Trois mois, 30 fois plus de demande : comment nous avons fait évoluer Google Meet dans le contexte du COVID-19

Samantha Schaevitz
Staff Site Reliability Engineer
Découvrez comment Google Cloud a augmenté sa capacité pour répondre aux fortes demandes d'utilisation de Google Meet dans le contexte du COVID-19.
Essayer Google Workspace
Obtenez une adresse e-mail professionnelle, tout l'espace de stockage dont vous avez besoin, des fonctionnalités de visioconférence et bien plus encore.
EssayerLe COVID-19 ayant peu à peu obligé le monde entier à garder ses distances, de nombreuses personnes se sont tournées vers la visioconférence en ligne pour rester en contact avec leurs proches, leurs élèves ou enseignants, et leurs collègues. Comme le montre le graphique ci-dessous, ce changement a généré une très importante augmentation du nombre d'utilisateurs sur Google Meet.

Le nombre de sessions par continent en période de pic a dicté la capacité de diffusion qu'il nous fallait avoir à disposition
Dans cet article, je vais vous expliquer comment nous nous sommes assurés que Meet ait une capacité de service disponible suffisante pour supporter la multiplication par 30 de son utilisation en raison du COVID-19. Je détaillerai également les mesures que nous avons prises pour rendre cette croissance viable d'un point de vue technique et opérationnel, grâce à un certain nombre de bonnes pratiques d'ingénierie en fiabilité des sites (SRE).
Les premières alertes
Alors que le monde découvrait progressivement le COVID-19, les individus ont commencé à adapter leurs habitudes au quotidien. L'impact grandissant du virus sur les modes de travail, l'enseignement et les relations sociales s'est traduit par une augmentation croissante de l'utilisation de services comme Google Meet pour pouvoir rester en contact. Le 17 février, l'équipe d'ingénierie SRE de Meet a reçu les premières alertes indiquant des problèmes de capacité au niveau régional.
Les alertes étaient symptomatiques ou issues de surveillance par boîte noire, et renvoyaient des messages comme "Trop d'échecs de tâches" et "Délestage de charge trop élevé". Les services de Google directement accessibles aux utilisateurs étant développés avec de la redondance, ces alertes ne correspondaient pas à des problèmes en cours visibles par les utilisateurs. Cependant, il est vite devenu clair que l'utilisation du produit en Asie était en forte hausse.
L'équipe d'ingénierie SRE a commencé à travailler avec l'équipe de planification de la capacité afin de trouver des ressources supplémentaires et de gérer cette augmentation, mais il nous a paru évident qu'il fallait voir encore plus loin, dans l'éventualité d'une progression de l'épidémie en dehors de la région.
Et effectivement, l'Italie a entamé un confinement lié au COVID-19 peu de temps après, entraînant une augmentation progressive de l'utilisation de Meet dans ce pays.
Un incident peu conventionnel
C'est à ce moment-là que nous avons commencé à mettre une stratégie en place. Comme à son habitude, l'équipe d'ingénierie SRE a commencé par déclarer un incident et par enclencher notre plan de gestion des incidents pour répondre à ce risque de capacité à l'échelle mondiale.
Il faut cependant noter que, même si nous avons abordé ce défi à l'aide de notre framework éprouvé de gestion des incidents, nous n'étions pas à ce moment-là en plein milieu d'une interruption, ni même sur le point d'en avoir une. Il n'y avait aucun impact immédiat sur les utilisateurs. La plupart des effets du COVID-19 sur la société étaient encore inconnus ou difficiles à prévoir. Notre mission était abstraite : il nous fallait éviter de potentielles interruptions pour un produit qui était devenu essentiel à un grand nombre de nouveaux utilisateurs, tout en faisant évoluer le système sans savoir d'où viendrait la croissance ni à quel moment elle se stabiliserait.
En outre, les membres de notre équipe (et tous les employés Google) étaient en train d'effectuer la transition vers une période indéfinie de télétravail due au COVID-19. Même si la plupart de nos flux de travail et outils étaient déjà disponibles en dehors des bureaux, la gestion virtuelle d'un tel incident de longue durée posait des difficultés supplémentaires.
