
Схема Google Cloud Search — это структура JSON, которая определяет объекты, свойства и параметры, которые будут использоваться при индексировании и запросе ваших данных. Ваш соединитель контента считывает данные из вашего репозитория и на основе зарегистрированной схемы структурирует и индексирует данные.
Вы можете создать схему, предоставив объект схемы JSON API и затем зарегистрировав его. Вы должны зарегистрировать объект схемы для каждого из ваших репозиториев, прежде чем сможете индексировать свои данные.
В этом документе описаны основы создания схемы. Информацию о том, как настроить схему для улучшения качества поиска, см. в разделе Улучшение качества поиска .
Создать схему
Ниже приведен список шагов, которые необходимо выполнить для создания схемы Cloud Search:
- Определите ожидаемое поведение пользователя
- Инициализировать источник данных
- Создать схему
- Полный пример схемы
- Зарегистрируйте свою схему
- Индексируйте свои данные
- Проверьте свою схему
- Настройте свою схему
Определите ожидаемое поведение пользователя
Прогнозирование типов запросов, которые делают ваши пользователи, помогает определить стратегию создания схемы.
Например, при отправке запросов к базе данных фильмов вы можете ожидать, что пользователь сделает такой запрос, как «Покажите мне все фильмы с Робертом Редфордом в главной роли». Поэтому ваша схема должна поддерживать результаты запросов, основанные на «всех фильмах с определенным актером».
Чтобы определить схему, отражающую модели поведения пользователя, рассмотрите возможность выполнения следующих задач:
- Оцените разнообразный набор желаемых запросов от разных пользователей.
- Определите объекты, которые могут использоваться в запросах. Объекты — это логические наборы связанных данных, например фильм в базе данных фильмов.
- Определите свойства и значения, составляющие объект и которые могут использоваться в запросах. Свойства — это индексируемые атрибуты объекта; они могут включать примитивные значения или другие объекты. Например, объект фильма может иметь такие свойства, как название фильма и дата выпуска, в качестве примитивных значений. Объект фильма может также содержать другие объекты, например актеров, которые имеют свои собственные свойства, такие как имя или роль.
- Приведите примеры допустимых значений свойств. Значения — это фактические данные, индексированные для свойства. Например, название одного фильма в вашей базе данных может быть «В поисках утраченного ковчега».
- Определите параметры сортировки и ранжирования, которые нужны вашим пользователям. Например, при запросе фильмов пользователи могут захотеть сортировать их в хронологическом порядке и ранжировать по рейтингу аудитории, а не сортировать по алфавиту по названию.
- (необязательно) Подумайте, представляет ли одно из ваших свойств более конкретный контекст, в котором может выполняться поиск, например должность или отдел пользователя, чтобы можно было предоставлять предложения автозаполнения на основе контекста. Например, при поиске в базе данных фильмов пользователи могут интересоваться только фильмами определенного жанра. Пользователи будут определять, какой жанр они хотят возвращать в результате поиска, возможно, как часть своего профиля пользователя. Затем, когда пользователь начинает вводить запрос фильмов, в рамках автозаполнения предлагаются только фильмы предпочитаемого им жанра, например «боевики».
- Составьте список этих объектов, свойств и примеров значений, которые можно использовать при поиске. (Подробную информацию об использовании этого списка см. в разделе «Определение параметров оператора ».)
Инициализируйте свой источник данных
Источник данных представляет собой данные из репозитория, которые были проиндексированы и сохранены в Google Cloud. Инструкции по инициализации источника данных см. в разделе Управление сторонними источниками данных .
Результаты поиска пользователя возвращаются из источника данных. Когда пользователь нажимает на результат поиска, Cloud Search направляет пользователя к фактическому элементу, используя URL-адрес, указанный в запросе на индексирование.
Определите свои объекты
Фундаментальной единицей данных в схеме является объект , также называемый « объектом схемы », который представляет собой логическую структуру данных. В базе данных фильмов одной логической структурой данных является «фильм». Другим объектом может быть «человек», представляющий актеров и съемочную группу, участвующих в фильме.
