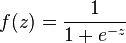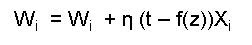Testing Blog
Online Machine Learning Testing == Extreme Testing
Monday, November 24, 2008
Posted by Alek Icev
As you may know our core vision is to build "The perfect search engine that would understand exactly what you mean and give back exactly what you want.". In order to do that we learn from our data, we learn from the past and we love Machine Learning. Everyday we are trying to answer the following questions.
Is this email spam?
Is this search result relevant?
What product category does that query belong to?
What is the ad that users are most likely to click on for the query
“flowers”?
Is this click fraudulent?
Is this ad likely to result in a purchase (not merely a click)?
Is this image pornographic?
Does this page contain malware?
–
Should this query bring up a maps onebox?
Solving many problems require Machine Learning techniques. On all of them we can build prediction models that will learn from the past and try to give the most precise answers to our users. We use variety of Machine Learning algorithms at Google and we are experimenting with numerous old and new advancements in this field in order to find the most accurate, fast and reliable solution for the different problems that we are attacking. Of course one the biggest challenges that we are facing in the Test Engineering community is how are we going to test these algorithms. The amount of the data that Google generates goes beyond all of the known boundaries of environments where the current Machine Learning Solutions were being crafted and tested. We want to open discussion around the ideas how to test different online machine algorithms. From time to time we will present an algorithm and some ideas how to test it and solicit the feedback from the wider audience i.e. try to build a wisdom of the crowds over the testing ideas.
So let's look at the Stochastic Gradient Descent Algorithm
Where X is the set of input values of X
i
,W is set of the importance factors(weights) of every value
X
i
. A positive weight means that that risk factor increases the probability of the outcome, while a negative weight means that that risk factor
decreases the probability of that outcome.
t is the target output value, η is the learning rate(the role of the learning rate is to control the level to which the weights are modified at every iteration and f(z) is the output generated by the function that maps large input domain to a small set of output values in this case. The function f(z) in this case is the logistic function:
z = x
0
w
0
+ x
1
w
1
+ x
2
w
2
+ ... + x
k
w
k
The logistic function has nice characteristics since it can take any input, and basically squash it to 0 or 1. Ideal for predicting probabilities on events that are dependent on multiple factors(
X
i
) each with different importance weights(
W
i).
The Stochastic Gradient Descent provides fast convergence to find the optimal minimums of the error(E) that the function is making on the prediction as well as if there are multiple local minimums the algorithms guarantees converging to the global minimum of the prediction error. So let’s go back now into the real online world where we want to give answers (predictions) to our users in milliseconds and ask the question how are we going to design automated tests for the Stochastic Gradient Descent Algorithm embedded into a live online prediction system. The environment is pretty agile and dynamic, the code is being changed every hour, you want your tests to run on 24/7 basis, you want to detect errors upstream in the development process, but you don’t want to block the development process with tests that are running days, on the other side you want to release new features fast, but the release process has to be error prone(imagine the world with google being down for 5 mins, that is a global catastrophe, isn’t it?!
So let’s look at some of the test strategies:
Should we try to train the model(set of the importance factors) and test the model with the subset of the training data? What if this takes far more than hours, maybe days to do that? Should we try to reduce the set of importance factors (X
i
) and get the convergence(E->0) on the reduced model?
Should we try to reduce the training data set(the variety of set of values for X as an input to the algorithm) and keep the original model and get the convergence by any price? Should we be happy with reducing both the model size and the training set? Are we going to worry for over-fitting in the test environment? Given the original data is online data and evolves fast, are we going to be satisfied with fixed data test set or change the input test data frequently? What are the triggers that will make you do so? What else should we do?
Drop us a note, all ideas are more than welcome.
7 comments
Intro to Ad Quality Test Challenges
Saturday, May 24, 2008
Alek Icev
I'd like to take a second and introduce you to the team testing the ads ranking algorithms. We'd like to think that we had a hand in the webs shift to a "content meritocracy". As you know the Google search results are unbiased by human editors, and we don't allow buying a spot at the top of the results list. This idea builds trust with users and allows the community to decide what's important.
Recently, we started applying the same concept to the online advertising. We asked ourselves how to bring the same level of "content meritocracy" to the online advertising where everybody pays to have ads being displayed on Google and on our partner sites. In other words, we needed to change a system that was predominately driven by human influence into one that build its merit based on feedback from the community. The idea was that we would penalize the ranking of paid ads in several circumstances: few users were clicking on a particular ads, an ad's landing page was not relevant, or if users don't like an ad's content. We want to provide our users with absolutely the most relevant ads for their click. In order to make our vision a reality we are building one of the largest online and real time machine learning labs in the world. We learn from everything: clicks, queries, ads, landing pages, conversions... hundreds of signals.
