Topic Suggestions for Millions of Repositories
We recently launched Topics, a new feature that lets you tag your repositories with descriptive words or phrases, making it easy to discover projects and explore GitHub.com. Topic suggestions on…
We recently launched Topics, a new feature that lets you tag your repositories with descriptive words or phrases, making it easy to discover projects and explore GitHub.com. Topic suggestions on public repositories, provides a quick way to add tags to repositories.

These suggestions are the result of recent data science work at GitHub. We applied concepts from text mining, natural language processing (NLP), and machine learning to build a topic extraction framework.
Solving the cold-start problem for topic suggestions
Because Topics is a brand new concept at GitHub, we started with no cues from users on what defined a topic and what type of topics they would typically add to their repositories. Given our focus on improving discoverability, internally we defined Topics as any “word or phrase that roughly describes the purpose of a repository and the type of content it encapsulates“. These can be words such as “data science”, “nlp”, “scikit-learn”, “clustering algorithm”, “jekyll plugin”, “css template”, or “python”.
While no tag or label-type feature existed prior to the start of this project, we did have a rich set of textual information to start from. At its core, GitHub is a platform for sharing software with other people, and some of the data typically found in a repository provides information to humans rather than instructions for computers. Repository names, descriptions, and READMEs are text that communicate functionality, use case, and features to human readers. That’s where we started.
Repo-Topix: our topics extraction framework
We developed a topic extraction framework, called repo-topix, to learn from the human-readable text that users provide in repo names, descriptions, and READMEs written by developers about their projects by incorporating methods from text mining, NLP, and supervised machine learning. At a high level, repo-topix does three things:
- Generates candidate topics from natural language text by incorporating data from millions of other repositories
- Selects the best topics from the set of candidates
- Finds similarities and relationships in topics to facilitate discoverability
Below, we describe each step of the repo-topix framework in greater technical detail.
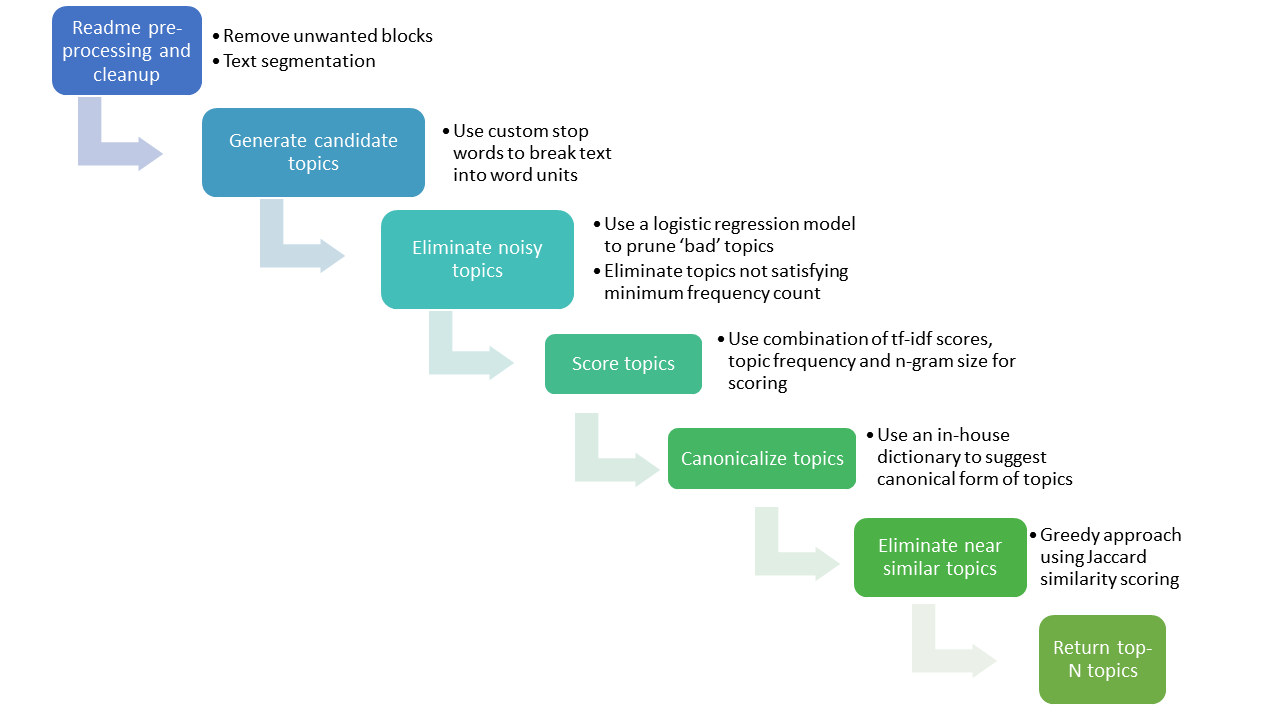
Generating candidate topics from natural language text
Preprocessing of READMEs
While README files within GitHub.com tend to be formatted using Markdown and reStructuredText with fairly lightweight formatting, there are certain sections such as code blocks, tables, and image links that are not useful for topic suggestions. For example, month names from within a table would not be useful to a user.
