Automating ingestion processes is crucial for modern businesses that handle vast amounts of data daily. In today's fast-paced digital landscape, the ability to seamlessly collect, process, and analyze data can make the difference between staying ahead of the competition and falling behind. To simplify ingestion, tools such as Fluent Bit enable customers to route data between pluggable sources and sinks without needing to write a single line of code. Instead, data routing is managed via a config file. The Fluent Bit WriteAPI Connector is a pluggable sink built on top of the BigQuery Storage Write API that enables organizations to rapidly develop a data ingestion pipeline.
What are the BigQuery Storage Write API and Fluent Bit?
The BigQuery Storage Write API is a high-performance data-ingestion API for BigQuery. It leverages both batching and streaming methods to ingest records into BigQuery in real-time. The WriteAPI offers features such as ability to scale and provides exactly-once delivery to guarantee that data is not duplicated. Using the Write API directly typically requires technical expertise, as users must navigate one of the client SDKs. This can create a high barrier to entry for some customers to stream data into BigQuery.
Fluent Bit is a widely-used open-source observability agent known for its lightweight design, speed, and flexibility. It operates by collecting logs, traces and metrics through various inputs such as local or network files, filtering and buffering them, and then routing them to designated outputs. Fluent Bit's high-performance parsing capabilities allow for data to be processed according to user specifications. The output component is a configurable plugin that directs data to different destinations, such as various tables in BigQuery. There can be multiple WriteAPI outputs and each output can be independently configured to use a specific write mode, enabling seamless data streaming into BigQuery based on tag/match pairs.
Why Use the Fluent Bit WriteAPI Connector?
Our solution to the technical challenges posed by using the WriteAPI is the Fluent Bit WriteAPI Connector. This connector automates the data ingestion process, eliminating the need for customers to write any code. The entire pipeline is managed through a single configuration file, making it easy to use. The flow of data is depicted in the diagram below.
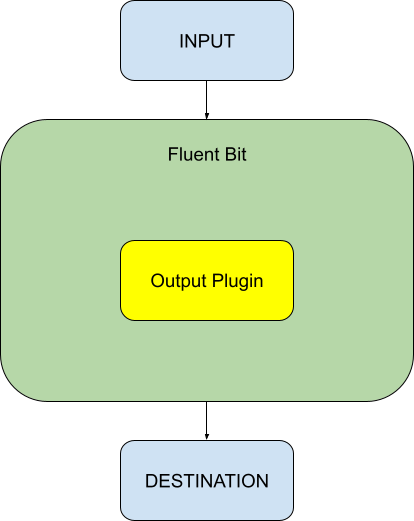 |
Example Use Case
Say we wish to monitor a log file containing JSON data, and we would like to ingest this data into a BigQuery table that has a single column titled “Text” of type String. A line from the log file looks like this:
{"Text": "Hello, World"}Setup Process
-
1. Setting Up Fluent Bit: The first step is to install and configure Fluent Bit. Once installed, Fluent Bit must be configured to collect data from your desired sources. This involves defining inputs, such as log files or system metrics, that Fluent Bit will monitor. This is explained below.
-
2. Cloning the Google Git Repository: Next, clone the Google Git Repository that contains the Fluent Bit WriteAPI Connector. This repository includes all the necessary files to set up the connector, along with an example configuration file to help you get started. Let’s say the git repo is cloned at /usr/local/fluentbit-bigquery-writeapi-sink. Edit the file in the git repo named plugins.conf to provide the full path to the writeapi plugin. For example, the contents of the file can now look like this:
- [PLUGINS]
- Path /usr/local/fluentbit-bigquery-writeapi-sink/out_writeapi.so
-
3. Setting Up BigQuery Tables: Ensure that your BigQuery tables are set up and ready to receive data. This might involve creating new tables or configuring existing ones to match the data schema you intend to use. For example, create the BigQuery table with a schema containing the column Text of type STRING. Let’s say the table is created at myProject.myDataset.myTable.
