

Nieprzetworzone dane z raportu na temat użytkowania Chrome (CrUX) są dostępne w BigQuery – bazie danych w Google Cloud. Korzystanie z BigQuery wymaga projektu GCP i podstawowej znajomości języka SQL.
Z tego przewodnika dowiesz się, jak za pomocą BigQuery pisać zapytania dotyczące zbioru danych Crux, aby uzyskiwać przydatne wyniki dotyczące wrażeń użytkowników w internecie:
- Organizowanie danych
- Tworzenie podstawowego zapytania do oceny skuteczności pochodzenia
- Tworzenie zaawansowanego zapytania do śledzenia wydajności w czasie
Organizacja danych
Zacznij od prostego zapytania:
SELECT COUNT(DISTINCT origin) FROM `chrome-ux-report.all.202206`
Aby uruchomić zapytanie, wpisz je w edytorze zapytań i kliknij przycisk „Uruchom zapytanie”:
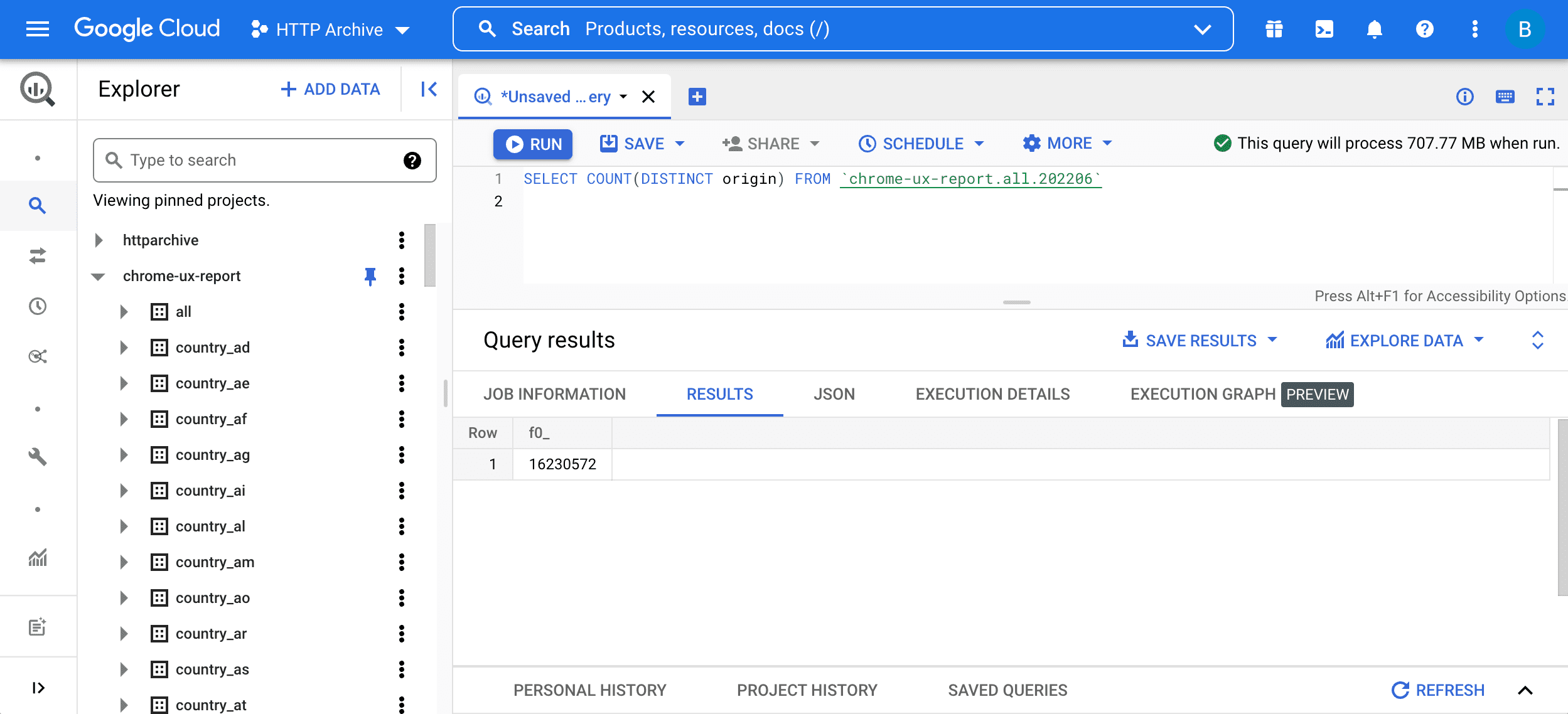
Zapytanie to składa się z 2 części:
SELECT COUNT(DISTINCT origin)oznacza wysłanie zapytania o liczbę źródeł w tabeli. Ogólnie rzecz biorąc, 2 adresy URL są częścią tego samego źródła, jeśli mają ten sam schemat, hosta i port.FROM chrome-ux-report.all.202206określa adres tabeli źródłowej, która składa się z 3 części:- Nazwa projektu Cloud
chrome-ux-report, w którym znajdują się wszystkie dane raportu CrUX - Zbiór danych
allzawierający dane ze wszystkich krajów - Tabela
202206, rok i miesiąc danych w formacie RRRRMM.