To extract text sections of interest, we developed a heuristics-based README tagger that marks sections in the README file as relevant or non-relevant. This simple tagger uses common formatting cues such as indentation, spacing, and use of backticks to determine “noise sections” and “valid text sections”. The use of a grammar-based parser was unnecessary as we only care about useful text sections and regard everything else in a README as noise.
Once we extract text sections of interest, we perform basic cleanup to remove file extensions, HTML tags, paths, and hosts from further processing, as these are more distracting than useful. Finally, the remaining text gets segmented into coarse-grained units using punctuation marks as well as README section markers such as contiguous hash symbols.
Finding candidate topics
We use the cleaned text from the previous step to generate candidate topics by eliminating low-information words and breaking the remaining text into strings of one or multiple consecutive words, called n-grams. Like any text, our sources contain many words that are so common that they do not contain distinguishing information. Called stop words, these typically include determiners like “is”, “the”, “are”, conjunctions like “and,”, “but”, and “yet”, and so on. Given our specialized domain, we created a custom stop word list that included words that are practically ubiquitous in our source text; for example, “push”, “pull”, “software”, “tool”, “var”, “val”, and “package.” The custom stop word list provides an efficient way to finding potential topics, as we simply take the resulting phrases left between eliminated words. For example, “this open source software is used for web scraping and search” produces three candidate topics: 1. “open source,” 2. “web scraping,” 3. “search”. This process eliminates the need for brute-force n-gram generation which could end up producing a large number of n-grams depending the length of the README files being processed. After testing internally among GitHub staff, we found that n-grams made up of many words tended to be too specific (e.g. “machine-learning-tutorial-part-1-intro”), so we limit candidate topics to n-grams of size 4 or less.
Selecting best topics
Eliminating low quality topics
While some of the generated word units in the previous step would be meaningful as topics, some could also be plain noise. We have a few strategies for pruning noise and unpromising candidate topics. The first is simply to eliminate phrases with low frequency counts. For example, if we had the following candidates with their corresponding counts, we could eliminate some of the low frequency topics:
machine learning tutorial part 1 (1)
machine learning (5)
beginners data science course (1)
topic modeling (3)From the above, we could easily eliminate topics that don’t satisfy a minimum frequency count threshold. However, this method doesn’t prune out topics with unwanted grammatical structure or word composition. For example, words and phrases like “great”, “cool”, “running slowly”, “performing operations”, “install database” and “@kavgan” (a GitHub handle) are not great topics for a repository. To aggressively prune out these keywords, we developed a supervised logistic regression model, trained to classify a topic as “good” (positive) or “bad” (negative). We call this the keyword filtering model.
We manually gathered about 300 training examples balanced across the positive (good topics) and negative (bad topics) categories. Because of this manual process with no input from users, our training data is actually fairly small. While it’s possible to learn from the actual words that make up a topic when you have a very large training set, with limited training data we used features that draw on the meta-information of the training examples so that our model does not just memorize specific words. For instance, one of the features we used was the part-of-speech usage within topics. If the model learns that single word verbs are often considered bad topics, the next time it sees such an occurrence, it would help eliminate such words from further consideration. Other features we used were occurrence of user names, n-gram size of a phrase, length of a phrase, and numeric content within a phrase. Our classifier is tuned for high recall in order to keep as many phrases as possible and prune obviously incorrect ones.
