Posted by Mateusz Jurczyk of Google Project Zero
Last month, I presented parts of my PostScript font security research at the REcon security conference in Montreal, in a talk titled “One font vulnerability to rule them all: A story of cross-software ownage, shared codebases and advanced exploitation”. This talk discussed the exploitation process of a vulnerability found in the implementation of a BLEND Charstring instruction, discovered in a user-mode Adobe Reader’s CoolType library and a kernel-mode Adobe Type Manager Font Driver (ATMFD.DLL) used by Windows, both of which are responsible for supporting Type 1 and OpenType fonts in the Reader and system GDI environments. This research was performed as part of my Project Zero work, and more generally resulted in a multitude of vulnerabilities discovered in different modern font engines, which all share a common ancestor of the Charstring interpreter routine – ranging from low to critical severity flaws. The full breakdown of the identified security issues can be found below, with links pointing to corresponding google-security-research bug tracker entries, containing reports with detailed analysis of the vulnerabilities together with Proof of Concept files, as they were provided to the vendors:
Microsoft Windows (ATMFD)
|
Adobe Reader (CoolType)
|
DirectWrite
|
Windows Presentation Foundation
| |
Unlimited Charstring execution
|
–
|
–
|
–
| |
Out-of-bounds reads from the Charstring stream
|
–
|
–
| ||
Off-by-x out-of-bounds reads/writes relative to the operand stack
|
–
|
–
|
–
| |
Memory disclosure via uninitialized transient array
| ||||
Read/write-what-where in LOAD and STORE operators
|
–
|
–
|
–
| |
Buffer overflow in Counter Control Hints
|
–
|
–
| ||
Buffer underflow due to integer overflow in STOREWV
|
–
|
–
| ||
Unlimited out-of-bounds stack manipulation via BLEND operator
|
–
|
–
|
As shown above, most of the vulnerabilities were present in more than one font engine, running in different security contexts or privilege levels. All of them were reported to the respective vendors shortly after their discovery, and were subsequently patched by Microsoft in two security bulletins: MS15-021 (March) and MS15-044 (May), while Adobe issued a single APSB15-10 bulletin in May to address all issues affecting Reader.
Some background story on the research can be found in the “Results of my recent PostScript Charstring security research unveiled” blog post, and the slide deck used during my REcon presentation is linked below:
One font vulnerability to rule them all: A story of cross-software ownage, shared codebases and advanced exploitation (PDF, 7.78MB)
To make a long story short, the one vulnerability mentioned in the title is CVE-2015-0093 (also dubbed CVE-2015-3052 by Adobe). What makes it unique is the fact that it provides an extremely powerful primitive, making it possible to perform arbitrary PostScript operations (e.g. arithmetic, logic, conditional and other) anywhere on the exploited thread’s stack, with full control over what is overwritten and how. This, in turn, could be used by an attacker to craft a self-contained malicious Type 1 font which, once loaded in the vulnerable environment, reliably and deterministically builds a ROP chain in the Charstring program, consequently defeating all modern exploit mitigations techniques such as stack cookies, DEP, ASLR, SMEP and so on. It also affected both Adobe Reader and the Windows kernel (32-bit), enabling the creation of a single PDF file, which would first achieve arbitrary code execution within the PDF viewer’s process, and further escape the sandbox by exploiting the very same bug in the operating system, elevating chosen process’ privileges in the system and removing the associated job’s restrictions.
In order to demonstrate that the above scenario was in fact possible, I created a Proof of Concept file which does exactly that, targeting the latest versions of the software affected by the bugs: Adobe Reader 11.0.10 and Windows 8.1 Update 1 (32-bit). Considering that 64-bit builds of Windows were not affected by the BLEND vulnerability, I also devised an x64 way to achieve reliable elevation of privileges using another Charstring vulnerability (CVE-2015-0090) found during the research, which also adheres to the “100% reliability” and “all mitigations bypassed” philosophy.
In the upcoming series of blog posts, I will discuss the exploitation of the BLEND vulnerability in more detail, and further extend some of the thoughts mentioned in the slides, sharing my insights and providing more context to those who didn’t get a chance to attend the REcon talk in person. Today’s part will cover a brief introduction to digital typography and the role PostScript fonts play in it, a Type 1 / OpenType primer, a short guide to reverse engineering the program interpreter found in ATMFD.DLL, and finally a description of the security flaw in the “blend” operator itself. Further posts released in the upcoming weeks will subsequently provide details on the process of exploiting Adobe Reader for remote code execution, and Windows 8.1 32/64-bit for sandbox escapes on both builds of the operating system. Let’s start with the beginning!
Some (pre)history
The history of digital typography is almost as old as the history of computing itself. Early personal computers seen in the very early 80’s offered a minimalistic user interface, which only allowed input and output to be passed around as text – text that had to be displayed on the screen somehow. Since both hardware and software were very simple and had limited capabilities, text formatting on the display were not an utmost priority back then (more so in the printing industry) with mostly predefined, fixed-width bitmap fonts used at first. Figure 1 shows the different typefaces (implemented in the form of bitmap fonts) designed by Susan Kare and released with the original Mac OS operating system in 1984.

Figure 1. Original typefaces shipped with Mac OS in 1984 (source: https://en.wikipedia.org/wiki/Susan_Kare)
A number of bitmap font formats were designed in the 80’s, with some of them still supported by software nowadays, such as Portable Compiled Format (PCF, supported by FreeType), Glyph Bitmap Distribution Format (BDF, supported by FreeType) or Microsoft Windows Bitmapped Font (FON, supported by FreeType and Windows GDI).
