
您可能以为,汇总统计信息不会泄露统计信息中所含数据的主人的任何信息。然而,事实上攻击者可以通过诸多手段从汇总统计信息获悉数据集中有关个人的敏感信息。
为了保护个人隐私,您需要学习如何使用 Privacy on Beam 中的差分隐私汇总来生成隐私统计信息。Privacy on Beam 是一个与 Apache Beam 配合使用的差分隐私框架。
“隐私”是什么意思?
此 Codelab 中使用的“隐私”一词是指用于生成输出结果的方式不会泄露数据中有关个人的任何隐私信息。若要做到这一点,我们可以使用差分隐私,这是一种作用强大的匿名化隐私概念。匿名化是通过汇总多个用户的数据来保护用户隐私的过程。所有匿名化方法都会使用汇总方法,但并非所有汇总方法都能实现匿名化。另一方面,差分隐私还可以在信息泄露和隐私保护方面提供可衡量的保证。
为了更好地了解差分隐私,我们来看一个简单的示例。
下面的条形图显示了一家小餐厅在某一个晚上的繁忙程度。晚上 7 点有大量顾客光临,而凌晨 1 点餐厅空无一人:
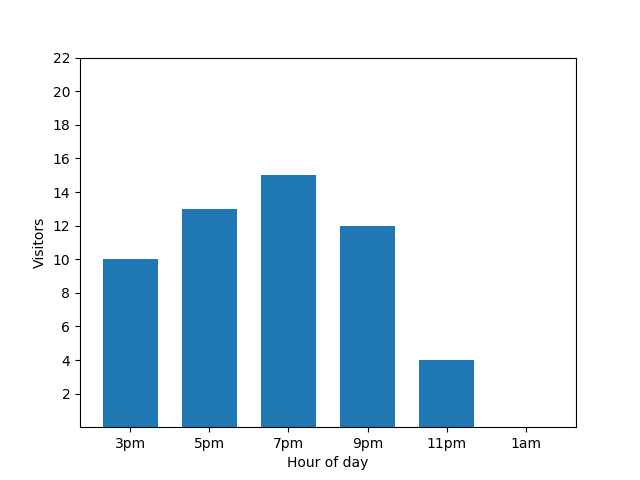
看起来似乎非常有用!
然而,存在一个问题。当一位新顾客光临时,条形图会立即揭示这一事实。请看图表:很明显有一位新顾客,而且这位顾客大约在凌晨 1 点抵店:

从隐私角度而言,这是一个弊端。真正匿名化的统计信息不应泄露个体的计入情况。将两个图表并排比较,结果会更加明显:橙色条形图多出了一位在凌晨 1 点左右光临的顾客:
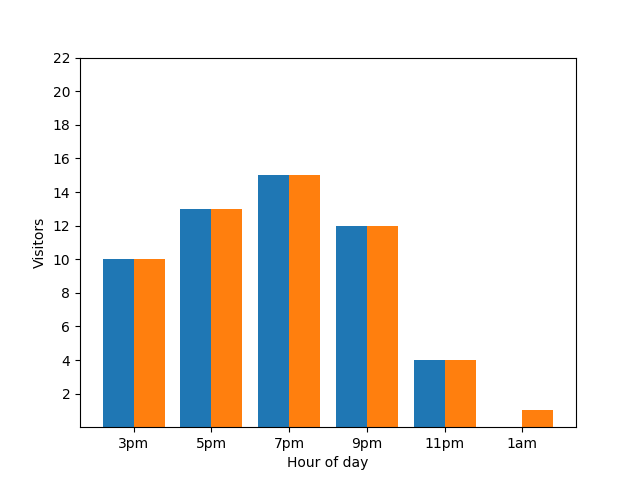
重申一遍,这是一个弊端。那么,我们该怎么办?
我们要添加随机噪声,略微降低条形图的准确性!
请看下面两个条形图。虽然这两个图并非完全准确,但仍然有用,而且不会泄露个体的计入情况。不错!

差分隐私是指添加适量的随机噪声来掩盖个体的计入情况。
我们的分析有点过于简化。正确实现差分隐私涉及更多问题,还存在许多非常出人意料的细微实现差异。与加密类似,自行创建差分隐私实现可能并不是一个好主意。您可以使用 Privacy on Beam,而不是实现您自己的解决方案。请勿部署您自己的差分隐私实现!
