Highlights from Git 2.34
To celebrate this most recent release, here’s GitHub’s look at some of the most interesting features and changes introduced since last time.

The open source Git project just released Git 2.34 with features and bug fixes from over 109 contributors, 29 of them new. We last caught up with you on the latest in Git back when 2.33 was released. To celebrate this most recent release, here’s GitHub’s look at some of the most interesting features and changes introduced since last time.
Sparse index
In the past, we’ve talked about new Git features to make it possible to work with large repositories, like partial clones and sparse-checkout. For a complete description, check out the linked blog posts. But as a refresher, these two features work together to allow you to:
- Fetch or clone only part of a repository’s objects, and
- Only populate part of your working copy, typically scoped to a set of
sub-directories.
This pair of features is designed to create the illusion that you are working in a much smaller repository than you actually are. For instance, if your work takes place in an all-encompassing monorepo, your local copy only needs to contain the parts of the repository that you frequently work in.
But often, this illusion falls short. Why? The answer is the index. The index is the data structure Git uses to track what will be written the next time you run git commit, as well as to track the state of every file in your repository at the current point in history.
As you can imagine, even if you are working in a small corner of a large repository, the index still has to keep track of the repository’s entire contents, not just the parts that you are working in. Unfortunately, that overhead adds up: every time Git needs work with the index, it needs to parse and write out a lot of data that doesn’t affect the parts of your repository outside of your sparse checkout.
That’s changing in this release with the addition of a sparse-enabled index. Unlike the index of previous versions, this release enables the index to only track the parts of your repository that you care about. Specifically, it only contains entries for parts of your repository that are either in your sparse checkout, or at the boundary between your sparse checkout and the rest of the repository.
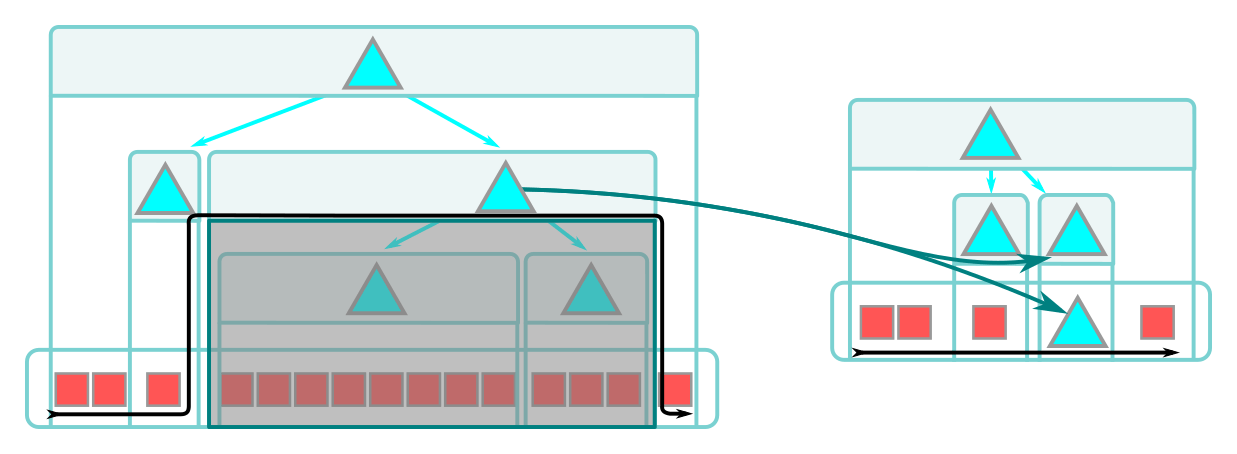
The high-level details here are that the index format now understands that specially marked directories indicate the boundary between the contents of your sparse checkout and the parts of your repository that you don’t have checked out. But the process of implementing this new format, teaching sub-commands how to use it, and making sure that the sparse index can be expanded to a full index is much more detailed.
For all of the details behind this exciting new feature, check out a comprehensive blog post published by Derrick Stolee last week: Making your monorepo feel small with Git’s sparse index.
[source, source, source, source, source, source, source, source]
Multi-pack reachability bitmaps
In a previous blog post, we talked about a new feature to enable reachability bitmaps to keep track of objects stored in multiple packs within your object store.
This release of Git contains the remaining components described in that blog post. If you haven’t read it, here’s a summary. When serving a fetch, a Git server needs to send the client everything reachable from the set of objects they want, less anything reachable from the set that they already have. (You can think of a clone as a “special case” fetch where the client wants everything and has nothing).
In order to compute this set efficiently, Git can use reachability bitmaps. One of these .bitmap files stores a set of bitmaps, each corresponding to some commit. The contents of an individual bitmap is a string of bits, one per object, indicating which objects are reachable from each commit.