 |
| click to enlarge |
-
4. Prepare the input file: We will be reading data from a log file at /usr/local/logfile.log. Let’s start with an empty log file. Create the log file as follows:
- touch /usr/local/logfile.log
-
5. Configuring the Plugin: The most critical step is setting up the configuration file for the Fluent Bit WriteAPI Connector. This singular file controls the entire data pipeline, from input collection to data filtering and routing. The configuration file is straightforward and highly intuitive. It allows you to define various parameters, such as input sources, data filters, and output destinations. Create a configuration file in, say /usr/local, and call it demo.conf. See details on how to format a configuration file. It looks like this:
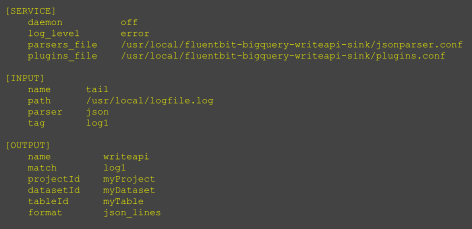 |
This routes the data from /usr/local/logfile.log to the BigQuery table at myProject.myDataset.myTable. There are additional configurable fields that control the stream, such as chunking, asynchronous response queue, and also the type of stream. These fields let you control how your data is streamed.
To run the pipeline, use the command:
fluent-bit -c /usr/local/demo.conf
As the log file is updated new lines will automatically appear in the BigQuery table. For example, to populate the log file you can run the following command:
echo "{\"Text\": \"Hello, world\"}" >> /usr/local/logfile.log
Note that the default flush interval in Fluent Bit is 1 minute, so it might take a minute before the log file is flushed. The BigQuery table will now be updated as follows:
 |
| click to enlarge |
Key Features
The connector supports a wide variety of features including multi-instancing, dynamic scaling, exactly-once delivery, and automatic retry.
- The multi-instancing feature of the Fluent Bit WriteAPI Connector is designed to offer flexibility in routing data. Specifically, users can configure the connector to handle multiple data inputs and outputs in various combinations. This feature also supports more complex configurations, such as multiple inputs feeding into multiple outputs, allowing data to be aggregated or distributed as needed. An input connector is labeled with a tag field. In our example, this has value log1. Data is routed to an output connector based on the value of its match field. In our example, this also has value log1, meaning there is a 1-to-1 correspondence between the input and output connector. The match field is a regex so it can be used to connect with multiple inputs. For example, if this was set to * then data from all inputs would flow to this output.
- Handling large volumes of data efficiently is crucial for modern pipelines. The dynamic scaling feature addresses the issue of potential overloads in the Write API. As data is streamed into BigQuery, there may be times when the API queue becomes full—by default, it can hold up to 1000 pending responses. When this limit is reached, no new data can be appended until some of the pending responses are processed, which can create back pressure in the system. To manage this, the connector automatically scales up its capacity by creating an additional network connection when it detects that the number of pending responses has reached the threshold.
- The "exactly-once" feature ensures that each piece of data is sent and recorded in BigQuery exactly once. This feature ensures no data is duplicated. If the connector encounters an intermittent issue while sending a specific piece of data, it will synchronously retry sending it until it is successful. This ensures data is delivered correctly.
- The retry functionality allows the connector to handle temporary failures gracefully. The retry mechanism is configurable, meaning users can set how many times the system should attempt to resend the data before giving up. By default, the connector will retry sending failed data up to four times. In the default stream mode, if a row of data fails to send, it is retried while other rows continue to be processed. However, in the "exactly once" mode, the retry process is synchronous, meaning the system will wait for the failed row to be successfully sent before moving on to subsequent rows.
- Error handling in the connector is designed to catch and manage issues that may arise during data transmission. The connector will continue processing incoming data even if earlier data had a failure. Any permanent issues that are encountered are logged to the console.
1. Multi-Instancing
2. Dynamic Scaling
3. Exactly-Once
4. Retry Functionality
5. Error Handling
Conclusion
The ability to efficiently collect, process, and analyze data is a critical factor for business success. The Fluent Bit WriteAPI Connector stands out as a powerful solution that simplifies and automates the data ingestion process, bridging the gap between Fluent Bit's versatile data collection capabilities and Google BigQuery's robust analytics platform.
By eliminating the need for complex coding and manual data management, the Fluent Bit WriteAPI Connector lowers the barrier to entry for businesses of all sizes. Whether you're a small startup or a large enterprise, this tool allows you to effortlessly set up and manage your data pipelines with a single configuration file. Its features like multi-instancing, dynamic scaling, exactly-once delivery, and error handling ensure that your data is ingested accurately, reliably, and in real-time.
The straightforward setup process, combined with the flexibility and scalability of the connector, make it a valuable asset for any organization looking to harness the power of their data. By automating the ingestion process, businesses can focus on what truly matters: deriving actionable insights from their data to drive growth and innovation.
By Tanishqa Puhan, BigQuery WriteAPI