
Разрешение сервисным работникам сообщать браузерам, какие страницы работают в автономном режиме.

Что такое API индексирования контента?
Использование прогрессивного веб-приложения означает наличие доступа к важной для людей информации — изображениям, видео, статьям и т. д. — независимо от текущего состояния вашего сетевого подключения. Такие технологии, как сервис-воркеры , Cache Storage API и IndexedDB, предоставляют вам строительные блоки для хранения и обслуживания данных, когда люди напрямую взаимодействуют с PWA. Но создание высококачественного PWA, ориентированного на офлайн-режим, — это только часть дела. Если люди не осознают, что контент веб-приложения доступен в автономном режиме, они не смогут в полной мере воспользоваться преимуществами работы, которую вы вложили в реализацию этой функциональности.
Это проблема открытия ; как ваш PWA может информировать пользователей о своем контенте, доступном в автономном режиме, чтобы они могли находить и просматривать то, что доступно? API индексирования контента — решение этой проблемы. Часть этого решения, ориентированная на разработчиков, представляет собой расширение для сервисных работников, которое позволяет разработчикам добавлять URL-адреса и метаданные страниц, поддерживающих автономный режим, в локальный индекс, поддерживаемый браузером. Это улучшение доступно в Chrome 84 и более поздних версиях.
Как только индекс будет заполнен содержимым вашего PWA, а также любых других установленных PWA, он будет отображаться в браузере, как показано ниже.

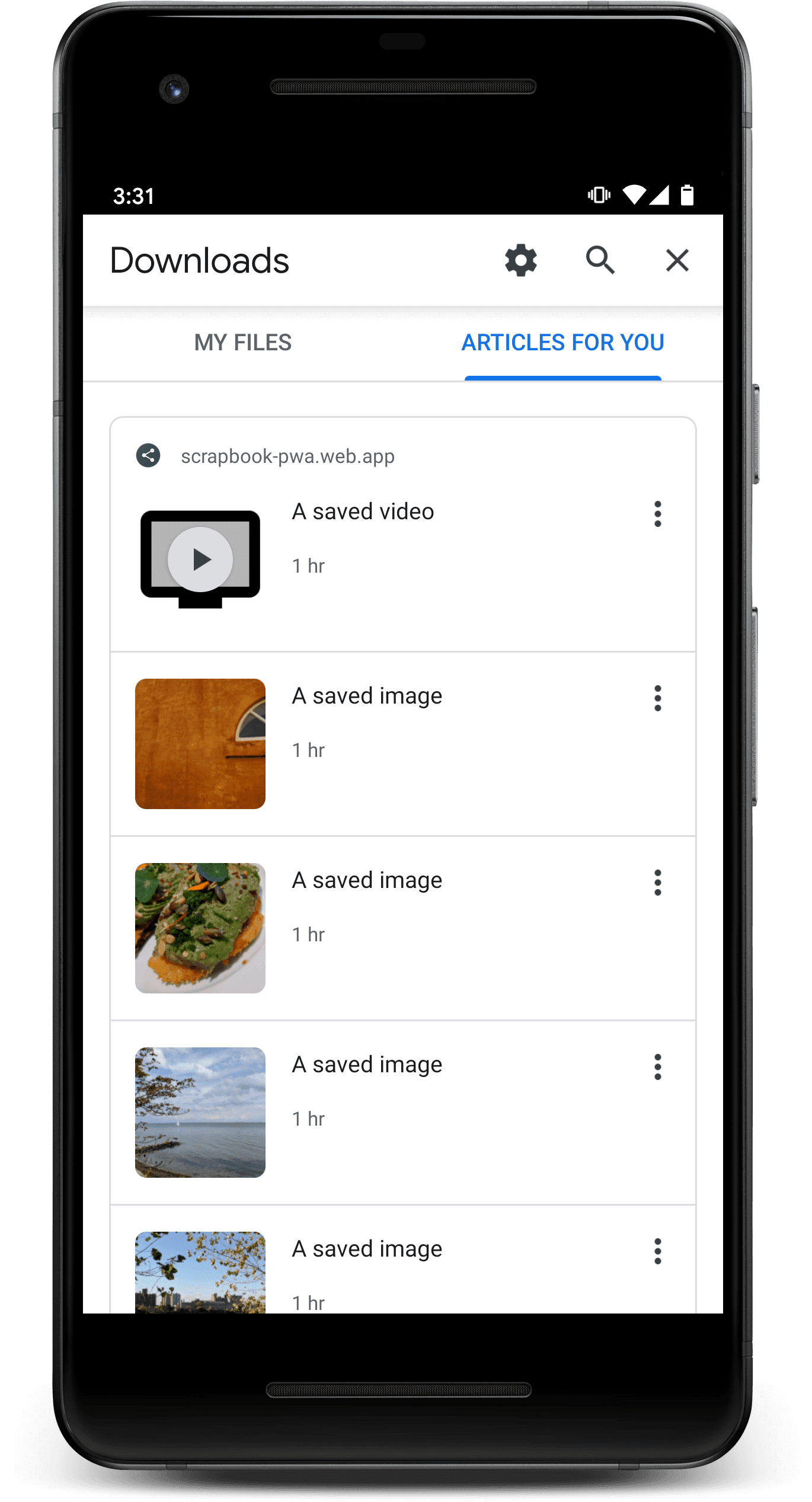
Кроме того, Chrome может заранее рекомендовать контент, когда обнаруживает, что пользователь не в сети.