Каждый объект в схеме имеет ряд свойств или атрибутов, описывающих объект, например название и продолжительность фильма или имя и дату рождения человека. Свойства объекта могут включать примитивные значения или другие объекты.
На рис. 1 показаны объекты Movie и Person и связанные с ними свойства.
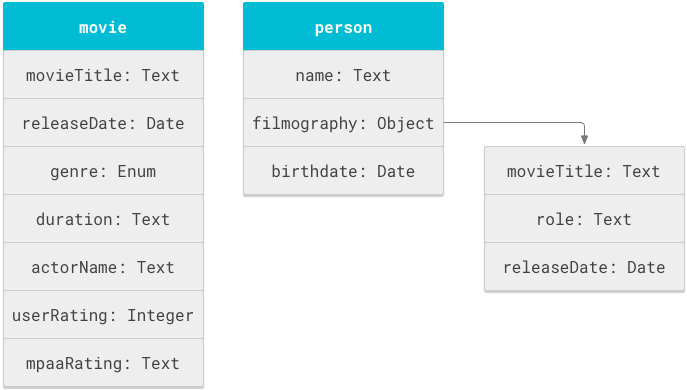
Схема Cloud Search — это, по сути, список операторов определения объекта, определенных в теге objectDefinitions . В следующем фрагменте схемы показаны операторы objectDefinitions для объектов схемы фильма и человека.
{
"objectDefinitions": [
{
"name": "movie",
...
},
{
"name": "person",
...
}
]
}
При определении объекта схемы вы указываете name объекта, которое должно быть уникальным среди всех других объектов в схеме. Обычно вы используете значение name , описывающее объект, например movie для объекта фильма. Служба схемы использует поле name в качестве ключевого идентификатора для индексируемых объектов. Дополнительную информацию о поле name см. в разделе «Определение объекта» .
Определить свойства объекта
Как указано в ссылке на ObjectDefinition , за именем объекта следует набор options и список propertyDefinitions . options могут дополнительно состоять из freshnessOptions и displayOptions . Параметры freshnessOptions используются для настройки рейтинга поиска в зависимости от свежести элемента. displayOptions используются для определения того, отображаются ли определенные метки и свойства в результатах поиска объекта.
В разделе propertyDefinitions вы определяете свойства объекта, такие как название фильма и дата выпуска.
В следующем фрагменте показан объект movie с двумя свойствами: movieTitle и releaseDate .
{
"objectDefinitions": [
{
"name": "movie",
"propertyDefinitions": [
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
"operatorOptions": {
"operatorName": "title"
}
},
"displayOptions": {
"displayLabel": "Title"
}
},
{
"name": "releaseDate",
"isReturnable": true,
"isSortable": true,
"datePropertyOptions": {
"operatorOptions": {
"operatorName": "released",
"lessThanOperatorName": "releasedbefore",
"greaterThanOperatorName": "releasedafter"
}
},
"displayOptions": {
"displayLabel": "Release date"
}
...
]
}
]
}
PropertyDefinition состоит из следующих элементов:
- строка
name. - Список параметров, не зависящих от типа, например
isReturnableв предыдущем фрагменте. - Тип и связанные с ним параметры, специфичные для типа, такие как
textPropertyOptionsиretrievalImportanceв предыдущем фрагменте. -
operatorOptionsописывающий, как свойство используется в качестве оператора поиска. - Один или несколько
displayOptions, напримерdisplayLabelв предыдущем фрагменте.
name свойства должно быть уникальным в пределах содержащего его объекта, но то же имя может использоваться в других объектах и подобъектах. На рисунке 1 название фильма и дата выхода определены дважды: один раз в объекте movie и еще раз в подобъекте filmography объекта person . Эта схема повторно использует поле movieTitle , поэтому схема может поддерживать два типа поведения поиска:
- Показывать результаты фильмов , когда пользователи ищут название фильма.
- Показывать людям результаты , когда пользователи ищут название фильма, в котором играл актер.
Аналогичным образом схема повторно использует поле releaseDate , поскольку оно имеет одинаковое значение для двух полей movieTitle .
При разработке собственной схемы подумайте, как в вашем репозитории могут быть связанные поля, содержащие данные, которые вы хотите объявить в своей схеме более одного раза.
