ViTMSN
Overview
The ViTMSN model was proposed in Masked Siamese Networks for Label-Efficient Learning by Mahmoud Assran, Mathilde Caron, Ishan Misra, Piotr Bojanowski, Florian Bordes, Pascal Vincent, Armand Joulin, Michael Rabbat, Nicolas Ballas. The paper presents a joint-embedding architecture to match the prototypes of masked patches with that of the unmasked patches. With this setup, their method yields excellent performance in the low-shot and extreme low-shot regimes.
The abstract from the paper is the following:
We propose Masked Siamese Networks (MSN), a self-supervised learning framework for learning image representations. Our approach matches the representation of an image view containing randomly masked patches to the representation of the original unmasked image. This self-supervised pre-training strategy is particularly scalable when applied to Vision Transformers since only the unmasked patches are processed by the network. As a result, MSNs improve the scalability of joint-embedding architectures, while producing representations of a high semantic level that perform competitively on low-shot image classification. For instance, on ImageNet-1K, with only 5,000 annotated images, our base MSN model achieves 72.4% top-1 accuracy, and with 1% of ImageNet-1K labels, we achieve 75.7% top-1 accuracy, setting a new state-of-the-art for self-supervised learning on this benchmark.
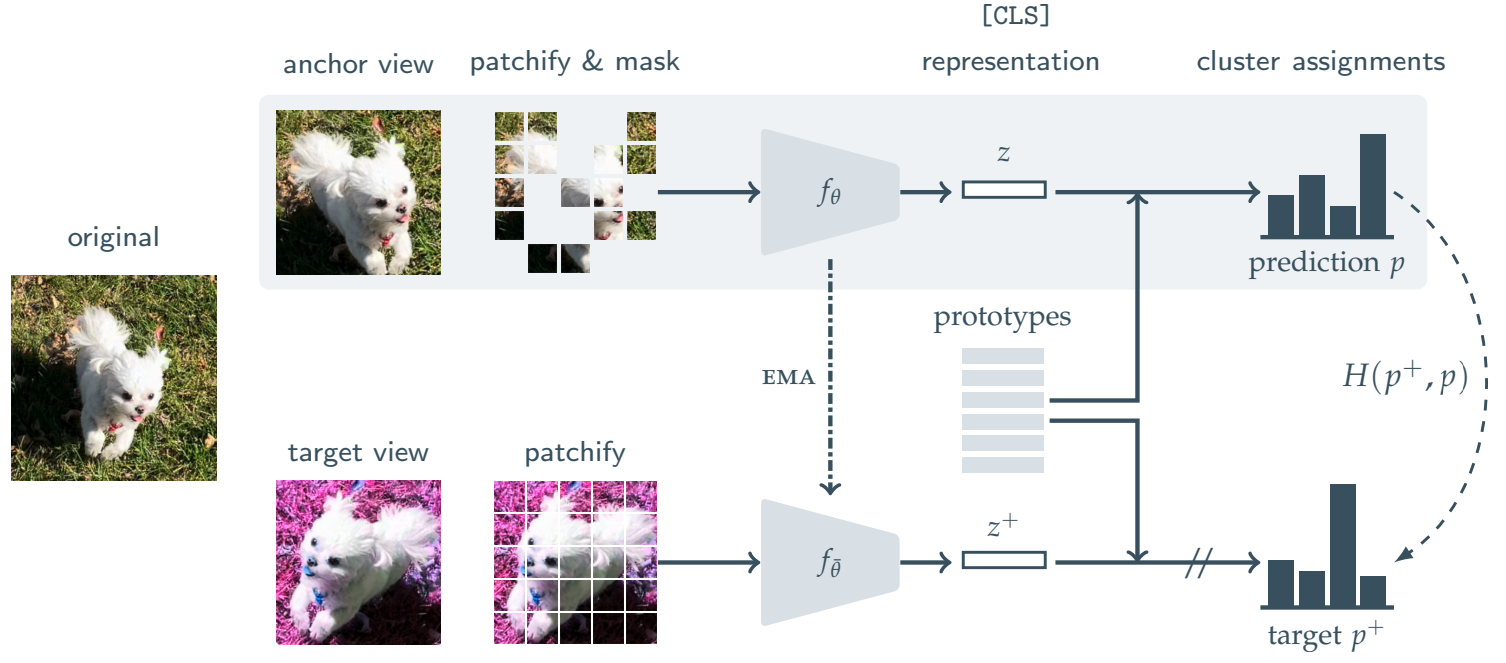 MSN architecture. Taken from the original paper.