With time, we plan to include feedback from users to update the keyword filtering model. For example, highly accepted topics can serve as positive training examples and highly rejected topics can either be used as stop words or used as negative examples in our model. We believe that this incremental update would help weed out uninteresting topics from the suggestions list.
Scoring candidate topics
Instead of treating all remaining candidate topics with equal importance, we rank the candidates by score to return only the top-N promising topics instead of a large list of arbitrary topics. We experimented with several scoring schemes. The first scoring approach measures the average strength of association of words in a phrase using pointwise mutual information (PMI) weighted by the frequency count of the phrases. The second approach we tried uses the average tf-idf scores of individual words in a phrase weighted by the phrase frequency (if it’s more than one word long) and n-gram size.
We found that the first scoring strategy favored topics that were unique in nature because of the way PMI works when data is fairly sparse: unique phrases tend to get very high scores. While some highly unique phrases can be interesting, some unique phrases can just be typos or even code snippets that were not formatted as code. The second approach favored phrases that were less unique and relatively frequent. We ended up using the tf-idf based scoring as it gave us a good balance between uniqueness of a topic and relevance of a topic to a repository. While our tf (term frequency) scoring is based on local counts, our idf (inverse document frequency) weighting is based on a large dictionary of idf scores built using the unstructured content from millions of public READMEs. The idf weights essentially tell us how common or unique a term is globally. The intuition is that the more common a term, the less information it carries and should thus have a lower weight. For example, in the GitHub domain, the term “application” is much more common than terms such as “machine”, “learning”, or “assignment” and this is clearly reflected by their idf weights as shown below:
| word | idf |
|---|---|
| application | 4.300 |
| machine | 7.169 |
| learning | 7.818 |
| assignment | 8.480 |
If a phrase has many words with low idf weighting, then its overall score should be lower compared to a phrase with more significant words – this is the intuition behind our tf-idf scoring strategy. As an example, assuming that the normalized tf of each word above is 0.5, the average tf-idf score for “machine-learning-application” would be 3.21 and the average tf-idf score for “machine-learning-assignment” would be 3.91. The former has a lower score because the term “application” is more ubiquitous and has a lower idf score than the term “assignment”.
In addition to the base tf-idf scoring, we are also experimenting with some additional ideas such as boosting scores of those phrases that tend to occur earlier in a document and aren’t unique to a few repositories. These minor tweaks are subject to change based on our internal evaluation.
Discovering similar topics
Canonicalizing topics to address character level topic differences and inflections
Because different users can express similar phrases in different ways, the generated topics can also vary from repository to repository. For example, we have commonly seen these variation of topics with different repositories:
neural-network
neural-networks
neuralnetwork
neuralnetworkstopic-models
topic-modelling
topic-modeling
topicmodel
topicmodelingmachinelearning-algorithms
machine-learning-algorithmTo keep topic suggestions fairly consistent, we use a dictionary to canonicalize suggested topics. Instead of suggesting the original topics discovered, we suggest a canonicalized version of the topic if present in our dictionary. This in-house dictionary was built using all non-canonicalized topics across public repositories. The non-canonicalized topics give us cues as to which topics are most commonly used and which ones can be grouped together as being equivalent. We currently use a combination of edit-distance, stemming, and word-level Jaccard similarity to group similar topics together. Jaccard similarity in our case estimates how similar two phrases are by comparing members of two sets to see which members are shared and which are distinct. With this, phrases that share many words can be grouped together.