Добавить параметры, независимые от типа
PropertyDefinition перечисляет общие параметры функции поиска, общие для всех свойств, независимо от типа данных.
-
isReturnable— указывает, идентифицирует ли свойство данные, которые должны быть возвращены в результатах поиска через API запросов. Все свойства фильма в качестве примера являются возвращаемыми. Невозвратные свойства можно использовать для поиска или ранжирования результатов без возврата пользователю. -
isRepeatable— указывает, разрешено ли для свойства несколько значений. Например, у фильма есть только одна дата выхода, но в нем может быть несколько актеров. -
isSortable— указывает, что свойство можно использовать для сортировки. Это не может быть правдой для свойств, которые повторяются. Например, результаты фильмов можно отсортировать по дате выхода или рейтингу аудитории. -
isFacetable— указывает, что свойство можно использовать для создания фасетов . Фасет используется для уточнения результатов поиска: пользователь видит первоначальные результаты, а затем добавляет критерии или фасеты для дальнейшего уточнения этих результатов. Этот параметр не может быть истинным для свойств, тип которых — объект, и для установки этого параметра значениеisReturnableдолжно быть истинным. Наконец, этот параметр поддерживается только для свойств enum, boolean и text. Например, в нашей примерной схеме мы могли бы создать фасетыgenre,actorName,userRatingиmpaaRating, чтобы их можно было использовать для интерактивного уточнения результатов поиска. -
isWildcardSearchableуказывает, что пользователи могут выполнять поиск по подстановочным знакам для этого свойства. Эта опция доступна только в свойствах текста. То, как работает поиск по подстановочным знакам в текстовом поле, зависит от значения, установленного в поле strictMatchWithOperator . Если дляexactMatchWithOperatorустановлено значениеtrue, текстовое значение маркируется как одно атомарное значение, и для него выполняется поиск по подстановочным знакам. Например, если текстовое значение —science-fiction, ему соответствует запрос с подстановочными знакамиscience-*. Если дляexactMatchWithOperatorустановлено значениеfalse, текстовое значение маркируется и для каждого токена выполняется поиск по подстановочным знакам. Например, если текстовое значение — «научная фантастика», запросы с подстановочными знакамиsci*илиfi*соответствуют элементу, ноscience-*не соответствуют ему.
Все эти общие параметры функции поиска являются логическими значениями; все они имеют значение по умолчанию false , и для их использования необходимо установить значение true .
В следующей таблице показаны логические параметры, которым присвоено значение true для всех свойств объекта movie :
| Свойство | isReturnable | isRepeatable | isSortable | isFacetable | isWildcardSearchable |
|---|---|---|---|---|---|
movieTitle | истинный | истинный | |||
releaseDate | истинный | истинный | |||
genre | истинный | истинный | истинный | ||
duration | истинный | ||||
actorName | истинный | истинный | истинный | истинный | |
userRating | истинный | истинный | |||
mpaaRating | истинный | истинный |
И для genre , и actorName isRepeatable установлено значение true , поскольку фильм может принадлежать более чем к одному жанру и обычно имеет более одного актера. Свойство не может быть сортируемым, если оно повторяется или содержится в повторяемом подобъекте.
Определить тип
В справочном разделе PropertyDefinition перечислены несколько xxPropertyOptions , где xx — определенный тип, например boolean . Чтобы установить тип данных свойства, необходимо определить соответствующий объект типа данных. Определение объекта типа данных для свойства устанавливает тип данных этого свойства. Например, определение textPropertyOptions для свойства movieTitle указывает, что заголовок фильма имеет текстовый тип. В следующем фрагменте показано свойство movieTitle , в котором textPropertyOptions задает тип данных.
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
...
},
...
},
Свойство может иметь только один связанный тип данных. Например, в нашей схеме фильма releaseDate может быть только датой (например, 13 2016-01-13 ) или строкой (например, January 13, 2016 ), но не тем и другим одновременно.