Sans la possibilité de se retrouver dans la même pièce, il devenait important de gérer nos canaux de communication de manière proactive, pour s'assurer de tous pouvoir accéder aux informations nécessaires à la réalisation de nos objectifs. Bon nombre d'entre nous devaient aussi gérer des défis extérieurs au travail, comme s'occuper de leurs proches pendant cette période d'adaptation. Même si ces facteurs présentaient des obstacles supplémentaires pour gérer l'incident, nous avons su les surmonter grâce à des tactiques comme la désignation de remplaçants supplémentaires, ou encore la gestion proactive des responsabilités et des canaux de communication.
Dans tous les cas, nous nous sommes tenus à notre approche de gestion des incidents. Notre première mesure à l'échelle mondiale a été de désigner plusieurs rôles : un chargé d'incidents, un responsable des communications et un responsable des opérations, à la fois en Amérique du Nord et en Europe, pour assurer une gestion 24h/24.
En tant que chargée d'incidents, ma fonction était semblable à celle d'un routeur d'informations avec état, mais un routeur avec des opinions, de l'influence et la capacité de prendre des décisions. Je récoltais des informations sur les problèmes tactiques en suspens, sur le rôle de chacun, et sur les contextes particuliers susceptibles d'influencer notre plan d'intervention (par exemple, les mesures prises par les gouvernements face au COVID-19). Je déléguais ensuite les différentes tâches aux personnes qualifiées. J'identifiais et examinais les zones d'incertitude, qu'il s'agisse de définir un problème ("Est-ce un souci que nous utilisions 50 % de nos processeurs en Amérique du Sud ?) ou de réfléchir à des solutions ("Comment allons-nous accélérer notre processus de mise en service ?"). Puis je coordonnais notre réponse globale et m'assurais que toutes les tâches à effectuer étaient clairement réparties.
Peu après le lancement du projet, nous nous sommes rendu compte que l'étendue de notre mission était colossale et que notre réponse devrait se faire sur le long terme. Pour que le périmètre de chaque contributeur reste gérable, nous avons divisé notre réponse en plusieurs axes de travail semi-indépendants. Dans les cas où les périmètres se chevauchaient, l'intersection entre les axes de travail était clairement définie.

Cliquez sur l'image pour l'agrandir
Nous avons mis en place les axes de travail suivants, illustrés dans le schéma ci-dessus :
● Capacité, dont la fonction était de trouver des ressources et de déterminer quelles proportions du service nous pouvions activer dans quelles régions
● Dépendances, dont les membres collaboraient avec les équipes gérant l'infrastructure de Meet (par exemple les systèmes d'authentification et d'autorisation des comptes Google), afin de s'assurer que ces systèmes disposaient eux aussi de ressources suffisantes pour s'adapter à la hausse d'utilisation
● Goulots d'étranglement, un axe qui se concentrait sur l'identification et la suppression des éléments de notre système pouvant limiter la mise en échelle
● Manœuvres de contrôle, un axe centré sur la création d'atténuations génériques au sein du système en cas d'interruption de la capacité, qu'elle soit imminente ou en cours
● Modifications en production, dont le but était de générer la capacité supplémentaire de manière sécurisée, de redéployer les serveurs avec des réglages améliorés et d'envoyer les nouvelles versions avec des manœuvres de contrôle additionnelles et prêtes à l'emploi
En tant que gestionnaires des incidents, nous devions continuellement réévaluer la validité de notre structure opérationnelle. Le but était d'avoir assez de structure pour opérer de manière efficace, mais pas plus. Si la structure est insuffisante, les gens prennent des décisions sans avoir eu accès aux bonnes informations, mais si elle est trop lourde, ils passent leur temps à prévoir des réunions.
Nous allions courir un marathon, et non un sprint. Tout au long du parcours, nous avons donc régulièrement vérifié si nos collègues avaient besoin d'aide ou devaient faire une pause. C'était essentiel pour éviter le surmenage et pour tenir dans la durée.
Pour prévenir les risques d'épuisement, chaque personne occupant un rôle au sein de l'équipe de gestion des incidents a désigné un collègue comme "remplaçant". Celui-ci participait aux réunions de son collègue responsable principal, avait accès aux documents pertinents, aux listes de diffusion et aux salons de discussion, et posait les questions nécessaires afin de pouvoir suppléer rapidement au responsable principal le cas échéant. Cette approche s'est révélée utile lorsque certains de nos collègues sont tombés malades ou ont dû faire une pause, car leur remplaçant disposait déjà de toutes les informations nécessaires pour être opérationnel sur-le-champ.