Also in 1984, Adobe introduced two outline font formats based on the PostScript language, itself created two years before: Type 1 fonts, which could use a specific subset of the PostScript specification, and Type 3 fonts, which could make use of all of the language’s features. This was a huge leap forward, as these fonts would specify the glyph shapes instead of their bitmap representation at a specific point size, making them more extensible, adjustable and universal. These formats were originally proprietary and licensed to Adobe partners; they were only publicly documented in 1990, following Apple’s work on an independent format, TrueType. As security researchers looking into PostScript fonts, we should be interested primarily in the Type 1 format (not Type 3), which is the one supported by popular software on desktop computers. The two most important documents are:
A year later in 1991, Adobe released an extension to the Type 1 font format, called Multiple Master fonts, which enabled specifying two or more masters (font styles: weight, width, optical size, style) and interpolating between them along a continuous range of “axes”, as shown in Figure 2. From a technical perspective, the extension was implemented by introducing several new Dictionary fields in the Type 1 header, together with several new Charstring instructions. The details of the technology can be found in the “Type 1 Font Format Supplement” linked above. The interesting bit about it is that while it is officially part of the specification and is therefore supported by many modern font engines, it was never commonly adopted worldwide, with just a handful of Multiple Master fonts ever coming to existence, mostly created by Adobe itself. This is something to keep in mind as old, sparse, unknown features of common file formats are often great vulnerability hunting targets. More information about the development of Multiple Master typefaces in Adobe can be found in the “The Adobe Originals Silver Anniversary Story: How the Originals endured in an ever-changing industry” article [1], but we actually recommend the entire “Celebrating 25 Years of Adobe Originals” series [2] for anyone curious about the history of digital typography and Adobe’s role in it.

Figure 2. Examples of design axes and dynamic ranges in multiple master typefaces (source: http://blog.typekit.com/2014/07/30/the-adobe-originals-silver-anniversary-story-how-the-originals-endured-in-an-ever-changing-industry/)
In the same year of 1991, Apple designed a completely new outline font format called TrueType as a competitor to Type 1. It was based on the SFNT general file structure (a short header and a number of data sections described by four-byte tag, offset, length and checksum), represented glyph outlines using quadratic bézier curves, and defined a dedicated turing-complete hinting programming language. The format was first supported in Mac OS System 7 released in May 1991, but Apple also licensed it to Microsoft for free in order to ensure wide adoption. As a result, TTF support was introduced in Windows 3.1 released in 1992. It is largely the same code that rasterizes TTF fonts in the most recent versions of Windows today.
Three years later, Apple extended TrueType with the launch of TrueType GX, which introduced new, advanced features such as morphing (similar to Adobe’s Multiple Masters) or Line Layout Manager. Microsoft failed to license the format from Apple [3] and started working on a new one, originally called TrueType Open. Adobe would later join Microsoft in these efforts in order to create technology which would supersede both TrueType and Type 1, eventually named OpenType. While OpenType shares the same overall SFNT structure as TrueType, it uses a different set of tables. Furthermore, it can specify glyph outlines in either the old TrueType format (“glyf” table) or a new one called “Compact Font Format” (CFF), which is essentially an extended and binary-encoded equivalent of Type 1. As the most common flavor nowadays, the term "OpenType font" is often used for short of OpenType/CFF.
Basic support for OpenType was implemented in Adobe Type Manager in the early years of the format’s development, but in order to have the fonts working in the Windows environment, the program had to be installed separately in Windows 3.0, 3.1, 95, 98, Me and NT. Microsoft then added official support for external font drivers in the operating system, and worked with Adobe to include an Adobe Type Manager Font Driver (ATMFD.DLL) module in default installations starting with Windows 2000. The driver has remained in all further editions of the OS, up to and including Windows 8.1. In the meanwhile, Adobe used the same code to handle OpenType fonts in some of their other products, such as Adobe Reader (the CoolType library), and other projects and vendors followed by also implementing support for the format, too. Overall, OpenType was widely recognized and is now one of two most commonly used font formats together with TrueType.
More recent times
Since late 90's, no groundbreaking revolution has taken place in the form of new font formats. Instead, the existing standards for TrueType and OpenType have been evolving, going through a number of official specification revisions and unofficial extensions implemented by various vendors, often with little to no collaboration with other major actors. For example, Apple introduced SFNT tables enabling more advanced font features supported by AAT (Apple Advanced Typography), Microsoft introduced new math tables supported by Office, Windows 8 (RichEdit 8.0) and Gecko, Mozilla and Adobe proposed adding full SVG support to OpenType and so forth. As a result, security researchers nowadays would be mostly interested in four font formats: FON bitmap fonts as still supported by Microsoft Windows and FreeType, Type 1 PostScript fonts supported by Microsoft Windows, Adobe Reader, FreeType and Oracle Java, as well as TrueType and OpenType fonts (with their various vendor-specific extensions) supported by pretty much every modern font engine. The three most exposed pieces of software would be the FreeType open-source library used by a majority of UNIX-based software (GNU/Linux, iOS, Android, Chrome OS etc.), and Windows GDI / DirectWrite, which are used by most desktop applications running on Windows for font rasterization (e.g. Internet Explorer, Google Chrome, Mozilla Firefox, Microsoft Office etc.).
As it turns out, the above historical background is quite important in the context of today's software security. Considering the extensive collaboration between vendors decades ago, a great number of modern widely used programs and systems share a common ancestor of their font rasterization code. For example, most TTF engines are based on Microsoft's original implementation of the format, including Windows GDI (win32k.sys), Microsoft GDI+, Microsoft DirectWrite, Adobe Reader and Adobe Flash. Likewise, most OTF engines are based on Adobe's original implementation, including Microsoft GDI (ATMFD.DLL), Microsoft DirectWrite, Microsoft Presentation Foundation and Adobe Reader. As a direct outcome, any bugs present in the original implementation that was later branched and included in multiple products were likely propagated, and may affect various programs or operating systems. This is of course an extremely frightful scenario, with a single 0-day vulnerability potentially being used in targeted or mass campaigns against users of different software, or chained to accomplish both remote code execution and a sandbox escape, leading to complete system compromise. Consequently, I believe that due to the high sensitivity of the code area, it deserves special attention from the security community.
Figure 3. Potential security impact of vulnerabilities present in the shared PostScript font implementation.
