

Chrome UX 보고서 (CrUX)의 원시 데이터는 Google Cloud의 데이터베이스인 BigQuery에서 확인할 수 있습니다. BigQuery를 사용하려면 GCP 프로젝트와 SQL에 대한 기본 지식이 필요합니다.
이 가이드에서는 BigQuery를 사용하여 CrUX 데이터 세트에 대한 쿼리를 작성하여 웹에서의 사용자 환경 상태에 관한 유용한 정보를 추출하는 방법을 알아봅니다.
- 데이터가 구성되는 방식 이해
- 출처의 실적을 평가하는 기본 쿼리 작성
- 시간 경과에 따른 성능을 추적하는 고급 쿼리 작성
데이터 조직
먼저 기본 쿼리를 살펴보세요.
SELECT COUNT(DISTINCT origin) FROM `chrome-ux-report.all.202206`
쿼리를 실행하려면 쿼리 편집기에 쿼리를 입력하고 '쿼리 실행' 버튼을 누릅니다.
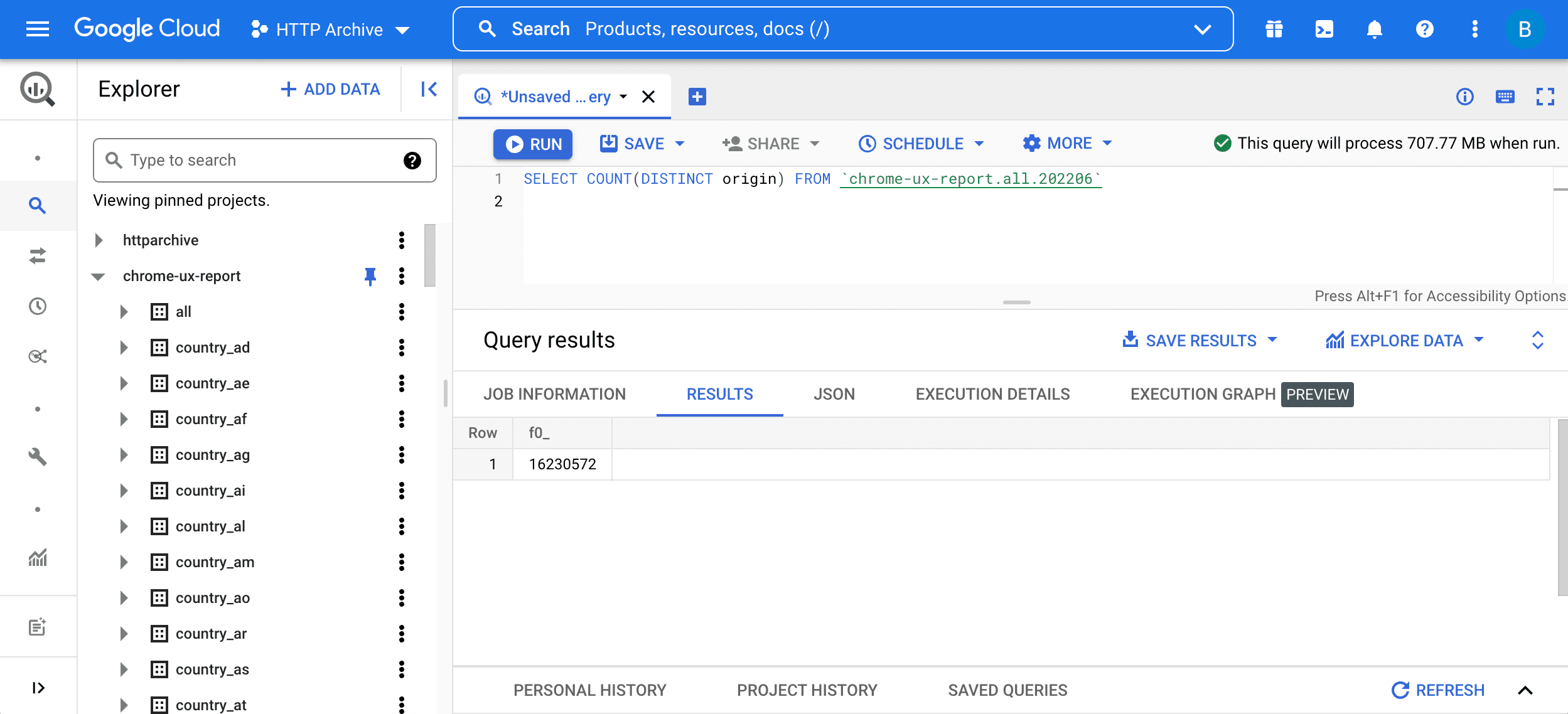
이 쿼리는 두 부분으로 구성됩니다.
