Introduction to Chainer 11 may,2018
•
12 likes•305,451 views

Published on 11 may, 2018 Chainer is a deep learning framework which is flexible, intuitive, and powerful. This slide introduces some unique features of Chainer and its additional packages such as ChainerMN (distributed learning), ChainerCV (computer vision), ChainerRL (reinforcement learning), Chainer Chemistry (biology and chemistry), and ChainerUI (visualization).







![Training models
model = LeNet5()
model = L.Classifier(model)
# Dataset is a list! ([] to access, having __len__)
dataset = [(x1, t1), (x2, t2), ...]
# iterator to return a mini-batch retrieved from dataset
it = iterators.SerialIterator(dataset, batchsize=32)
# Optimization methods (you can easily try various methods by changing SGD to
# MomentumSGD, Adam, RMSprop, AdaGrad, etc.)
opt = optimizers.SGD(lr=0.01)
opt.setup(model)
updater = training.StandardUpdater(it, opt, device=0) # device=-1 if you use CPU
trainer = training.Trainer(updater, stop_trigger=(100, 'epoch'))
trainer.run()
For more details, refer to official examples: https://github.com/pfnet/chainer/tree/master/examples](https://image.slidesharecdn.com/introductiontochainer11may2018-180512001553/85/Introduction-to-Chainer-11-may-2018-13-320.jpg)

![● How to write custom kernels: https://docs-cupy.chainer.org/en/latest/tutorial/kernel.html
● Custom kernel example: https://github.com/cupy/cupy/tree/master/examples/gemm
● Example: element-wise kernel to compute: f(x, y) = (x − y)^2
Write you own CUDA kernel with CuPy
Usage (note that broadcasting is supported):
>>> x = cp.arange(10, dtype=np.float32).reshape(2, 5)
>>> squared_diff(x, 5)
array([[ 25., 16., 9., 4., 1.],
[ 0., 1., 4., 9., 16.]], dtype=float32)
Code:
>>> squared_diff = cp.ElementwiseKernel(
... 'float32 x, float32 y',
... 'float32 z',
... 'z = (x - y) * (x - y)',
... 'squared_diff')](https://image.slidesharecdn.com/introductiontochainer11may2018-180512001553/85/Introduction-to-Chainer-11-may-2018-16-320.jpg)






























![Chainer Model Export
tfchain: TensorFlow export (experimental)
Caffe-export
• https://github.com/mitmul/tfchain
• Supports Linear, Convolution2D, MaxPooling2D, ReLU
• Just add @totf decorator right before the forward method of the model
import chainer
import chainer.functions as F
import chainer.links as L
import numpy as np
from chainer.exporters import caffe
model = chainer.Sequential(
L.Linear(None, 10),
F.relu,
L.Linear(10, 10)
F.relu,
L.Linear(10, 10)
)
x = chainer.Variable(
x.random.rand(1, 10).astype('f'))
caffe.export(model, [x], './, True)](https://image.slidesharecdn.com/introductiontochainer11may2018-180512001553/85/Introduction-to-Chainer-11-may-2018-61-320.jpg)





Introduction to Chainer 11 may,2018
- 1. Last update: 11 May, 2018
- 2. Chainer – a deep learning framework Chainer is a Python framework that lets researchers quickly implement, train, and evaluate deep learning models. Designing a network Training, evaluation Data set
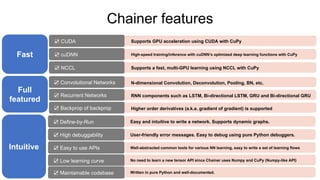