It is important to note that while the same pieces of code can be found in a variety of modern programs and environments, they have been living in different branches and maintained by different groups of people for many years now. They have very likely received a varied degree of auditing and fuzzing (being more or less valuable targets), which means that they don’t have to be affected by the exact same set of bugs today. On one hand, this can be considered good news, since a bug in one of the products won’t necessarily affect all the other ones, limiting the impact. On the other hand, security relevant differences in the codebases can reveal issues in the unpatched software through missing sanity checks and similar patterns easy to recognize by reverse engineers using binary diffing tools.
What makes font engines even more sensitive and susceptible to attacks is the fact that the attackers can choose from any of the existing file formats, most of which are extremely complex both structurally and semantically, making it very difficult to get them 100% right in implementation. If we also consider that a majority of the parsers were in a large part developed in C/C++ several decades ago, that they are easily reachable via numerous channels (websites, documents, USB sticks etc.), and that they support extensive, turing-complete virtual machine environments for running untrusted TTF/PostScript Charstring programs, it becomes clear that fonts are one of the best imaginable attack vectors. This is true even despite the great number of vulnerabilities that have already been fixed in virtually every font engine in existence, conference talks given in the past (nearly every major one having a font-related presentation in agenda), and font vulnerabilities being used both “in the wild” (e.g. the Duqu TTF exploit [4], or comex’ iOS jailbreak via a FreeType Type 1 vulnerability [5]) and in various hacking competitions such as pwn2own 2013 (Joshua Drake’s Java 7 SE OpenType memory corruption vulnerability [6]), or pwn2own 2015 (K33n Team’s TTF vulnerability [7]).
Before we dive into discussing the Charstring related vulnerabilities discovered in Type 1 / OpenType handling implemented in ATMFD.DLL and related font engines, let’s briefly go through the format and structure of the two PostScript formats.
Type 1 font primer
In essence, Type 1 fonts are a set of so-called “dictionaries” (associative name → value arrays with field-specific primitive types or other nested dictionaries) responsible for specifying the general font properties, and PostScript programs called “Charstrings” describing the shapes of all glyphs supported by the font. An overview of the general font structure is shown in Figure 4.
Figure 4. Typical dictionary structure of a Type 1 font (source: Adobe Type 1 Font Format, Adobe Systems Inc.)
There are a number of file formats related to Type 1 fonts:
- .AFM (Adobe Font Metrics), .ACFM (Adobe Composite Font Metrics), .AMFM (Adobe Multiple Font Metrics) – textual metrics files.
- .PFA (Printer Font ASCII) – textual representation of the core font file.
- .PFB (Printer Font Binary) – binary representation of the core font file.
- .PFM (Printer Font Metric) – binary representation of the font metrics.
- .MMM (Multiple Master Metric) – binary representation of Multiple Master font metrics.
Depending on the environment, various subsets of the above files are necessary to use the font, with .PFB (the main, partially binary encoded font file) and .PFM (binary encoded font metrics) being the most common ones. For example, the AddFontResource Windows API function requires paths to the .PFB and .PFM files separated by a pipe character, with the potential addition of an .MMM file if the font supports multiple masters.
Examining and modifying .PFB files (and especially the Charstrings contained within) is inconvenient due to two major reasons: binary encoding and encryption. As it turns out, Adobe introduced a simple encryption scheme in Type 1 fonts in order to prevent casual inspection by third parties. The full details of the algorithm used to “protect” (or obfuscate, rather) the Private dictionary and Charstrings were only documented when the Type 1 format specification came to light in the 90’s. The encryption routine is shown below, with decryption achieved using the same function with minor changes:
unsigned short int r;
unsigned short int c1 = 52845;
unsigned short int c2 = 22719;
unsigned char Encrypt(plain) unsigned char plain;
{unsigned char cipher;
cipher = (plain ^ (r>>8));
r = (cipher + r) * c1 + c2;
return cipher;
}
(source: Adobe Type 1 Font Format, Adobe Systems Inc.)
In order to work around the encryption and Charstring encoding, we can conveniently use the type1 and detype1 utilities as part of the Adobe Font Development Kit for OpenType (AFDKO) (open source code available on GitHub), which can convert between .PFB and .PFA (textual, human readable) font files:
$ detype1 font.pfb > font.pfa
$ type1 font.pfa > font.pfb
$ detype1 font.pfb > font.pfa
$ type1 font.pfa > font.pfb
At this point, we can freely work with Type 1 fonts, analyzing and modifying them as needed. If we take a quick look into any .PFA file, we will see a number of PostScript programs of the following form:
/at ## -| { 36 800 hsbw -15 100 hstem 154 108 hstem 466 108 hstem 666 100 hstem 445 85 vstem 155 120 vstem 641 88 vstem 0 100 vstem 275 353 rmoveto 54 41 59 57 vhcurveto 49 0 30 -39 -7 -57 rrcurveto -6 -49 -26 -59 -62 0 rrcurveto -49 -27 43 48 hvcurveto closepath 312 212 rmoveto -95 hlineto -10 -52 rlineto -30 42 -42 19 -51 0 rrcurveto -124 -80 -116 -121 hvcurveto -101 80 -82 88 vhcurveto 60 0 42 28 26 29 rrcurveto 33 4 callsubr 8 -31 26 -25 28 -1 rrcurveto 48 -2 58 26 48 63 rrcurveto 40 52 22 75 0 82 rrcurveto 0 94 -44 77 -68 59 rrcurveto -66 59 -81 27 -88 0 rrcurveto -213 -169 -168 -223 hvcurveto -225 173 -165 215 vhcurveto 107 0 92 31 70 36 rrcurveto -82 65 rlineto -32 -20 -64 -12 -83 0 rrcurveto -171 -125 108 182 hvcurveto 172 111 119 168 vhcurveto 153 0 118 -84 -9 -166 rrcurveto -5 -86 -51 -81 -36 -4 rrcurveto -29 -3 12 43 5 24 rrcurveto closepath endchar } |-
As clearly visible, the instruction stream consists of various outline-related instructions interlaced with immediate numbers (operands). To better understand how the program execution works, let’s discuss the various components of the execution environment:
- Instruction stream - the stream of encoded instructions used to fetch operators and execute them. Not accessible by the Type 1 program itself.