SELECT COUNT(DISTINCT origin)는 테이블의 출처 수를 쿼리하는 것을 의미합니다. 대략적으로 두 URL의 스키마, 호스트, 포트가 동일하면 두 URL이 동일한 출처에 속한다고 할 수 있습니다.FROM chrome-ux-report.all.202206는 소스 테이블의 주소를 지정하며, 이 주소는 세 부분으로 구성됩니다.- 모든 CrUX 데이터가 구성되는 Cloud 프로젝트 이름
chrome-ux-report입니다. - 모든 국가의 데이터를 나타내는 데이터 세트
all - 테이블
202206: YYYYMM 형식의 데이터 연도 및 월
- 모든 CrUX 데이터가 구성되는 Cloud 프로젝트 이름
모든 국가의 데이터 세트도 있습니다. 예를 들어 chrome-ux-report.country_ca.202206는 캐나다에서 발생한 사용자 환경 데이터만 나타냅니다.
각 데이터 세트에는 201710 이후 매월의 테이블이 있습니다. 지난달의 새 표는 정기적으로 게시됩니다.
데이터 테이블의 구조 (스키마라고도 함)에는 다음이 포함됩니다.
- 출처(예:
origin = 'https://www.example.com')로, 해당 웹사이트의 모든 페이지에 대한 집계된 사용자 환경 분포를 나타냅니다. - 페이지 로드 시의 연결 속도입니다(예:
effective_connection_type.name = '4G'). - 기기 유형(예:
form_factor.name = 'desktop') - UX 측정항목 자체
각 측정항목의 데이터는 객체의 배열로 구성됩니다. JSON 표기법에서 first_contentful_paint.histogram.bin는 다음과 같이 표시됩니다.