API индексирования контента не является альтернативным способом кэширования контента . Это способ предоставления метаданных о страницах, которые уже кэшированы вашим сервис-воркером, чтобы браузер мог отображать эти страницы, когда люди, вероятно, захотят их просмотреть. API индексирования контента помогает обнаруживать кэшированные страницы.
Посмотрите это в действии
Лучший способ познакомиться с API индексирования контента — попробовать пример приложения.
- Убедитесь, что вы используете поддерживаемый браузер и платформу. В настоящее время это ограничено Chrome 84 или более поздней версии на Android . Перейдите на страницу
about://version, чтобы узнать, какую версию Chrome вы используете. - Посетите https://contentindex.dev.
- Нажмите кнопку
+рядом с одним или несколькими элементами в списке. - (Необязательно) Отключите Wi-Fi и сотовую связь вашего устройства или включите режим полета, чтобы имитировать автономный режим вашего браузера.
- Выберите «Загрузки» в меню Chrome и переключитесь на вкладку «Статьи для вас» .
- Просмотрите ранее сохраненный контент.
Посмотреть исходный код примера приложения можно на GitHub .
Другой пример приложения, Scrapbook PWA , иллюстрирует использование Content Indexing API с API Web Share Target . Код демонстрирует метод синхронизации API индексирования контента с элементами, хранящимися веб-приложением с помощью API Cache Storage .
Использование API
Чтобы использовать API, в вашем приложении должен быть сервис-воркер и URL-адреса, доступные для навигации в автономном режиме. Если в вашем веб-приложении в настоящее время нет сервис-воркера, библиотеки Workbox могут упростить его создание.
Какие типы URL-адресов можно проиндексировать как доступные в автономном режиме?
API поддерживает индексирование URL-адресов, соответствующих HTML-документам. Например, URL-адрес кэшированного медиа-файла не может быть проиндексирован напрямую. Вместо этого вам необходимо предоставить URL-адрес страницы, на которой отображаются мультимедиа и которая работает в автономном режиме.
Рекомендуемый шаблон — создать HTML-страницу «просмотрщика», которая могла бы принимать базовый URL-адрес мультимедиа в качестве параметра запроса, а затем отображать содержимое файла, возможно, с дополнительными элементами управления или содержимым на странице.
Веб-приложения могут добавлять в индекс контента только те URL-адреса, которые находятся в области действия текущего сервисного работника. Другими словами, веб-приложение не могло добавить URL-адрес, принадлежащий совершенно другому домену, в индекс контента.
Обзор
API индексирования контента поддерживает три операции: добавление, перечисление и удаление метаданных. Эти методы предоставляются из нового свойства index , добавленного в интерфейс ServiceWorkerRegistration .
Первым шагом в индексировании контента является получение ссылки на текущий ServiceWorkerRegistration . Использование navigator.serviceWorker.ready — самый простой способ:
const registration = await navigator.serviceWorker.ready;
// Remember to feature-detect before using the API:
if ('index' in registration) {
// Your Content Indexing API code goes here!
}
Если вы вызываете API индексирования контента из сервис-воркера, а не внутри веб-страницы, вы можете обратиться к ServiceWorkerRegistration напрямую через registration . Он уже будет определен как часть ServiceWorkerGlobalScope.
