Boost your log analysis with BigQuery vector search and LLMs
Roy Arsan
Cloud Solutions Architect, Google
Omid Fatemieh
Engineering Lead, Google Cloud
We recently launched BigQuery vector search, which enables semantic similarity search in BigQuery. This powerful capability can be used to analyze logs and asset metadata stored in BigQuery tables. For example, given a suspected log entry, your Site Reliability Engineering (SRE) or incident response (IR) team can search for semantically similar logs to validate whether that’s a true anomaly. These searches can be done proactively to auto-triage such anomalies, saving your users time on otherwise lengthy investigations. Furthermore, these relevant search results can provide more complete context for your large language model (LLM) to identify relationships, patterns and nuances that can otherwise be harder to capture with traditional schema-based querying alone. This can accelerate many user workflows — from threat detection and investigation, to network forensics, business insights and application troubleshooting.
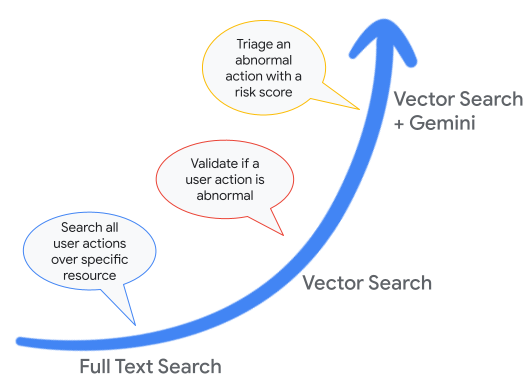
Faster time-to-insights using BigQuery over audit logs
In this blog, we provide an overview of how to use BigQuery’s new vector search capabilities against logs and asset metadata. First, we’ll present key components of this solution. Then we’ll go over a few real-world customer use cases on how to leverage BigQuery vector search over your logs and assets. We’ll also include pointers on how to cost-effectively deploy this at scale.
Vector search vs. text search
While traditional text search relies on matching exact words, or tokens, vector search identifies semantically similar records, by finding closely matching vector embeddings. A vector embedding is a high-dimensional numerical vector that encapsulates the semantic meaning of a given data record (text, image, audio or video file). In the case of logs or assets, the data record is either a log entry (e.g., audit, network, application) or a resource metadata (e.g., asset or policy config change).
BigQuery users can configure and manage search indexes and vector indexes for fast and efficient retrieval. While full-text search indexes yield deterministic results (full recall), vector search with a vector index returns approximate results. This is due to using the Approximate Nearest Neighbor (ANN) search technique, which offers better performance and lower cost in exchange for lower recall.
While text search helps with needle-in-haystack type searches, vector search helps with similarity and outlier-type searches. Both of these search techniques are commonly used for log analytics to answer questions such as the following:
For the rest of this blog, we’ll focus on a few illustrative examples on how you can use vector search on logs data, including retrieval-augmented generation (RAG).
From semi-structured back to unstructured data
In addition to the classic challenges of big data (notably the 4 Vs of data — volume, variety, velocity and variability), analyzing logs involves making sense of their complex semi-structured format. Logs are often composed of deeply nested fields and non-uniform payloads like JSON. A typical organization can have billions of log entries with hundreds or thousands of different log payload formats.
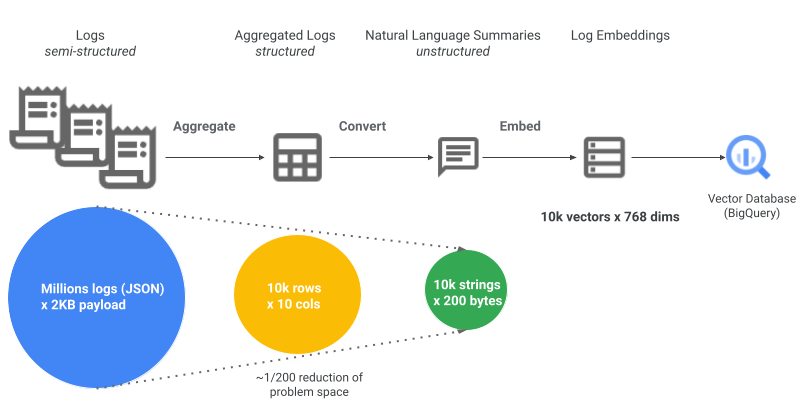
To handle the massive volume of logs and to make them embedding-friendly, this solution employs two key steps as depicted in the above architecture diagram:
-
Aggregation reduces data volume by combining multiple log entries into one. So instead of analyzing individual log entries, user actions can be grouped into a single entry per hour/day. For instance, a particular action done 20 times by a user on a given day (and therefore logged 20 times), can be coalesced into one record, achieving 20:1 reduction in space.