[
{"start": 0, "end": 100, "density": 0.1234},
{"start": 100, "end": 200, "density": 0.0123},
...
]
각 비트에는 시작 시간과 종료 시간이 밀리초 단위로 포함되며, 이 기간 내 사용자 환경의 비율을 나타내는 밀도가 포함됩니다. 다시 말해, 이 가상의 출처, 연결 속도, 기기 유형에 대한 FCP 경험의 12.34% 가 100ms 미만입니다. 모든 비율 밀도의 합계는 100%입니다.
실적 평가하기
테이블 스키마에 대한 지식을 사용하여 이 성능 데이터를 추출하는 쿼리를 작성할 수 있습니다.
SELECT
fcp
FROM
`chrome-ux-report.all.202206`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
effective_connection_type.name = '4G' AND
form_factor.name = 'phone' AND
fcp.start = 0
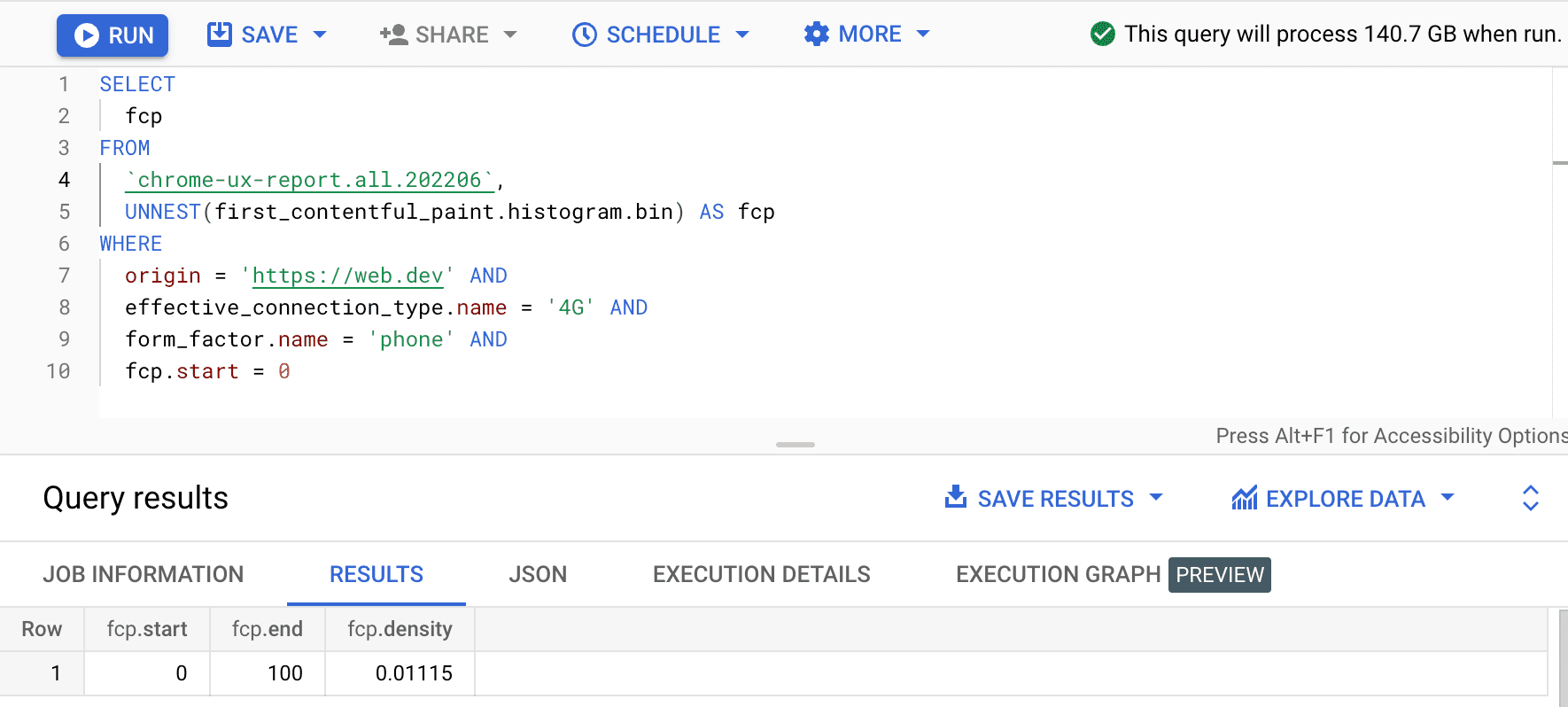
결과는 0.01115입니다. 즉, 이 출처의 사용자 경험 중 1.115% 가 4G 및 휴대전화에서 0~100ms 사이입니다. 쿼리를 모든 연결 및 기기 유형으로 일반화하려면 WHERE 절에서 이를 생략하고 SUM 집계 함수를 사용하여 각 비율 밀도를 모두 더하면 됩니다.
SELECT
SUM(fcp.density)
FROM