Добавление в индекс
Используйте метод add() для индексации URL-адресов и связанных с ними метаданных. Вам решать, когда элементы добавляются в индекс. Возможно, вы захотите добавить его в индекс в ответ на ввод, например нажатие кнопки «Сохранить в автономном режиме». Или вы можете добавлять элементы автоматически каждый раз, когда кэшированные данные обновляются с помощью такого механизма, как периодическая фоновая синхронизация .
await registration.index.add({
// Required; set to something unique within your web app.
id: 'article-123',
// Required; url needs to be an offline-capable HTML page.
url: '/articles/123',
// Required; used in user-visible lists of content.
title: 'Article title',
// Required; used in user-visible lists of content.
description: 'Amazing article about things!',
// Required; used in user-visible lists of content.
icons: [{
src: '/img/article-123.png',
sizes: '64x64',
type: 'image/png',
}],
// Optional; valid categories are currently:
// 'homepage', 'article', 'video', 'audio', or '' (default).
category: 'article',
});
Добавление записи влияет только на индекс контента; он ничего не добавляет в кеш .
Пограничный случай: вызовите add() из контекста window , если ваши значки полагаются на обработчик fetch .
Когда вы вызываете add() , Chrome запросит URL-адрес каждого значка, чтобы убедиться, что у него есть копия значка, которую можно использовать при отображении списка проиндексированного контента.
Если вы вызываете
add()из контекстаwindow(другими словами, с вашей веб-страницы), этот запрос вызовет событиеfetchдля вашего сервис-воркера.Если вы вызываете
add()внутри своего сервис-воркера (возможно, внутри другого обработчика событий), запрос не вызовет обработчикfetchсервис-воркера. Значки будут загружены напрямую, без участия сервисного работника. Имейте это в виду, если ваши значки зависят от вашего обработчикаfetch, возможно, потому, что они существуют только в локальном кеше, а не в сети. Если да, убедитесь, что вы вызываетеadd()только из контекстаwindow.
Листинг содержимого индекса
Метод getAll() возвращает обещание для итерируемого списка индексированных записей и их метаданных. Возвращенные записи будут содержать все данные, сохраненные с помощью add() .
const entries = await registration.index.getAll();
for (const entry of entries) {
// entry.id, entry.launchUrl, etc. are all exposed.
}
Удаление элементов из индекса
Чтобы удалить элемент из индекса, вызовите delete() указав id удаляемого элемента:
await registration.index.delete('article-123');
Вызов delete() влияет только на индекс. Он ничего не удаляет из кэша .
Обработка события удаления пользователя
Когда браузер отображает проиндексированный контент, он может включать собственный пользовательский интерфейс с пунктом меню «Удалить» , давая людям возможность указать, что они закончили просмотр ранее проиндексированного контента. Вот как выглядит интерфейс удаления в Chrome 80:
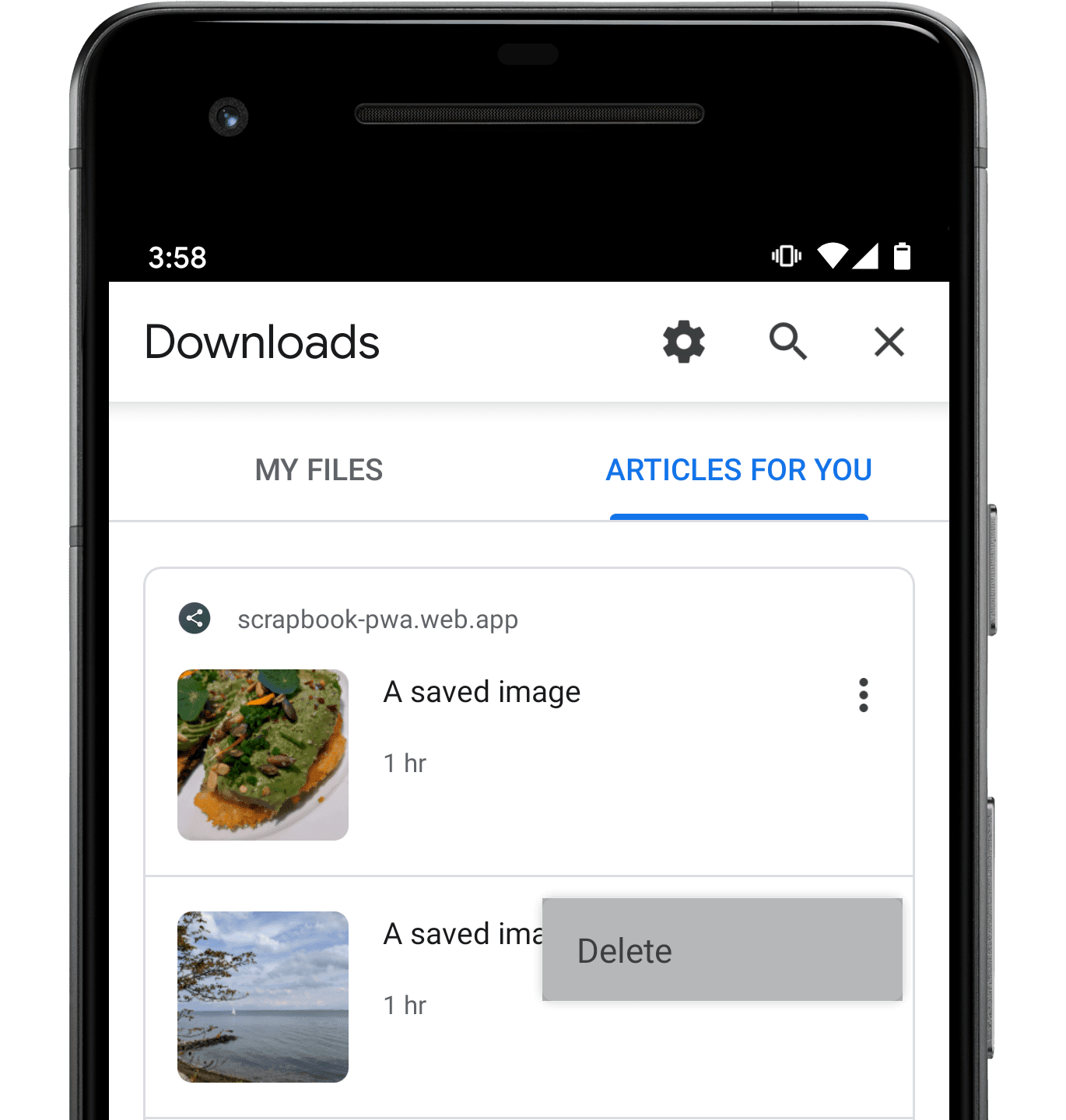
Когда кто-то выбирает этот пункт меню, сервис-воркер вашего веб-приложения получит событие contentdelete . Хотя обработка этого события не является обязательной, она дает вашему сервисному работнику возможность «очистить» контент, например локально кэшированные медиафайлы, с которыми кто-то указал, что они закончили.
Вам не нужно вызывать registration.index.delete() внутри обработчика contentdelete ; если событие было запущено, соответствующее удаление индекса уже выполнено браузером.
self.addEventListener('contentdelete', (event) => {
// event.id will correspond to the id value used
// when the indexed content was added.
// Use that value to determine what content, if any,
// to delete from wherever your app stores it—usually
// the Cache Storage API or perhaps IndexedDB.
});
Отзыв о дизайне API
Есть ли что-то в API неудобное или не работает должным образом? Или есть недостающие детали, необходимые для реализации вашей идеи?
Сообщите о проблеме в репозитории GitHub с объяснением API индексирования контента или добавьте свои мысли к существующей проблеме.
Проблема с реализацией?
Вы нашли ошибку в реализации Chrome?
Сообщите об ошибке на https://new.crbug.com . Включите как можно больше деталей, простые инструкции по воспроизведению и установите для Components значение Blink>ContentIndexing .
Планируете использовать API?
Планируете использовать API индексирования контента в своем веб-приложении? Ваша публичная поддержка помогает Chrome расставлять приоритеты для функций и показывает другим поставщикам браузеров, насколько важно их поддерживать.
- Отправьте твит @ChromiumDev, используя хэштег
#ContentIndexingAPIи подробно описав, где и как вы его используете.
Каковы последствия индексации контента для безопасности и конфиденциальности?
Ознакомьтесь с ответами на анкету W3C по безопасности и конфиденциальности . Если у вас есть дополнительные вопросы, начните обсуждение через репозиторий проекта на GitHub .
Изображение героя Максима Кагарлицкого на Unsplash .
,Разрешение сервисным работникам сообщать браузерам, какие страницы работают в автономном режиме.
Что такое API индексирования контента?
Использование прогрессивного веб-приложения означает наличие доступа к важной для людей информации — изображениям, видео, статьям и т. д. — независимо от текущего состояния вашего сетевого подключения. Такие технологии, как сервис-воркеры , Cache Storage API и IndexedDB, предоставляют вам строительные блоки для хранения и обслуживания данных, когда люди напрямую взаимодействуют с PWA. Но создание высококачественного PWA, ориентированного на офлайн-режим, — это только часть дела. Если люди не осознают, что контент веб-приложения доступен в автономном режиме, они не смогут в полной мере воспользоваться преимуществами работы, которую вы вложили в реализацию этой функциональности.