-
NL Conversion: Additionally, converting verbose semi-structured JSON log payloads into simple natural language log summaries further reduces data volume. This conversion makes it easier to generate embeddings from the textual data, and to subsequently query with vector search. For instance, a 2KB audit log entry can be condensed into a 200-character sentence that semantically explains what this audit log entry means, achieving 10:1 additional reduction in space.
As an example, here are SQL samples (in Dataform SQLX) to process Cloud Audit Logs:
-
SQL query to aggregate and convert Cloud Audit Logs into log summaries
-
SQL query to generate embeddings for those log summaries. This query also sets up the vector index over the embeddings column.
The natural language log summaries, alongside their embeddings, allow a subsequent LLM application to better understand and capture nuances that are otherwise harder to represent using structured or semi-structured raw data alone. We will demonstrate this in the next section. The raw logs can still be retained and referenced in the source log bucket or BigQuery dataset.
It's important to note that the exact parameters for aggregation and conversion are ultimately dependent on your specific log type and use case. For example, the aggregation interval (10 min vs. 1 hr vs. 1 day) depends on your search lag-time requirements and allowable time-precision loss. Similarly, the conversion step requires carefully selecting the most relevant log fields to extract — this is typically done by a subject matter expert who’s familiar with that particular log type. Careful planning and configuration of both aggregation and conversion steps will help you strike the right balance between reducing log volume and maintaining the ability to identify meaningful patterns and insights.
Real-world applications

Now, let’s demonstrate how to use BigQuery SQL function VECTOR_SEARCH in SQL queries that you can try on your own. The examples below assume the logs are already preprocessed (aggregated, converted, and embedded) into a table of historical logs called actions_summary_embeddings, as implemented in this sample Dataform repo.
-
Example 1 uses vector search to validate potential anomalies against the historical logs. The test dataset (potential anomalies) is stored in table
actions_summary_embeddings_suspected. -
Example 2 uses vector search to find rule violations throughout our historical logs. Notice how the rule is expressed in natural language, and embedded dynamically.
-
Examples 3 and 4 are more complex uses of vector search: example 3 uses subsequent logic to triage anomalies based on nearest neighbor results like number and distance of matches, while example 4 uses nearest neighbor results to augment the LLM in-context prompt (RAG) and have the LLM such as Gemini reason and triage anomalies for us.
Note: Solutions built based on embeddings, vector search, and LLM inference are inherently probabilistic and approximate. Consider evaluating the recall rate of your vector searches and other metrics based on your higher-level task’s objectives and risk tolerance.
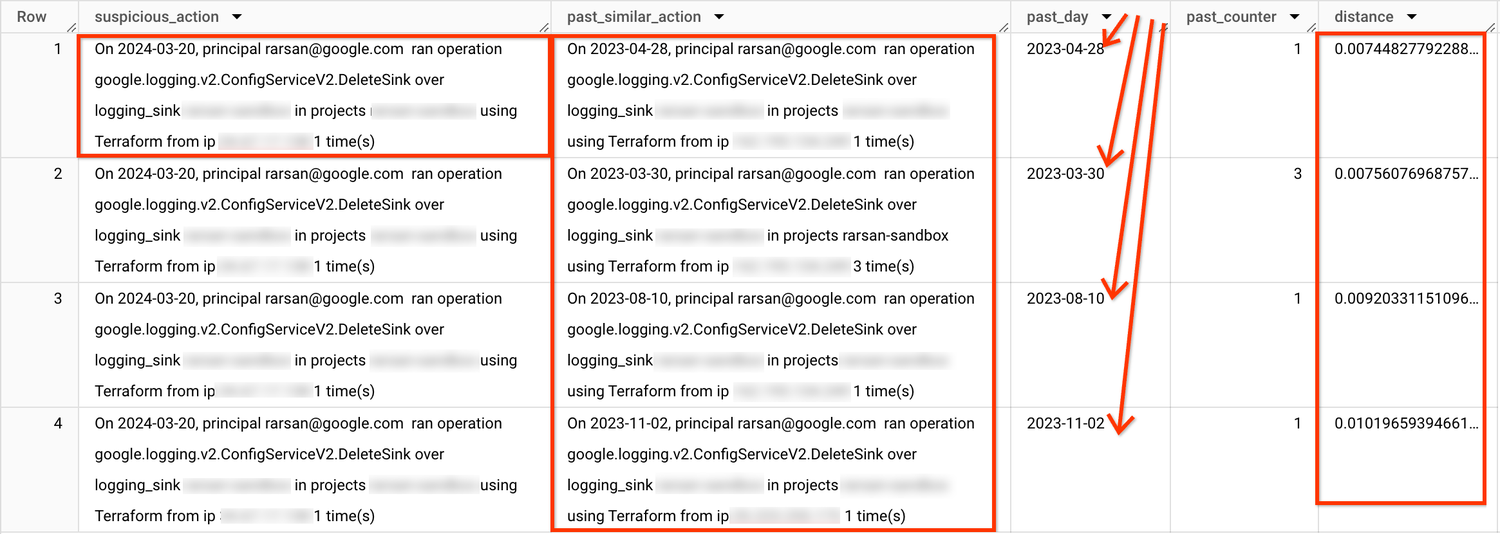
1) Validate anomalies using vector search (outlier detection)
Example results:
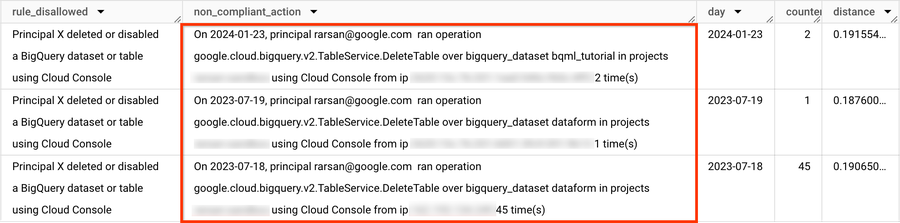
2) Search policy violations using vector search (similarity search)
Example results:
3) Triage anomalies using vector search with rule-based logic
Example results:
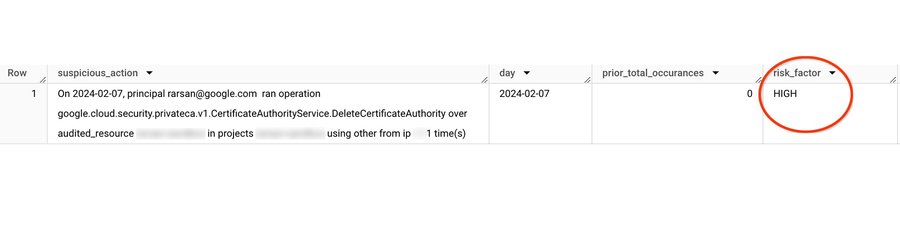
4) Triage anomalies using vector search with LLM reasoning (RAG)
Example output (exported to Google Sheets) showing the prompt enriched with vector search results and the generated LLM response:

Generated LLM response copied below for clarity:
**Low risk.**
- The principal ([email protected]) has performed the same operation (google.logging.v2.ConfigServiceV2.DeleteSink) on the same logging sink (<redacted>) in the same project (<redacted>) multiple times in the past using Terraform.
- The IP address (<redacted>) used in the suspected administrative action is not significantly different from the IP addresses (<redacted> and <redacted>) used in previous administrative actions.
- The frequency of the suspected administrative action (1 time) is consistent with the frequency of previous administrative actions (1 time, 3 times, 1 time, and 1 time).
A note about scale, cost and performance
Vector search, like full-text search, employs a specialized index to enhance performance. By using a vector index, vector search queries can efficiently search embeddings, leading to faster response times and reduced data scanning or slot usage. However, this increased efficiency comes with the trade-off of potentially returning less precise results.
For example, consider a project with 50GB worth of audit logs over the last 12 months. Assuming 2KB average payload of an audit log entry, this translates to about 25M log records. By employing the aforementioned methods of reducing log volume, we can achieve a two-to-three orders of magnitude reduction in volume:
-
25M log entries @ 2KB/each → 1.25M (aggregated) logs @ 200 bytes/each
-
50GB raw logs → ~240MB log embeddings
That’s roughly the size of your vector index. This means fast (1-2 seconds) and cost-effective semantic search over the 12-months lookback.
Now, let’s assume the 50GB of logs are ingested daily. For a one-year retention, this translates to a total of 17TB of raw log data, but only 81.72GB of log embeddings. This is far less data volume to store and search in BigQuery using a fully-managed vector index.
Try BigQuery vector search today
In summary, BigQuery has evolved into a comprehensive platform offering not just robust data analytics, but also integrated full-text and vector search. This is particularly useful in the context of log analytics including detecting and investigating anomalies. Semantic search, powered by vector search, broadens the types of questions you can ask of your data and accelerates the time to get to insights. Additionally, by leveraging vector search for information retrieval within a RAG architecture, you can develop sophisticated LLM-powered applications that keep pace with the increasing volume of logs and potential security threats.
To experiment with BigQuery vector search over your audit logs, try this Log Anomaly Detection & Investigation notebook, which provides a step-by-step walkthrough of log preparation, querying, and visualization. To deploy the solution described in this blog, you can use this BigQuery Dataform repo which automates the end-to-end data pipeline. All the steps including log aggregation, conversion and embeddings generation are codified in SQL queries and periodically executed using Dataform scheduled workflow. Using Dataform is the fastest way to customize, deploy and evaluate this solution for your use case and for your logs in log analytics or BigQuery.