- 3. Written in pure Python and well-documented. No need to learn a new tensor API since Chainer uses Numpy and CuPy (Numpy-like API) User-friendly error messages. Easy to debug using pure Python debuggers. Easy and intuitive to write a network. Supports dynamic graphs. Chainer features Fast ☑ CUDA ☑ cuDNN ☑ NCCL Full featured ☑ Convolutional Networks ☑ Recurrent Networks ☑ Backprop of backprop Intuitive ☑ Define-by-Run ☑ High debuggability Supports GPU acceleration using CUDA with CuPy High-speed training/inference with cuDNN’s optimized deep learning functions with CuPy Supports a fast, multi-GPU learning using NCCL with CuPy N-dimensional Convolution, Deconvolution, Pooling, BN, etc. RNN components such as LSTM, Bi-directional LSTM, GRU and Bi-directional GRU Higher order derivatives (a.k.a. gradient of gradient) is supported Well-abstracted common tools for various NN learning, easy to write a set of learning flows☑ Easy to use APIs ☑ Low learning curve ☑ Maintainable codebase
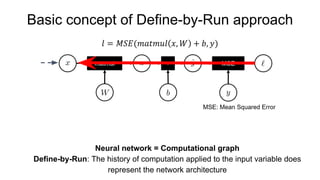
- 4. Basic concept of Define-by-Run approach Neural network = Computational graph Define-by-Run: The history of computation applied to the input variable does represent the network architecture
- 5. Basic concept of Define-by-Run approach Neural network = Computational graph Define-by-Run: The history of computation applied to the input variable does represent the network architecture
- 6. Basic concept of Define-by-Run approach Neural network = Computational graph Define-by-Run: The history of computation applied to the input variable does represent the network architecture
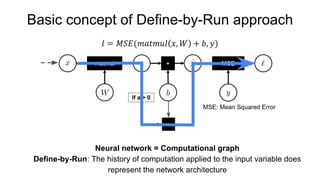
- 7. Basic concept of Define-by-Run approach Neural network = Computational graph Define-by-Run: The history of computation applied to the input variable does represent the network architecture * if a > 0
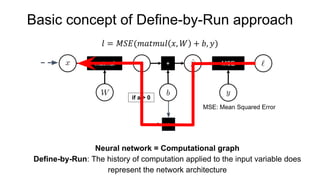
- 8. Basic concept of Define-by-Run approach Neural network = Computational graph Define-by-Run: The history of computation applied to the input variable does represent the network architecture * if a > 0
- 9. Basic concept of Define-by-Run approach Neural network = Computational graph Define-by-Run: The history of computation applied to the input variable does represent the network architecture * if a > 0
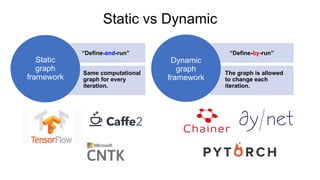
- 10. Static vs Dynamic “Define-and-run” Same computational graph for every iteration. Static graph framework The graph is allowed to change each iteration. “Define-by-run” Dynamic graph framework
- 11. Define-and-Run and Define-by-Run # Define the (static) graph x = Variable(‘x’) y = Variable(‘y’) z = x + 2 * y # Evaluation (z represents a graph) for xi, yi in data: eval(z, (xi, yi)) # Build, evaluate at the same time for xi, yi in data: x = Variable(xi) y = Variable(yi) if y > 0: z = x + 2 * y else: z = x - y You can conditionally perform different forward computations depending on the data Define-and-Run Define-by-Run Easy to optimize, but difficult to change behavior depending on the data
- 12. How to write a convolutional network in Chainer import chainer import chainer.links as L import chainer.functions as F class LeNet5(chainer.Chain): def __init__(self): super(LeNet5, self).__init__() with self.init_scope(): self.conv1 = L.Convolution2D(1, 6, 5, 1) self.conv2 = L.Convolution2D(6, 16, 5, 1) self.conv3 = L.Convolution2D(16, 120, 4, 1) self.fc4 = L.Linear(None, 84) self.fc5 = L.Linear(84, 10) • Start writing a model by inheriting Chain class • Register parametric layers inside the init_scope • Write forward computation in __call__ method (no need to write backward computation) def __call__(self, x): h = F.sigmoid(self.conv1(x)) h = F.max_pooling_2d(h, 2, 2) h = F.sigmoid(self.conv2(h)) h = F.max_pooling_2d(h, 2, 2) h = F.sigmoid(self.conv3(h)) h = F.sigmoid(self.fc4(h)) return self.fc5(h)