- Nazwa projektu Cloud
Dane są też dostępne dla każdego kraju. Na przykład chrome-ux-report.country_ca.202206 reprezentuje tylko dane dotyczące wrażeń użytkowników pochodzące z Kanady.
W zbiorze danych są tabele odpowiadające poszczególnym miesiącom od 201710 r. Regularnie publikujemy nowe tabele dotyczące poprzedniego miesiąca kalendarzowego.
Struktura tabel danych (zwana też schematem) zawiera:
- Źródło, np.
origin = 'https://www.example.com', które reprezentuje zbiorczą dystrybucję wrażeń użytkowników na wszystkich stronach w danej witrynie. - Szybkość połączenia w momencie wczytywania strony, np.
effective_connection_type.name = '4G' - Typ urządzenia, na przykład
form_factor.name = 'desktop'. - Dane dotyczące UX.
Dane dotyczące każdego rodzaju danych są uporządkowane w tablicę obiektów. W zapisie JSON element first_contentful_paint.histogram.bin wyglądałby tak:
[
{"start": 0, "end": 100, "density": 0.1234},
{"start": 100, "end": 200, "density": 0.0123},
...
]
Każdy przedział zawiera czas rozpoczęcia i zakończenia w milisekundach oraz gęstość obrazu, która odzwierciedla odsetek wrażeń użytkowników w danym przedziale czasu. Inaczej mówiąc, w przypadku tej hipotetycznej usługi FCP, szybkości połączenia i typu urządzenia 12, 34% użytkowników ma mniej niż 100 ms. Suma wszystkich gęstości zbiorników wynosi 100%.
Przeglądaj strukturę tabel w BigQuery.
Ocena skuteczności
Dzięki swojej wiedzy o schemacie tabel możemy napisać zapytanie wyodrębniające te dane o wydajności.
SELECT
fcp
FROM
`chrome-ux-report.all.202206`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
effective_connection_type.name = '4G' AND
form_factor.name = 'phone' AND
fcp.start = 0
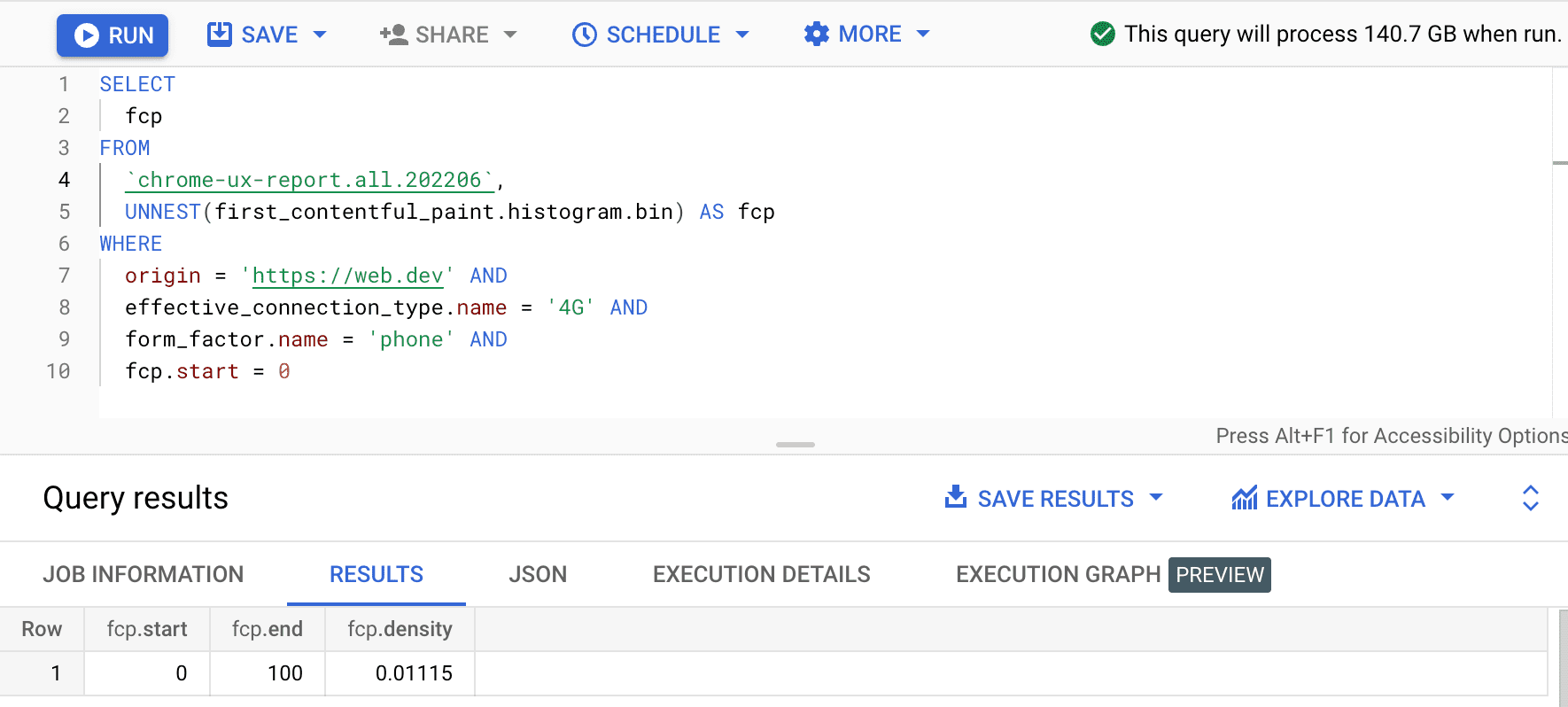
Wynik to 0.01115, co oznacza, że 1,115% wrażeń użytkownika w tym źródle trwa od 0 do 100 ms w sieci 4G i na telefonie. Jeśli chcemy uogólnić zapytanie, aby