Это проблема открытия ; как ваш PWA может информировать пользователей о своем контенте, доступном в автономном режиме, чтобы они могли находить и просматривать то, что доступно? API индексирования контента — решение этой проблемы. Часть этого решения, ориентированная на разработчиков, представляет собой расширение для сервисных работников, которое позволяет разработчикам добавлять URL-адреса и метаданные страниц, поддерживающих автономный режим, в локальный индекс, поддерживаемый браузером. Это улучшение доступно в Chrome 84 и более поздних версиях.
Как только индекс будет заполнен содержимым вашего PWA, а также любых других установленных PWA, он будет отображаться в браузере, как показано ниже.
Кроме того, Chrome может заранее рекомендовать контент, когда обнаруживает, что пользователь не в сети.
API индексирования контента не является альтернативным способом кэширования контента . Это способ предоставления метаданных о страницах, которые уже кэшированы вашим сервис-воркером, чтобы браузер мог отображать эти страницы, когда люди, вероятно, захотят их просмотреть. API индексирования контента помогает обнаруживать кэшированные страницы.
Посмотрите это в действии
Лучший способ познакомиться с API индексирования контента — попробовать пример приложения.
- Убедитесь, что вы используете поддерживаемый браузер и платформу. В настоящее время это ограничено Chrome 84 или более поздней версии на Android . Перейдите на страницу
about://version, чтобы узнать, какую версию Chrome вы используете. - Посетите https://contentindex.dev.
- Нажмите кнопку
+рядом с одним или несколькими элементами в списке. - (Необязательно) Отключите Wi-Fi и сотовую связь вашего устройства или включите режим полета, чтобы имитировать автономный режим вашего браузера.
- Выберите «Загрузки» в меню Chrome и переключитесь на вкладку «Статьи для вас» .
- Просмотрите ранее сохраненный контент.
Посмотреть исходный код примера приложения можно на GitHub .
Другой пример приложения, Scrapbook PWA , иллюстрирует использование Content Indexing API с API Web Share Target . Код демонстрирует метод синхронизации API индексирования контента с элементами, хранящимися веб-приложением с помощью API Cache Storage .
Использование API
Чтобы использовать API, в вашем приложении должен быть сервис-воркер и URL-адреса, доступные для навигации в автономном режиме. Если в вашем веб-приложении в настоящее время нет сервис-воркера, библиотеки Workbox могут упростить его создание.
Какие типы URL-адресов можно проиндексировать как доступные в автономном режиме?
API поддерживает индексирование URL-адресов, соответствующих HTML-документам. Например, URL-адрес кэшированного медиа-файла не может быть проиндексирован напрямую. Вместо этого вам необходимо предоставить URL-адрес страницы, на которой отображаются мультимедиа и которая работает в автономном режиме.
Рекомендуемый шаблон — создать HTML-страницу «просмотрщика», которая могла бы принимать базовый URL-адрес мультимедиа в качестве параметра запроса, а затем отображать содержимое файла, возможно, с дополнительными элементами управления или содержимым на странице.
Веб-приложения могут добавлять в индекс контента только те URL-адреса, которые находятся в области действия текущего сервисного работника. Другими словами, веб-приложение не могло добавить URL-адрес, принадлежащий совершенно другому домену, в индекс контента.
Обзор
API индексирования контента поддерживает три операции: добавление, перечисление и удаление метаданных. Эти методы предоставляются из нового свойства index , добавленного в интерфейс ServiceWorkerRegistration .
Первым шагом в индексировании контента является получение ссылки на текущий ServiceWorkerRegistration . Использование navigator.serviceWorker.ready — самый простой способ:
const registration = await navigator.serviceWorker.ready;
// Remember to feature-detect before using the API:
if ('index' in registration) {
// Your Content Indexing API code goes here!
}
Если вы вызываете API индексирования контента из сервис-воркера, а не внутри веб-страницы, вы можете обратиться к ServiceWorkerRegistration напрямую через registration . Он уже будет определен как часть ServiceWorkerGlobalScope.
Добавление в индекс
Используйте метод add() для индексации URL-адресов и связанных с ними метаданных. Вам решать, когда элементы будут добавляться в индекс. Возможно, вы захотите добавить его в индекс в ответ на ввод, например нажатие кнопки «Сохранить в автономном режиме». Или вы можете добавлять элементы автоматически каждый раз, когда кэшированные данные обновляются с помощью такого механизма, как периодическая фоновая синхронизация .
await registration.index.add({
// Required; set to something unique within your web app.
id: 'article-123',
// Required; url needs to be an offline-capable HTML page.
url: '/articles/123',
// Required; used in user-visible lists of content.
title: 'Article title',
// Required; used in user-visible lists of content.
description: 'Amazing article about things!',
// Required; used in user-visible lists of content.
icons: [{
src: '/img/article-123.png',
sizes: '64x64',
type: 'image/png',
}],
// Optional; valid categories are currently:
// 'homepage', 'article', 'video', 'audio', or '' (default).
category: 'article',
});
Добавление записи влияет только на индекс контента; он ничего не добавляет в кеш .