- 13. Training models model = LeNet5() model = L.Classifier(model) # Dataset is a list! ([] to access, having __len__) dataset = [(x1, t1), (x2, t2), ...] # iterator to return a mini-batch retrieved from dataset it = iterators.SerialIterator(dataset, batchsize=32) # Optimization methods (you can easily try various methods by changing SGD to # MomentumSGD, Adam, RMSprop, AdaGrad, etc.) opt = optimizers.SGD(lr=0.01) opt.setup(model) updater = training.StandardUpdater(it, opt, device=0) # device=-1 if you use CPU trainer = training.Trainer(updater, stop_trigger=(100, 'epoch')) trainer.run() For more details, refer to official examples: https://github.com/pfnet/chainer/tree/master/examples
- 14. Define-by-Run brings flexibility and intuitiveness “Forward computation” becomes a definition of network • Depending on data, it is easy to change a network structure (e.g. conditionally, stochastically, etc.) • You can define a network itself by Python code =The network structure can be treated as a program instead of data. For Chainer, the “forward computation” can be written in Python • Enables you to write a network structure freely using the syntax of Python • Define-by-Run makes it easy to insert any process like putting a print statement between network computations (In case of define-and-run which compiles a network, this kind of debugging is difficult) • Easy to reuse code of the same network for other purposes with few changes (e.g. by just adding a conditional branch partially) • Easy to check intermediate values and the design of the network itself using external debugging tools etc.
- 15. CuPy - Drop-in replacement of NumPy for GPU acceleration Independent library to handle all GPU calculations in Chainer Lower cost to migrate CPU code to GPU with NumPy-compatible API GPU-execute linear algebra algorithms such as a singular value decomposition Rich in examples such as KMeans, Gaussian Mixture Model import numpy as np x = np.random.rand(10) W = np.random.rand(10, 5) y = np.dot(x, W) import cupy as cp x = cp.random.rand(10) W = cp.random.rand(10, 5) y = cp.dot(x, W) GPU https://github.com/cupy/cupy
- 16. ● How to write custom kernels: https://docs-cupy.chainer.org/en/latest/tutorial/kernel.html ● Custom kernel example: https://github.com/cupy/cupy/tree/master/examples/gemm ● Example: element-wise kernel to compute: f(x, y) = (x − y)^2 Write you own CUDA kernel with CuPy Usage (note that broadcasting is supported): >>> x = cp.arange(10, dtype=np.float32).reshape(2, 5) >>> squared_diff(x, 5) array([[ 25., 16., 9., 4., 1.], [ 0., 1., 4., 9., 16.]], dtype=float32) Code: >>> squared_diff = cp.ElementwiseKernel( ... 'float32 x, float32 y', ... 'float32 z', ... 'z = (x - y) * (x - y)', ... 'squared_diff')
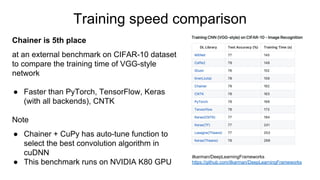
- 17. Training speed comparison ilkarman/DeepLearningFrameworks https://github.com/ilkarman/DeepLearningFrameworks Chainer is 5th place at an external benchmark on CIFAR-10 dataset to compare the training time of VGG-style network ● Faster than PyTorch, TensorFlow, Keras (with all backends), CNTK Note ● Chainer + CuPy has auto-tune function to select the best convolution algorithm in cuDNN ● This benchmark runs on NVIDIA K80 GPU