dotyczyło dowolnego połączenia i dowolnego typu urządzenia, możemy pominąć te informacje w klauzuli WHERE i użyć funkcji agregatora SUM, aby zsumować wszystkie odpowiednie gęstości binów:
SELECT
SUM(fcp.density)
FROM
`chrome-ux-report.all.202206`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start = 0
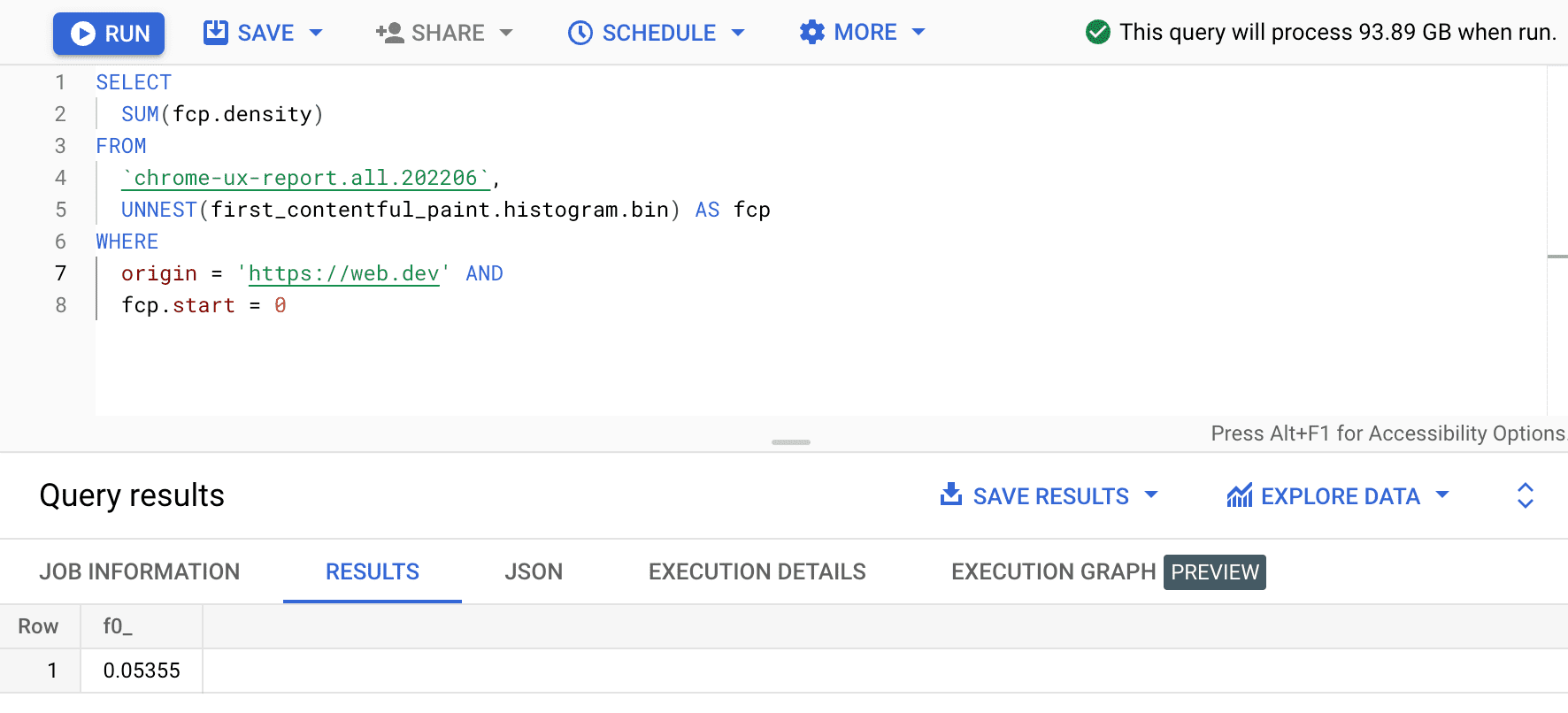
Wynik to 0.05355, czyli 5,355% w przypadku wszystkich urządzeń i typów połączeń. Możemy nieznacznie zmodyfikować zapytanie i dodać gęstości dla wszystkich przedziałów, które mieszczą się w zakresie „szybki” FCP (0–1000 ms):
SELECT
SUM(fcp.density) AS fast_fcp
FROM
`chrome-ux-report.all.202206`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start < 1000
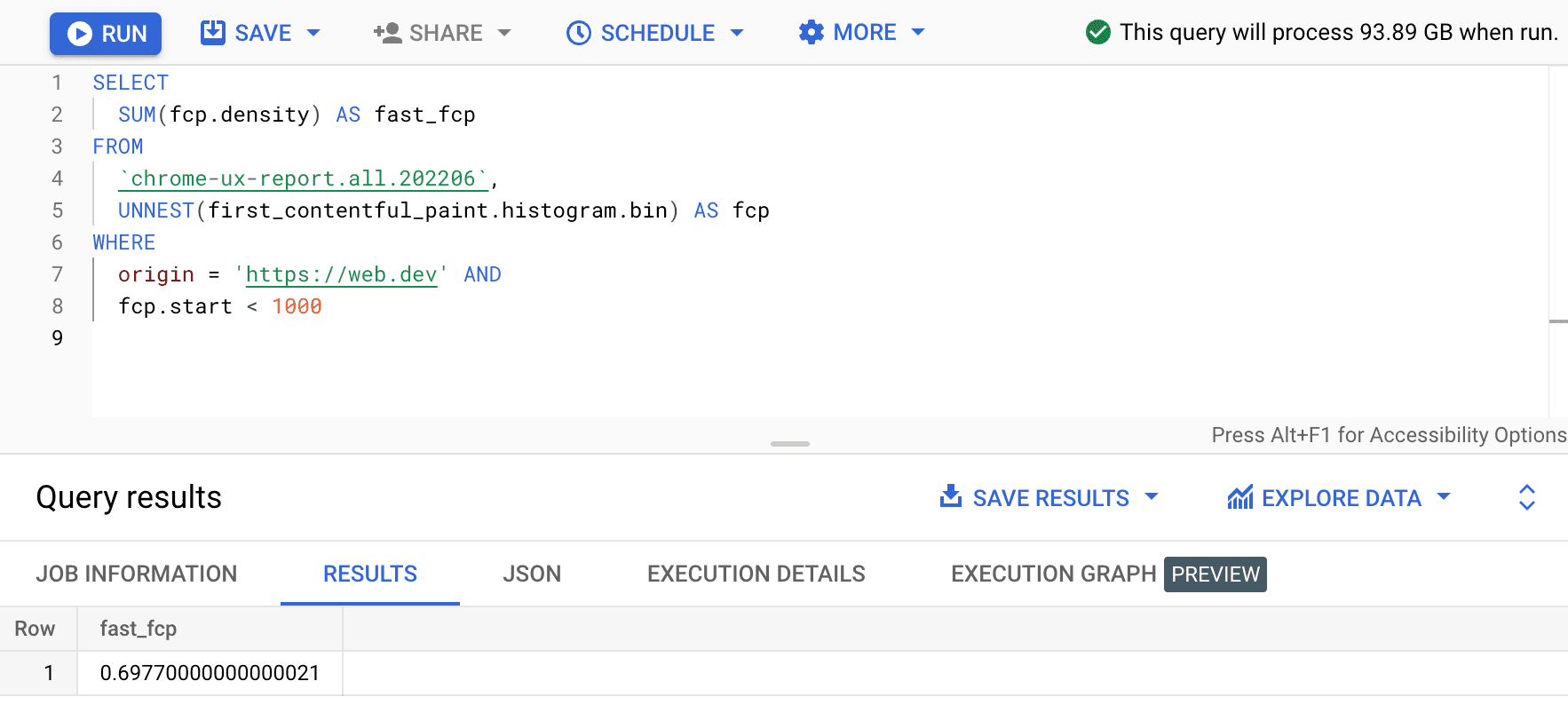
Dzięki temu mamy 0.6977. Inaczej mówiąc, 69,77% wrażeń użytkowników w ramach FCP w web.dev jest uznawanych za „szybkie” zgodnie z definicją zakresu FCP.
Śledzenie skuteczności