Вот объекты типов данных, используемые для указания типов данных для свойств в примерной схеме фильма:
| Свойство | Объект типа данных |
|---|---|
movieTitle | textPropertyOptions |
releaseDate | datePropertyOptions |
genre | enumPropertyOptions |
duration | textPropertyOptions |
actorName | textPropertyOptions |
userRating | integerPropertyOptions |
mpaaRating | textPropertyOptions |
Тип данных, который вы выбираете для свойства, зависит от ожидаемых вариантов использования. В воображаемом сценарии этой схемы фильма ожидается, что пользователи захотят сортировать результаты в хронологическом порядке, поэтому releaseDate является объектом даты. Если, например, предполагался вариант использования для сравнения декабрьских выпусков разных лет с январскими выпусками, тогда может оказаться полезным строковый формат.
Настройка параметров для конкретного типа
Справочный раздел PropertyDefinition содержит ссылки на параметры для каждого типа. Большинство параметров, специфичных для типа, являются необязательными, за исключением списка possibleValues в enumPropertyOptions . Кроме того, опция orderedRanking позволяет ранжировать значения относительно друг друга. В следующем фрагменте показано свойство movieTitle с textPropertyOptions задающим тип данных, и с параметром, специфичным для типа, retrievalImportance .
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
...
},
...
}
Ниже приведены дополнительные параметры, специфичные для типа, используемые в примерной схеме:
| Свойство | Тип | Опции для конкретного типа |
|---|---|---|
movieTitle | textPropertyOptions | retrievalImportance |
releaseDate | datePropertyOptions | |
genre | enumPropertyOptions | |
duration | textPropertyOptions | |
actorName | textPropertyOptions | |
userRating | integerPropertyOptions | orderedRanking , maximumValue |
mpaaRating | textPropertyOptions |
Определить параметры оператора
Помимо параметров, специфичных для типа, каждый тип имеет набор необязательных operatorOptions Эти параметры описывают, как свойство используется в качестве оператора поиска. В следующем фрагменте показано свойство movieTitle с textPropertyOptions задающим тип данных, а также с параметрами, зависящими от типа, retrievalImportance operatorOptions .
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
"operatorOptions": {
"operatorName": "title"
}
},
...
}
Каждый operatorOptions имеет имя operatorName , например title для movieTitle . Имя оператора является оператором поиска свойства. Оператор поиска — это фактический параметр, который, как вы ожидаете, будут использовать пользователи при сужении поиска. Например, для поиска фильмов по названию пользователь должен ввести title:movieName , где movieName — это название фильма.
Имена операторов не обязательно должны совпадать с именем свойства. Вместо этого вам следует использовать имена операторов, которые отражают наиболее распространенные слова, используемые пользователями в вашей организации. Например, если ваши пользователи предпочитают термин «имя» вместо «название» для названия фильма, тогда имя оператора должно быть установлено на «имя».
Вы можете использовать одно и то же имя оператора для нескольких свойств, если все свойства разрешаются к одному и тому же типу. При использовании общего имени оператора во время запроса извлекаются все свойства, использующие это имя оператора. Например, предположим plot что объект фильма имеет plotSummary plotSynopsis , и каждое из этих свойств имеет имя operatorName . Пока оба этих свойства являются текстовыми ( textPropertyOptions ), один запрос с использованием оператора поиска plot извлекает их оба.
В дополнение operatorName свойства, которые можно сортировать, могут иметь поля lessThanOperatorName и greaterThanOperatorName operatorOptions . Пользователи могут использовать эти параметры для создания запросов на основе сравнения с отправленным значением.
Наконец, textOperatorOptions имеет поле exactMatchWithOperator в operatorOptions . Если вы установили для exactMatchWithOperator значение true , строка запроса должна соответствовать всему значению свойства, а не просто находиться в тексте. Текстовое значение рассматривается как одно атомарное значение при поиске операторов и сопоставлении фасетов.
Например, рассмотрите возможность индексирования объектов Book или Movie со свойствами жанра. Жанры могут включать «Научную фантастику», «Науку» и «Художественную литературу». Если для exactMatchWithOperator установлено значение false или опущено, поиск по жанру или выбор фасета «Наука» или «Художественная литература» также вернет результаты для «Научная фантастика», поскольку текст токенизирован и существуют токены «Наука» и «Художественная литература». в «Научная фантастика». Если exactMatchWithOperator имеет true , текст обрабатывается как один токен, поэтому ни «Science», ни «Fiction» не соответствует «Science-Fiction».