- Operand stack - a LIFO structure holding up to 24 numeric (32-bit) entries. Similarly to regular PostScript, it is used to store instruction operands. It’s important to note that while the maximum width of each entry is 32 bits, different instructions may interpret them in a variety of ways, e.g. as 16.16 fixed points, 16-bit values (discarding part of the information) etc.
- Transient array or BuildCharArray - a fully accessible array of 32-bit numeric entries; can be pre-initialized by specifying a /BuildCharArray array in the Private dictionary, and the size can be controlled via a /lenBuildCharArray entry of type “number”.
Most instructions are encoded with a single byte, with the exception of some immediate numbers and the “escape” instructions. The entirety of operators can be divided into six groups depending on their functions:
Byte range 0 - 31:
- Commands for starting and finishing a character’s outline,
- Path construction commands,
- Hint commands,
- Arithmetic commands,
- Subroutine commands.
Byte range 32 - 255:
- Immediate values pushed on the operand stack, encoded with a varying number of bytes depending on the size of the number.
All instructions documented in the latest version of the Type 1 format specification are shown in Figure 5.
Figure 5. Currently documented Charstring commands (source: Adobe Type 1 Font Format, Adobe Systems Inc.)
While the current list of Type 1 instructions seems rather short, it is important to remember that the PostScript font formats have been evolving over decades, going through a number of iterations which introduced and removed various operators along the way. As a result, font engines which are supposed to maintain backwards compatibility with most/all fonts ever created likely support instructions that are not on the above list (but may still be interesting from a security point of view). In this context, old revisions of said specifications may be a very valuable source of information.
The Type 1 font specification discusses a number of interesting mechanisms used by the format (such as subroutines or so-called “othersubrs”), but since they are not necessary to understand or exploit the BLEND vulnerability covered in this post, we will not explain them here. If you’re interested in font internals or other vulnerabilities discovered during my Charstring security research, we encourage you to study the full specification.
OpenType font primer
The following two documents should work as solid foundation for any OpenType/CFF related research:
Since OpenType is a fully binary format, it’s similarly inconvenient to inspect or modify manually. In this case, you can use the ttx.py tool (part of the Fonttools suite) to convert TrueType and OpenType fonts to a human-readable XML form and back. The fact that it supports a majority of modern SFNT tables and TrueType/PostScript programs makes it a very useful tool.
Overall, the OpenType/CFF format is largely similar to Type 1. There are only a handful of major differences:
- the font is always contained within a single file (.OTF) instead of two or more.
- previously textual data (such as some of the Dictionaries) is now encoded in binary form in order to reduce memory/disk consumption.
- the Charstring specification was greatly extended, introducing many new instructions and deprecating some older ones.
A full listing of Type 2 Charstring operators defined in the latest revision of the specification is shown in Figure 6.

Figure 6. All currently documented Type 2 Charstring operators (source: The Type 2 Charstring Format, Adobe Systems Inc.)
A careful reader will notice that the encodings of Type 1 and Type 2 Charstring instructions are binary compatible: the now-unused Type 1 operators are always marked as “-Reserved-” and never reused in Type 2, while all new commands use previously vacant opcodes (either in the main or “escape” namespace). This makes it possible to create a PostScript program containing instructions from both Type 1 and Type 2 specs, which might have been intentional, so that Type 1 and OpenType/CFF fonts could be converted to each other without information loss. However, this behavior might also have some interesting security implications – something to keep in mind for the future.
If we look closely at the list above, we can see that a number of seemingly interesting instructions were added:
- with new global and local type subroutines in OpenType, a callgsubr instruction was introduced,
- hinting-related instructions (hstemhm, hintmask, cntrmask, ...),
- arithmetic and logic instructions (and, or, not, abs, add, sub, neg, ...),
- miscellaneous instructions (random),
- instructions operating on the transient array (get, put).
On the other hand, the “OtherSubrs” functionality was dropped and the callothersubr instruction removed. The execution environment didn’t fundamentally change as compared to Type 1 – it still consists of an instruction stream, operand stack (extended from 24 to 48 entries) and a transient array (converted to a fixed-size array of 32 items).
One other interesting part of the CFF specification is a table defining the various limits of data structures used to implement CFF font support (Figure 7). It is a great starting point for auditing any implementation of the format, as it explicitly indicates the places where things can go wrong due to some of these limits not being properly enforced.
Figure 7. Implementation limits of Type 2 Charstring interpreters (source: The Type 2 Charstring Format, Adobe Systems Inc.)
Armed with some general knowledge of the Type 1 / OpenType formats and the Charstring execution environment, let’s dive into the Adobe Type Manager Font Driver, which is one of the most complete implementations among PostScript font engines, and is still used in the Windows kernel to rasterize fonts in the operating system.
Adobe Type Manager Font Driver
The ATMFD.DLL library is a third-party Windows kernel module provided by Adobe, which handles all Type 1 and OpenType fonts loaded via the GDI interface. It is based on Adobe Type Manager, a family of programs developed by Adobe alongside the PostScript font specification, used to manage fonts, rasterize them on computer monitors and print text on non-PostScript printers. ATM was available for Windows starting with Windows 3.0 as an optional component, and was first shipped by default in Windows 2000. For the last 15 years, the module has always been there, supporting PostScript fonts in the Windows environment.
In order to make use of ATMFD.DLL, Microsoft introduced a universal interface for installing external font drivers through the HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion\Font Drivers registry key. To our current knowledge, the only value residing there in any default Windows installation is "Adobe Type Manager"="atmfd.dll", and we are not aware of any other third-party font drivers in existence. However, it should be theoretically possible to develop and plug a custom driver supporting any font format we would wish.