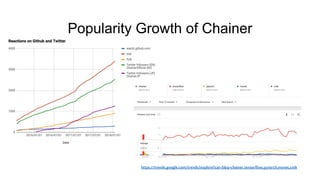
- 18. Popularity Growth of Chainer https://trends.google.com/trends/explore?cat=5&q=chainer,tensorflow,pytorch,mxnet,cntk
- 19. Chainer comes with several examples of models such as ● Natural language processing: RNNs, Recursive nets, Word2Vec, Seq2Seq, etc. ● Image classification: various convnets for MNIST, CIFAR10, ImageNet ● Generative models: VAE, DCGAN For details, see https://github.com/chainer/chainer/tree/master/examples Additional models such as chainer-gan-lib can be found on pfnet-research: https://github.com/pfnet-research/chainer-gan-lib A large number of external examples are also available: https://github.com/chainer/chainer/wiki/External-examples Chainer examples
- 20. pomegranate (probabilistic models): https://github.com/jmschrei/pomegranate PyINN (fused PyTorch ops in CuPy): https://github.com/szagoruyko/pyinn Vanilla LSTM with CuPy (no Chainer, easily and quickly ported from NumPy): https://github.com/mitmul/chainer-notebooks/blob/master/9_vanilla-LSTM-with-cupy.ipynb QRNN for PyTorch (uses CuPy for custom kernel) https://github.com/salesforce/pytorch-qrnn External projects/examples using CuPy
- 21. Add-on packages for Chainer Distributed deep learning, deep reinforcement learning, computer vision ChainerMN (Multi-Node): additional package for distributed deep learning High scalability (100 times faster with 128GPU) ChainerRL: deep reinforcement learning library DQN, DDPG, A3C, ACER, NSQ, PCL, etc. OpenAI Gym support ChainerCV: provides image recognition algorithms, dataset wrappers Faster R-CNN, Single Shot Multibox Detector (SSD), SegNet, etc.
- 22. ChainerMN: Multi-Node training Keeping the easy-to-use characteristics of Chainer as is, ChainerMN enables to use multiple nodes which have multiple GPUs easily to make training faster GPU GPU InfiniBand GPU GPU InfiniBand MPI NVIDIA NCCL
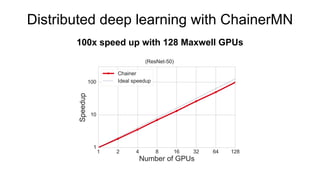
- 23. Distributed deep learning with ChainerMN 100x speed up with 128 Maxwell GPUs
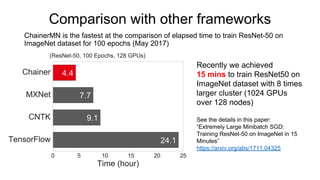
- 24. Comparison with other frameworks ChainerMN is the fastest at the comparison of elapsed time to train ResNet-50 on ImageNet dataset for 100 epochs (May 2017) Recently we achieved 15 mins to train ResNet50 on ImageNet dataset with 8 times larger cluster (1024 GPUs over 128 nodes) See the details in this paper: “Extremely Large Minibatch SGD: Training ResNet-50 on ImageNet in 15 Minutes” https://arxiv.org/abs/1711.04325
- 25. We confirmed that if we increase the number of nodes, the almost same accuracy can be achieved Speedup without dropping the accuracy
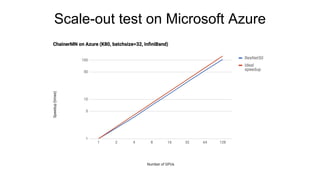
- 26. Scale-out test on Microsoft Azure
- 27. Easy-to-use API of ChainerMN You can start using ChainerMN just by wrapping one line! optimizer = chainer.optimizers.MomentumSGD() optimizer = chainermn.DistributedOptimizer( chainer.optimizers.MomentumSGD())
- 28. Add-on packages for Chainer Distribute deep learning, deep reinforcement learning, computer vision ChainerMN (Multi-Node): additional package for distributed deep learning High scalability (100 times faster with 128GPU) ChainerRL: deep reinforcement learning library DQN, DDPG, A3C, ACER, NSQ, PCL, etc. OpenAI Gym support ChainerCV: provides image recognition algorithms, dataset wrappers Faster R-CNN, Single Shot Multibox Detector (SSD), SegNet, etc.