Création de notre marge de capacité
Pendant que l'équipe de gestion des incidents essayait de coordonner au mieux le flux d'informations et le travail nécessaires pour résoudre l'incident, la plupart des personnes qui travaillaient sur le projet s'occupaient des risques directement en production.
Notre principale exigence technique était simplement d'avoir une capacité de service supérieure à la demande des utilisateurs de Meet au niveau régional. Google possédant plus de 20 centres de données à travers le monde, nous pouvions nous appuyer sur une infrastructure solide. Nous avons rapidement tiré parti des ressources brutes dont nous disposions déjà, ce qui suffisait pour presque doubler la capacité de service disponible de Meet.
Précédemment, nous nous étions appuyés sur un historique des tendances pour prévoir la capacité qu'il nous faudrait provisionner. Cependant, nous ne pouvions plus nous fier aux extrapolations des données historiques. Nous devions à présent provisionner de la capacité en fonction de prévisions analytiques. Ces modèles devaient être transposés dans des termes que notre équipe chargée des modifications en production puisse utiliser. Les membres de l'axe "capacité" devaient donc traduire le modèle d'utilisation en quantités de processeurs et de RAM nécessaires. La création de ce modèle de traduction nous a ensuite permis d'accélérer la mise en production de la capacité disponible, car nous avons appris à nos outils et à nos processus d'automatisation à le comprendre.
Bientôt, il est devenu clair que simplement doubler notre empreinte ne serait pas suffisant. Nous avons donc commencé à travailler dans la perspective, autrefois impensable, d'une multiplication de nos services par 50.
Réduire les besoins en ressources
En plus d'effectuer une mise à l’échelle à la hausse de notre capacité, nous avons travaillé sur l'identification et la suppression des aspects inefficaces de notre pile de diffusion. La plupart de ces tâches entraient dans l'une des deux catégories suivantes : l'ajustement d'indicateurs binaires et l'allocation de ressources d'une part, et la réécriture de code pour limiter les dépenses d'autre part.
Pour rendre nos instances de serveurs plus économes en ressources, nous avons dû fournir des efforts sur plusieurs plans. Notre objectif pourrait être résumé ainsi : "traiter un maximum de requêtes avec un minimum de ressources, sans sacrifier l'expérience utilisateur ou la fiabilité du système".
Voici quelques-unes des questions que nous nous sommes posées :
● Pouvions-nous faire tourner moins de serveurs en réservant plus de ressources, pour réduire les calculs supplémentaires ?
● Avions-nous réservé plus de RAM ou de processeurs que nécessaire ? Pouvions-nous faire une meilleure utilisation de ces ressources ailleurs ?
● Avions-nous assez de bande passante de sortie en périphérie du réseau pour proposer des flux vidéo dans toutes les régions ?
● Pouvions-nous réduire la quantité de mémoire et de processeurs nécessaires à une certaine instance de serveur en créant des sous-ensembles de serveurs backend ?Même si nous validons toujours les nouveaux profils et configurations de serveurs avant de les mettre en service, à ce moment-là, il nous paraissait important de les réévaluer. Avec l'utilisation accrue de Meet, les caractéristiques d'utilisation ont elles aussi évolué : la durée des réunions, le nombre de participants et le partage du temps d'audio entre ces participants n'étaient plus les mêmes.
Le service Meet nécessitant plus de ressources brutes que jamais, nous nous sommes peu à peu aperçus qu'au lieu de prioriser la gestion des requêtes, un important pourcentage de nos cycles de processeurs était consacré à des opérations supplémentaires, par exemple à maintenir les équilibreurs de charge et les connexions aux systèmes de surveillance.
Afin de booster le débit, c'est-à-dire le nombre de requêtes traitées par un processeur à la seconde, nous avons augmenté les spécifications des ressources consacrées au traitement, à la fois en termes de processeurs et de RAM réservés. Dans ce genre de situation, on parle parfois de l'exécution de tâches "lourdes".
