both queries would produce robust results for both styles of searches.
Reciprocal rank fusion (RRF)
RRF is a simple yet effective technique for combining results from multiple search queries. It calculates a relevance score for each record based on its position in all result sets, rewarding records ranked highly in individual searches. This method is particularly useful when the relevance scores from the individual searches are calculated in different spaces, making them difficult to compare directly. RRF addresses this by focusing on the relative rankings instead of scores within each result set.
Here's how RRF works in our example:
-
Calculate rank reciprocals: For each product, calculate its rank reciprocal in each result set by taking the inverse of its rank after adding a constant (e.g., 60). This constant prevents top-ranked products from dominating the final score and allows lower-ranked products to contribute meaningfully. For instance, a product ranked 5th in one result set would have a rank reciprocal of 1/(5 + 60) = 1/65 in that result set.
-
Sum rank reciprocals: Sum the rank reciprocals from all result sets to get the final RRF score of a product.
The formula for RRF is –
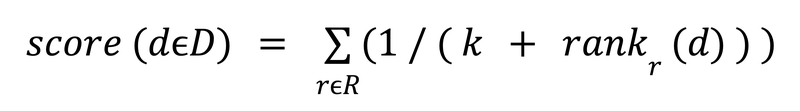
– where:
-
d is a product description
-
R is the set of retrievers (in this case, the two search queries)
-
rankr (d) is the rank of product description d in the results of retriever r.
-
k is a constant
Implementing RRF within Spanner’s SQL interface is relatively straightforward. Here’s how:
Explanations:
-
Common table expressions (CTEs): These are the WITH clauses, which are used in this query to improve readability. However, due to a current limitation, they may cause the query optimizer to default to an older version that lacks full-text search support. For now, the query uses the
@{optimizer_version=7}hint to suggest a more recent optimizer version. -
ANN CTE: This is the same as the previous ANN query, but with a twist. We assign a rank to each product in the results. While Spanner doesn’t support a direct way to assign ranks, there's a workaround. By converting the results into an array of structs, we can use the offset of each element within the array as its rank. Since array offsets start at zero, we use
offset + 1to represent the actual rank. Note that this is purely a SQL language workaround without performance impact. The query planner effectively optimizes away the array conversion and directly assigns an offset to each row in the result set. -
FTS CTE: Similarly, this part mirrors the previous full-text search query, with the rank assigned using the array offset.
-
Combining and ranking: The results from both CTEs are unioned, and grouped by the product
id. For each product, we calculate therrf_scoreand then select the top 50 products.
While RRF is an effective technique, Spanner's versatile SQL interface empowers application developers to explore and implement various other result fusion methods. For instance, developers can normalize scores across different searches to a common range and then combine them using a weighted sum, assigning different importance to each search method. This flexibility allows for fine-grained control over the search experience and enables developers to tailor it to specific application requirements.
Using an ML model to rerank search results
ML model-based reranking is a powerful way of refining search results to deliver improved results to the users. It applies an advanced yet computationally expensive model to a narrowed set of initial candidates, retrieved using methods like vector search, full-text search, or their combination, as discussed earlier. Due to its high computational cost, ML model-based reranking is applied after the initial retrieval reduces the result set to a small set of promising candidates.
Spanner's integration with Vertex AI makes it possible to perform ML model-based reranking directly within Spanner. You can use a model deployed to your Vertex AI endpoint, including those available from the Vertex AI Model Garden. Once the model is deployed, you can create a corresponding reranker MODEL in Spanner.
In this example, SpanMart employs a Cross-Encoder model for reranking. This model takes two text inputs - text and text_pair - and outputs a relevance score indicating how well the two texts align. Unlike vector search, which uses an embedding model to independently map each text into a fixed-dimensional space before measuring their similarity, a Cross-Encoder directly evaluates the two texts together. This allows the Cross-Encoder to capture richer contextual and semantic nuances in complex queries, such as “gift for an 8-year-old who enjoys logical reasoning but not a toy”. In a more advanced setup, the reranker could leverage a custom-trained model that incorporates additional signals such as product reviews, promotions, and user-specific data like browsing and purchase history, to offer an even more comprehensive search experience.
Once this model is defined in Spanner, we can proceed to add reranking on the initial search results using the following query:
Explanations:
-
ANN, FTS and RRF CTEs: These are the same previously defined approximate nearest neighbors, full-text search and reciprocal rank fusion queries, respectively.
-
ML.PREDICT Ranking: This step applies the
rerankermodel to each product description astextfrom the RRF results, along with the search query astext_pair. The model assigns a relevancescoreto each product. The products are then sorted by these scores, and the top 10 are selected.
Get started
In this post, we demonstrated one approach to combine full-text search and vector search in Spanner, but developers are encouraged to explore other approaches, such as refining full-text search results with vector search, or combining multiple search results with customized fusion methods.
Learn more about Spanner and try it out today. For additional information, check out:
-
Spanner vector search documentation and codelab
-
Spanner full-text search overview
- Spanner vertex AI integration overview and tutorial on generating ML predictions using SQL


