Generative AI has the potential to transform every industry. Human workers are already using large language models (LLMs) to explain, reason about, and solve difficult cognitive tasks. Retrieval-augmented generation (RAG) connects LLMs to data, expanding the usefulness of LLMs by giving them access to up-to-date and accurate information.
Many enterprises have already started to explore how RAG can help them automate business processes and mine data for insight. Although most enterprises have initiated multiple pilots aligned to generative AI use cases, it’s estimated that 90% of them won’t move beyond the evaluation phase in the near future. Transforming a compelling RAG demo into a production service that delivers real business value remains challenging.
In this blog, we describe how NVIDIA AI helps you move RAG applications from pilot to production in four steps.
Building an enterprise-ready RAG pipeline
Many obstacles are associated with developing and deploying a production-ready enterprise RAG pipeline.
IT administrators face challenges related to LLM security, usability, portability, and data governance. Enterprise developers may struggle with LLM accuracy and the overall maturity of LLM programming frameworks. And the sheer velocity of open-source innovation is overwhelming for everyone, with new LLM models and RAG techniques appearing every day.
Building blocks to simplify production RAG development and deployment
NVIDIA helps to manage this complexity by providing a reference architecture for cloud-native, end-to-end RAG applications. The reference architecture is modular, combining popular open-source software with NVIDIA acceleration. Leveraging a comprehensive suite of modular building blocks offers several benefits.
- First, enterprises can selectively integrate new components into their existing infrastructure.
- Second, they can choose between commercial and open-source components for each stage of the pipeline. Enterprises are free to select the right components for their own use cases while simultaneously avoiding vendor lock-in.
- Finally, the modular architecture simplifies evaluation, observation, and troubleshooting at each stage of the pipeline.
Figure 1 shows the essential building blocks for deploying a RAG pipeline.
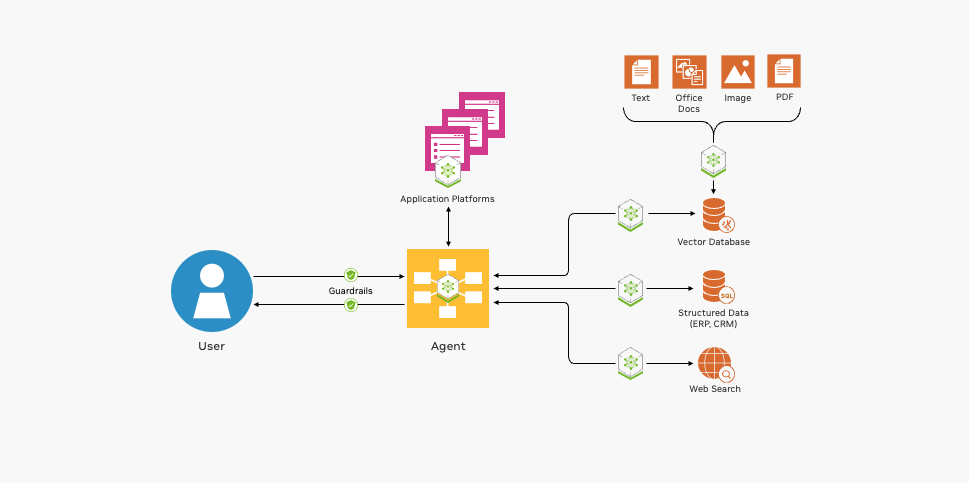
NVIDIA offers open-source integration, GPU-accelerated containers, and more to help develop your RAG applications.
Open-source integration with popular frameworks and tools
NVIDIA provides example pipelines to help kickstart RAG application development. NVIDIA RAG pipeline examples show developers how to combine with popular open-source LLM programming frameworks—including LangChain, LlamaIndex, and Haystack—with NVIDIA accelerated software. By using these examples as a starting point, enterprise developers can enjoy the best of both worlds—combining open-source innovation with accelerated performance and scale.
The examples also demonstrate integration with popular open-source tools for evaluation, pipeline observability, and data ingestion, making day-two pipeline operations easier and more cost effective.
GPU-accelerated containers for fast, accurate responses
LLM-powered enterprise RAG applications must be responsive and accurate. CPU-based systems cannot deliver acceptable performance at enterprise scale. The NVIDIA API catalog includes containers to power every stage of a RAG pipeline that benefits from GPU acceleration.
- NVIDIA NIM delivers best-in-industry performance and scale for LLM inference.
- NVIDIA NeMo Retriever simplifies and accelerates the document embedding, retrieval, and querying functions at the heart of a RAG pipeline.
- NVIDIA RAPIDS accelerates searching and indexing of the databases that store the vector representations of enterprise data.
Support for multimodal input, output, and data processing
RAG applications are quickly evolving from text-based chatbots to complex, event-driven workflows involving a variety of modalities such as images, audio, and video. NVIDIA AI software enhances the usability and functionality of RAG pipelines to address these emerging use cases.
- NVIDIA Riva delivers GPU-accelerated text-to-speech, speech-to-text, and translation interfaces for interacting with RAG pipelines using spoken language.
- NVIDIA RAPIDS can GPU-accelerate actions triggered by LLM agents. For example, LLM agents can call RAPIDS cuDF to perform statistical math on structured data.
- NVIDIA Morpheus can be used to preprocess massive volumes of enterprise data and ingest it in real time.
- NVIDIA Metropolis and NVIDIA Holoscan add video and sensor processing capabilities to the RAG pipeline.