MSN architecture. Taken from the original paper. This model was contributed by sayakpaul. The original code can be found here.
Usage tips
- MSN (masked siamese networks) is a method for self-supervised pre-training of Vision Transformers (ViTs). The pre-training objective is to match the prototypes assigned to the unmasked views of the images to that of the masked views of the same images.
- The authors have only released pre-trained weights of the backbone (ImageNet-1k pre-training). So, to use that on your own image classification dataset, use the ViTMSNForImageClassification class which is initialized from ViTMSNModel. Follow this notebook for a detailed tutorial on fine-tuning.
- MSN is particularly useful in the low-shot and extreme low-shot regimes. Notably, it achieves 75.7% top-1 accuracy with only 1% of ImageNet-1K labels when fine-tuned.
Using Scaled Dot Product Attention (SDPA)
PyTorch includes a native scaled dot-product attention (SDPA) operator as part of torch.nn.functional. This function
encompasses several implementations that can be applied depending on the inputs and the hardware in use. See the
official documentation
or the GPU Inference
page for more information.
SDPA is used by default for torch>=2.1.1 when an implementation is available, but you may also set
attn_implementation="sdpa" in from_pretrained() to explicitly request SDPA to be used.
from transformers import ViTMSNForImageClassification
model = ViTMSNForImageClassification.from_pretrained("facebook/vit-msn-base", attn_implementation="sdpa", torch_dtype=torch.float16)
...For the best speedups, we recommend loading the model in half-precision (e.g. torch.float16 or torch.bfloat16).
On a local benchmark (A100-40GB, PyTorch 2.3.0, OS Ubuntu 22.04) with float32 and facebook/vit-msn-base model, we saw the following speedups during inference.
| Batch size | Average inference time (ms), eager mode | Average inference time (ms), sdpa model | Speed up, Sdpa / Eager (x) |
|---|---|---|---|
| 1 | 7 | 6 | 1.17 |
| 2 | 8 | 6 | 1.33 |
| 4 | 8 | 6 | 1.33 |
| 8 | 8 | 6 | 1.33 |
Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ViT MSN.
- ViTMSNForImageClassification is supported by this example script and notebook.
- See also: Image classification task guide
If you’re interested in submitting a resource to be included here, please feel free to open a Pull Request and we’ll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
ViTMSNConfig
class transformers.ViTMSNConfig
< source >( hidden_size = 768 num_hidden_layers = 12 num_attention_heads = 12 intermediate_size = 3072 hidden_act = 'gelu' hidden_dropout_prob = 0.0 attention_probs_dropout_prob = 0.0 initializer_range = 0.02 layer_norm_eps = 1e-06 image_size = 224 patch_size = 16 num_channels = 3 qkv_bias = True **kwargs )
Parameters
- hidden_size (
int, optional, defaults to 768) — Dimensionality of the encoder layers and the pooler layer. - num_hidden_layers (
int, optional, defaults to 12) — Number of hidden layers in the Transformer encoder. - num_attention_heads (
int, optional, defaults to 12) — Number of attention heads for each attention layer in the Transformer encoder. - intermediate_size (
int, optional, defaults to 3072) — Dimensionality of the “intermediate” (i.e., feed-forward) layer in the Transformer encoder. - hidden_act (
strorfunction, optional, defaults to"gelu") — The non-linear activation function (function or string) in the encoder and pooler. If string,"gelu","relu","selu"and"gelu_new"are supported. - hidden_dropout_prob (
float, optional, defaults to 0.0) — The dropout probability for all fully connected layers in the embeddings, encoder, and pooler. - attention_probs_dropout_prob (
float, optional, defaults to 0.0) — The dropout ratio for the attention probabilities. - initializer_range (
float, optional, defaults to 0.02) — The standard deviation of the truncated_normal_initializer for initializing all weight matrices. - layer_norm_eps (
float, optional, defaults to 1e-06) — The epsilon used by the layer normalization layers. - image_size (
int, optional, defaults to 224) — The size (resolution) of each image. - patch_size (
int, optional, defaults to 16) — The size (resolution) of each patch. - num_channels (
int, optional, defaults to 3) — The number of input channels. - qkv_bias (
bool, optional, defaults toTrue) — Whether to add a bias to the queries, keys and values.