In the past, the contents of a reachability bitmap were tied to the order of objects within a single packfile. This meant that a bitmap could only cover objects in one packfile. In other words, bitmaps were only useful if you could efficiently pack the entire contents of your repository down into a single packfile.
For many repositories, writing all objects into the same pack is completely feasible. But the effort it takes to write a pack (including searching for deltas between objects, compressing individual objects, and I/O cost) scales with the size of the pack you’re writing.
Git 2.34 introduces a new bitmap format that is instead tied to the contents of the multi-pack index file. This means that a bitmap can now flexibly represent objects in multiple packs, and server operators no longer need to repack their biggest repositories into a single pack in order to take full advantage of reachability bitmaps.
For more details, including some of the steps required to make this new feature work, see the aforementioned blog post.
A new default merge strategy
In an earlier blog post, we explained Git’s newest merge strategy: ort. Here are some of the basics:
When Git needs to merge two branches, it uses one of several “strategy” backends in order to resolve the changes or emit conflicts when two changes cannot be reconciled.
For years, Git has used a strategy called “recursive”. If you have ever done a merge in Git without passing -s <strategy>, then you have almost certainly used the recursive engine. Recursive behaves mostly like a standard three-way merge, with one exception. In the case of “criss-cross” merges (where there isn’t a single merge base), recursive merges multiple bases together in pairs (recursively) in order to produce a single tree which is then treated as the new merge base. This makes it possible to resolve cases where a traditional three-way merge might produce a conflict.
In recent versions of Git, there has been an ongoing effort to replace the recursive strategy with a new one called ort (short for “ostensibly recursive‘s twin”). Why do this? There are a few reasons, but perhaps the most compelling is that a rewrite allowed Git to implement a merge strategy that doesn’t operate on the index (that same one we talked about a couple of sections ago)!
ort does just that: it’s a full-blown rewrite of the merge strategy that aims to emulate the same concepts behind recursive while avoiding many of its long-standing performance and correctness problems. In a merge containing many renames, ort outperforms recursive by 500x. For a series of similar merges (like in a rebase operation), the speedup is over 9000x, in part due to ort’s ability to cache and reuse results from previous merges.
These numbers show off some of the worst-case scenarios for recursive, but in testing, ort consistently outperforms recursive with much less variance. In Git 2.34, ort is now the default merge strategy, so you should notice faster merges with fewer bugs just by upgrading.
For more details about the ort merge strategy, see our earlier blog post, or any one of a six-part series of posts written by ort‘s creator, Elijah Newren: part one, part two, part three, part four, part five, and part six.
[source]
Tidbits
Now that we have looked at some of the bigger features in detail, let’s turn to a handful of smaller topics from this release.
- You might be aware that Git allows you to sign your work by attaching your PGP signature to certain objects. For example, the Git project itself publishes tags signed by the maintainer in order to verify that each release comes from someone trustworthy.
But the experience of using GPG and maintaining keys can be somewhat
cumbersome. One alternative is to use a new feature of OpenSSH (released
back in OpenSSH 8.0) that allows using the SSH key you likely already have as a signing key.Git 2.34 includes support to take advantage of this feature and allows you to sign your work using SSH keys. To try it out, you can either set
user.signingKeyto the SSH key you want to use (for example, by asking your ssh-agent for a list withssh-add -L), or setgpg.formattosshandgpg.ssh.defaultKeyCommandtossh-add -Lin order to automatically use the first SSH key available.After configuring Git to sign objects using your SSH keys, you can use
git,
commit -Sgit merge -S, andgit tag -sas usual, and they will automatically use your SSH key.For more information about the new configuration options, including information about how to verify SSH signatures with an “allowed signers” file, check out the documentation.