(Необязательно) Добавьте раздел displayOptions .
В конце любого раздела propertyDefinition есть необязательный раздел displayOptions . Этот раздел содержит одну строку displayLabel . displayLabel — это рекомендуемая, удобная для пользователя текстовая метка свойства. Если свойство настроено для отображения с помощью ObjectDisplayOptions , эта метка отображается перед свойством. Если свойство настроено для отображения и displayLabel не определено, отображается только значение свойства.
В следующем фрагменте показано свойство movieTitle с displayLabel для которого установлено значение «Title».
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
"operatorOptions": {
"operatorName": "title"
}
},
"displayOptions": {
"displayLabel": "Title"
}
},
Ниже приведены значения displayLabel для всех свойств объекта movie в примерной схеме:
| Свойство | displayLabel |
|---|---|
movieTitle | Title |
releaseDate | Release date |
genre | Genre |
duration | Run length |
actorName | Actor |
userRating | Audience score |
mpaaRating | MPAA rating |
(Необязательно) Добавьте раздел suggestionFilteringOperators[]
В конце любого раздела propertyDefinition имеется необязательный раздел suggestionFilteringOperators[] . Используйте этот раздел, чтобы определить свойство, используемое для фильтрации предложений автозаполнения. Например, вы можете определить оператор genre для фильтрации предложений на основе предпочтительного жанра фильма пользователя. Затем, когда пользователь вводит поисковый запрос, в рамках автозаполнения отображаются только те фильмы, которые соответствуют его предпочтительному жанру.
Зарегистрируйте свою схему
Чтобы структурированные данные возвращались из запросов Cloud Search, вам необходимо зарегистрировать свою схему в службе схемы Cloud Search. Для регистрации схемы требуется идентификатор источника данных, полученный на этапе инициализации источника данных .
Используя идентификатор источника данных, выполните запрос UpdateSchema , чтобы зарегистрировать вашу схему.
Как подробно описано на справочной странице UpdateSchema , выполните следующий HTTP-запрос, чтобы зарегистрировать вашу схему:
PUT https://cloudsearch.googleapis.com/v1/indexing/{name=datasources/*}/schema
Тело вашего запроса должно содержать следующее:
{
"validateOnly": // true or false,
"schema": {
// ... Your complete schema object ...
}
}
Используйте опцию validateOnly , чтобы проверить правильность вашей схемы без ее фактической регистрации.
Индексируйте свои данные
После регистрации схемы заполните источник данных с помощью вызовов индекса . Индексирование обычно выполняется внутри вашего коннектора контента .
Используя схему фильма, запрос на индексацию REST API для одного фильма будет выглядеть следующим образом:
{
"name": "datasource/<data_source_id>/items/titanic",
"acl": {
"readers": [
{
"gsuitePrincipal": {
"gsuiteDomain": true
}
}
]
},
"metadata": {
"title": "Titanic",
"sourceRepositoryUrl": "http://www.imdb.com/title/tt2234155/?ref_=nv_sr_1",
"objectType": "movie"
},
"structuredData": {
"object": {
"properties": [
{
"name": "movieTitle",
"textValues": {
"values": [
"Titanic"
]
}
},
{
"name": "releaseDate",
"dateValues": {
"values": [
{
"year": 1997,
"month": 12,
"day": 19
}
]
}
},
{
"name": "actorName",
"textValues": {
"values": [
"Leonardo DiCaprio",
"Kate Winslet",
"Billy Zane"
]
}
},
{
"name": "genre",
"enumValues": {
"values": [
"Drama",
"Action"
]
}
},
{
"name": "userRating",
"integerValues": {
"values": [
8
]
}
},
{
"name": "mpaaRating",
"textValues": {
"values": [
"PG-13"
]
}
},
{
"name": "duration",
"textValues": {
"values": [
"3 h 14 min"
]
}
}
]
}
},
"content": {
"inlineContent": "A seventeen-year-old aristocrat falls in love with a kind but poor artist aboard the luxurious, ill-fated R.M.S. Titanic.",
"contentFormat": "TEXT"
},
"version": "01",
"itemType": "CONTENT_ITEM"
}
Обратите внимание, что значение movie в поле objectType соответствует имени определения объекта в схеме. Сопоставляя эти два значения, Cloud Search знает, какой объект схемы использовать во время индексации.