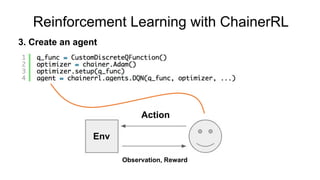
- 29. Reinforcement Learning: ChainerRL: Deep Reinforcement Learning Library Train an agent which interacts with the environment to maximize the rewards Action Env Observation, Reward
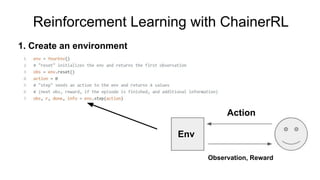
- 30. Reinforcement Learning with ChainerRL 1. Create an environment Action Env Observation, Reward
- 31. Distribution: Softmax, Mellowmax, Gaussian,… Policy: Observation → Distribution of actions 2. Define an agent model Reinforcement Learning with ChainerRL
- 32. 2. Define an agent model (contd.) Q-Function: Observation → Value of each action (expectation of the sum of future rewards) ActionValue: Discrete, Quadratic Reinforcement Learning with ChainerRL
- 33. Action Env Observation, Reward 3. Create an agent Reinforcement Learning with ChainerRL
- 34. 4. Interact with the environment! Reinforcement Learning with ChainerRL
- 35. Algorithms provided by ChainerRL • Deep Q-Network (Mnih et al., 2015) • Double DQN (Hasselt et al., 2016) • Normalized Advantage Function (Gu et al., 2016) • (Persistent) Advantage Learning (Bellemare et al., 2016) • Deep Deterministic Policy Gradient (Lillicrap et al., 2016) • SVG(0) (Heese et al., 2015) • Asynchronous Advantage Actor-Critic (Mnih et al., 2016) • Asynchronous N-step Q-learning (Mnih et al., 2016) • Actor-Critic with Experience Replay (Wang et al., 2017) <- NEW! • Path Consistency Learning (Nachum et al., 2017) <- NEW! • etc.
- 36. ChainerRL Quickstart Guide • Define a Q-function in a Jupyter notebook and learn the Cart Pole Balancing problem with DQN https://github.com/chainer/chainerrl/blob/master/examples/quickstart/quickstart.ipynb
- 37. Add-on packages for Chainer Distribute deep learning, deep reinforcement learning, computer vision ChainerMN (Multi-Node): additional package for distributed deep learning High scalability (100 times faster with 128GPU) ChainerRL: deep reinforcement learning library DQN, DDPG, A3C, ACER, NSQ, PCL, etc. OpenAI Gym support ChainerCV: provides image recognition algorithms, dataset wrappers Faster R-CNN, Single Shot Multibox Detector (SSD), SegNet, etc.
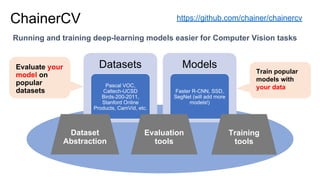
- 38. Evaluate your model on popular datasets Running and training deep-learning models easier for Computer Vision tasks ChainerCV https://github.com/chainer/chainercv Datasets Pascal VOC, Caltech-UCSD Birds-200-2011, Stanford Online Products, CamVid, etc. Models Faster R-CNN, SSD, SegNet (will add more models!) Training tools Evaluation tools Dataset Abstraction Train popular models with your data
- 39. Start computer vision research using deep learning much easier ChainerCV Latest algorithms with your data Provide complete model code, training code, inference code for segmentation algorithms (SegNet, etc.) and object detection algorithms (Faster R-CNN, SSD, etc.), and so on All code is confirmed to reproduce the results All training code and model code reproduced the experimental results shown in the original paper
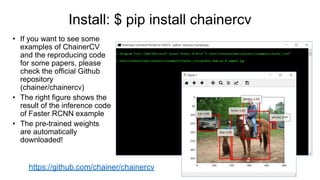
- 40. • If you want to see some examples of ChainerCV and the reproducing code for some papers, please check the official Github repository (chainer/chainercv) • The right figure shows the result of the inference code of Faster RCNN example • The pre-trained weights are automatically downloaded! https://github.com/chainer/chainercv Install: $ pip install chainercv
- 41. • • → ←
- 42. • • •
- 43. ChainerUI ChainerUI is a visualization and experiment management tool for Chainer Install: $ pip install chainerui ● You can compare the effect of different hyperparameters visually by loss curves and the scores in the table ● You can change the learning rate dynamically during training See the details in: https://github.com/chainer/chainerui