When one starts looking into the internals of ATMFD, one thing becomes immediately clear – as opposed to a majority of Windows libraries, this one doesn’t have debug symbols available from the Microsoft symbol server. This makes it considerably more difficult to do any reverse-engineering from the start, and might also be one of the reasons why the TrueType font handling implemented in win32k.sys (Microsoft’s component) is arguably more thoroughly audited. In order to (partly) work around the problem, we can make use of the fact that function symbols are available for the OpenType implementations found in DirectWrite (DWrite.dll) and Windows Presentation Foundation (PresentationCFFRasterizerNative_v0300.dll). By cross-diffing either of these modules with ATMFD.DLL, it is possible to recover the names of some functions, which might subsequently help with further analysis.
Quite interestingly, there is also another approach to the problem of missing symbols. As Halvar Flake noticed, some ancient builds of Adobe Reader (the ones we know about are Reader 4 for AIX and Reader 5 for Windows) shipped with debug symbols, including the CoolType.dll font processing library. As the code has not fundamentally changed since then, it is also possible to use the old CoolType as a source of symbols which can be matched with modern ATMFD.DLL code; or better yet, all three pieces of software sharing the same common ancestor as ATMFD (DirectWrite, WPF, CoolType) could be used together to get the most complete picture of the reverse engineered module.
There are also other sorts of information included in the Adobe Type Manager which can help us find our way in the assembly – the font driver is full of debug messages which contain a variety of information, like local/global variable names, function names, expressions used in the code and source file paths. Additionally, we can also find a number of string literals related to Type 1 fonts (e.g. names of dictionary fields) which reveal the locations of functions dealing with those entries through their cross-references in the DLL. Examples of such useful strings are shown below:

... and many others. All this information makes it relatively easy to spot the target we are after in this research - the Charstring processing routine - as it directly references many such Charstring related debug strings:

Incidentally, the function is also by far the largest one in the DLL file, with a size of more than 20kB, while the second largest routine is “only” 4kB long. The magnitude and complexity of the function is best illustrated by a control flow graph, as presented in Figure 8. In order to display the graph, the maximum number of nodes in IDA had to be increased from the default value of 1000.
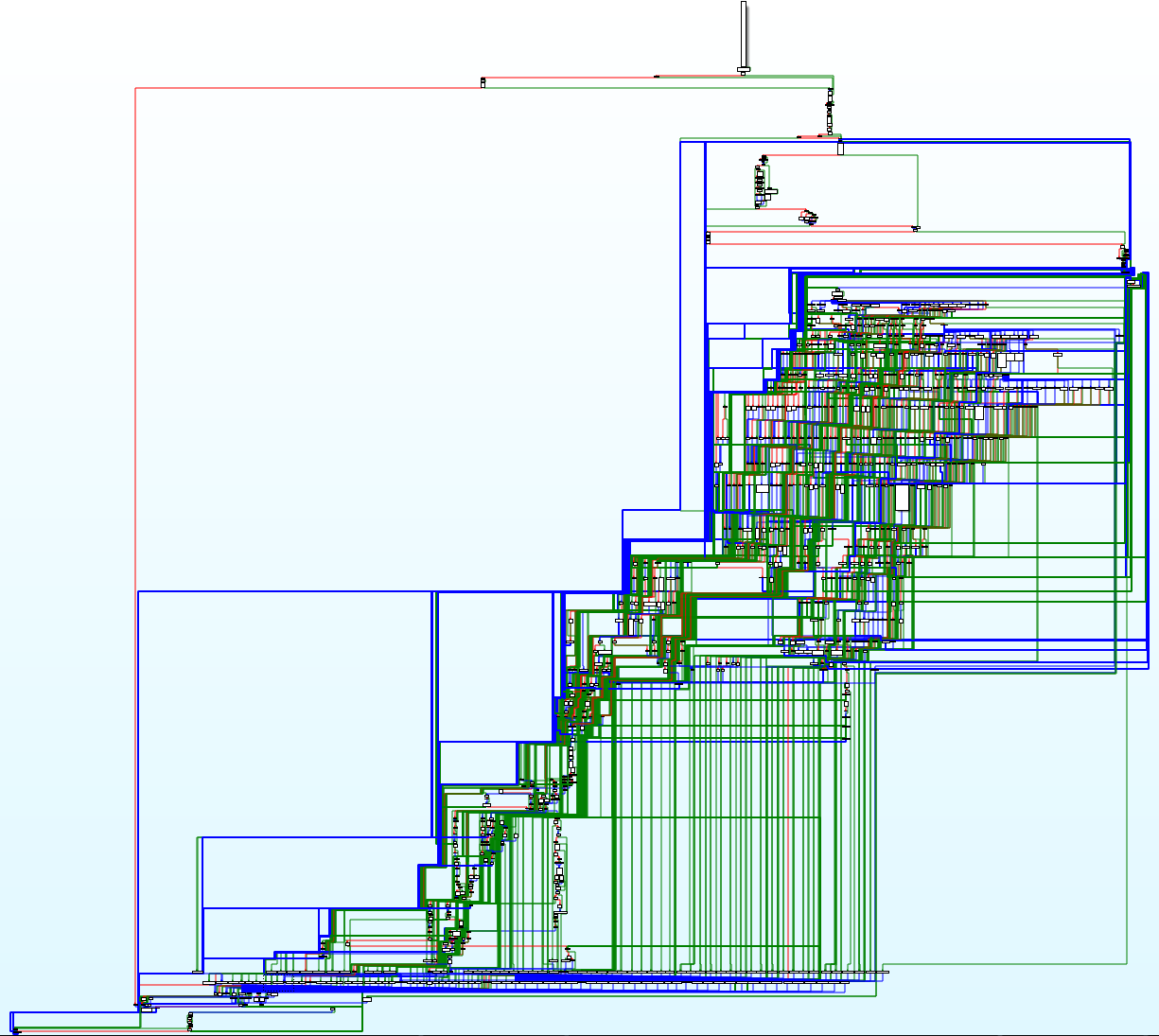
Figure 8. Control flow graph representation of the Charstring processing function found in ATMFD.DLL.