Также обратите внимание, что индексация свойства releaseDate схемы использует подсвойства year , month и day , которые оно наследует, поскольку оно определено как тип данных date с помощью datePropertyOptions для его определения. Однако, поскольку year , month и day не определены в схеме, вы не можете запросить одно из этих свойств (например, year ) отдельно.
А также обратите внимание на то, как повторяемое свойство actorName индексируется с использованием списка значений.
Выявление потенциальных проблем с индексацией
Две наиболее распространенные проблемы, связанные со схемами и индексированием:
Ваш запрос на индексирование содержит объект схемы или имя свойства, которое не было зарегистрировано в службе схемы. Эта проблема приводит к игнорированию свойства или объекта.
В вашем запросе на индексирование имеется свойство со значением типа, отличным от типа, зарегистрированного в схеме. Эта проблема приводит к тому, что Cloud Search возвращает ошибку во время индексации.
Проверьте свою схему с помощью нескольких типов запросов.
Прежде чем зарегистрировать свою схему для большого репозитория производственных данных, рассмотрите возможность тестирования с меньшим репозиторием тестовых данных. Тестирование с использованием меньшего тестового репозитория позволяет быстро внести изменения в схему и удалить индексированные данные, не затрагивая более крупный индекс или существующий производственный индекс. Для хранилища тестовых данных создайте список управления доступом, который авторизует только тестового пользователя, чтобы другие пользователи не видели эти данные в результатах поиска.
Чтобы создать интерфейс поиска для проверки поисковых запросов, обратитесь к разделу Интерфейс поиска.
В этом разделе содержится несколько различных примеров запросов, которые вы можете использовать для проверки схемы фильма.
Тестирование с помощью общего запроса
Общий запрос возвращает все элементы источника данных, содержащие определенную строку. Используя интерфейс поиска, вы можете запустить общий запрос к источнику данных о фильме, введя слово «Титаник» и нажав Return . Все фильмы со словом «Титаник» должны возвращаться в результатах поиска.
Тестируйте с оператором
Добавление оператора в запрос ограничивает результаты элементами, которые соответствуют значению этого оператора. Например, вы можете использовать оператор actor , чтобы найти все фильмы с определенным актером в главной роли. Используя интерфейс поиска, вы можете выполнить этот операторный запрос, просто введя пару оператор=значение , например «актёр:Зейн» , и нажав Return . В результатах поиска должны быть возвращены все фильмы с Зейном в роли актера.
Настройте свою схему
После того, как ваша схема и ваши данные будут использованы, продолжайте отслеживать, что работает, а что не работает для ваших пользователей. Вам следует рассмотреть возможность корректировки схемы для следующих ситуаций:
- Индексирование поля, которое ранее не было проиндексировано. Например, ваши пользователи могут неоднократно искать фильмы по имени режиссера, поэтому вы можете настроить свою схему так, чтобы она поддерживала имя режиссера в качестве оператора.
- Изменение названий операторов поиска на основе отзывов пользователей. Имена операторов должны быть удобными для пользователя. Если ваши пользователи постоянно «помнит» неправильное имя оператора, вы можете рассмотреть возможность его изменения.
Переиндексация после изменения схемы
Изменение любого из следующих значений в вашей схеме не требует повторной индексации данных. Вы можете просто отправить новый запрос UpdateSchema , и ваш индекс продолжит работать:
- Имена операторов.
- Целочисленные минимальные и максимальные значения.
- Целочисленный и перечисляемый упорядоченный рейтинг.
- Варианты свежести.
- Параметры отображения.
При следующих изменениях ранее проиндексированные данные продолжат работать по ранее зарегистрированной схеме. Однако вам необходимо переиндексировать существующие записи, чтобы увидеть изменения на основе обновленной схемы, если в ней есть эти изменения:
- Добавление или удаление нового свойства или объекта
- Изменение
isReturnable,isFacetableилиisSortableсfalseнаtrue.
