In the realm of high-performance computing (HPC), NVIDIA has continually advanced HPC by offering its highly optimized NVIDIA High-Performance Conjugate Gradient (HPCG) benchmark program as part of the NVIDIA HPC benchmark program collection.
We now provide the NVIDIA HPCG benchmark program in the /NVIDIA/nvidia-hpcg GitHub repo, using its high-performance math libraries, cuSPARSE, and the NVIDIA Performance Libraries (NVPL) to achieve optimal performance for sparse matrix-vector multiplication (SpMV) and sparse matrix triangular solvers (SpSV) on NVIDIA GPUs and NVIDIA CPUs.
Understanding the HPCG benchmark
The HPCG benchmark complements the High-Performance LINPACK (HPL) benchmark, traditionally used to rank supercomputers in the TOP500 list. While HPL measures peak floating-point performance, it does not fully represent the performance of real-world applications that rely on memory access patterns and data locality.
This is where HPCG comes in, offering a more comprehensive assessment by simulating a variety of computation and data access patterns common in scientific computing. The HPCG benchmark is used to rank supercomputers in the TOP500 list on par with the HPL benchmark.
HPCG evaluates the preconditioned conjugate gradient (PCG) method, crucial for solving large, sparse linear systems in fields like computational fluid dynamics, structural analysis, and material science. It assesses HPC systems’ memory bandwidth and latency handling real-world applications by constructing a globally distributed sparse linear system using a 27-point stencil per grid point in a 3D domain.
Managed by MPI processes, this setup enables scalable computations across processors. Key operations include the following:
- Vector inner product
- Updates
- SpSV for symmetric Gauss-Seidel (SYMGS) smoothing
- SpMV
For more information about the benchmark, see the HPCG Benchmark Technical Specification.
The efficiency of HPCG heavily relies on the performance of SpMV and SpSV operations. These computations form the backbone of the iterative PCG method, directly influencing the benchmark’s ability to simulate real-world workloads accurately. High-performance implementations of SpMV and SpSV can significantly enhance the overall performance of HPC systems, providing valuable insights into their capabilities in handling complex scientific computations.
Enhancing performance on HPCG
The performance of the NVIDIA HPCG benchmark program is significantly enhanced through its specialized math libraries: cuSPARSE for GPUs and NVPL Sparse for aarch64 architectures such as the NVIDIA Grace CPU. These libraries are integral to accelerating sparse linear algebra operations essential for iterative algorithms like the PCG method.
cuSPARSE, optimized for NVIDIA GPU architectures, supports a wide range of functionalities including SpMV, sparse matrix-matrix multiplication (SpMM), and SpSV. These operations are critical for many scientific computations due to their ability to handle large-scale sparse matrices efficiently.
NVPL Sparse, on the other hand, targets Arm 64-bit architectures such as the NVIDIA Grace CPU. It is part of NVPL, designed to maximize performance and efficiency on these platforms. This library includes functionalities tailored to sparse linear algebra, enabling applications to fully exploit the capabilities of Arm-based architectures.
The recent beta release of NVPL Sparse boosts performance on Grace CPUs and provides a competitive edge in heterogeneous computing environments.
The cuSPARSE and NVPL Sparse generic APIs offer flexibility in configuring data layouts, supporting mixed data types, and selecting algorithms tailored to specific computational tasks, ensuring compatibility across different applications and optimization opportunities:
- Configurable storage formats such as CSR and ELLPACK
- Flexible data types for input, output, and compute
- Various indexing options such as 32-bit and 64-bit
Memory management features and extensive consistency checks further enhance reliability and performance consistency across diverse computing scenarios.
By integrating cuSPARSE and NVPL Sparse into the NVIDIA HPCG benchmark program, it enhances critical operations such as SpMV and SpSV. These libraries empower you to achieve peak performance on NVIDIA GPU and Grace CPU architectures, advancing supercomputing capabilities to effectively manage intricate scientific simulations and computations.
Optimizations and innovations
The symmetric Gauss-Seidel smoother involves forward and backward SpSV of the sparse matrix, where the triangular solves are inherently sequential due to row dependencies. To address this, the NVIDIA HPCG benchmark program employs graph coloring to reorder the sparse matrix rows, enabling parallel processing of independent rows grouped by color. For more information, see A CUDA Implementation of the High Performance Conjugate Gradient Benchmark.
NVIDIA has also introduced the sliced-ELLPACK storage format for sparse matrices within the NVIDIA HPCG benchmark program. This format minimizes computational overhead by reducing zero-padding in lower and upper triangular matrices compared to traditional CSR formats. The adoption of sliced-ELLPACK has demonstrated notable performance improvements, including 1.2x faster SpMV and 1.7x faster SpSV on the NVIDIA DGX H100 platform.