We can further confirm that this is in fact the desired function by using the methods discussed above to acquire its name from one of the libraries with available symbols. If we look into DirectWrite or Windows Presentation Foundation, we will learn that the caller of the function is named “Type1InterpretCharString”; in CoolType, the function itself is called “DoType1InterpretCharString”, affirming that this in fact the piece of code we want to look into.
As indicated by the shape and structure of the above graph, we can deduce that the routine most likely consists of a giant switch/case construct, handling each of the various supported PostScript operators accordingly. A deeper analysis of the function shows that this is in fact the case – during each iteration of the execution loop, the function fetches the next command opcode and enters a corresponding block of code:
BYTE op = *charstring++;
switch (op) {
case HSTEM:
...
case VSTEM:
...
case VMOVETO:
...
.
.
.
}
BYTE op = *charstring++;
switch (op) {
case HSTEM:
...
case VSTEM:
...
case VMOVETO:
...
.
.
.
}
However, this construct alone doesn’t justify the size of the function. In part, it is caused by the fact that it is a universal interpreter used for both Type 1 and Type 2 Charstrings, which are binary compatible formats as mentioned above. This already bodes well for an attacker, as it enables Type 1 Charstrings to make use of all Type 2 (OpenType/CFF) features and vice versa – for example, if there was a vulnerability in a Type 1 specific operator (unrelated to the general structure of Type 1 fonts), an exploit for the vulnerability could also be delivered via an OpenType file, which might sometimes be more convenient for an attacker (.OTF being the more widespread and generally trusted file format).
Further inspection also shows the real reason for the bloated interpreter – it implements every single feature that has ever been part of the Type 1 or Type 2 specifications, including the strictly experimental ones or those officially deprecated many years ago. As the formats have been evolving for decades, the currently officially supported Charstring commands are only a small subset of the entirety of the operators that have ever seen daylight. While presumably done to maintain compatibility with all fonts in existence (including ones created many years ago), this situation is also favorable to a vulnerability hunter, since:
- it significantly increases the attack surface open for analysis and exploitation,
- the implementations of legacy or deprecated features that have not been heard of for a long time are frequently affected by security vulnerabilities, as other developers or researchers might have not been aware of the “hidden” functionality, which may thus have remained untested for many years.
The last noteworthy discovery I made while delving into the interpreter was that the PostScript operand stack (with a maximum of 48 32-bit elements) was implemented in the form of a local array on the interpreter’s function stack, and called “op_stk” according to various debug messages referring to it. The current position on the stack was indicated by a local pointer called “op_sp”, which would be originally set to &op_stk[0], and then incremented or decremented depending on the executed PostScript commands. While this isn’t a bug or bad behavior in itself, it makes it easy for the developer to slip, as somewhat advanced pointer arithmetic needs to be employed to correctly performs all bounds checks affecting the value of “op_sp” – and if one of such checks is missing or faulty, the consequences of having an out-of-bounds operand stack pointer pointing somewhere on the local thread’s stack while executing subsequent Charstring instructions might have catastrophic consequences for the security of the affected software. However, let’s not jump the gun. :-)
All of the above kept my hopes high for some interesting discoveries – and, as shown at the top of the post, I didn’t end up disappointed. In the following section, I will discuss my most impactful finding, the BLEND vulnerability, which provided a primitive allowing for a complete and fully reliable bypass of all currently available software exploit mitigations, and affected both Adobe Reader and the Windows Kernel (ATMFD.DLL) at the same time. Read on.
The BLEND vulnerability (CVE-2015-0093, CVE-2015-3052)
In order to understand the vulnerability being the main subject of the post, we first have to get a grasp on the functionality it was discovered in – the “blend” PostScript operator. It is strongly related to the forgotten Multiple Masters font extension, and was originally introduced in the “The Type 2 Charstring Format” document on 5 May 1998. It was the time when “Multiple Masters” - originally an extension of Type 1 PostScript fonts - was also considered as an addition to the new OpenType/CFF format, resulting in a number of MM-related operators added to the 1998 revision of the Charstring specification (together with new fields introduced into the CFF format). However, since the idea of OpenType/MM was not widely adopted (with just a few such fonts ever coming into existence, none of the publicly used), all references to Multiple Masters were soon removed from the document on 16 March 2000, as shown in the excerpt in Figure 9.

Figure 9. An excerpt from the change log of the “The Type 2 Charstring Format” document from 16 March 2000.
Less than two years of the feature’s existence already warranted it a place in the Charstring interpreter found in the Windows kernel and Adobe Reader.
The details of the operation performed by the instruction are explained in the Type 2 Charstring specs from 1998. From a security perspective, the outcome of executing a “blend” operator boils down to the following actions:
- Loading a signed 16-bit integer value from the operand stack (let’s call it n).
- Loading k*n further elements from the stack, where k is the number of the font’s master designs (2-16, controlled via the length of the /WeightVector Type 1 table).
- Pushing n values back to the operand stack.
In other words, the instruction “blends” k*n values into n numbers on the PostScript stack, with k being a controlled small number and n being an arbitrary 15-bit number with sign. With such complex functionality, involving shifting the stack pointer in various directions based on the result of an arithmetic operation where factors are user-controlled, a number of things can obviously go wrong. The authors of the code were definitely aware of this too, as they included a number of sanity checks executed prior to performing any actual operations on the operand stack:
- Is the stack pointer within the bounds of the operand stack?
op_sp >= op_stk && op_sp <= &op_stk_end - Is there at least one item on the operand stack (the n value)?
op_sp >= &op_sp[1] - Are there at least k*n items on the operand stack to load?