在此 Codelab 中,我们将介绍如何使用 Privacy on Beam 执行差分隐私分析。
您无需下载 Privacy on Beam 就可以关注代码实验室,因为所有相关代码和图表都可以在本文档中找到。 但是,如果您希望下载以使用代码、自行运行或稍后使用隐私上的 Beam,请按照以下步骤操作。
请注意,此代码实验室适用于该库的 1.1.0 版。
首先,下载 Privacy on Beam:
或者,您也可以克隆 GitHub 代码库:
git clone --branch v1.1.0 https://github.com/google/differential-privacy.git
Privacy on Beam 位于顶级 privacy-on-beam/ 目录中。
此 Codelab 和数据集的代码位于 privacy-on-beam/codelab/ 目录中。
您还需要在计算机上安装 Bazel。您可以在 Bazel 网站上找到适用于您的操作系统的安装说明。
假设您是一位餐厅老板并想分享一些有关您的餐厅的统计信息,比如公开顾客喜欢光临的时间。值得庆幸的是,您知道差分隐私和匿名化,因此您希望采用一种不会泄露任何个体顾客信息的方式来进行这种分享。
此示例的代码位于 codelab/count.go 中。
首先,我们加载一个模拟数据集,其中包含您的餐厅在某一个星期一的顾客光临数据。它的代码并非此 Codelab 的关注点,不过您可以在 codelab/main.go、codelab/utils.go 和 codelab/visit.go 中查阅相关代码。
顾客 ID | 进店时间 | 逗留时间(分钟) | 消费金额(欧元) |
1 | 上午 9:30:00 | 26 | 24 |
2 | 上午 11:54:00 | 53 | 17 |
3 | 下午 1:05:00 | 81 | 33 |
您要先使用 Beam 在以下代码示例中生成餐厅的顾客光临时间的非隐私条形图。Scope 是流水线的表示形式,我们对数据执行的每个新操作都会添加到 Scope 中。CountVisitsPerHour 接受一个 Scope 和一个光临数据集合,该集合在 Beam 中表示为 PCollection。它通过对集合应用 extractVisitHour 函数来提取每次顾客光临的时段。然后,计算每个时段的顾客光临次数并返回结果。
func CountVisitsPerHour(s beam.Scope, col beam.PCollection) beam.PCollection {
s = s.Scope("CountVisitsPerHour")
visitHours := beam.ParDo(s, extractVisitHourFn, col)
visitsPerHour := stats.Count(s, visitHours)
return visitsPerHour
}
func extractVisitHourFn(v Visit) int {
return v.TimeEntered.Hour()
}
这段代码会在当前目录中(通过运行 bazel run codelab -- --example="count" --input_file=$(pwd)/day_data.csv --output_stats_file=$(pwd)/count.csv --output_chart_file=$(pwd)/count.png)生成有效的条形图,并命名为 count.png:

下一步是将流水线和条形图转换为隐私图表。具体操作如下:
首先,对 PCollection<V> 调用 MakePrivateFromStruct 以获取 PrivatePCollection<V>。输入 PCollection 必须是结构体集合。我们需要输入一个 PrivacySpec 和一个 idFieldPath 作为 MakePrivateFromStruct 的输入。
spec := pbeam.NewPrivacySpec(epsilon, delta) pCol := pbeam.MakePrivateFromStruct(s, col, spec, "VisitorID")
PrivacySpec 是一个结构体,其中包含我们想要用于对数据进行匿名化的差分隐私参数(epsilon 和 delta)。(您目前无需关注这些参数,如果您想详细了解,后面安排了相关的可选章节。)
idFieldPath 是结构体内的用户标识符字段(在本例中为 Visit)的路径。在本例中,顾客的用户标识符是 Visit 的 VisitorID 字段。
接下来,我们调用 pbeam.Count() 而不是 stats.Count(),pbeam.Count() 接受一个 CountParams 结构体作为输入,该结构体包含 MaxValue 等影响输出准确性的参数。
visitsPerHour := pbeam.Count(s, visitHours, pbeam.CountParams{
// Visitors can visit the restaurant once (one hour) a day
MaxPartitionsContributed: 1,
// Visitors can visit the restaurant once within an hour
MaxValue: 1,
})
同理,MaxPartitionsContributed 用于限制用户可计入多少个不同的光临时段。我们认为顾客每天最多只会光临餐厅一次(或者我们不在意他们是否一天当中多次光临餐厅),因此我们将其也设为 1。我们会在可选章节中更详细地介绍这些参数。
MaxValue 用于限制单个用户可以计入我们所计算的值中多少次。在本例中,我们计算的值是光临时段,而且我们认为一位用户只会光临餐厅一次(或者我们不在意他们是否每个时段光临餐厅多次),因此我们将此参数设为 1。
最后,您的代码将如下所示:
func PrivateCountVisitsPerHour(s beam.Scope, col beam.PCollection) beam.PCollection {
s = s.Scope("PrivateCountVisitsPerHour")
// Create a Privacy Spec and convert col into a PrivatePCollection
spec := pbeam.NewPrivacySpec(epsilon, delta)
pCol := pbeam.MakePrivateFromStruct(s, col, spec, "VisitorID")
visitHours := pbeam.ParDo(s, extractVisitHourFn, pCol)
visitsPerHour := pbeam.Count(s, visitHours, pbeam.CountParams{
// Visitors can visit the restaurant once (one hour) a day
MaxPartitionsContributed: 1,
// Visitors can visit the restaurant once within an hour
MaxValue: 1,
})
return visitsPerHour
}
我们会看到一个相似的差分隐私统计信息条形图 (count_dp.png)(前一个命令同时运行非隐私和隐私流水线):
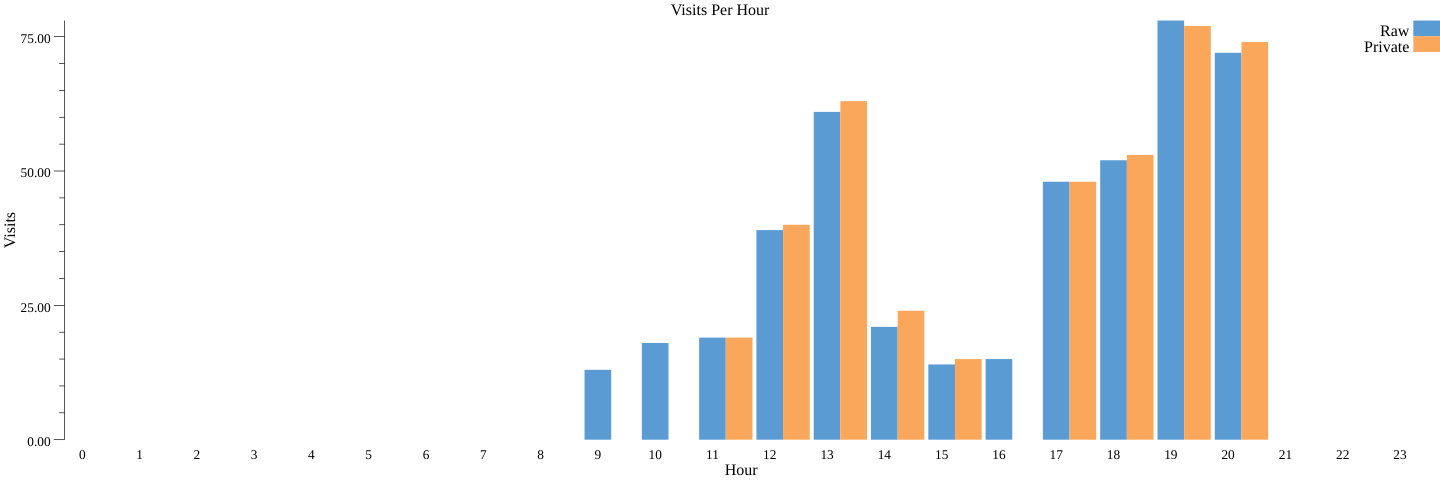
恭喜!您已完成第一次差分隐私统计信息的计算!