Near similar topics
While it’s possible to suggest all top-scoring topics, some topics may be fairly repetitive, and the set of topics returned may not provide enough variety for labeling a repository. For example, the following top-scoring topics (from an actual repository), while valid and meaningful, are not interesting and lack variety as it captures different granularity of similar topics:
machine learning
deep learning
general-purpose machine learning
machine learning library
machine learning algorithms
distributed machine learning
machine learning framework
deep learning library
support vector machine
linear regressionWe use a greedy topic selection strategy that starts with the highest-scoring topic. If the topic is similar to other lower-scoring topics, the lower-scoring topics are dropped from consideration. We repeat this process iteratively using the next highest-scoring topic until all candidate topics have been accounted for. For the example above, the final set of topics returned to the user would be as follows:
machine learning
deep learning
support vector machine
linear regressionWe use word-level Jaccard similarity when computing similarity between phrases, because it’s known to work well for short phrases. It also produces a score between 0-1, making it easy to set thresholds.
Evaluation
As topic labels were not available during the development of repo-topix, we needed to get a rough approximation of how well the suggested topics describe a repository. For this rough approximation, we used the description text for repositories since descriptions often provide insights into the function of a repository. If indeed the auto-suggested topics are not completely arbitrary, there should be some amount of overlap between suggested topics and the description field. For this evaluation, we computed ROUGE-1 precision and recall. ROUGE is an n-gram overlap metric that counts the number of overlapping units between a system summary (suggested topics in our case) and a gold standard summary (description in our case). We performed this evaluation on roughly 127,000 public repositories with fairly long descriptions. These are our most recent results:
Repos with no topic suggestions: ~28%
Average ROUGE-1 Recall: 0.259
Average ROUGE-1 Precision: 0.372
F-Measure: 0.306The ROUGE recall above tells us quantitatively how much of the description is being captured by topic suggestions and precision tells us what proportion of the suggestion words are words that are also in the description. Based on the results we see that there is some overlap as expected. We’re not looking for perfect overlap, but some level of overlap after disregarding all stop words.
Summary
Our topics extraction framework is capable of discovering promising topics for any public repository on GitHub.com. Instead of applying heavy NLP and complex parsing algorithms within our framework (e.g. grammar-based markdown parsing, dependency parsing, chunking, lemmatization), we focused on using lightweight methods that would easily scale as GitHub.com’s repository base grows over the years. For many of our tasks, we leverage the volume in available data to build out reusable dictionaries such as the IDF dictionary, which was built using all public README files, a custom stop-word list, and a canonicalization dictionary for topics. While we currently depend on the presence of README files to generate suggestions, in the future we hope to make suggestions by looking at any available content within a repository. Most of the core topics extraction code was developed using Java and Python within the Spark framework.
Future plans
Our plan for the near future is to evaluate the usage of suggested topics as well as manually created topics to continuously improve suggestions shown to users. Some of the rejected topics could feed into our topics extraction framework as stop words or as negative examples to our keyword filtering model. Highly accepted topics could add positive examples to our keyword filtering model and also provide lessons on the type of topics that users care about. This would provide cues as to what type of “meta-information” users add to their repositories in addition to the descriptive terms found within README files. We also plan to explore topic suggestions on private repositories and with GitHub Enterprise in a way that fully respects privacy concerns and eliminates certain data dependencies.
Beyond these near term goals, our vision for using topics is to build an ever-evolving GitHub knowledge graph containing concepts and mapping how they relate to each other and to the code, people, and projects on GitHub.
References
These are references to some of the libraries that we used:
- https://spark.apache.org/
- https://spark.apache.org/mllib/
- https://tartarus.org/martin/PorterStemmer/
Work with us
Want to work on interesting problems like code analysis, social network analysis, recommendations engine and improving search relevance? Apply here!
Topics Data Team
- Kavita Ganesan, @kavgan, Senior Data Scientist – Machine Learning
- Rafer Hazen, @rafer, Engineering Manager – Data Engineering
- Frances Zlotnick, @franniez, Senior Data Scientist – Analytics
Written by
Related posts

Breaking down CPU speed: How utilization impacts performance
The Performance Engineering team at GitHub assessed how CPU performance degrades as utilization increases and how this relates to capacity.

How to make Storybook Interactions respect user motion preferences
With this custom addon, you can ensure your workplace remains accessible to users with motion sensitivities while benefiting from Storybook’s Interactions.

GitHub Enterprise Cloud with data residency: How we built the next evolution of GitHub Enterprise using GitHub
How we used GitHub to build GitHub Enterprise Cloud with data residency.