These statistics highlight the importance of open source software in modern technology and software development. At the same time, they demonstrate that as its relevance grows, so do the challenges associated with keeping it safe. At Open Source Summit EU, we discussed these challenges and how open source security could be improved. Let’s begin by breaking down the landscape of open source.
The open source ecosystem is fragmented, with diverse languages, build systems, and testing pipelines, making it difficult to maintain consistent security standards. This fragmentation forces developers to juggle multiple roles, such as managing security vulnerabilities, often without adequate tools and support. As a result, inconsistencies and security gaps arise, leaving open source projects vulnerable to attacks. Creating consistent security practices across the board is key to addressing vulnerabilities, which standardization helps to minimize while streamlining the development process.
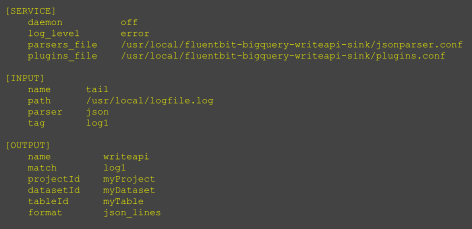
Google’s SLSA (Supply Chain Levels for Software Artifacts) framework and OSV (Open Source Vulnerabilities) schemas are prime examples of how de facto standardization can transform open source security. SLSA has united several companies to create a standard that enables developers to improve their supply chain security posture, helping prevent attacks like those experienced by SolarWinds and Codecov.
The OSV schema has also been successful, with more than 20 language ecosystems adopting it. This schema allows vulnerabilities to be exported in a precise, machine-readable format, making them easier to manage and address. Thanks to its standardized format, over 150,000 vulnerabilities in open source software have been aggregated and made accessible to anyone in the world via a single API call.
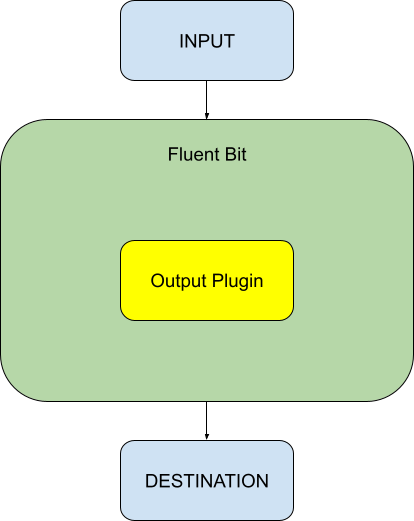
However, many tasks remain manual, making them time-consuming and more prone to human error. Developers must integrate multiple tools at different stages of the software development cycle. The future of open source security lies in creating a fully integrated platform—a tool suite that integrates the best-in-industry tools and solutions, and provides simple hooks for continuous operation in the CI/CD system. Automation is crucial.
The key to revolutionizing open source security is AI, as it can automate manual and error-prone tasks, and reduce the burden on developers.
Google has already started leveraging AI in open source security by successfully using it to write and improve fuzzer unit tests. Google's OSS-Fuzz has been a game changer with a 40% increase in code coverage for over 160 projects. Since its inception, it has identified over 12,000 vulnerabilities with a 90% fix rate. Its effectiveness is due to its close integration with the developer’s workflow, testing the latest commits and helping to fix regressions quickly.
While AI remains an area of active research, and it has not yet solved all security challenges, Google is eager to collaborate with the community to push the boundaries of what AI can achieve in open source security.
Google's approach to open source security is now focused on long-term thinking and scalable solutions. To make a meaningful difference at scale, it is focusing on three key aspects:
- Simplifying and applying security best practices consistently: Common, usable standards are key to reducing vulnerabilities and maintaining a secure ecosystem.
- Developing an intelligent and integrated platform: A seamless, integrated platform that automates security tasks and naturally integrates into the developer workflow.
- Leveraging AI to accelerate and enhance security: Reducing the workload on developers and catching vulnerabilities that might go undetected.
By maintaining this focus and continuing to collaborate with the community, Google and the open source ecosystem can ensure that FOSS remains a secure, reliable foundation for the software solutions of tomorrow.
By Abhishek Arya – Principal Engineer, Open Source and Supply Chain Security