Пограничный случай: вызовите add() из контекста window , если ваши значки полагаются на обработчик fetch .
Когда вы вызываете add() , Chrome запросит URL-адрес каждого значка, чтобы убедиться, что у него есть копия значка, которую можно использовать при отображении списка проиндексированного контента.
Если вы вызываете
add()из контекстаwindow(другими словами, с вашей веб-страницы), этот запрос вызовет событиеfetchдля вашего сервис-воркера.Если вы вызываете
add()внутри своего сервис-воркера (возможно, внутри другого обработчика событий), запрос не вызовет обработчикfetchсервис-воркера. Значки будут загружены напрямую, без участия сервисного работника. Имейте это в виду, если ваши значки зависят от вашего обработчикаfetch, возможно, потому, что они существуют только в локальном кеше, а не в сети. Если да, убедитесь, что вы вызываетеadd()только из контекстаwindow.
Листинг содержимого индекса
Метод getAll() возвращает обещание для итерируемого списка индексированных записей и их метаданных. Возвращенные записи будут содержать все данные, сохраненные с помощью add() .
const entries = await registration.index.getAll();
for (const entry of entries) {
// entry.id, entry.launchUrl, etc. are all exposed.
}
Удаление элементов из индекса
Чтобы удалить элемент из индекса, вызовите delete() указав id удаляемого элемента:
await registration.index.delete('article-123');
Вызов delete() влияет только на индекс. Он ничего не удаляет из кэша .
Обработка события удаления пользователя
Когда браузер отображает проиндексированный контент, он может включать собственный пользовательский интерфейс с пунктом меню «Удалить» , давая людям возможность указать, что они закончили просмотр ранее проиндексированного контента. Вот как выглядит интерфейс удаления в Chrome 80:
Когда кто-то выбирает этот пункт меню, сервис-воркер вашего веб-приложения получит событие contentdelete . Хотя обработка этого события не является обязательной, она дает вашему сервисному работнику возможность «очистить» контент, например локально кэшированные медиафайлы, с которыми кто-то указал, что они закончили.
Вам не нужно вызывать registration.index.delete() внутри обработчика contentdelete ; если событие было запущено, соответствующее удаление индекса уже выполнено браузером.
self.addEventListener('contentdelete', (event) => {
// event.id will correspond to the id value used
// when the indexed content was added.
// Use that value to determine what content, if any,
// to delete from wherever your app stores it—usually
// the Cache Storage API or perhaps IndexedDB.
});
Отзыв о дизайне API
Есть ли что-то в API неудобное или не работает должным образом? Или есть недостающие детали, необходимые для реализации вашей идеи?
Сообщите о проблеме в репозитории GitHub с объяснением API индексирования контента или добавьте свои мысли к существующей проблеме.
Проблема с реализацией?
Вы нашли ошибку в реализации Chrome?
Сообщите об ошибке на https://new.crbug.com . Включите как можно больше деталей, простые инструкции по воспроизведению и установите для Components значение Blink>ContentIndexing .
Планируете использовать API?
Планируете использовать API индексирования контента в своем веб-приложении? Ваша публичная поддержка помогает Chrome расставлять приоритеты для функций и показывает другим поставщикам браузеров, насколько важно их поддерживать.
- Отправьте твит @ChromiumDev, используя хэштег
#ContentIndexingAPIи подробно описав, где и как вы его используете.
Каковы последствия индексации контента для безопасности и конфиденциальности?
Ознакомьтесь с ответами на анкету W3C по безопасности и конфиденциальности . Если у вас есть дополнительные вопросы, начните обсуждение через репозиторий проекта на GitHub .
Изображение героя Максима Кагарлицкого на Unsplash .
,Разрешение сервисным работникам сообщать браузерам, какие страницы работают в автономном режиме.
Что такое API индексирования контента?