-
If you’ve ever accidentally typed
git psuhwhen you meantpush, you
might have seen this message:$ git psuh git: 'psuh' is not a git command. See 'git --help'. The most similar command is pushYou have always been able to control this behavior by setting the
help.autoCorrectconfiguration. You can hide this advice by setting that
configuration tonever, or let Git automatically rerun the most similar
command for you immediately or with a delay (by settingimmediate, or a
real number of seconds to wait before rerunning your command).In Git 2.34, you can now configure Git to ask you interactively whether you
want to rerun your last operation with the suggested command by setting
help.autoCorrecttoprompt.[source]
In Git 2.34, a handful of patch series were focused on improving the performance of interacting with other repositories. Here’s a pair of tidbits that improves the performance of git fetch and git push:
- When fetching from a remote, your client needs to do some bookkeeping before
and after it receives a set of objects from the remote.Before anything happens, your client needs to figure out what it has in common with the remote it’s fetching from, and what commits it wants as a result. Previously, this process was somewhat wasteful: Git used to load commit objects directly when they could instead have been read from the
commit-graph, resulting in much improved performance. In Git 2.34, commits loaded in this code path use thecommit-graphwhen possible. The effect of this scales with the number of references in your repository: in an example repository with over 2 million references, it cuts the time it takes to fetch a single commit by more than half.[source]
-
Another patch series made a handful of improvements to updating local references when fetching, along with some changes to improve fetch negotiation, as well as skipping the connectivity check (which I’ll talk about in more detail in the next tidbit) when the receiving end had already verified the connectedness of the new objects. These changes together contributed similarly impressive performance improvements to the
git fetchcommand.[source]
You might have heard of “submodules,” the Git feature that allows combining multiple repositories by storing links to other repositories. Submodules have been somewhat neglected over the years, but this release brought renewed attention to the feature. Here are just some of the changes that enhance submodules:
- It might be a surprise to learn that, though the majority of Git is written in C, the original
git submodulecommand is actually a shell script!The Git project has been converting many of its subcommands written in other languages into C. Reimplementing subcommands as C programs means that
they can be read and written more easily, take advantage of Git’s comprehensive libraries, and avoid the overhead of spawning many processes, especially on platforms where the new process overhead is rather costly.In Git 2.34, many parts of the
git submodulecommand were rewritten in C.
This project was completed by Atharva Raykar, who is a Google Summer of Code
student. You can check out their final report here, along with Git’s other GSoC participant ZheNing Hu’s report here. -
While we’re on the topic of submodules, one thing you might not know is that
when using commands that deal with objects from both the submodule and the
repository containing it, the submodule is temporarily added as an alternate
object store of the other repository!Alternates are Git’s object borrowing mechanism, which allow you to in effect link multiple object stores together. When using a repository with alternates, any object lookups that fail to find an object are retried in that repository’s alternate.
In order to make both the objects in a submodule and the objects in the repository that contains that submodule available to
git grep(among a select set of
other commands), the submodule would temporarily be added as an alternate for the duration of that command.If you’re thinking to yourself, “this is a hack”, then you’re not alone. Git has made internal changes to parameterize many functions in terms of a repository (which is usually the global
the_repository). This allowed Git to avoid combining multiple repositories via alternates and instead make function calls by passing two (or more) separate repository instances. This enables Git to avoid hackily relying on the alternates mechanism, which produced less confusing and error-prone code as a result. -
One last submodule-related topic (though there are more we couldn’t fit here!). If you are cloning a repository that you know to contain submodules, it is often useful to pass the
--recurse-submodules, which will cause that repository’s submodules to be cloned and initialized, too.But other commands that can optionally recurse into submodules (like
git diff, for example) don’t themselves recurse into submodules by default, even when you cloned with--recurse-submodules. In Git 2.34, this is no longer the case, with one caveat: when cloning with--recurse-submodules, other commands only recurse into submodules if thesubmodule.stickyRecursiveCloneconfiguration is set, to prevent commands from unintentionally running in submodules.[source]
Now that I’ve listed out a few of the submodule-related changes, let’s get back
to the rest of the tidbits:
- If you’ve ever scripted around Git, you have almost certainly run into Git’s
cat-fileplumbing command. This tool can be used to print out a single object (by providing the object name as an argument), a stream of objects (by providing line-delimited object names over stdin), or all objects in your repository (with--batch-all-objects).This low-level command accidentally took into account replace refs, which produced confusing results when combined with
--batch-all-objects, resulting in it not actually showing all objects in your repository if some were hidden byrefs/replace.Dropping support for replacement refs made it possible for
cat-fileto reuse some information when it is given--batch-all-objects. Namely, to populate the list of objects, it iterates each object in each pack and therefore knows the byte offset within each pack where each object can be found. Previous versions of Git did not reuse this information when looking up objects to parse them, but Git 2.34 retains this information.This makes it possible to process an object’s metadata much more quickly by avoiding having to locate it twice. In a copy of
torvalds/linux, the time it takes to print the name and type of each object (for the curious, that’sgit cat-file --batch-check='%(objectname) %(objecttype)' --batch-all-objects --unordered) dropped from 8.1 seconds to just 4.3 seconds.[source]
-
There has been a recent concerted effort to remove some memory leaks from Git’s code. Unlike library code, Git typically has a very short runtime. This makes the need to free allocated memory much less urgent, since if a process is about to exit, all memory allocated to it will be “freed” by the operating system.