您在运行代码时生成的条形图可能与此图表不同。没关系。由于差分隐私中使用了噪声,每次运行代码时都会生成不同的条形图,但是您会发现,这些图表或多或少都与原始的非隐私条形图相似。
请注意,不要多次重复运行流水线(例如,为了获得更美观的条形图而重复运行),这一点对于保证隐私非常重要。“计算多次统计信息”部分说明了不应重复运行流水线的原因。
在上一部分中,您可能已经注意到,我们去除了某些部分(即某些时段)的所有光临(数据)。
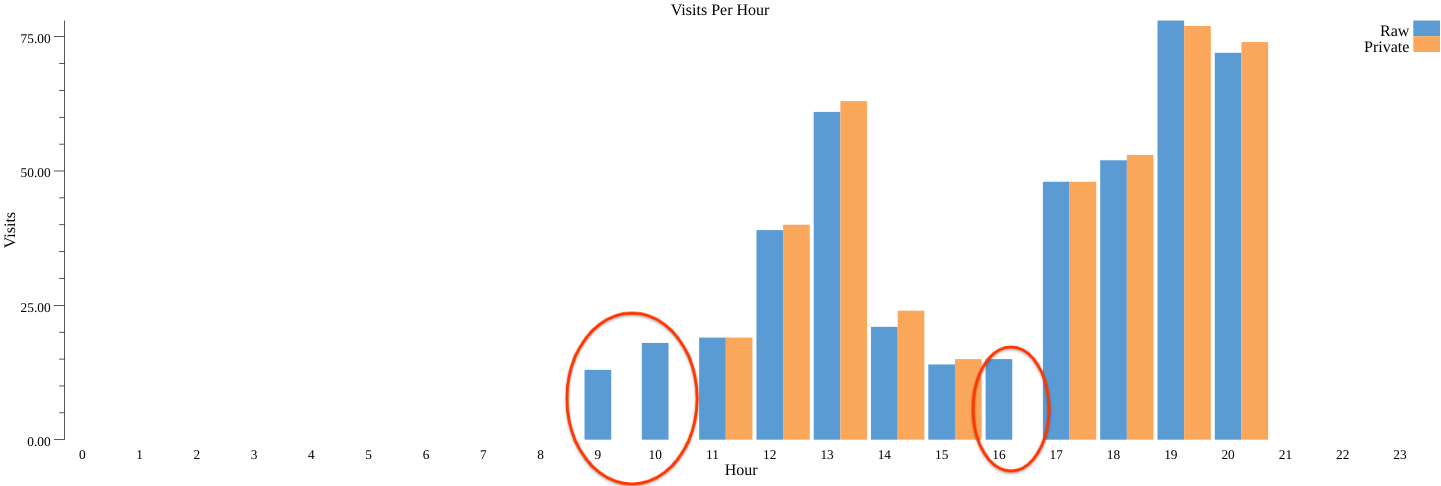
这是选择所需部分/设定阈值造成的,当各输出部分是否存在取决于用户数据本身时,这一步对于确保差分隐私得到保证非常重要。在那种情况下,仅凭输出中存在某个部分就会泄露数据中存在单个用户的事实(如需查看有关这样做为什么违反隐私权的说明,请参阅此博文)。为了防止出现这种情况,Privacy on Beam 仅保留包含足够数量的用户的那些部分。
当是否列出各输出部分并不取决于用户隐私数据时(即,属于公开信息),就不需要执行选择所需部分这一步。实际上,我们的餐厅例子正是这种情况:我们知道餐厅的工作时间(9.00 点到 21.00 点)。
此示例的代码位于 codelab/public_partitions.go 中。
我们只需创建由 9 点到 21 点(不含)之间的时段组成的 PCollection,然后将其输入 CountParams 的 PublicPartitions 字段:
func PrivateCountVisitsPerHourWithPublicPartitions(s beam.Scope,
col beam.PCollection) beam.PCollection {
s = s.Scope("PrivateCountVisitsPerHourWithPublicPartitions")
// Create a Privacy Spec and convert col into a PrivatePCollection
spec := pbeam.NewPrivacySpec(epsilon, /* delta */ 0)
pCol := pbeam.MakePrivateFromStruct(s, col, spec, "VisitorID")
// Create a PCollection of output partitions, i.e. restaurant's work hours
// (from 9 am till 9pm (exclusive)).