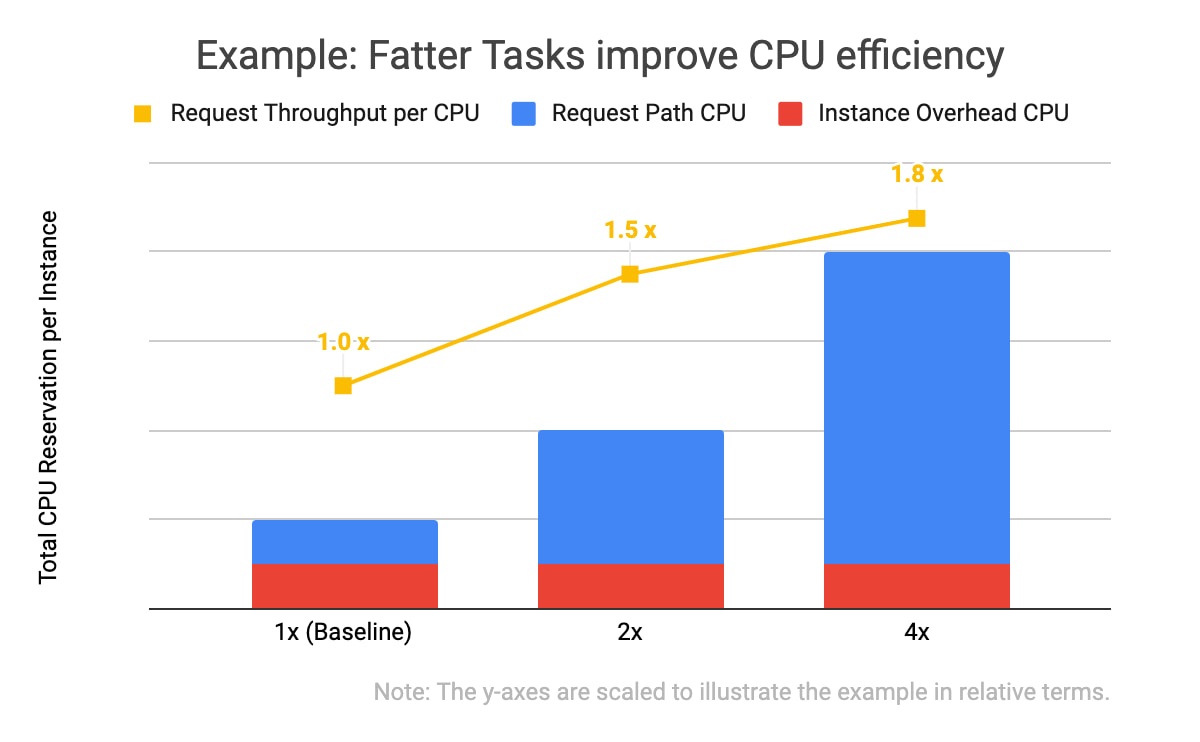
Dans l'exemple illustré ci-dessus, vous remarquerez deux choses : tout d'abord, les trois spécifications d'instances comportent les mêmes calculs supplémentaires (en rouge), et ensuite, plus le nombre global de serveurs réservés pour une instance est élevé, plus le débit des requêtes est important (en jaune). Avec la même quantité globale de serveurs réservés alloués, une instance de profil "x4" peut traiter 1,8 fois plus de requêtes que quatre instances avec un profil de base. C'est parce que le nombre de calculs supplémentaires (comme les entrées persistantes de journaux de débogage, la vérification du bon fonctionnement des canaux de connexion réseau et l'initialisation des classes) ne progresse pas de façon linéaire par rapport au nombre de requêtes entrantes traitées par la tâche.
Nous avons continué à essayer de doubler les réserves de nos tâches de diffusion tout en divisant par deux le nombre de tâches dans notre parc informatique, jusqu'à atteindre une limite dans le scaling limitation d’échelle.
Et bien sûr, il nous fallait tester et valider chacune de ces modifications. Nous avons utilisé des environnements Canary pour vérifier que ces modifications se comportaient comme souhaité, et n'introduisaient ou n'activaient pas de limites jusqu'alors inconnues. De la même manière que nous validons les nouvelles versions de nos serveurs, nous avons vérifié qu'il n'existait aucune régression fonctionnelle ou de performances, et que les effets désirés des modifications étaient bel et bien atteints en production.