&op_stk[n * master_designs] <= op_sp - Is there enough space left on the stack to push the output parameters?
master_designs != 0 || &op_sp[n] < &op_stk_end
The checks were also made easier to understand thanks to a number of debug messages referenced in the code:
"stack underflow in cmdBLEND",
"stack overflow in cmdBLEND"
"DoBlend would underflow operand stack", "op_stk + inst->lenWeightVector*nArgs <= op_sp"
While the developers went to some great lengths to make sure that the operation would be safe, they missed one corner case: a negative value of n, which is the culprit of the vulnerability. In such case, the control flow reaches a “DoBlend” function, which is where the actual blending operation is performed. If we disregard the specific values loaded from and pushed to the stack, then the only thing the routine does is perform the following operation on the operand stack pointer:
op_sp -= n * (master_designs - 1) * 4
which is a different way of expressing the popping of k*n values, and pushing n values back. In fact, the “DoBlend” function is fortunately constructed such that for a negative n, no actual popping/pushing takes place, avoiding unnecessary corruption of the stack data; however, the “op_sp” pointer is still adjusted accordingly to the formula above. This means that with a controlled 16-bit n, we can increase the stack pointer arbitrarily beyond the “op_stk” array. Since having “op_sp” always point to inside of “op_stk” is one of the fundamental assumptions made by the interpreter code, it is also a security boundary which can be crossed with a sufficiently small negative n number.
It should be noted that while the “blend” operator was documented as part of the Type 2 Charstring specs (used in OpenType files), nowadays it is only functional in the context of Type 1 fonts. This is due to the fact that the number of master designs (referred to as the k factor) can only be controlled via the length of the /WeightVector array in the Top DICT of Type 1 fonts, as the corresponding CFF entries are no longer supported by ATMFD. Hence, the vulnerability is limited to Type 1 fonts only.
It turns out that the rest of the code continues to work in the attacker’s favor. Once we execute the “blend” instruction which increases “op_sp” beyond the end of “op_stk”, another iteration of the interpreter loop takes place, which starts with the following lines of code:
if (op_sp < op_stk) {
AtmfdDbgPrint("windows\\core\\ntgdi\\fondrv\\otfd\\bc\\t1interp.c",
4475, "underflow of Type 1 operand stack",
"op_sp >= op_stk");
abort();
}
if (op_sp < op_stk) {
AtmfdDbgPrint("windows\\core\\ntgdi\\fondrv\\otfd\\bc\\t1interp.c",
4475, "underflow of Type 1 operand stack",
"op_sp >= op_stk");
abort();
}
That’s right – at the beginning of each instruction’s execution, the function checks that “op_sp” is not below the operand stack array, but at the same time doesn’t verify the upper boundary, making it possible for the Charstring to continue normal execution with an inconsistent state of the interpreter (an out-of-bounds stack pointer).
Considering that there are two factors of the product used to shift the operand stack pointer (n and k), the maximum number of bytes we can increase “op_sp” by is 32768 (maximum negative value of n) times 15 (maximum number of k - 1) times 4 (size of a single stack item) = 1966080 (0x1E0000), or almost 2MB. Since the exploited thread’s stack will probably always be smaller than that, it would allow us to operate on other types of nearby memory regions such as heaps/pools, executable images etc. On the other hand, with k=2, the stack pointer is shifted by exactly -n*4 bytes (-n DWORDs), which provides a great granularity for out-of-bounds memory access. By using a simple two-command “-x BLEND” instruction sequence, we can set “op_sp” to any 4-byte aligned offset relative to the “op_stk” array!
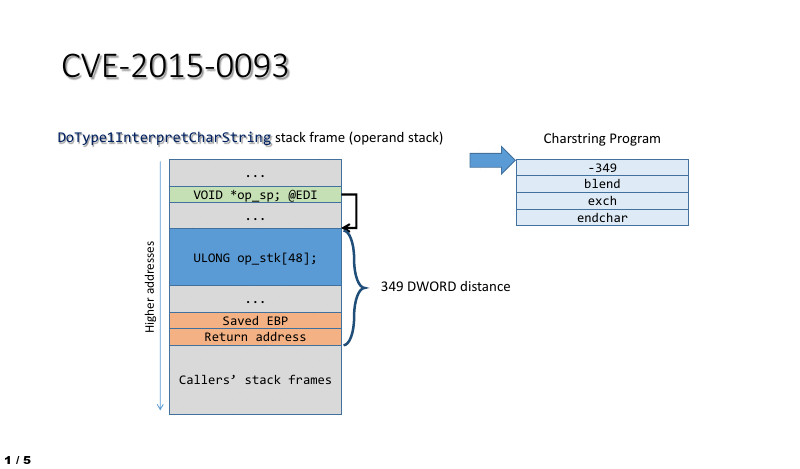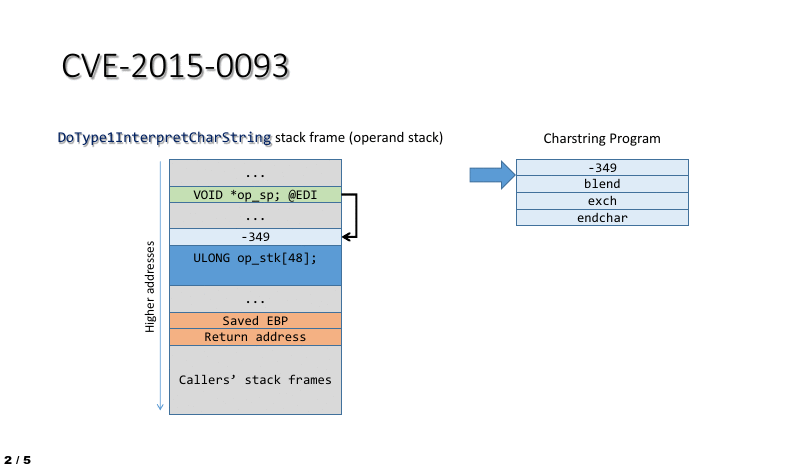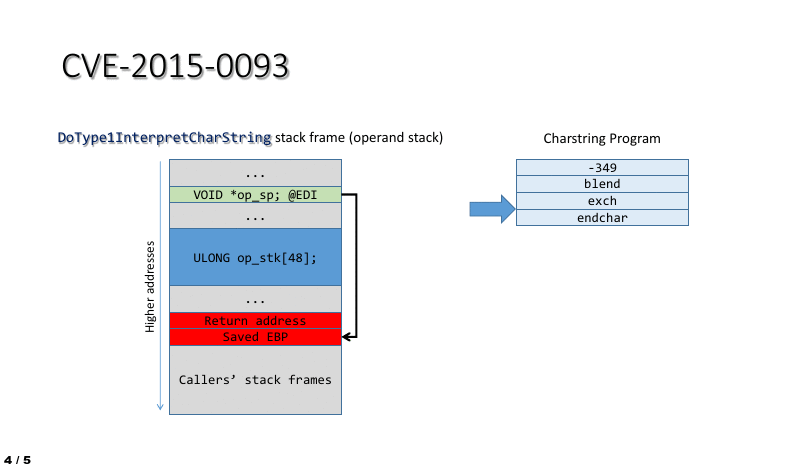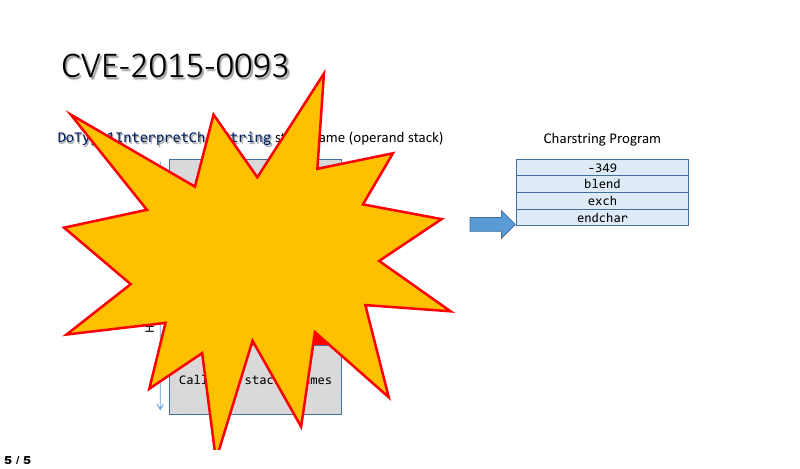