`chrome-ux-report.all.202206`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start = 0

결과는 0.05355 또는 모든 기기 및 연결 유형에서 5.355% 입니다. 쿼리를 약간 수정하고 0~1,000ms의 '빠른' FCP 범위에 있는 모든 빈의 밀도를 더할 수 있습니다.
SELECT
SUM(fcp.density) AS fast_fcp
FROM
`chrome-ux-report.all.202206`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start < 1000
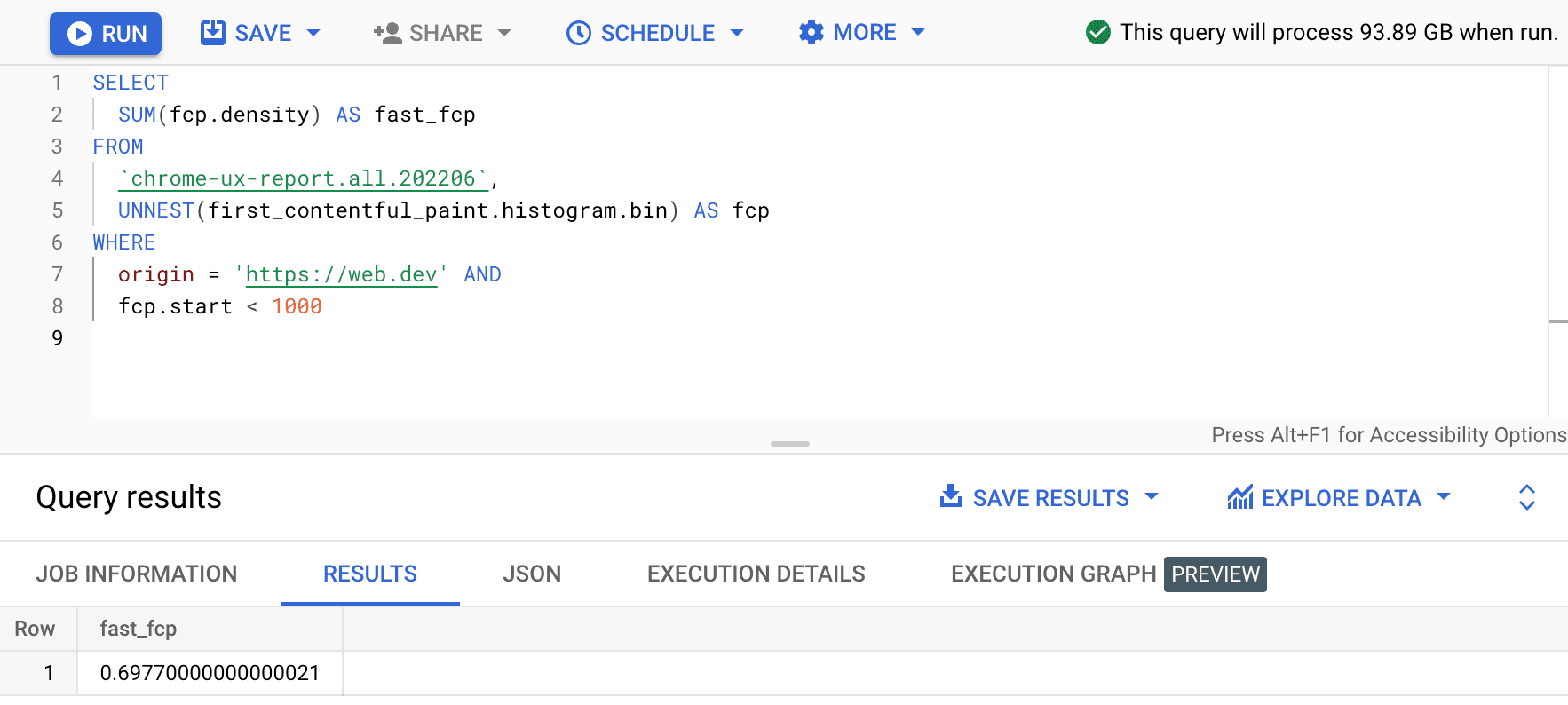
그러면 0.6977가 됩니다. 즉, web.dev의 FCP 사용자 환경 중 69.77% 가 FCP 범위 정의에 따라 '빠름'으로 간주됩니다.
실적 추적
이제 출처에 대한 실적 데이터를 추출했으므로 이전 테이블에 있는 이전 데이터와 비교할 수 있습니다. 이렇게 하려면 테이블 주소를 이전 월로 다시 작성하거나 와일드 카드 문법을 사용하여 모든 월을 쿼리할 수 있습니다.
SELECT
_TABLE_SUFFIX AS yyyymm,
SUM(fcp.density) AS fast_fcp
FROM
`chrome-ux-report.all.*`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start < 1000
GROUP BY
yyyymm
ORDER BY
yyyymm DESC
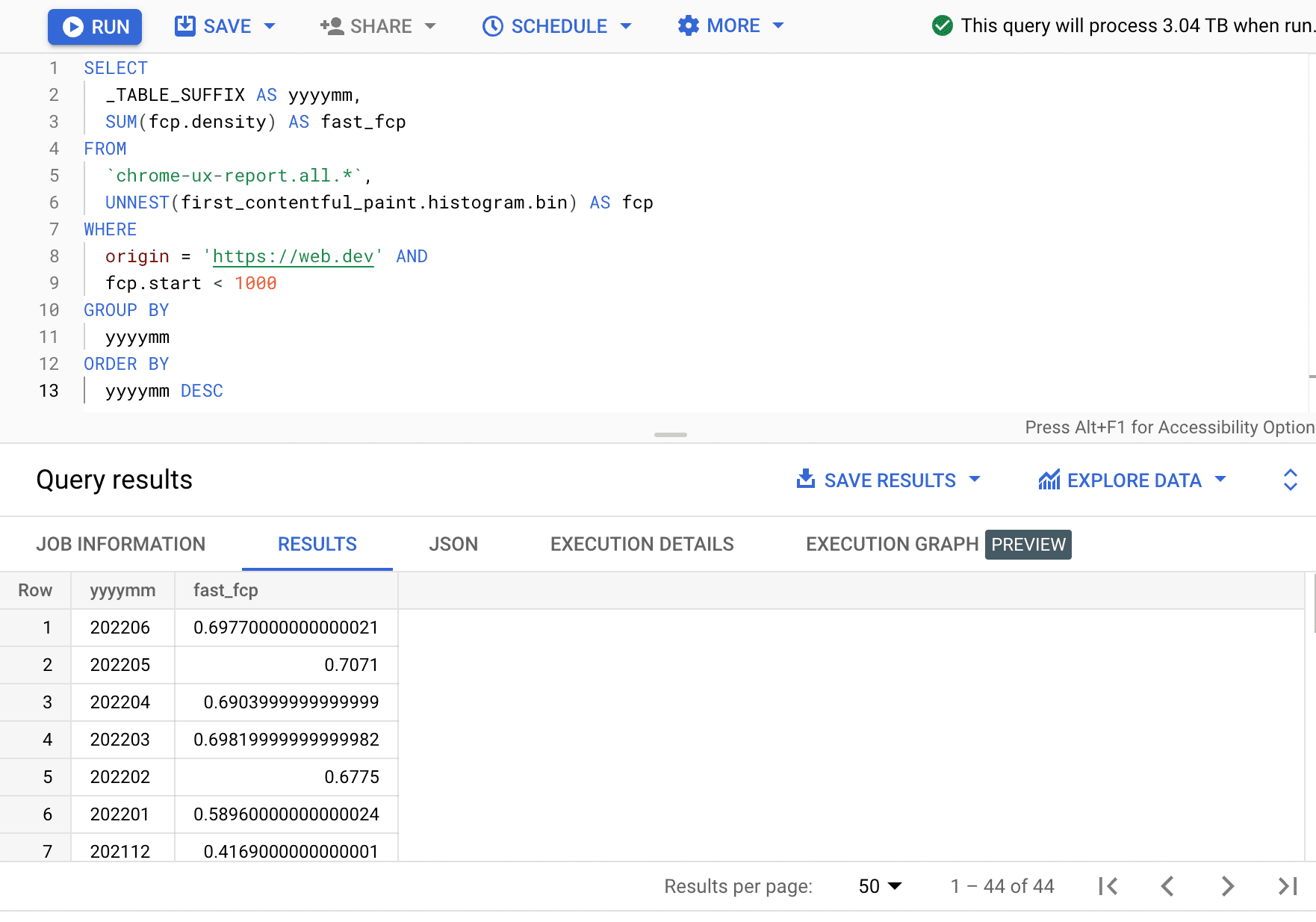