Nous avons également apporté des améliorations fonctionnelles à notre codebase. Par exemple, nous avons réécrit un cache distribué en mémoire pour que sa segmentation des entrées dans les instances de tâches soit plus flexible. Cela nous a ensuite permis de stocker plus d'entrées dans une seule région en augmentant le nombre d'instances de serveurs au sein d'un cluster.
Imaginer des sorties de secours
Même si nous étions de plus en plus confiants quant aux prévisions sur la hausse d'utilisation, celles-ci n'étaient toujours pas fiables à 100 %. Que se passerait-il si nous venions à manquer de capacité de diffusion dans une région en particulier ? Ou si nous poussions un certain lien réseau à saturation ? Le but de l'axe de travail "manœuvres de contrôle" était de fournir des réponses satisfaisantes, à défaut d'être parfaites, à ce genre de question. Il nous fallait un plan acceptable pour les cygnes noirs qui pourraient apparaître dans nos consoles.
Un groupe a commencé à identifier et élaborer des contrôles et des sorties de secours en production. Bien sûr, nous espérions ne pas avoir à y recourir. Par exemple, ces manœuvres nous permettraient de passer rapidement d'une qualité vidéo haute définition (celle définie par défaut) à une définition standard à l'arrivée d'un nouveau participant dans une conférence Meet. Cette modification nous ferait gagner un peu de temps pour rectifier le tir en utilisant les autres axes de travail (améliorations du provisionnement et de l'efficacité), sans trop porter atteinte au produit. Les utilisateurs pourraient toujours repasser en vidéo haute définition s'ils le souhaitaient.
Créer, tester et mettre en place un certain nombre de contrôles instrumentés comme celui-là nous a permis d'avoir une marge supplémentaire au cas où nos pires prévisions se révéleraient inexactes, ce qui nous a tranquillisés.
Viabilité des opérations
Cette stratégie structurée a impliqué un grand nombre de Googleurs occupant des postes variés. Cela signifiait que pour continuer à avancer tout au long de l'incident, nous avions besoin d'une coordination poussée et d'une communication intentionnelle.
Tous les jours, nous organisions des réunions de transfert entre nos deux fuseaux horaires, pour les Googleurs basés à Zurich, Stockholm, Kirkland (Washington) et Sunnyvale (Californie). Nos responsables des communications transmettaient les dernières informations à de nombreux collaborateurs au sein de nos équipes produit, direction, infrastructure et service client, pour qu'ils soient au courant de l'état du projet au moment de prendre leurs propres décisions. Les chefs des axes de travail utilisaient Google Docs pour mettre à jour des documents partagés relatant l'état de l'incident. Ils y précisaient les différents risques actuels, les noms des personnes à contacter, les efforts d'atténuation en cours, et y consignaient leurs notes prises lors des réunions.
Cette approche a bien fonctionné au début, mais elle nous a vite paru fastidieuse. Il nous fallait faire passer la durée du cycle de planification de quelques jours à plusieurs semaines afin de réduire sensiblement les heures consacrées à la coordination, et augmenter le temps passé à véritablement atténuer la crise rencontrée.
Notre première tactique a été de créer des modèles de prévision plus efficaces et plus fiables. Cela a permis d'augmenter la prévisibilité et de stabiliser notre cible d'augmentation de la capacité de diffusion sur une semaine, plutôt qu'au jour le jour.
Nous avons également essayé de réduire le nombre de tâches laborieuses nécessaires pour générer de la capacité de diffusion supplémentaire. Nos processus, tout comme les systèmes que nous exploitions, devaient être automatisés.
À ce moment-là, mettre à l'échelle la pile de diffusion de Meet était l'opération en cours qui demandait le plus de travail, en raison tout d'abord du nombre de personnes qui devaient être informées des dernières prévisions et quantités de ressources, et ensuite du nombre d'outils (pas toujours fiables) nécessaires à certaines opérations.

Comme il est souligné dans le schéma du cycle de vie présenté ci-dessus, le meilleur moyen d'automatiser ces tâches était d'apporter des améliorations étape par étape. Nous avons d'abord rassemblé des informations sur les tâches, puis avons commencé par en automatiser certaines parties jusqu'à ce qu'enfin, dans les conditions idéales, le logiciel arrive à effectuer la tâche du début à la fin sans intervention manuelle.