This is the configuration class to store the configuration of a ViTMSNModel. It is used to instantiate an ViT MSN model according to the specified arguments, defining the model architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of the ViT facebook/vit_msn_base architecture.
Configuration objects inherit from PretrainedConfig and can be used to control the model outputs. Read the documentation from PretrainedConfig for more information.
Example:
>>> from transformers import ViTMSNModel, ViTMSNConfig
>>> # Initializing a ViT MSN vit-msn-base style configuration
>>> configuration = ViTConfig()
>>> # Initializing a model from the vit-msn-base style configuration
>>> model = ViTMSNModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configViTMSNModel
class transformers.ViTMSNModel
< source >( config: ViTMSNConfig use_mask_token: bool = False )
Parameters
- config (ViTMSNConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The bare ViTMSN Model outputting raw hidden-states without any specific head on top. This model is a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( pixel_values: typing.Optional[torch.Tensor] = None bool_masked_pos: typing.Optional[torch.BoolTensor] = None head_mask: typing.Optional[torch.Tensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None interpolate_pos_encoding: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None ) → transformers.modeling_outputs.BaseModelOutput or tuple(torch.FloatTensor)
Parameters
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel values. Pixel values can be obtained using AutoImageProcessor. See ViTImageProcessor.call() for details. - head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - interpolate_pos_encoding (
bool, optional) — Whether to interpolate the pre-trained position encodings. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - bool_masked_pos (
torch.BoolTensorof shape(batch_size, num_patches), optional) — Boolean masked positions. Indicates which patches are masked (1) and which aren’t (0).
Returns
transformers.modeling_outputs.BaseModelOutput or tuple(torch.FloatTensor)
A transformers.modeling_outputs.BaseModelOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (ViTMSNConfig) and inputs.
-
last_hidden_state (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size)) — Sequence of hidden-states at the output of the last layer of the model. -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The ViTMSNModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import AutoImageProcessor, ViTMSNModel
>>> import torch
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image_processor = AutoImageProcessor.from_pretrained("facebook/vit-msn-small")
>>> model = ViTMSNModel.from_pretrained("facebook/vit-msn-small")
>>> inputs = image_processor(images=image, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_stateViTMSNForImageClassification
class transformers.ViTMSNForImageClassification
< source >( config: ViTMSNConfig )
Parameters
- config (ViTMSNConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
ViTMSN Model with an image classification head on top e.g. for ImageNet.
This model is a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( pixel_values: typing.Optional[torch.Tensor] = None head_mask: typing.Optional[torch.Tensor] = None labels: typing.Optional[torch.Tensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None interpolate_pos_encoding: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None ) → transformers.modeling_outputs.ImageClassifierOutput or tuple(torch.FloatTensor)
Parameters
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel values. Pixel values can be obtained using AutoImageProcessor. See ViTImageProcessor.call() for details. - head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - interpolate_pos_encoding (
bool, optional) — Whether to interpolate the pre-trained position encodings. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple.
Returns
transformers.modeling_outputs.ImageClassifierOutput or tuple(torch.FloatTensor)
A transformers.modeling_outputs.ImageClassifierOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (ViTMSNConfig) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Classification (or regression if config.num_labels==1) loss. -
logits (
torch.FloatTensorof shape(batch_size, config.num_labels)) — Classification (or regression if config.num_labels==1) scores (before SoftMax). -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each stage) of shape(batch_size, sequence_length, hidden_size). Hidden-states (also called feature maps) of the model at the output of each stage. -
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, patch_size, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The ViTMSNForImageClassification forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import AutoImageProcessor, ViTMSNForImageClassification
>>> import torch
>>> from PIL import Image
>>> import requests
>>> torch.manual_seed(2)
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image_processor = AutoImageProcessor.from_pretrained("facebook/vit-msn-small")
>>> model = ViTMSNForImageClassification.from_pretrained("facebook/vit-msn-small")
>>> inputs = image_processor(images=image, return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> # model predicts one of the 1000 ImageNet classes
>>> predicted_label = logits.argmax(-1).item()
>>> print(model.config.id2label[predicted_label])
tusker