hours := beam.CreateList(s, [12]int{9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20})
visitHours := pbeam.ParDo(s, extractVisitHourFn, pCol)
visitsPerHour := pbeam.Count(s, visitHours, pbeam.CountParams{
// Visitors can visit the restaurant once (one hour) a day
MaxPartitionsContributed: 1,
// Visitors can visit the restaurant once within an hour
MaxValue: 1,
// Visitors only visit during work hours
PublicPartitions: hours,
})
return visitsPerHour
}
请注意,如果使用公开部分和拉普拉斯噪声(默认选项),可以将 delta 设为 0,如上所示。
当我们(使用 bazel run codelab -- --example="public_partitions" --input_file=$(pwd)/day_data.csv --output_stats_file=$(pwd)/public_partitions.csv --output_chart_file=$(pwd)/public_partitions.png)以公开部分运行流水线时,输出如下(public_partitions_dp.png):
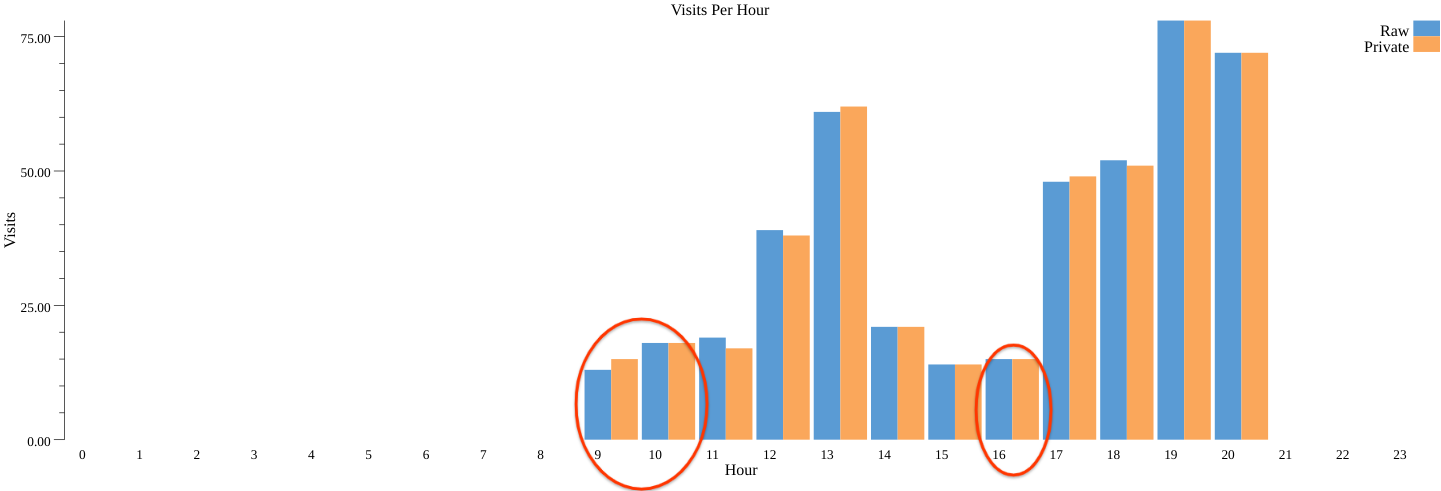
可以看到,我们现在保留了先前未使用公开部分时去除的 9、10 和 16 这几部分。
使用公开部分不仅可以保留更多部分,而且因为无需在选择所需部分上花任何隐私预算(即,epsilon 和 delta),它为每个部分添加的噪声大约只有不使用公开部分时的一半。因此,与上一次运行流水线相比,原始计数与隐私计数之间的差异略小。
使用公开部分时,有两个重要注意事项:
- 从原始数据派生所需部分列表时,请务必小心:如果不以差分隐私方式执行此操作(例如,直接读取用户数据中所有部分的列表),流水线就无法再提供差分隐私保证。如需了解如何以差分隐私方式执行此操作,请参阅下文“高级”部分。
- 如果某些公开部分没有数据(例如,光临数据),将对这些部分应用噪声以保护差分隐私。例如,如果我们使用 0 点到 24 点(而非 9 点到 21 点)之间的时段,那么就会对所有时段应用噪声,并有可能在没有光临数据的情况下显示一些光临数据。
(高级)从数据中派生所需部分
如果在同一流水线中以相同的非公开输出部分列表运行多次汇总,可以使用 SelectPartitions() 派生一次所需部分列表,然后将这些部分作为 PublicPartition 输入提供给每次汇总。这样做不仅能从隐私角度保护安全,还可以减少需要添加的噪声,因为整个流水线只需在选择所需部分上花一次隐私预算。
现在,我们已经了解如何以差分隐私方式进行计算,接下来我们将介绍如何计算平均值。具体而言,我们现在将计算顾客的平均逗留时间。
此示例的代码位于 codelab/mean.go 中。
通常,若要计算逗留时间的非隐私平均值,我们会使用 stats.MeanPerKey(),通过预处理步骤将传入的光临数据 PCollection 转换为 PCollection<K,V>,其中 K 是光临时段,而 V 是顾客在餐厅逗留的时间。
func MeanTimeSpent(s beam.Scope, col beam.PCollection) beam.PCollection {
s = s.Scope("MeanTimeSpent")
hourToTimeSpent := beam.ParDo(s, extractVisitHourAndTimeSpentFn, col)
meanTimeSpent := stats.MeanPerKey(s, hourToTimeSpent)
return meanTimeSpent
}
func extractVisitHourAndTimeSpentFn(v Visit) (int, int) {
return v.TimeEntered.Hour(), v.MinutesSpent
}