Использование прогрессивного веб-приложения означает наличие доступа к важной для людей информации — изображениям, видео, статьям и т. д. — независимо от текущего состояния вашего сетевого подключения. Такие технологии, как сервис-воркеры , Cache Storage API и IndexedDB, предоставляют вам строительные блоки для хранения и обслуживания данных, когда люди напрямую взаимодействуют с PWA. Но создание высококачественного PWA, ориентированного на офлайн-режим, — это только часть дела. Если люди не осознают, что контент веб-приложения доступен в автономном режиме, они не смогут в полной мере воспользоваться преимуществами работы, которую вы вложили в реализацию этой функциональности.
Это проблема открытия ; как ваш PWA может информировать пользователей о своем контенте, доступном в автономном режиме, чтобы они могли находить и просматривать то, что доступно? API индексирования контента — решение этой проблемы. Часть этого решения, ориентированная на разработчиков, представляет собой расширение для сервисных работников, которое позволяет разработчикам добавлять URL-адреса и метаданные страниц, поддерживающих автономный режим, в локальный индекс, поддерживаемый браузером. Это улучшение доступно в Chrome 84 и более поздних версиях.
Как только индекс будет заполнен содержимым вашего PWA, а также любых других установленных PWA, он будет отображаться в браузере, как показано ниже.
Кроме того, Chrome может заранее рекомендовать контент, когда обнаруживает, что пользователь не в сети.
API индексирования контента не является альтернативным способом кэширования контента . Это способ предоставления метаданных о страницах, которые уже кэшированы вашим сервис-воркером, чтобы браузер мог отображать эти страницы, когда люди, вероятно, захотят их просмотреть. API индексирования контента помогает обнаруживать кэшированные страницы.
Посмотрите это в действии
Лучший способ познакомиться с API индексирования контента — попробовать пример приложения.
- Убедитесь, что вы используете поддерживаемый браузер и платформу. В настоящее время это ограничено Chrome 84 или более поздней версии на Android . Перейдите на страницу
about://version, чтобы узнать, какую версию Chrome вы используете. - Посетите https://contentindex.dev.
- Нажмите кнопку
+рядом с одним или несколькими элементами в списке. - (Необязательно) Отключите Wi-Fi и сотовую связь вашего устройства или включите режим полета, чтобы имитировать автономный режим вашего браузера.
- Выберите «Загрузки» в меню Chrome и переключитесь на вкладку «Статьи для вас» .
- Просмотрите ранее сохраненный контент.
Посмотреть исходный код примера приложения можно на GitHub .
Другой пример приложения, Scrapbook PWA , иллюстрирует использование Content Indexing API с API Web Share Target . Код демонстрирует метод синхронизации API индексирования контента с элементами, хранящимися веб-приложением с помощью API Cache Storage .
Использование API
Чтобы использовать API, в вашем приложении должен быть сервис-воркер и URL-адреса, доступные для навигации в автономном режиме. Если в вашем веб-приложении в настоящее время нет сервис-воркера, библиотеки Workbox могут упростить его создание.
Какие типы URL-адресов можно проиндексировать как доступные в автономном режиме?
API поддерживает индексирование URL-адресов, соответствующих HTML-документам. Например, URL-адрес кэшированного медиа-файла не может быть проиндексирован напрямую. Вместо этого вам необходимо предоставить URL-адрес страницы, на которой отображаются мультимедиа и которая работает в автономном режиме.
Рекомендуемый шаблон — создать HTML-страницу «просмотрщика», которая могла бы принимать базовый URL-адрес мультимедиа в качестве параметра запроса, а затем отображать содержимое файла, возможно, с дополнительными элементами управления или содержимым на странице.
Веб-приложения могут добавлять в индекс контента только те URL-адреса, которые находятся в области действия текущего сервисного работника. Другими словами, веб-приложение не могло добавить URL-адрес, принадлежащий совершенно другому домену, в индекс контента.
Обзор
API индексирования контента поддерживает три операции: добавление, перечисление и удаление метаданных. Эти методы предоставляются из нового свойства index , добавленного в интерфейс ServiceWorkerRegistration .
Первым шагом в индексировании контента является получение ссылки на текущий ServiceWorkerRegistration . Использование navigator.serviceWorker.ready — самый простой способ:
const registration = await navigator.serviceWorker.ready;
// Remember to feature-detect before using the API:
if ('index' in registration) {
// Your Content Indexing API code goes here!
}
Если вы вызываете API индексирования контента из сервис-воркера, а не внутри веб-страницы, вы можете обратиться к ServiceWorkerRegistration напрямую через registration . Он уже будет определен как часть ServiceWorkerGlobalScope.