The Google Ad Prediction System brought new challenges to Test Engineering. The problem is that we needed to build the abstraction layers and metrics systems that allow us to understand if the system is organically getting better or regressing. Put another way, we started off lacking the decision tree or a perceptron that a bank or credit card company have embedded into their risk analysis, or the neural net that's behind all broken speech recognition, or the latest tweaks on expectation-maximization algorithms needed to predict the protein transcription in the cells. The amount and versatility of the data that Google Ad Prediction models learn is immense. The amount of time needed to make the prediction is counted in milliseconds. The amount of computing resources, ads databases and infrastructure needed to serve predictions on every ad that is showing today is beyond imagination. Our challenge is to train and test learning models, that span clusters of servers and databases, simulate ads traffic and having everything compiled and running from the latest code changes submitted to the huge source depot. And the icing on the cake is to run that on 24/7 schedule.
On top of all of the technical challenges, we are also challenging the industry definition of "testing" and are believers in automated tests that are incorporated upstream into the development process and run on continuous basis. Ads Quality Test Engineering Group at Google, works on a bleeding edge testing infrastructure to test, simulate and train Google Ads Prediction systems in real time.
6 comments
Labels
TotT
102
GTAC
61
James Whittaker
42
Misko Hevery
32
Code Health
30
Anthony Vallone
27
Patrick Copeland
23
Jobs
18
Andrew Trenk
12
C++
11
Patrik Höglund
8
JavaScript
7
Allen Hutchison
6
George Pirocanac
6
Zhanyong Wan
6
Harry Robinson
5
Java
5
Julian Harty
5
Adam Bender
4
Alberto Savoia
4
Ben Yu
4
Erik Kuefler
4
Philip Zembrod
4
Shyam Seshadri
4
Chrome
3
Dillon Bly
3
John Thomas
3
Lesley Katzen
3
Marc Kaplan
3
Markus Clermont
3
Max Kanat-Alexander
3
Sonal Shah
3
APIs
2
Abhishek Arya
2
Alan Myrvold
2
Alek Icev
2
Android
2
April Fools
2
Chaitali Narla
2
Chris Lewis
2
Chrome OS
2
Diego Salas
2
Dori Reuveni
2
Jason Arbon
2
Jochen Wuttke
2
Kostya Serebryany
2
Marc Eaddy
2
Marko Ivanković
2
Mobile
2
Oliver Chang
2
Simon Stewart
2
Stefan Kennedy
2
Test Flakiness
2
Titus Winters
2
Tony Voellm
2
WebRTC
2
Yiming Sun
2
Yvette Nameth
2
Zuri Kemp
2
Aaron Jacobs
1
Adam Porter
1
Adam Raider
1
Adel Saoud
1
Alan Faulkner
1
Alex Eagle
1
Amy Fu
1
Anantha Keesara
1
Antoine Picard
1
App Engine
1
Ari Shamash
1
Arif Sukoco
1
Benjamin Pick
1
Bob Nystrom
1
Bruce Leban
1
Carlos Arguelles
1
Carlos Israel Ortiz García
1
Cathal Weakliam
1
Christopher Semturs
1
Clay Murphy
1
Dagang Wei
1
Dan Maksimovich
1
Dan Shi
1
Dan Willemsen
1
Dave Chen
1
Dave Gladfelter
1
David Bendory
1
David Mandelberg
1
Derek Snyder
1
Diego Cavalcanti
1
Dmitry Vyukov
1
Eduardo Bravo Ortiz
1
Ekaterina Kamenskaya
1
Elliott Karpilovsky
1
Elliotte Rusty Harold