这段代码会在当前目录中(通过运行 bazel run codelab -- --example="mean" --input_file=$(pwd)/day_data.csv --output_stats_file=$(pwd)/mean.csv --output_chart_file=$(pwd)/mean.png)生成有效的条形图,并命名为 mean.png:
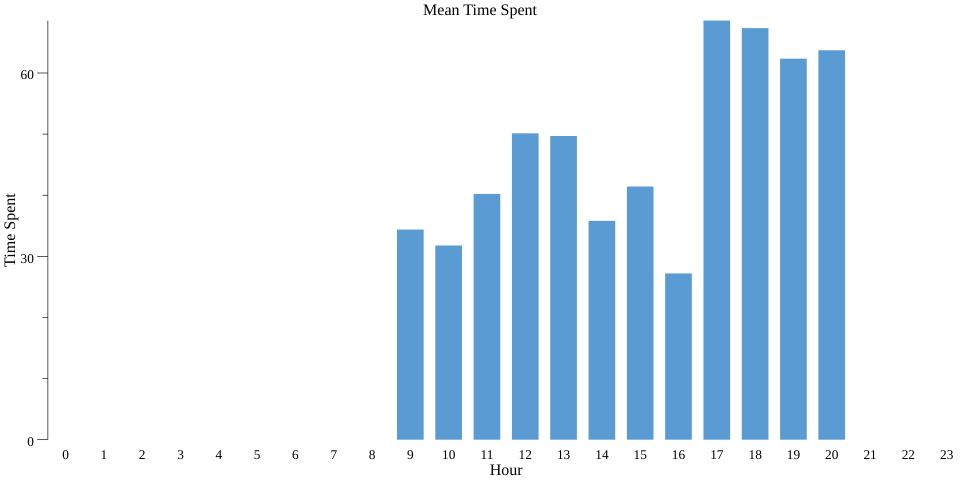
为了对此进行差分隐私处理,我们再次将 PCollection 转换为 PrivatePCollection,并将 stats.MeanPerKey() 替换为 pbeam.MeanPerKey()。与 Count 类似,MeanParams 包含一些影响准确性的参数,例如 MinValue 和 MaxValue。MinValue 和 MaxValue 表示我们对每个用户计入每个键所设定的限制。
meanTimeSpent := pbeam.MeanPerKey(s, hourToTimeSpent, pbeam.MeanParams{
// Visitors can visit the restaurant once (one hour) a day
MaxPartitionsContributed: 1,
// Visitors can visit the restaurant once within an hour
MaxContributionsPerPartition: 1,
// Minimum time spent per user (in mins)
MinValue: 0,
// Maximum time spent per user (in mins)
MaxValue: 60,
})
在本例中,每个键表示一个时段,而值则表示顾客逗留的时间。我们将 MinValue 设为 0,因为我们认为顾客在餐厅逗留的时间不会少于 0 分钟。我们将 MaxValue 设为 60,这意味着如果顾客逗留的时间超过 60 分钟,我们便假定该用户逗留了 60 分钟。
最后,您的代码将如下所示:
func PrivateMeanTimeSpent(s beam.Scope, col beam.PCollection) beam.PCollection {
s = s.Scope("PrivateMeanTimeSpent")
// Create a Privacy Spec and convert col into a PrivatePCollection
spec := pbeam.NewPrivacySpec(epsilon, /* delta */ 0)
pCol := pbeam.MakePrivateFromStruct(s, col, spec, "VisitorID")
// Create a PCollection of output partitions, i.e. restaurant's work hours
// (from 9 am till 9pm (exclusive)).
hours := beam.CreateList(s, [12]int{9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20})
hourToTimeSpent := pbeam.ParDo(s, extractVisitHourAndTimeSpentFn, pCol)
meanTimeSpent := pbeam.MeanPerKey(s, hourToTimeSpent, pbeam.MeanParams{
// Visitors can visit the restaurant once (one hour) a day
MaxPartitionsContributed: 1,
// Visitors can visit the restaurant once within an hour
MaxContributionsPerPartition: 1,
// Minimum time spent per user (in mins)
MinValue: 0,
// Maximum time spent per user (in mins)
MaxValue: 60,
// Visitors only visit during work hours
PublicPartitions: hours,
})
return meanTimeSpent