- 44. Chainer Chemistry Chainer Chemisry is a collection of tools for training neural networks on biology and chemistry tasks using Chainer Install: $ pip install chainer-chemistry ● It currently provides widely used graph convolution implementation: ○ NFP: Neural fingerprint ○ GGNN: Gated Graph Neural Network ○ Weave ○ SchNet See the details in: https://github.com/pfnet-research/chainer-chemistry
- 45. Summary • Chainer is a deep learning framework focusing on flexibility • There are 5 additional packages for specific task/domain: • ChainerMN - Distributed learning • ChainerRL - Reinforcement learning • ChainerCV - Computer vision • ChainerUI - Visualization and experiment management • Chainer Chemistry - Graph convolutions for biology/chemistry tasks
- 46. Intel Chainer
- 47. Intel Chainer with MKL-DNN Backend CPU CuPy NVIDIA GPU CUDA cuDNN BLAS NumPy Chainer MKL-DNN Intel Xeon/Xeon Phi MKL
- 48. Intel Chainer with MKL-DNN Backend MKL-DNN • Neural Network library optimized for Intel architectures • Supported CPUs: ✓ Intel Atom(R) processor with Intel(R) SSE4.1 support ✓ 4th, 5th, 6th and 7th generation Intel(R) Core processor ✓ Intel(R) Xeon(R) processor E5 v3 family (code named Haswell) ✓ Intel(R) Xeon(R) processor E5 v4 family (code named Broadwell) ✓ Intel(R) Xeon(R) Platinum processor family (code name Skylake) ✓ Intel(R) Xeon Phi(TM) product family x200 (code named Knights Landing) ✓ Future Intel(R) Xeon Phi(TM) processor (code named Knights Mill) • MKL-DNN accelerates the computation of NN on the above CPUs
- 49. Intel Chainer with MKL-DNN Backend convnet-benchmarks* result: Intel Chainer Chainer with NumPy (MKL-Build) Alexnet Forward 429.16 ms 5041.91 ms Alexnet Backward 841.73 ms 5569.49 ms Alexnet Total 1270.89 ms 10611.40 ms ~8.35x faster than NumPy backend!
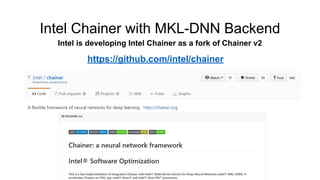
- 50. Intel Chainer with MKL-DNN Backend Intel is developing Intel Chainer as a fork of Chainer v2 https://github.com/intel/chainer
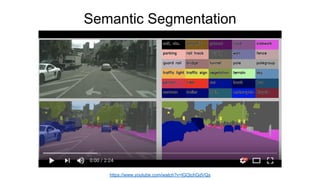
- 53. Semantic Segmentation https://www.youtube.com/watch?v=lGOjchGdVQs
- 54. Ponanza Chainer ● Won the 2nd place at The 27th World Computer Shogi Championship ● Based on Ponanza which was the champion for two years in a row (2015, 2016) ● “Ponanza Chainer” applied Deep Learning for ordering the possible next moves for which “Ponanza” should think ahead deeply ● “Ponanza Chainer” wins “Ponanza” with a probability of 80% Team PFN Issei Yamamoto Akira Shimoyama Team Ponanza
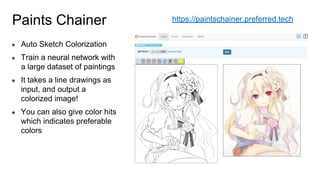
- 55. Paints Chainer ● Auto Sketch Colorization ● Train a neural network with a large dataset of paintings ● It takes a line drawings as input, and output a colorized image! ● You can also give color hits which indicates preferable colors https://paintschainer.preferred.tech
- 57. 1. Install CUDA Toolkit 8.0 https://developer.nvidia.com/cuda-downloads 2. Install cuDNN v6.0 Library https://developer.nvidia.com/rdp/cudnn-download 3. Install NCCL for Multi-GPUs https://github.com/NVIDIA/nccl 4. Install CuPy and Chainer % pip install cupy % pip install chainer Chainer on Ubuntu For more details, see the official installation guide: http://docs.chainer.org/en/stable/install.html
- 58. Chainer on Windows with NVIDIA GPU 1. Install Visual C++ 2015 Build Tools http://landinghub.visualstudio.com/visual-cpp-build-tools 2. Install CUDA Toolkit 8.0 https://developer.nvidia.com/cuda-downloads 3. Install cuDNN v6.0 Library for Windows 10 https://developer.nvidia.com/rdp/cudnn-download Put all files under C:Program FilesNVIDIA GPU Computing ToolkitCUDAv8.0 4. Install Anaconda 4.3.1 Python 3.6 or 2.7 https://www.continuum.io/downloads 5. Add environmental variables - Add “C:Program Files (x86)Microsoft Visual Studio 14.0VCbin” to PATH variable - Add “C:Program Files (x86)Windows Kits10Include10.0.10240.0ucrt” to INCLUDE variable 6. Install Chainer on Anaconda Prompt > pip install cupy > pip install chainer Note: If Visual C++ 2017 was previously installed, some additional steps might be required. In that case, please visit our support channels for help.
