This model is in maintenance mode only, we don't accept any new PRs changing its code.
If you run into any issues running this model, please reinstall the last version that supported this model: v4.40.2.
You can do so by running the following command: pip install -U transformers==4.40.2.
The TVLT model was proposed in TVLT: Textless Vision-Language Transformer by Zineng Tang, Jaemin Cho, Yixin Nie, Mohit Bansal (the first three authors contributed equally). The Textless Vision-Language Transformer (TVLT) is a model that uses raw visual and audio inputs for vision-and-language representation learning, without using text-specific modules such as tokenization or automatic speech recognition (ASR). It can perform various audiovisual and vision-language tasks like retrieval, question answering, etc.
The abstract from the paper is the following:
In this work, we present the Textless Vision-Language Transformer (TVLT), where homogeneous transformer blocks take raw visual and audio inputs for vision-and-language representation learning with minimal modality-specific design, and do not use text-specific modules such as tokenization or automatic speech recognition (ASR). TVLT is trained by reconstructing masked patches of continuous video frames and audio spectrograms (masked autoencoding) and contrastive modeling to align video and audio. TVLT attains performance comparable to its text-based counterpart on various multimodal tasks, such as visual question answering, image retrieval, video retrieval, and multimodal sentiment analysis, with 28x faster inference speed and only 1/3 of the parameters. Our findings suggest the possibility of learning compact and efficient visual-linguistic representations from low-level visual and audio signals without assuming the prior existence of text.
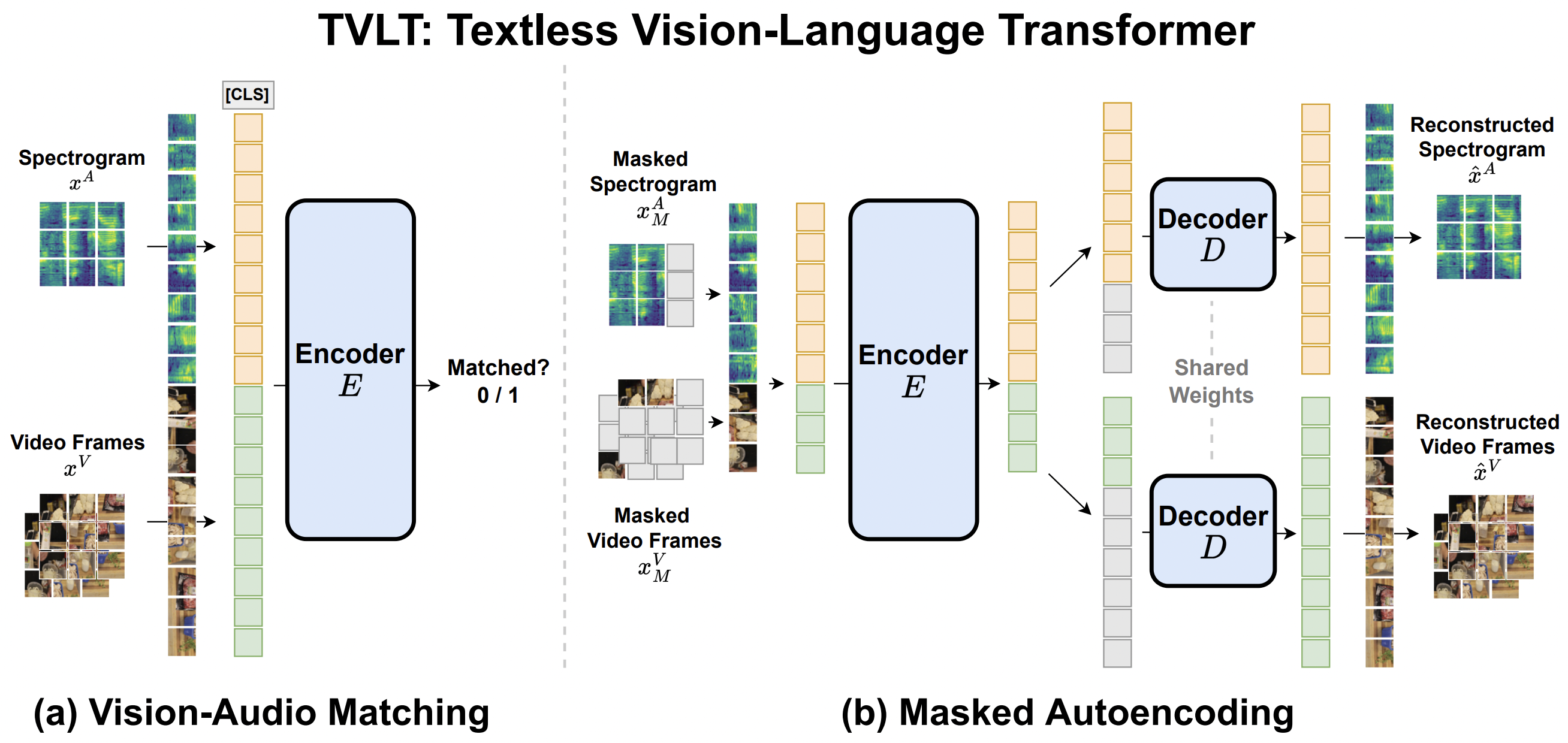
TVLT architecture. Taken from the original paper.
The original code can be found here. This model was contributed by Zineng Tang.
- TVLT is a model that takes both
pixel_valuesandaudio_valuesas input. One can use [TvltProcessor] to prepare data for the model. This processor wraps an image processor (for the image/video modality) and an audio feature extractor (for the audio modality) into one. - TVLT is trained with images/videos and audios of various sizes: the authors resize and crop the input images/videos to 224 and limit the length of audio spectrogram to 2048. To make batching of videos and audios possible, the authors use a
pixel_maskthat indicates which pixels are real/padding andaudio_maskthat indicates which audio values are real/padding. - The design of TVLT is very similar to that of a standard Vision Transformer (ViT) and masked autoencoder (MAE) as in ViTMAE. The difference is that the model includes embedding layers for the audio modality.
- The PyTorch version of this model is only available in torch 1.10 and higher.
[[autodoc]] TvltConfig
[[autodoc]] TvltProcessor - call
[[autodoc]] TvltImageProcessor - preprocess
[[autodoc]] TvltFeatureExtractor - call
[[autodoc]] TvltModel - forward
[[autodoc]] TvltForPreTraining - forward
[[autodoc]] TvltForAudioVisualClassification - forward