}
我们会看到一个相似的差分隐私统计信息条形图 (mean_dp.png)(前一个命令同时运行非隐私和隐私流水线):
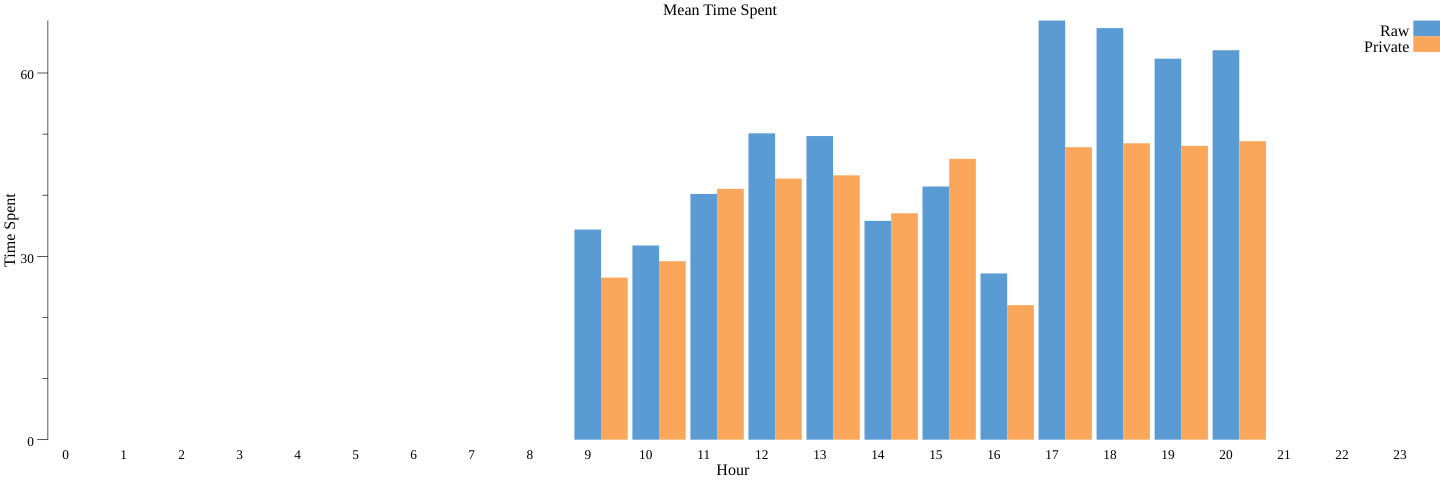
同样,与计数类似,由于这是差分隐私操作,所以每次运行时都会得出不同的结果。但是可以看到,差分隐私逗留时间与实际结果相差不远。
我们可以再来分析一项有趣的统计信息,那就是一天之中的每时段收入。
此示例的代码位于 codelab/sum.go 中。
同样,我们从非隐私版本开始。对模拟数据集进行一些预处理后,我们可以创建一个 PCollection<K,V>,其中 K 是光临时段,V 是顾客在餐厅的消费金额:若要计算非隐私的每时段收入,我们只需调用 stats.SumPerKey() 对顾客消费的所有金额求和:
func RevenuePerHour(s beam.Scope, col beam.PCollection) beam.PCollection {
s = s.Scope("RevenuePerHour")
hourToMoneySpent := beam.ParDo(s, extractVisitHourAndMoneySpentFn, col)
revenues := stats.SumPerKey(s, hourToMoneySpent)
return revenues
}
func extractVisitHourAndMoneySpentFn(v Visit) (int, int) {
return v.TimeEntered.Hour(), v.MoneySpent
}
这段代码会在当前目录中(通过运行 bazel run codelab -- --example="sum" --input_file=$(pwd)/day_data.csv --output_stats_file=$(pwd)/sum.csv --output_chart_file=$(pwd)/sum.png)生成有效的条形图,并命名为 sum.png:
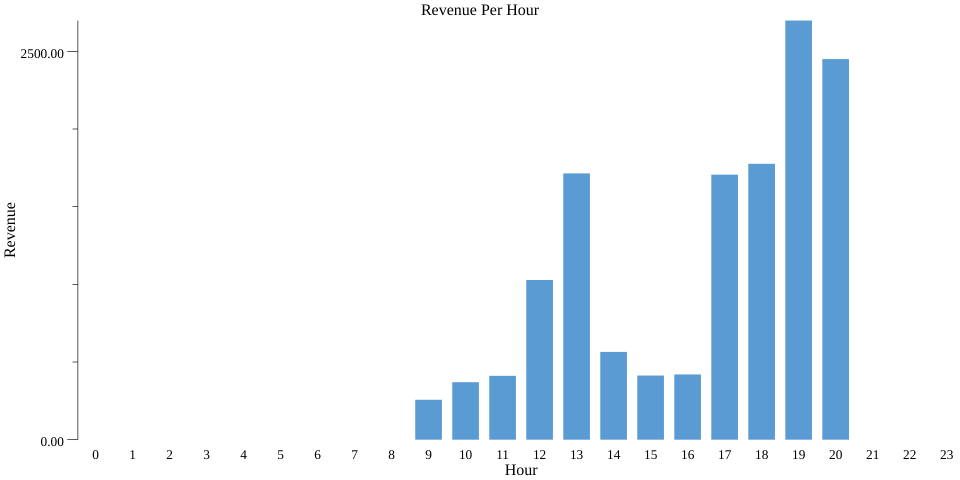
为了对此进行差分隐私处理,我们再次将 PCollection 转换为 PrivatePCollection,并将 stats.SumPerKey() 替换为 pbeam.SumPerKey()。与 Count 和 MeanPerKey 类似,SumParams 包含一些影响准确性的参数,例如 MinValue 和 MaxValue。
revenues := pbeam.SumPerKey(s, hourToMoneySpent, pbeam.SumParams{
// Visitors can visit the restaurant once (one hour) a day
MaxPartitionsContributed: 1,
// Minimum money spent per user (in euros)
MinValue: 0,
// Maximum money spent per user (in euros)
MaxValue: 40,
})
在本例中,MinValue 和 MaxValue 表示我们对每位顾客消费的金额所设定的限制。我们将 MinValue 设为 0,因为我们认为顾客在餐厅消费的金额不会少于 0 欧元。我们将 MaxValue 设为 40,这意味着如果顾客消费的金额超过 40 欧元,我们便假定该用户消费了 40 欧元。
最后,代码将如下所示:
func PrivateRevenuePerHour(s beam.Scope, col beam.PCollection) beam.PCollection {
s = s.Scope("PrivateRevenuePerHour")
// Create a Privacy Spec and convert col into a PrivatePCollection
spec := pbeam.NewPrivacySpec(epsilon, /* delta */ 0)
pCol := pbeam.MakePrivateFromStruct(s, col, spec, "VisitorID")
// Create a PCollection of output partitions, i.e. restaurant's work hours
// (from 9 am till 9pm (exclusive)).