Po wyodrębnieniu danych o wydajności źródła możemy je porównać z danymi historycznymi dostępnymi w starszych tabelach. Aby to zrobić, możemy zmienić adres tabeli na wcześniejszy miesiąc lub użyć składni z symbolem wieloznacznym, aby zapytać o wszystkie miesiące:
SELECT
_TABLE_SUFFIX AS yyyymm,
SUM(fcp.density) AS fast_fcp
FROM
`chrome-ux-report.all.*`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start < 1000
GROUP BY
yyyymm
ORDER BY
yyyymm DESC
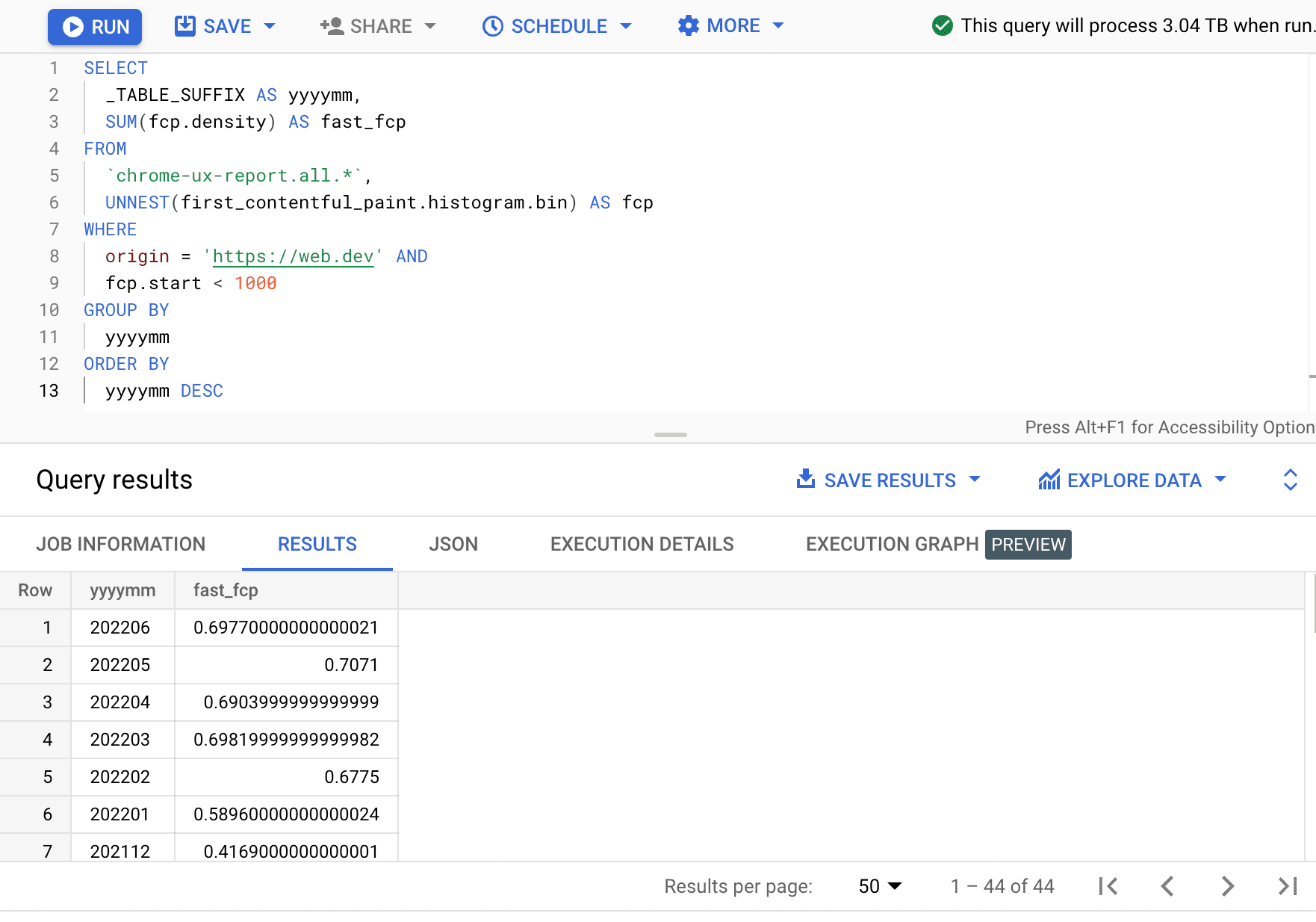
Widać tu, że odsetek szybkich sesji FCP zmienia się co miesiąc o kilka punktów procentowych.
| rrrrmm | fast_fcp |
|---|---|
| 202206 | 69,77% |
| 202205 | 70,71% |
| 202204 | 69,04% |
| 202203 | 69,82% |
| 202202 | 67,75% |
| 202201 | 58,96% |
| 202112 | 41,69% |
| … | … |
Dzięki tym technikom możesz sprawdzić skuteczność pochodzenia, obliczyć odsetek szybkich doświadczeń i śledzić go na przestrzeni czasu. W następnym kroku przeprowadź zapytanie dotyczące co najmniej 2 źródeł i porównaj ich skuteczność.
Najczęstsze pytania
Oto niektóre z najczęstszych pytań o zbiór danych BigQuery w CrUX:
Kiedy warto używać BigQuery zamiast innych narzędzi?
BigQuery jest potrzebne tylko wtedy, gdy nie możesz uzyskać tych samych informacji z innych narzędzi, np. z panelu CrUX lub narzędzia PageSpeed Insights. Na przykład BigQuery umożliwia dzielenie danych na sensowne części, a nawet ich złączanie z innymi publicznymi zbiorami danych, takimi jak archiwum HTTP, aby przeprowadzać zaawansowane wydobywanie danych.
Czy korzystanie z BigQuery wiąże się z jakimiś ograniczeniami?
Tak. Najważniejszym ograniczeniem jest to, że domyślnie użytkownicy mogą wysyłać zapytania dotyczące danych o wielkości maksymalnie 1 TB na miesiąc. Po przekroczeniu tego limitu obowiązuje standardowa stawka 5 USD/TB.
Gdzie mogę dowiedzieć się więcej o BigQuery?
Więcej informacji znajdziesz w dokumentacji BigQuery.