The NVIDIA HPCG benchmark program implements specific strategies to minimize unnecessary memory accesses and computational redundancies. For instance, by restricting matrix operations to relevant portions during iterative steps and leveraging specialized APIs like cusparseSpSV_UpdateMatrix and nvpl_sparse_update_matrix, the NVIDIA HPCG benchmark program achieves efficient sparse matrix updates and computations.
Beyond using the NVIDIA math API, the NVIDIA HPCG benchmark program incorporates several optimizations to enhance the efficiency of the PCG execution phase: overlap of computation and communication and support for different point-to-point (P2P) communication modes.
Overlap of computation and communication
During critical operations such as SpMV and SYMGS computations, the NVIDIA HPCG benchmark program overlaps computation with communication tasks. This strategy involves transferring boundary data from the GPU to the CPU, performing MPI send/receive operations with neighboring processes, and transferring the results back to the GPU.
The NVIDIA HPCG benchmark program achieves this overlap with CUDA streams, which enable concurrent execution of communication copies in separate streams from computation kernels, thereby reducing idle time and improving overall throughput.
Support for different P2P communication modes
The NVIDIA HPCG benchmark program supports various P2P communication modes to evaluate performance across diverse cluster configurations:
- Host-MPI
- CUDA-AWARE-MPI
- Host-All2allv
- CUDA-AWARE-All2allv
- NVIDIA Collective Communication Library (NCCL)
Each mode is optimized for specific network architectures and communication patterns, enabling HPCG to assess and optimize performance in different cluster environments effectively. This flexibility ensures that the NVIDIA HPCG benchmark program can adapt to varying communication infrastructures and maximize efficiency in large-scale parallel computations.
Heterogeneous computing capabilities
The NVIDIA HPCG benchmark program extends its optimization strategies to heterogeneous computing environments, seamlessly integrating GPUs and NVIDIA Grace CPUs. This approach involves assigning an MPI rank to each GPU and one or more MPI ranks to the Grace CPU.
To fully maximize the utilization of every aspect of the system, the strategy is to allocate a larger local problem size to the GPU compared to the Grace CPU. This ensures that the computational strengths of both the GPU and the CPU are fully leveraged. During MPI blocking communication steps like MPI_Allreduce, this approach helps maintain balanced workloads across the system components, optimizing overall performance and minimizing idle time for any part of the system.
In the NVIDIA HPCG benchmark program, the GPU and Grace CPU local problems are configured to differ in only one dimension while keeping the other dimensions identical. This design enables proper halo exchange operations across the dimensions that remain identical between the GPU and Grace ranks.
Figure 1 shows an example of this design. The GPU and Grace CPU ranks have the same y and z dimensions. The x dimension is different, which enables assigning different local problems for the GPU and Grace ranks. The NVIDIA HPCG benchmark program offers you the flexibility to choose the 3D shape of ranks, select the different dimensions, and configure the sizes of the GPU and Grace ranks.
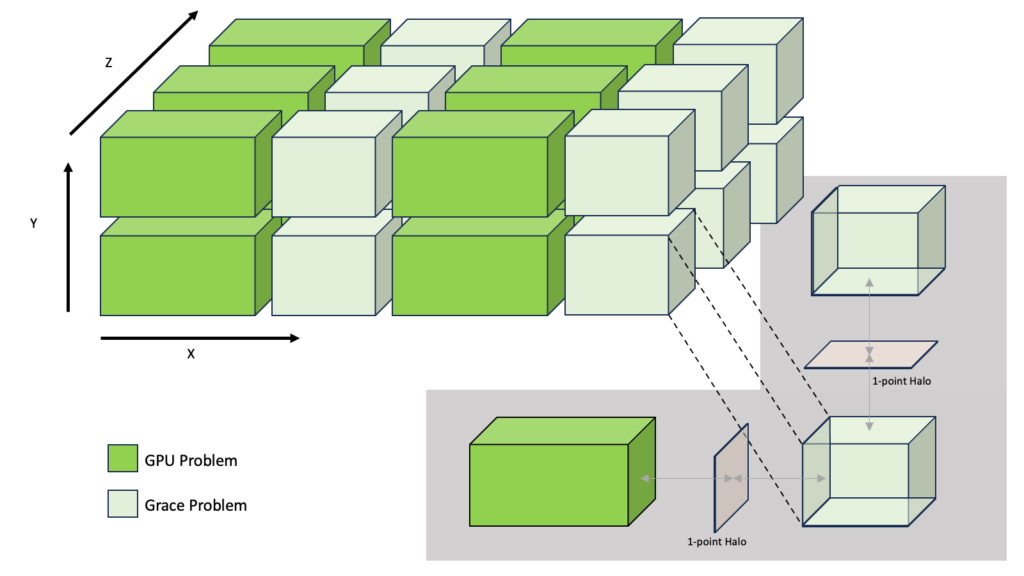
The performance of the heterogeneous execution mode depends on the shape of the 3D grid, the ratio between the GPU and Grace CPU problem sizes, and the hardware capabilities of the GPU and CPU.