hours := beam.CreateList(s, [12]int{9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20})
hourToMoneySpent := pbeam.ParDo(s, extractVisitHourAndMoneySpentFn, pCol)
revenues := pbeam.SumPerKey(s, hourToMoneySpent, pbeam.SumParams{
// Visitors can visit the restaurant once (one hour) a day
MaxPartitionsContributed: 1,
// Minimum money spent per user (in euros)
MinValue: 0,
// Maximum money spent per user (in euros)
MaxValue: 40,
// Visitors only visit during work hours
PublicPartitions: hours,
})
return revenues
}
我们会看到一个相似的差分隐私统计信息条形图 (sum_dp.png)(前一个命令同时运行非隐私和隐私流水线):
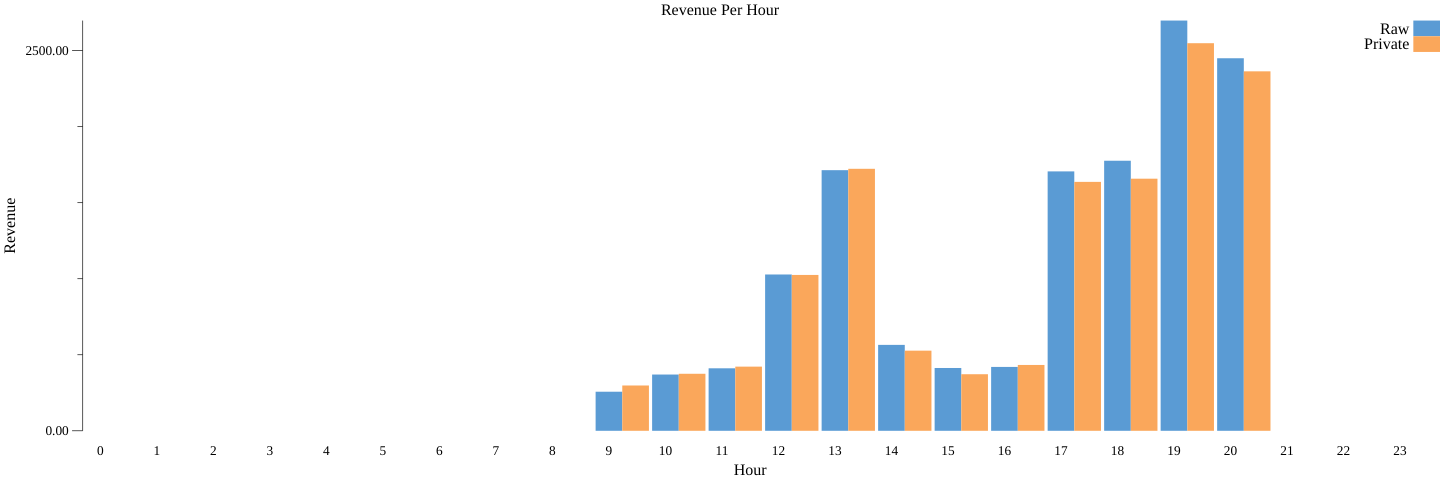
同样,与计数和平均值类似,由于这是差分隐私操作,所以每次运行时都会得出不同的结果。但是可以看到,差分隐私结果非常接近于实际的每时段收入。
在大多数情况下,您可能都会对基于相同的基础数据计算多次统计信息感兴趣,就像您在计算计数、平均值和总和时那样。在单一 Beam 流水线和单个二进制文件中,这种做法通常更整洁也更容易。您也可以使用 Privacy on Beam 执行此操作。编写一个流水线来运行转换和计算,并在整个流水线中使用单个 PrivacySpec。
使用单个 PrivacySpec 不仅更方便,也能更好地保护隐私。还记得我们提供给 PrivacySpec 的 epsilon 和 delta 参数吧,它们代表所谓的“隐私预算”,用于衡量您泄露了基础数据中的多少用户隐私。
关于隐私预算的一个重要注意事项是它是累积的:如果使用特定的 epsilon ε 和 delta δ 运行一次某个流水线,所花预算为 (ε,δ)。如果第二次运行该流水线,所花总预算为 (2ε, 2δ)。同理,如果使用 PrivacySpec (ε,δ)(并连续使用隐私预算)计算多次统计信息,所花总预算为 (2ε, 2δ)。这意味着,隐私保证水平正在逐步降低。
为了避免发生这种情况,当您想要基于相同的基础数据计算多次统计信息时,应使用包含您想使用的总预算的单个 PrivacySpec。然后,您需要指定要用于每次汇总的 epsilon 和 delta。最后的结果将是总体的隐私保证水平保持不变,而具体某一次汇总的 epsilon 和 delta 越高,其准确性就会越高。
为了亲眼一睹实际操作,我们可以在一个流水线中计算之前分别计算过的三项统计信息(计数、平均值和总和)。
此示例的代码位于 codelab/multiple.go 中。请注意我们是如何在三个汇总之间平均分配 (ε,δ) 总预算的:
func ComputeCountMeanSum(s beam.Scope, col beam.PCollection) (visitsPerHour, meanTimeSpent, revenues beam.PCollection) {
s = s.Scope("ComputeCountMeanSum")
// Create a Privacy Spec and convert col into a PrivatePCollection
// Budget is shared by count, mean and sum.
spec := pbeam.NewPrivacySpec(epsilon, /* delta */ 0)
pCol := pbeam.MakePrivateFromStruct(s, col, spec, "VisitorID")
// Create a PCollection of output partitions, i.e. restaurant's work hours
// (from 9 am till 9pm (exclusive)).