A recent patch has made it so that Git’s integration tests can be run in a mode that ensures no memory is leaked (by setting
GIT_TEST_PASSING_SANITIZE_LEAK=truein the environment). Since Git’s test suite still contains memory leaks in some tests, a new mode was added to run only tests that have been specifically marked as being leak-free. That way, when Git is compiled with leak detection (by runningmake SANITIZE=leak), you can easily spot regressions in tests that were supposedly leak-free.Building off this new infrastructure, there have been many patch series that remove leaks from the code in various places.
[source, source, source, source, source, source, source, source, source, source, source]
-
When you need to get some debugging information out of a Git process, like what version you’re running, or how much time it spent in a particular region, the trace2 mechanism is a good choice. Often, looking at these logs is like looking at a piece of a puzzle. For example, when you run
git fetch, you actually rungit fetch-pack, which then invokesgit upload-packon the remote, which itself invokesgit pack-objects.Trace2 output includes information about when child processes are started and stopped (and consequently, how long they took to run), but what if you’re trying to figure out something more basic than that, like what process you were started by? In other words, if you’re stuck looking at output from a slow
git pack-objects, how do you figure out whether it was a fetch (in which case it would have been started byupload-pack) or part of a repository repack (which here would be started bygit repack)?Git 2.34 includes additional debugging information in trace2 output to indicate the full ancestry of a process, so you can easily read out the name of the program a process was started by, like so:
$ cat trace2.log 21:14:38.170730 common-main.c:48 version 2.34.0.rc1.14.g88d915a634 21:14:38.170810 common-main.c:49 start /home/ttaylorr/src/git/git pack-objects git pack-objects --revs --thin --stdout --progress --delta-base-offset 21:14:38.174325 compat/linux/procinfo.c:170 cmd_ancestry sh <- git-upload-pack <- sh <- git <- zsh <- sshd <- systemd(Above, you can see that
pack-objectswas run bygit upload-pack, which was run bysh–that’s where we inserted the trace point viauploadpack.packObjectsHook, which was run bygit, in my shell, oversshd, which was started bysystemd.) -
In a previous post, we talked about the background maintenance daemon, which can be used to perform routine repository maintenance in the background (like pre-fetching, or repacking the objects in your repository).
When this feature was first released back in Git 2.31, it had support for
cronon Linux,launchctlon macOS, andschtaskson Windows. Git 2.34 brings support for systemd-based timers on Linux. This has a few benefits overcron:cronmay not be available everywhere, and usingsystemdisolates each service into its own cgroup and writes its logs separately.If you want to use
systemdinstead of the default scheduler, you can run:$ git maintenance start --scheduler=systemd[source]
-
In a previous blog post, we talked about how
git rebaseworks, and how to move a complicated branching structure elsewhere in your repository’s history.The brief history is that this used to be done with the
--preserve-mergesoption, which attempted to replay merges elsewhere in history. Confusingly, this mode uses rebase’s interactive machinery internally, so attempting to manually edit the rebase sequence (withgit rebase -i) often produced counterintuitive results.The
--rebase-mergesoption fixed many of these issues and has been the recommended replacement of--preserve-mergesfor some time now. In Git 2.34, the--preserve-mergesoption is now gone for good.[source]
-
You might have used
git grepto quickly search through your code. But you might not have known thatgit loghas a--grep=<expression>option, which allows you to filter through commits produced bygit logto only show ones whose commit messages match the provided expression.In previous versions, the
--grepoption only filtered down which results were presented in the output ofgit log. But in Git 2.34,git lognow knows how to colorize the parts of its output that matched the provided expression, like so:
[source]
-
Last but not least, if you’re using Git in a terminal on Windows, you might have noticed that your terminal is left in a weird state after running
git commit, orgit rebase, like in this issue.This was because Git shares its terminal with any child processes it spawns, including your
$EDITOR. If your editor sets special terminal settings but does not clear them upon exiting, it can leave your terminal in a broken state.Git 2.34 introduces functionality to save and restore the terminal settings before and after launching your editor. That means that even misbehaving editors cannot corrupt your terminal since it will always be restored to the state it was in before launching the editor.
[source]
The rest of the iceberg
That’s just a sample of changes from the latest release. For more, check out the release notes for 2.34, or any previous version in the Git repository.
Tags:
Written by
Related posts

Game Off 2024 theme announcement
GitHub’s annual month-long game jam, where creativity knows no limits! Throughout November, dive into your favorite game engines, libraries, and programming languages to bring your wildest game ideas to life. Whether you’re a seasoned dev or just getting started, it’s all about having fun and making something awesome!

Highlights from Git 2.47
Git 2.47 is here, with features like incremental multi-pack indexes and more. Check out our coverage of some of the highlights here.

Leading the way: 10 projects in the Open Source Zone at GitHub Universe 2024
Let’s take a closer look at some of the stars of the Open Source Zone at GitHub Universe 2024 🔎