Вам следует установить для isFacetable или isSortable значение true только если у вас есть четкий вариант использования и необходимость.
Наконец, когда вы обновляете свою схему, отмечая свойство isSuggestable , вам необходимо переиндексировать свои данные, что приводит к задержке использования автозаполнения для этого свойства.
Запрещенные изменения свойств
Некоторые изменения схемы не допускаются, даже если вы переиндексируете свои данные, поскольку они нарушат индекс или дадут плохие или противоречивые результаты поиска. К ним относятся изменения:
- Тип данных свойства.
- Имя свойства.
-
exactMatchWithOperatorнастройкаMatchWithOperator. - Параметр
retrievalImportance.
Однако есть способ обойти это ограничение.
Внести сложное изменение схемы
Чтобы избежать изменений, которые могут привести к плохим результатам поиска или повреждению индекса поиска, Cloud Search предотвращает определенные виды изменений в запросах UpdateSchema после индексации репозитория. Например, тип данных или имя свойства нельзя изменить после того, как они были установлены. Этих изменений невозможно добиться с помощью простого запроса UpdateSchema , даже если вы повторно проиндексируете свои данные.
В ситуациях, когда вам необходимо внести в схему изменения, которые в противном случае были бы запрещены , вы часто можете внести ряд разрешенных изменений, которые достигают того же эффекта. Как правило, это предполагает сначала миграцию индексированных свойств из более старого определения объекта в более новое, а затем отправку запроса на индексирование, который использует только новое свойство.
Следующие шаги показывают, как изменить тип данных или имя свойства:
- Добавьте новое свойство в определение объекта в вашей схеме. Используйте имя, отличное от имени свойства, которое вы хотите изменить.
- Выполните запрос UpdateSchema с новым определением. Не забудьте отправить в запросе всю схему, включая новое и старое свойство.
Заполните индекс из хранилища данных. Чтобы заполнить индекс, отправляйте все запросы индексирования с использованием нового свойства, а не старого свойства, поскольку это приведет к двойному подсчету совпадений запроса.
- Во время заполнения индексации проверьте наличие нового свойства и по умолчанию используйте старое свойство, чтобы избежать несогласованного поведения.
- После завершения заполнения запустите тестовые запросы для проверки.
Удалить старое свойство. Выполните еще один запрос UpdateSchema без старого имени свойства и прекратите использование старого имени свойства в будущих запросах на индексирование.
Перенесите любое использование старого свойства в новое. Например, если вы измените имя свойства с «создатель» на «автор», вам необходимо обновить код запроса, чтобы использовать имя «автор» там, где оно ранее ссылалось на «создателя».
Cloud Search сохраняет записи обо всех удаленных свойствах или объектах в течение 30 дней, чтобы защитить их от любого повторного использования, которое может привести к неожиданным результатам индексации. В течение этих 30 дней вам следует отказаться от любого использования удаленного объекта или свойства, в том числе исключить их из будущих запросов на индексирование. Это гарантирует, что если вы позже решите восстановить это свойство или объект, вы сможете сделать это таким образом, чтобы сохранить правильность вашего индекса.
Знайте ограничения по размеру
Cloud Search накладывает ограничения на размер объектов и схем структурированных данных. Эти ограничения таковы:
- Максимальное количество объектов верхнего уровня — 10 объектов.
- Максимальная глубина иерархии структурированных данных составляет 10 уровней.
- Общее количество полей в объекте ограничено 1000, включая количество примитивных полей плюс сумму количества полей в каждом вложенном объекте.
Следующие шаги
Вот несколько следующих шагов, которые вы можете предпринять:
Создайте интерфейс поиска для проверки вашей схемы.
Настройте свою схему, чтобы улучшить качество поиска .
Структурируйте схему для оптимальной интерпретации запроса .
Узнайте, как использовать схему
_dictionaryEntryдля определения синонимов терминов, часто используемых в вашей компании. Чтобы использовать схему_dictionaryEntry, обратитесь к разделу Определение синонимов .Создайте соединитель .