Introducing BigQuery text embeddings for NLP tasks
Wen Zhang
Software Engineer, Google Cloud
Xi Cheng
Engineering Manager
Text embeddings are a key enabler and building block for applications such as semantic search, recommendation, text clustering, sentiment analysis, and named entity extractions. Today, we’re announcing a set of new features in BigQuery to generate text embeddings and apply them to downstream application tasks with familiar SQL commands. Starting today, you can use four types of text embedding generation directly from BigQuery SQL:
textembedding-gecko for embedding with generative AI
BERT for natural language processing tasks that require context or/and multi-language support
NNLM for simple NLP tasks such as text classification and sentiment analysis
SWIVEL for a large corpus of data that needs to capture complex relationships between words
The newly supported array<numeric> feature type allows these generated embeddings to be used by any ML model supported by BigQuery for data analysis based on proximity and distance within the vector space.
Generate your first embedding using BigQuery
To set the stage for the BQML applications covered below, we first review the newly added function using textembedding-gecko PaLM API for generating embeddings. More specifically, it can be invoked via the new BigQuery ML function called ML.GENERATE_TEXT_EMBEDDING, using a simple two-step process.
First, we register the textembedding-gecko model as a remote model.
Second, we use the ML.GENERATE_TEXT_EMBEDDING function to generate embeddings. The example below uses the imdb review dataset as input.
More details can be found by visiting the documentation page. You can also choose to generate text embeddings using smaller models, namely BERT, NNLM, and SWIVEL. Their generated embeddings offer reduced capacity for encoding the semantic meaning of text, but are more scalable for handling a very large corpus. Check out this public tutorial for more details about how to use them in BigQuery ML.
Build embedding applications in BigQuery ML
With the creation of a text embedding table, we showcase two common applications: classification and a basic version of similarity search.
Sentiment analysis via classification
Let’s take a look at how to build a logistic regression model that predicts the sentiment (positive or negative) of an IMDB review using embeddings generated from the NNLM model, combined with the original data column reviewer_rating.
Once the model is created, you can call ML.PREDICT to obtain sentiment of a review and ML.EVALUATE for overall model performance. One thing to highlight is that text input needs to be transformed to embedding first before feeding into the model. Below is an example of ML.PREDICT query:
Check out this tutorial for more details.
Basic similarity search via clustering
Another example we introduce is training a K-means model to partition the search space for a basic approximate search use case.
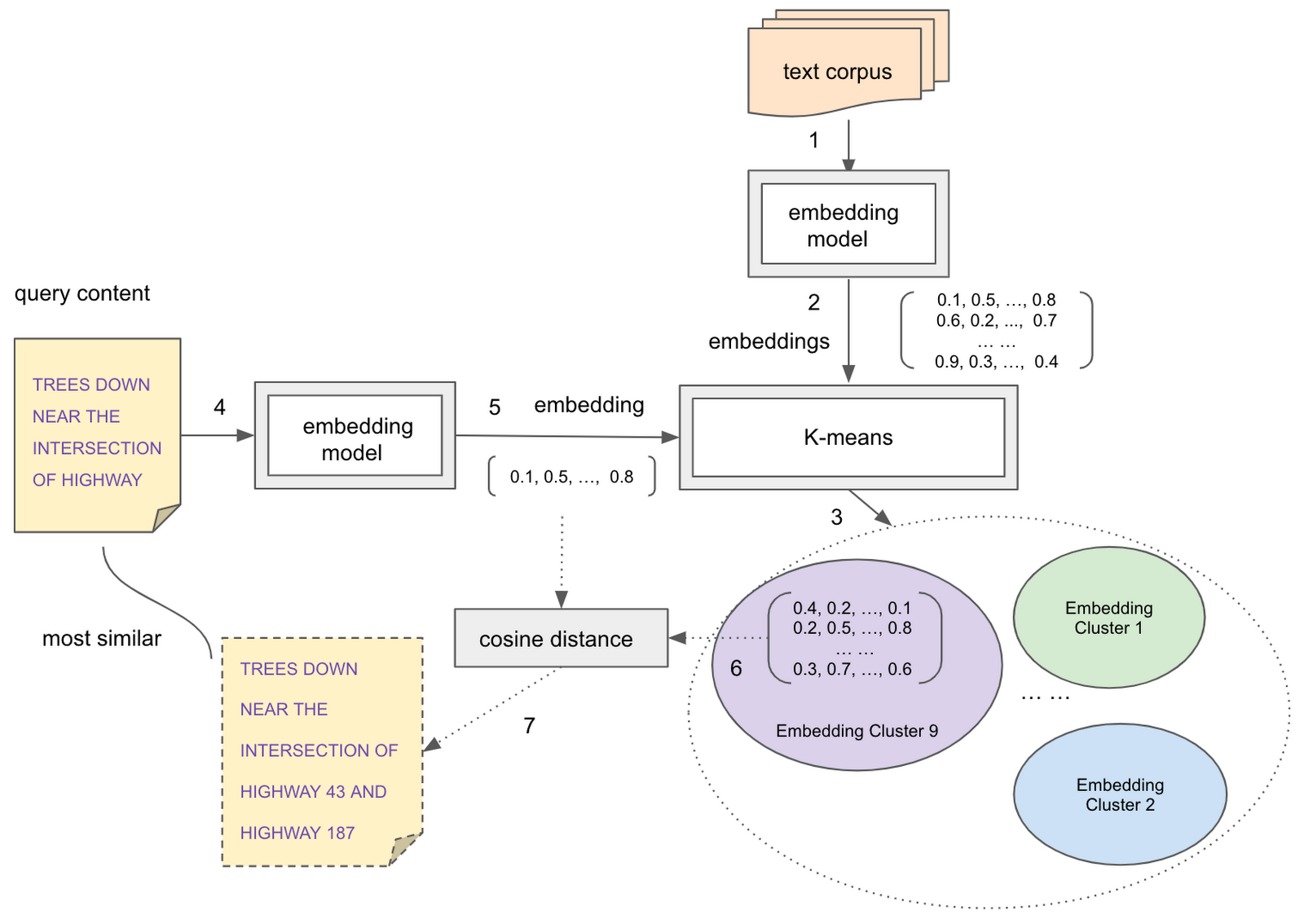
Back in 2020, we wrote a blog that presented an approach to do document similarity search and clustering, leveraging an open-source embedding model and a workaround to use embeddings for model training. Today, you can accomplish the search task with a more streamlined and concise SQL syntax.
To better illustrate, we use the same wind_reports public dataset. Assuming we have used the above textembedding-gecko model to generate embeddings for the “reports'' text column, we obtain a new table named semantic_search_tutorial.wind_reports_embedding that has embeddings and original data.
Next, we train a K-means model to partition the search space.
The next step is to use the ML.PREDICT function with the above trained K-means model and the query embedding to find the K-means cluster that the search candidates reside in. By computing the cosine distance between the query embedding and the embeddings of the search candidate in the predicted cluster, you can get a set of the most similar items to the query item. An example query is shown below.
Check out this tutorial for more details.
What’s next?
BigQuery ML text embedding is publicly available in Preview to unlock powerful capabilities for both embedding generation and downstream application tasks. Check out the tutorial for a comprehensive walkthrough of the above examples. For more details, please refer to the documentation.