hours := beam.CreateList(s, [12]int{9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20})
visitHours := pbeam.ParDo(s, extractVisitHourFn, pCol)
visitsPerHour = pbeam.Count(s, visitHours, pbeam.CountParams{
// Visitors can visit the restaurant once (one hour) a day
MaxPartitionsContributed: 1,
// Visitors can visit the restaurant once within an hour
MaxValue: 1,
// Visitors only visit during work hours
PublicPartitions: hours,
})
hourToTimeSpent := pbeam.ParDo(s, extractVisitHourAndTimeSpentFn, pCol)
meanTimeSpent = pbeam.MeanPerKey(s, hourToTimeSpent, pbeam.MeanParams{
// Visitors can visit the restaurant once (one hour) a day
MaxPartitionsContributed: 1,
// Visitors can visit the restaurant once within an hour
MaxContributionsPerPartition: 1,
// Minimum time spent per user (in mins)
MinValue: 0,
// Maximum time spent per user (in mins)
MaxValue: 60,
// Visitors only visit during work hours
PublicPartitions: hours,
})
hourToMoneySpent := pbeam.ParDo(s, extractVisitHourAndMoneySpentFn, pCol)
revenues = pbeam.SumPerKey(s, hourToMoneySpent, pbeam.SumParams{
// Visitors can visit the restaurant once (one hour) a day
MaxPartitionsContributed: 1,
// Minimum money spent per user (in euros)
MinValue: 0,
// Maximum money spent per user (in euros)
MaxValue: 40,
// Visitors only visit during work hours
PublicPartitions: hours,
})
return visitsPerHour, meanTimeSpent, revenues
}
您已经看到此 Codelab 中提及的相当多参数:epsilon、delta、maxPartitionsContributed 等。我们可以将其大致分为两个类别:隐私参数和效用参数。
隐私参数
epsilon 和 delta 是量化使用差分隐私提供的隐私的参数。更确切地说,epsilon 和 delta 是一种度量,用于衡量潜在攻击者通过查看匿名输出能获取有关基础数据的多少信息。epsilon 和 delta 越高,攻击者获取的有关基础数据的信息就越多,这会带来隐私风险。
另一方面,epsilon 和 delta 越低,您需要添加到输出中以实现匿名化的噪声就越多,每个部分为了保留在匿名输出中而需要包含的唯一身份用户数量也越多。因此,此处需要在效用参数与隐私参数之间进行权衡。
在 Beam on Privacy 中,当您指定 PrivacySpec 中的总隐私预算时,您需要关心的是您想在匿名输出中提供的隐私保证。需要注意的是,如果您希望保持隐私保证水平,就必须遵照此 Codelab 中的建议,不要每次汇总都使用单独的 PrivacySpec,也不要多次运行流水线,以免过度使用预算。
如需详细了解差分隐私以及隐私参数的含义,可以查看文献。
效用参数
这些参数不会影响隐私保证(只要正确遵循有关如何使用 Privacy on Beam 的建议),但会影响准确性,进而影响输出的效用。每个汇总的 Params 结构体中会提供这些参数,例如 CountParams、SumParams 等。这些参数用于调节添加的噪声。
Params 中提供并适用于所有汇总的效用参数是 MaxPartitionsContributed。一个部分对应于 Privacy On Beam 汇总操作输出的 PCollection 的一个键(例如 Count、SumPerKey 等)。因此,MaxPartitionsContributed 对一个用户可以在输出中计入多少个不同的键值做出了限制。如果用户在基础数据中计入的键数超过 MaxPartitionsContributed 的值,其部分计入将被去除,使其计入的键数正好等于 MaxPartitionsContributed 的值。
与 MaxPartitionsContributed 相似,大多数汇总也有一个 MaxContributionsPerPartition 参数。Params 结构体中会提供这些参数,每个汇总的这些参数可以有不同的值。与 MaxPartitionsContributed 不同,MaxContributionsPerPartition 对一个用户计入每个键的次数做出了限制。换言之,一个用户计入每个键的次数只能等于 MaxContributionsPerPartition 的值。
添加到输出中的噪声根据 MaxPartitionsContributed 和 MaxContributionsPerPartition 进行调节,所以需要在此加以权衡:MaxPartitionsContributed 和 MaxContributionsPerPartition 较大都意味着可以保留更多数据,但最终得出的结果受噪声影响也更大。
有些汇总需要 MinValue 和 MaxValue。这些参数用于对每个用户的计入指定限制。如果用户计入的值小于 MinValue,该值将被上调至 MinValue。同理,如果用户计入的值大于 MaxValue,该值将被下调至 MaxValue。这意味着,为了保留更多原始值,必须指定更大的限制。与 MaxPartitionsContributed 和 MaxContributionsPerPartition 类似,噪声根据限制的大小进行调节,因此限制较大意味着可以保留更多数据,但最终得出的结果受噪声影响也更大。
我们要介绍的最后一个参数是 NoiseKind。Privacy On Beam 中支持两种不同的噪声机制:GaussianNoise 和 LaplaceNoise。两种机制各有利弊,但拉普拉斯分布以较低的计入限制提供更高的效用,因此 Privacy On Beam 默认使用此机制。不过,如果您希望使用高斯分布噪声,可以为 Params 提供 pbeam.GaussianNoise{} 变量。
太棒了!您已完成 Privacy on Beam Codelab,学到了许多有关差分隐私和 Privacy on Beam 的知识:
- 通过调用
MakePrivateFromStruct将PCollection转换为PrivatePCollection。 - 使用
Count计算差分隐私计数。 - 使用
MeanPerKey计算差分隐私平均值。 - 使用
SumPerKey计算差分隐私总和。 - 在一个流水线中使用单个
PrivacySpec计算多次统计信息。 - (可选)自定义
PrivacySpec和汇总参数 (CountParams, MeanParams, SumParams)。
不过,使用 Privacy on Beam,您还可以执行许多其他汇总(例如分位数,计算不同的值)!您可以通过 GitHub 代码库或 godoc 了解详情。
如果您有时间,请填写调查问卷,向我们提供有关此 Codelab 的反馈。