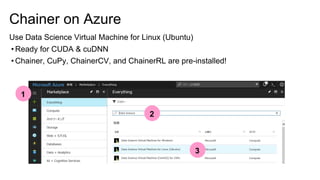
- 59. Chainer on Azure Use Data Science Virtual Machine for Linux (Ubuntu) • Ready for CUDA & cuDNN • Chainer, CuPy, ChainerCV, and ChainerRL are pre-installed! 1 2 3
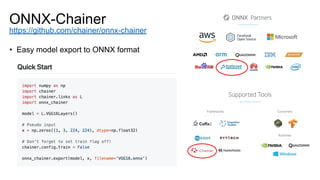
- 60. • Easy model export to ONNX format ONNX-Chainer https://github.com/chainer/onnx-chainer
- 61. Chainer Model Export tfchain: TensorFlow export (experimental) Caffe-export • https://github.com/mitmul/tfchain • Supports Linear, Convolution2D, MaxPooling2D, ReLU • Just add @totf decorator right before the forward method of the model import chainer import chainer.functions as F import chainer.links as L import numpy as np from chainer.exporters import caffe model = chainer.Sequential( L.Linear(None, 10), F.relu, L.Linear(10, 10) F.relu, L.Linear(10, 10) ) x = chainer.Variable( x.random.rand(1, 10).astype('f')) caffe.export(model, [x], './, True)
- 62. External Projects for Model Portability DLPack • https://mil-tokyo.github.io/webdnn/ • The model conversion to run it on a web browser supports Chainer WebDNN • https://github.com/dmlc/dlpa ck • MXNet, Torch, Caffe2 have joined to discuss the guideline of memory layout of tensor and the common operator interfaces
- 64. The Chainer project is now supported by these Leading computing companies
- 66. Chainer is an open-source project. • You can send a PR from here: https://github.com/chainer/chainer • The development speed of Deep Learning research is super fast, therefore, to provide the state-of-the-art technologies through Chainer, we continuously update the development plans: • Chainer v3.0.0 will be released on 26th September! • Will support gradient of gradient (higher order differentiation) • Will add the official Windows support ensured by Microsoft The release schedule after v2.0.1 (4th July)→
- 67. ● Started as a fork of Chainer. API is similar to Chainer. ● Codebase is written in a combination of Python, C, C++ -> More complicated codebase than Chainer but can also be faster in some cases. ● Uses familiar Torch tensor API. Easy for torch users but requires extra learning curve for NumPy users. Conversion functions sometimes needed. Comparison of Chainer with PyTorch ● Codebase is written entirely in Python and therefore accessible to researchers who are not familiar with C/C++ -> Keep codebase in pure Python if possible. Value an easily understandable and maintainable codebase over extreme performance in all cases. ● Uses familiar Numpy API: Numpy (CPU) or CuPy (GPU). ● Easy to write custom GPU kernels in Chainer using CuPy. ● CuPy makes it easy for researchers to write custom CUDA kernels. Chainer PyTorch So, the differences are mostly in the array libraries and different philosophies on how to achieve the best balance between performance optimizations and maintainability and flexibility of the core codebase.