On the Grace Hopper Superchip (GH200), the GPU problem size should be 16x larger than the Grace CPU problem size to achieve a 5% performance improvement over the GPU-only execution mode. The command-line parameters offer great flexibility in selecting the different dimensions and configuring the 3D grid dimensions accordingly.
HPCG performance
The HPCG runtime guidelines state, “The problem size should reflect what would be reasonable for a real sparse iterative solver.” Typically, this means the HPCG problem size should be at least 25% of the available system memory.
These guidelines create an interesting challenge for benchmarking HPCG on the NVIDIA Grace Hopper Superchip (GH200) as real-world applications relying on sparse iterative solvers may perform their calculations entirely in CPU memory, entirely in GPU memory, or a combination of both.
To most accurately represent sparse iterative solver performance on GH200, we’ve chosen to present the performance of the following problem sizes:
- 25% of CPU memory
- 25% of GPU memory
- 25% of the combined CPU and GPU memory
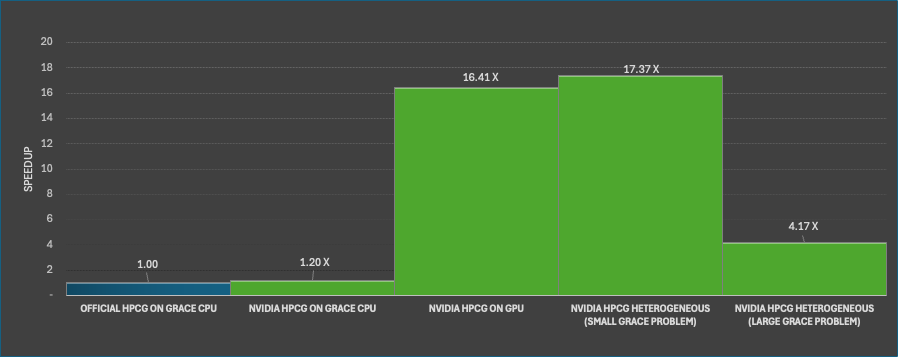
Figure 2 shows the performance comparison between the NVIDIA HPCG benchmark program and the official HPCG benchmark on the NVIDIA GH200-480GB. To optimize parallelism for the official HPCG benchmark, we used 72 MPI ranks to manage smaller local tasks.
The NVIDIA HPCG CPU-only configuration demonstrated a 20% performance improvement over the official HPCG benchmark due to CPU software optimization.
Figure 2 also shows the performance of the NVIDIA HPCG GPU-only configuration, alongside the heterogeneous GPU and Grace CPU implementation, which has a 5% performance boost compared to the GPU-only setup when the Grace CPU handles a smaller problem that can overlap with the GPU workload. The Grace CPU MPI rank handles an additional 1/16 of the GPU problem size, producing the highest speedup of 17.4x compared to the official HPCG benchmark executing on the CPU.
Finally, when the HPCG problem is 25% of the total system memory (CPU+GPU), the total speedup is 4.2x. In this case, there is an advantageous trade-off between runtime performance and total problem size. The problem size is similar to the large CPU-only case; however, runtime performance has increased by over 4x.
The experiments were performed on an NVIDIA GH200 GPU with a 480-GB memory capacity (GH200-480GB).
Summary
The open-source NVIDIA HPCG benchmark program uses high-performance math libraries, cuSPARSE, and NVPL Sparse, for optimal performance on GPUs and Grace CPUs. It supports GPU-only, Grace-only, and heterogeneous execution, offering flexibility to configure execution modes.
The NVIDIA HPCG benchmark program uses a unique design where the GPU and Grace CPU problem sizes differ in one dimension while keeping others identical, facilitating efficient halo exchange operations.
For more information, see the following resources:
- /NVIDIA/nvidia-hpcg GitHub repo
- NVIDIA cuSPARSE developer page
- NVIDIA Performance Libraries (NVPL) developer page
- Accelerated Computing developer forum