Enterprise developers can leverage NVIDIA AI Enterprise to deploy these AI software components for production. NVIDIA AI Enterprise provides the fastest and most efficient runtime for enterprise-grade generative AI applications.
Four steps to take your RAG app from pilot to production
Building production RAG applications requires collaboration between many stakeholders.
- Data scientists evaluate LLMs for performance and accuracy.
- Enterprise AI developers write, test, and improve RAG applications.
- Data engineers connect and transform enterprise data for indexing and retrieval.
- MLOps, DevOps, and site reliability engineers (SREs) deploy and maintain the production systems.
NVIDIA AI extends from the cloud to silicon to support every stage of RAG application development, deployment, and operation. Figure 2 shows the four steps to move a RAG application from evaluation to production.
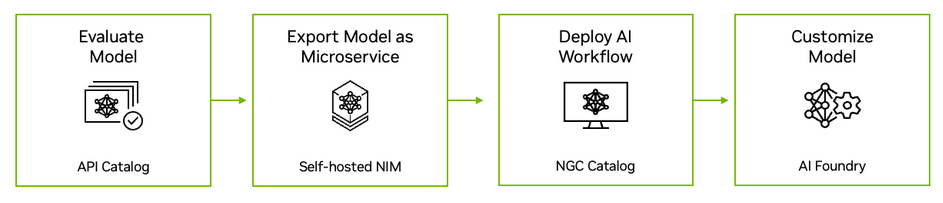
Step 1. Evaluate LLMs in the NVIDIA API catalog
Start by visiting the NVIDIA API catalog to experience leading open-source and commercial models running on NVIDIA GPUs. Developers can interact with the models through a user interface and then view the backend API calls generated by the interaction. The API calls can be exported as Python, Go, or TypeScript code snippets, or as shell scripts.
Step 2. Export a model as a microservice
Next, export a model as an NVIDIA NIM. A NIM is an easy-to-use, self-hosted microservice designed to accelerate the deployment of generative AI. The microservice can run as a container in a virtual machine on any major cloud, or it can be installed into a Kubernetes cluster through Helm. If you have concerns about data privacy or security, you can evaluate the model in your own data center or virtual private cloud.
Step 3. Develop a sample RAG application
After evaluating the self-hosted model, explore NVIDIA Generative AI Examples to write sample RAG applications. The examples illustrate how NVIDIA microservices integrate with popular open-source LLM programming frameworks to produce end-to-end RAG pipelines. Data scientists can use these examples to tune applications for performance and evaluate their accuracy. NVIDIA AI Enterprise customers also have access to NVIDIA AI workflows that demonstrate how the generative AI examples can be applied to industry-specific use cases.
Step 4. Deploy the RAG pipeline to production
After the application has been developed, MLOps administrators can deploy it to a test or production namespace.
Production RAG pipelines that enhance productivity
Production RAG systems can boost worker productivity by reducing toil, making pertinent data easier to find, and automating events.
NVIDIA uses a RAG pipeline to help build secure enterprise software. The NVIDIA CVE analysis example workflow combines NVIDIA NIM, NeMo Retriever, and the Morpheus cybersecurity AI framework to identify and triage common vulnerabilities and exposures (CVEs) in NGC containers. This critical business process—that ensures the integrity of all containers posted to the NGC container registry—now takes hours instead of days.
Organizations including Deepset, Sandia National Laboratories, Infosys, Quantiphi, Slalom, and Wipro are unlocking valuable insights with NVIDIA generative AI—enabling semantic search of enterprise data.
Deepset’s new Haystack 2.0 integration with NVIDIA NIM and NeMo Retriever help organizations efficiently examine GPU-accelerated LLMs to support rapid-prototyping of RAG applications.
Sandia National Laboratories and NVIDIA are collaborating to evaluate emerging generative AI tools to maximize data insights while improving accuracy and performance.
Infosys has expanded their strategic collaboration with NVIDIA pairing Infosys Generative AI, part of Infosys Topaz, with NVIDIA NeMo to create enterprise-ready RAG applications for various industries. These applications disrupt norms and deliver value for use cases from automating biopharma clinical trial reports to finding insights from over 100,000 proprietary financial documents.
Quantiphi incorporates NVIDIA accelerated generative AI to develop RAG-based solutions that can extract insights from vast drug discovery documents repositories, and assist in delivering breakthrough results by optimizing retail supply chains tailored to demographics and geolocation.
Slalom is assisting organizations in navigating the complexities of generative AI and RAG, including design, implementation, and governance with a robust framework for mitigating risks and ensuring responsible application of AI.
Working with generative AI tools, Wipro is helping healthcare organizations advance outcomes through the improved delivery of service to millions of patients across the United States.
Get started
Enterprises are increasingly turning to generative AI to solve complex business challenges and enhance employee productivity. Many will also incorporate generative AI into their products. Enterprises can rely on the security, support, and stability provided by NVIDIA AI Enterprise to move their RAG applications from pilot to production. And, by standardizing on NVIDIA AI, enterprises gain a committed partner to help them keep pace with the rapidly evolving LLM ecosystem.
Experience NVIDIA NeMo Retriever microservices, including the retrieval embedding model, in the API catalog. Or, explore NVIDIA Generative AI Examples to get started building a chatbot that can accurately answer domain-specific questions in natural language using up-to-date information.
To hear about the latest innovations and best practices for building RAG applications, check out the retrieval-augmented generation sessions from NVIDIA GTC 2024.