Pour ce faire, nous avons demandé à un certain nombre d'experts en automatisation, appartenant ou non à l'équipe Meet, de se concentrer sur la résolution de cet espace de problème. Voici certains des éléments de travail :
●Rendre un plus grand nombre de services en production réactifs aux modifications grâce à un fichier de configuration testé et faisant autorité
●Renforcer les outils communs pour les adapter aux configurations système uniques à Meet (par exemple, des besoins élevés en termes de bande passante et de mise en réseau à faible latence)
●Ajuster les vérifications de régression, qui étaient devenues moins fiables à mesure que l'échelle du système augmentait
L'automatisation et la codification de ces tâches ont permis de réduire considérablement les opérations manuelles requises pour mettre Meet en service dans un nouveau cluster ou pour déployer une nouvelle version binaire qui aboutirait à des performances améliorées. Lorsque la fin de cet incident de mise à l’échelle est arrivée, nous avions pu pleinement automatiser notre empreinte de capacité par région et par tâche de diffusion, évitant ainsi des centaines d'appels manuels sur des outils de ligne de commande. Cela a permis de libérer du temps et de l'énergie pour un bon nombre d'ingénieurs, qui ont pu travailler sur des problèmes plus difficiles et tout aussi importants.
À cette étape d’intensification de nos opérations, nous avons pu passer à des transferts "hors connexion" entre les différents sites via e-mail, réduisant encore plus le nombre de réunions auxquelles il nous fallait participer. Maintenant que nous avions une stratégie mieux définie et une marge plus importante, nous pouvions passer à un mode d'exécution plus purement tactique.
Peu après, nous avons graduellement dissous notre structure consacrée à l'incident et avons commencé à travailler à peu près comme nous l'aurions fait pour n'importe quel projet au long cours.
Résultats
À la fin de l'incident, Meet comptait plus de 100 millions de personnes participants à des réunions chaque jour. Arriver à ce résultat n'a été ni simple, ni direct. Les scénarios envisagés par l'équipe Meet pendant les tests de gestion des incidents et des situations d'urgence avant le COVID-19 n'avaient pas pris en compte la durée ou l'échelle de l'augmentation de capacité que nous avons eu à gérer. Nous avons donc défini notre stratégie au fur et à mesure.
Nous avons rencontré plusieurs problèmes en cours de route, car nous devions équilibrer les risques d'une façon que nous n'avions jamais envisagée en temps normal. Par exemple, nous avons déployé du nouveau code sur nos serveurs en production en passant moins de temps que d'habitude en phase Canary, car celui-ci contenait des correctifs de performances qui nous permettaient de gagner du temps et de ne pas manquer de capacité disponible au niveau local.
L'une des compétences les plus cruciales que nous ayons affinées pendant les deux mois qu'a duré ce projet est la capacité à cataloguer, quantifier et vérifier les risques et les bénéfices de manière flexible. Chaque jour, nous recevions de nouvelles informations sur les confinements liés au COVID-19, sur de nouveaux clients qui prévoyaient d'utiliser Meet, et sur la capacité disponible en production. Parfois, ces informations rendaient obsolète le travail que nous avions entamé le jour d'avant.
Chaque minute comptait. Nous ne pouvions pas nous permettre d'attribuer la même priorité ou la même urgence à chaque tâche, mais nous ne pouvions pas non plus ignorer nos propres modèles de prévision. Il était hors de question d'attendre des informations parfaites. Nous devions donc faire de notre mieux pour avoir autant de marge que possible, tout en prenant des décisions avisées, mais rapides à partir des données à notre disposition.
Tout ce travail n'a été possible que grâce à nos collaborateurs intelligents et polyvalents, ayant le sens du collectif, qui venaient d'une dizaine d'équipes et occupaient de multiples postes : ingénieurs en fiabilité des sites, chefs de produit, chefs de projet, ingénieurs réseau et membres du service client. Ils ont travaillé tous ensemble pour mener à bien le projet.
Nous étions maintenant bien placés pour envisager la prochaine étape de notre parcours : la mise à disposition gratuite de Meet pour tous les utilisateurs ayant un compte Google. En temps normal, l'ouverture du produit à tous les consommateurs aurait été un effort d’une mise à l’échelle colossale, mais après l'intense travail que nous avions déjà accompli, nous étions prêts à relever le défi.