여기에서 빠른 FCP 환경의 비율은 매달 몇 퍼센트씩 달라지는 것을 확인할 수 있습니다.
| yyyymm | fast_fcp |
|---|---|
| 202206 | 69.77% |
| 202205 | 70.71% |
| 202204 | 69.04% |
| 202203 | 69.82% |
| 202202 | 67.75% |
| 202201 | 58.96% |
| 202112 | 41.69% |
| ... | ... |
이러한 기법을 사용하면 출처의 실적을 조회하고, 빠른 환경의 비율을 계산하고, 시간 경과에 따른 추적을 할 수 있습니다. 다음 단계로 두 개 이상의 출처를 쿼리하고 실적을 비교해 보세요.
FAQ
다음은 CrUX BigQuery 데이터 세트와 관련하여 자주 묻는 질문입니다.
언제 다른 도구와 달리 BigQuery를 사용하게 되나요?
BigQuery는 CrUX 대시보드 및 PageSpeed Insights와 같은 다른 도구에서 동일한 정보를 가져올 수 없는 경우에만 필요합니다. 예를 들어 BigQuery를 사용하면 의미 있는 방식으로 데이터를 슬라이스하고 HTTP Archive와 같은 다른 공개 데이터 세트와 조인하여 고급 데이터 마이닝을 수행할 수도 있습니다.
BigQuery를 사용하는 데 제한사항이 있나요?
예, 가장 중요한 제한사항은 기본적으로 사용자가 매달 1TB 분량의 데이터만 쿼리할 수 있다는 것입니다. 그 이상 사용하면 TB당 5달러의 표준 요금이 적용됩니다.
BigQuery에 대해 자세히 알아보려면 어디로 가야 하나요?
자세한 내용은 BigQuery 문서를 참고하세요.