The impact of the vulnerability in the context of ATMFD.DLL can be easily illustrated by using a short stream of four Charstring instructions, which perform the following actions:
- Shift the operand stack pointer so that it points at the interpreter function’s return address.
- Trigger an “exchange” operation, swapping the two topmost operand stack entries, which in this case are the stack frame pointer (saved EBP) and the return address.
- Use the ENDCHAR command to cause the control flow to leave the interpreter, thus triggering a bugcheck upon an attempt to execute data from stack while using the corrupted return address.
This process is also shown in the animation below:
And the resulting kernel crash would look as follows:
ATTEMPTED_EXECUTE_OF_NOEXECUTE_MEMORY (fc)
An attempt was made to execute non-executable memory. The guilty driver
is on the stack trace (and is typically the current instruction pointer).
When possible, the guilty driver's name (Unicode string) is printed on
the bugcheck screen and saved in KiBugCheckDriver.
Arguments:
Arg1: 97ebf6a4, Virtual address for the attempted execute.
Arg2: 11dd2963, PTE contents.
Arg3: 97ebf56c, (reserved)
Arg4: 00000002, (reserved)
An attempt was made to execute non-executable memory. The guilty driver
is on the stack trace (and is typically the current instruction pointer).
When possible, the guilty driver's name (Unicode string) is printed on
the bugcheck screen and saved in KiBugCheckDriver.
Arguments:
Arg1: 97ebf6a4, Virtual address for the attempted execute.
Arg2: 11dd2963, PTE contents.
Arg3: 97ebf56c, (reserved)
Arg4: 00000002, (reserved)
The impact of the vulnerability is greatly elevated by the fact that we can use all implemented operators (arithmetic, storage, etc.) over the out-of-bounds “op_sp” pointer, making it possible to add, subtract, move data around the stack, insert constants and so on. In other words, it provides us with all the primitives necessary to build a full ROP chain used to achieve arbitrary code execution. This, in turn, enables the creation of a 100% reliable exploit subverting all modern exploit mitigations such as stack cookies, DEP, ASLR or SMEP. The entire exploitation process takes place during Charstring execution, and therefore doesn’t require any interaction with the vulnerable software other than loading a specially crafted font.
The only downside of the bug is that it doesn’t affect 64-bit platforms. This is caused by one of the bounds checks in the “blend” operator implementation, which does in fact prevent negative values of n from passing through, thanks to a subexpression being cast to a 32-bit unsigned integer value before being added to a 64-bit pointer:
if ((uint64)(&op_stk + 4 * (uint32)(n * master_designs)) > op_sp)
The behavior effectively eliminates the vulnerability from the compiled code – however, there isn’t so much to worry about from the exploitation angle. At the time of this writing, Adobe only ships 32-bit builds of Reader, making all unpatched installations of the software affected by the flaw. While x64 builds of the Windows kernel might be more troublesome, other vulnerabilities discovered during the research could be used to escape the sandbox in our proof of concept exploit, which will also be discussed later in the series.
That’s it for today. In the subsequent upcoming posts, we will discuss the process of developing a universal, fully reliable proof-of-concept PDF file, which will spawn an elevated calc.exe running with high integrity level and the “System” security token when opened with the most recent vulnerable versions of Adobe Reader and Windows 8.1 32/64-bit.
This is an *amazing* write-up. Thanks for taking the time to write something comprehensible!
ReplyDeleteThe recon2015.pdf link points to a 404 error. It can currently be found on http://j00ru.vexillium.org/slides/2015/recon.pdf instead.
ReplyDelete