Добавление в индекс
Используйте метод add() для индексации URL-адресов и связанных с ними метаданных. Вам решать, когда элементы добавляются в индекс. Возможно, вы захотите добавить его в индекс в ответ на ввод, например нажатие кнопки «Сохранить в автономном режиме». Или вы можете добавлять элементы автоматически каждый раз, когда кэшированные данные обновляются с помощью такого механизма, как периодическая фоновая синхронизация .
await registration.index.add({
// Required; set to something unique within your web app.
id: 'article-123',
// Required; url needs to be an offline-capable HTML page.
url: '/articles/123',
// Required; used in user-visible lists of content.
title: 'Article title',
// Required; used in user-visible lists of content.
description: 'Amazing article about things!',
// Required; used in user-visible lists of content.
icons: [{
src: '/img/article-123.png',
sizes: '64x64',
type: 'image/png',
}],
// Optional; valid categories are currently:
// 'homepage', 'article', 'video', 'audio', or '' (default).
category: 'article',
});
Добавление записи влияет только на индекс контента; он ничего не добавляет в кеш .
Пограничный случай: вызовите add() из контекста window , если ваши значки полагаются на обработчик fetch .
Когда вы вызываете add() , Chrome запросит URL-адрес каждого значка, чтобы убедиться, что у него есть копия значка, которую можно использовать при отображении списка проиндексированного контента.
Если вы вызываете
add()из контекстаwindow(другими словами, с вашей веб-страницы), этот запрос вызовет событиеfetchдля вашего сервис-воркера.Если вы вызываете
add()внутри своего сервис-воркера (возможно, внутри другого обработчика событий), запрос не вызовет обработчикfetchсервис-воркера. Значки будут загружены напрямую, без участия сервисного работника. Имейте это в виду, если ваши значки зависят от вашего обработчикаfetch, возможно, потому, что они существуют только в локальном кеше, а не в сети. Если да, убедитесь, что вы вызываетеadd()только из контекстаwindow.
Листинг содержимого индекса
Метод getAll() возвращает обещание для итерируемого списка индексированных записей и их метаданных. Возвращенные записи будут содержать все данные, сохраненные с помощью add() .
const entries = await registration.index.getAll();
for (const entry of entries) {
// entry.id, entry.launchUrl, etc. are all exposed.
}
Удаление элементов из индекса
Чтобы удалить элемент из индекса, вызовите delete() указав id удаляемого элемента:
await registration.index.delete('article-123');
Вызов delete() влияет только на индекс. Он ничего не удаляет из кэша .
Обработка события удаления пользователя
Когда браузер отображает проиндексированный контент, он может включать собственный пользовательский интерфейс с пунктом меню «Удалить» , давая людям возможность указать, что они закончили просмотр ранее проиндексированного контента. Вот как выглядит интерфейс удаления в Chrome 80:
Когда кто-то выбирает этот пункт меню, сервис-воркер вашего веб-приложения получит событие contentdelete . Хотя обработка этого события не является обязательной, она дает вашему сервисному работнику возможность «очистить» контент, например локально кэшированные медиафайлы, с которыми кто-то указал, что они закончили.
Вам не нужно вызывать registration.index.delete() внутри обработчика contentdelete ; если событие было запущено, соответствующее удаление индекса уже выполнено браузером.
self.addEventListener('contentdelete', (event) => {
// event.id will correspond to the id value used
// when the indexed content was added.
// Use that value to determine what content, if any,
// to delete from wherever your app stores it—usually
// the Cache Storage API or perhaps IndexedDB.
});
Отзыв о дизайне API
Есть ли что-то в API неудобное или не работает должным образом? Или есть недостающие детали, необходимые для реализации вашей идеи?
Сообщите о проблеме в репозитории GitHub с объяснением API индексирования контента или добавьте свои мысли к существующей проблеме.
Проблема с реализацией?
Вы нашли ошибку в реализации Chrome?
Сообщите об ошибке на https://new.crbug.com . Включите как можно больше деталей, простые инструкции по воспроизведению и установите для Components значение Blink>ContentIndexing .
Планируете использовать API?
Планируете использовать API индексирования контента в своем веб-приложении? Ваша публичная поддержка помогает Chrome расставлять приоритеты для функций и показывает другим поставщикам браузеров, насколько важно их поддерживать.
- Отправьте твит @ChromiumDev, используя хэштег
#ContentIndexingAPIи подробно описав, где и как вы его используете.
Каковы последствия индексации контента для безопасности и конфиденциальности?
Ознакомьтесь с ответами на анкету W3C по безопасности и конфиденциальности . Если у вас есть дополнительные вопросы, начните обсуждение через репозиторий проекта на GitHub .
Изображение героя Максима Кагарлицкого на Unsplash .