1
Espresso
1
Felipe Sodré
1
Francois Aube
1
Gene Volovich
1
Google+
1
Goran Petrovic
1
Goranka Bjedov
1
Hank Duan
1
Havard Rast Blok
1
Hongfei Ding
1
Jason Elbaum
1
Jason Huggins
1
Jay Han
1
Jeff Hoy
1
Jeff Listfield
1
Jessica Tomechak
1
Jim Reardon
1
Joe Allan Muharsky
1
Joel Hynoski
1
John Micco
1
John Penix
1
Jonathan Rockway
1
Jonathan Velasquez
1
Josh Armour
1
Julie Ralph
1
Kai Kent
1
Karin Lundberg
1
Kaue Silveira
1
Kevin Bourrillion
1
Kevin Graney
1
Kirkland
1
Kurt Alfred Kluever
1
Manjusha Parvathaneni
1
Marek Kiszkis
1
Marius Latinis
1
Mark Ivey
1
Mark Manley
1
Mark Striebeck
1
Matt Lowrie
1
Meredith Whittaker
1
Michael Bachman
1
Michael Klepikov
1
Mike Aizatsky
1
Mike Wacker
1
Mona El Mahdy
1
Noel Yap
1
Palak Bansal
1
Patricia Legaspi
1
Per Jacobsson
1
Peter Arrenbrecht
1
Peter Spragins
1
Phil Norman
1
Phil Rollet
1
Pooja Gupta
1
Project Showcase
1
Radoslav Vasilev
1
Rajat Dewan
1
Rajat Jain
1
Rich Martin
1
Richard Bustamante
1
Roshan Sembacuttiaratchy
1
Ruslan Khamitov
1
Sam Lee
1
Sean Jordan
1
Sharon Zhou
1
Shiva Garg
1
Siddartha Janga
1
Simran Basi
1
Stan Chan
1
Stephen Ng
1
Tejas Shah
1
Test Analytics
1
Test Engineer
1
Tim Lyakhovetskiy
1
Tom O'Neill
1
Vojta Jína
1
automation
1
dead code
1
iOS
1
mutation testing
1
Archive
▼
2024
(12)
▼
Oct
(1)
SMURF: Beyond the Test Pyramid
►
Sep
(1)
►
Aug
(1)
►
Jul
(1)
►
May
(3)
►
Apr
(3)
►
Mar
(1)
►
Feb
(1)
►
2023
(14)
►
Dec
(2)
►
Nov
(2)
►
Oct
(5)
►
Sep
(3)
►
Aug
(1)
►
Apr
(1)
►
2022
(2)
►
Feb
(2)
►
2021
(3)
►
Jun
(1)
►
Apr
(1)
►
Mar
(1)
►
2020
(8)
►
Dec
(2)
►
Nov
(1)
►
Oct
(1)
►
Aug
(2)
►
Jul
(1)
►
May
(1)
►
2019
(4)
►
Dec
(1)
►
Nov
(1)
►
Jul
(1)
►
Jan
(1)
►
2018
(7)
►
Nov
(1)
►
Sep
(1)
►
Jul
(1)
►
Jun
(2)
►
May
(1)
►
Feb
(1)
►
2017
(17)
►
Dec
(1)
►
Nov
(1)
►
Oct
(1)
►
Sep
(1)
►
Aug
(1)
►
Jul
(2)
►
Jun
(2)
►
May
(3)
►
Apr
(2)
►
Feb
(1)
►
Jan
(2)
►
2016
(15)
►
Dec
(1)
►
Nov
(2)
►
Oct
(1)
►
Sep
(2)
►
Aug
(1)
►
Jun
(2)
►
May
(3)
►
Apr
(1)
►
Mar
(1)
►
Feb
(1)
►
2015
(14)
►
Dec
(1)
►
Nov
(1)
►
Oct
(2)
►
Aug
(1)
►
Jun
(1)
►
May
(2)
►
Apr
(2)
►
Mar
(1)
►
Feb
(1)
►
Jan
(2)
►
2014
(24)
►
Dec
(2)
►
Nov
(1)
►
Oct
(2)
►
Sep
(2)
►
Aug
(2)
►
Jul
(3)
►
Jun
(3)
►
May
(2)
►
Apr
(2)
►
Mar
(2)
►
Feb
(1)
►
Jan
(2)
►
2013
(16)
►
Dec
(1)
►
Nov
(1)
►
Oct
(1)
►
Aug
(2)
►
Jul
(1)
►
Jun
(2)
►
May
(2)
►
Apr
(2)
►
Mar
(2)
►
Jan
(2)
►
2012
(11)
►
Dec
(1)
►
Nov
(2)
►
Oct
(3)
►
Sep
(1)
►
Aug
(4)
►
2011
(39)
►
Nov
(2)
►
Oct
(5)
►
Sep
(2)
►
Aug
(4)
►
Jul
(2)
►
Jun
(5)
►
May
(4)
►
Apr
(3)
►
Mar
(4)
►
Feb
(5)
►
Jan
(3)
►
2010
(37)
►
Dec
(3)
►
Nov
(3)
►
Oct
(4)
►
Sep
(8)
►
Aug
(3)
►
Jul
(3)
►
Jun
(2)
►
May
(2)
►
Apr
(3)
►
Mar
(3)
►
Feb
(2)
►
Jan
(1)
►
2009
(54)
►
Dec
(3)
►
Nov
(2)
►
Oct
(3)
►
Sep
(5)
►
Aug
(4)
►
Jul
(15)
►
Jun
(8)
►
May
(3)
►
Apr
(2)
►
Feb
(5)
►
Jan
(4)
►
2008
(75)
►
Dec
(6)
►
Nov
(8)
►
Oct
(9)
►
Sep
(8)
►
Aug
(9)
►
Jul
(9)
►
Jun
(6)
►
May
(6)
►
Apr
(4)
►
Mar
(4)
►
Feb
(4)
►
Jan
(2)
►
2007
(41)
►
Oct
(6)
►
Sep
(5)
►
Aug
(3)
►
Jul
(2)
►
Jun
(2)
►
May
(2)
►
Apr
(7)
►
Mar
(5)
►
Feb
(5)
►
Jan
(4)
Feed
Follow @googletesting