
Quizás piensas que las estadísticas globales no filtran información sobre los individuos cuyos datos contienen las estadísticas. Sin embargo, existen muchas maneras de las que un atacante pueda saber información sensible sobre los individuos de un conjunto de datos, a partir de una estadística global.
Para proteger la privacidad de las personas, aprenderás a calcular estadísticas privadas a través de agregaciones privadas de manera diferencial de Privacy on Beam. Privacy on Beam es un framework de privacidad diferencial que funciona con Apache Beam.
¿A qué nos referimos con "privado"?
Cuando usamos la palabra "privado" en este codelab, nos referimos a que el resultado se calcula de una manera que no filtra información privada sobre las personas físicas en los datos. Para esto, podemos usar la privacidad diferencial, una noción de privacidad sólida de anonimización. La anonimización es el proceso de agregar datos de varios usuarios para proteger la privacidad. Todos los métodos de anonimización usan la agregación, pero no todos los métodos de agregación logran la anonimización. La privacidad diferencial, por otro lado, ofrece garantías medibles sobre la filtración y privacidad de la información.
Para comprender mejor la privacidad diferencial, veamos un ejemplo sencillo.
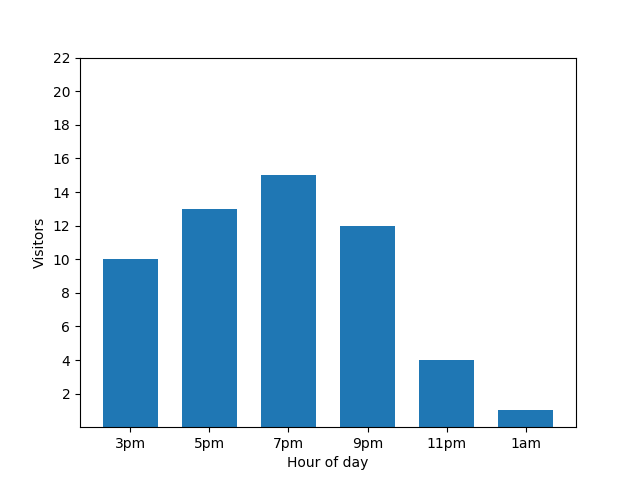
El gráfico de barras muestra la actividad de un restaurante pequeño durante una noche particular. Muchos clientes llegan a las 7 p.m. y el restaurante está completamente vacío a la 1 a.m.:

Esto parece ser útil.
Existe un truco. Cuando llega un nuevo cliente, el gráfico de barras lo revela de inmediato. Observa el gráfico. Está claro que hay un nuevo cliente, que llegó aproximadamente a la 1 a.m.:
Esto no es muy útil desde el punto de vista de la privacidad. Una estadística realmente anónima no debe revelar las contribuciones individuales. Si se une la información de los dos gráficos en uno, esta se vuelve aún más evidente: el gráfico de barras naranja tiene un cliente adicional que llegó aproximadamente a la 1 a.m.:
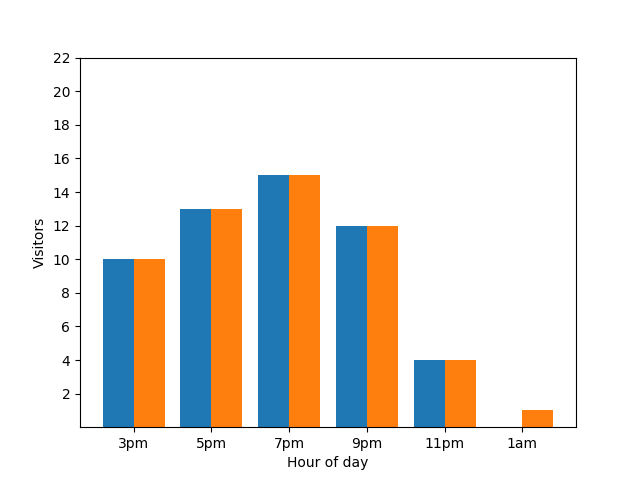
Una vez más, eso no es lo mejor. ¿Qué hacemos?
Agregaremos ruido aleatorio para que los gráficos de barras sean un poco menos precisos.
Observa los dos gráficos de barras que aparecen a continuación. Aunque no son completamente precisos, aún son útiles y no revelan las contribuciones individuales. ¡Genial!

La privacidad diferencial agrega la cantidad correcta de ruido aleatorio para enmascarar las contribuciones individuales.
El análisis estaba bastante simplificado. La implementación de la privacidad diferencial de forma adecuada es más compleja y tiene una serie de sutilezas de implementación inesperadas. Al igual que la criptografía, crear tu propia implementación de la privacidad diferencial puede no ser la mejor idea. Puedes usar Privacy on Beam, en vez de implementar tu propia solución. No implementes tu propia privacidad diferencial.
En este codelab, te mostraremos cómo realizar análisis diferenciales privados mediante Privacy on Beam.
No es necesario descargar Privacy on Beam para poder seguir el codelab porque todo el código relevante y los gráficos se pueden encontrar en este documento. Sin embargo, si desea descargar para jugar con el código, ejecutarlo usted mismo o usar Privacidad en Beam más adelante, no dude en hacerlo siguiendo los pasos a continuación.
Tenga en cuenta que este codelab es para la versión 1.1.0 de la biblioteca.
Primero, descarga Privacy on Beam:
O bien, puedes clonar el repositorio de GitHub:
git clone --branch v1.1.0 https://github.com/google/differential-privacy.git
Privacy on Beam se encuentra en el nivel superior privacy-on-beam/ del directorio.
El código de este codelab y el conjunto de datos está en el directorio privacy-on-beam/codelab/.
Además debes tener instalado Bazel en tu computadora. Ve al sitio web de Bazel para encontrar las instrucciones de instalación para tu sistema operativo.
Supón que eres el propietario de un restaurante y deseas compartir algunas estadísticas sobre el lugar, como revelar los horarios populares. Afortunadamente, sabes de privacidad diferencial y anonimización, por lo que quieres hacerlo de una manera que no se filtre información sobre ningún cliente individual.
El código de este ejemplo está en codelab/count.go.
Comencemos con la carga de un conjunto de datos ficticio que contenga visitas a tu restaurante un lunes en particular. El código para esto no es interesante para los fines de este codelab, pero puedes verlo en codelab/main.go, codelab/utils.go y codelab/visit.go.
ID del visitante | Hora de entrada | Tiempo de estadía (min) | Dinero gastado (EUR) |
1 | 9:30 a.m. | 26 | 24 |
2 | 11:54 a.m. | 53 | 17 |
3 | 1:05 p.m. | 81 | 33 |
Primero, realizarás un gráfico de barras no privado de los horarios de visita a tu restaurante a través de Beam en el siguiente código de muestra. Scope es una representación de la canalización y cada operación nueva que hacemos en los datos se agrega a Scope. CountVisitsPerHour toma un Scope y una colección de visitas, que se representa como una PCollection en Beam. Extrae la hora de cada visita utilizando la función extractVisitHour de la colección. Luego, cuenta los casos de cada hora y los muestra.
func CountVisitsPerHour(s beam.Scope, col beam.PCollection) beam.PCollection {
s = s.Scope("CountVisitsPerHour")
visitHours := beam.ParDo(s, extractVisitHourFn, col)
visitsPerHour := stats.Count(s, visitHours)
return visitsPerHour
}
func extractVisitHourFn(v Visit) int {
return v.TimeEntered.Hour()
}
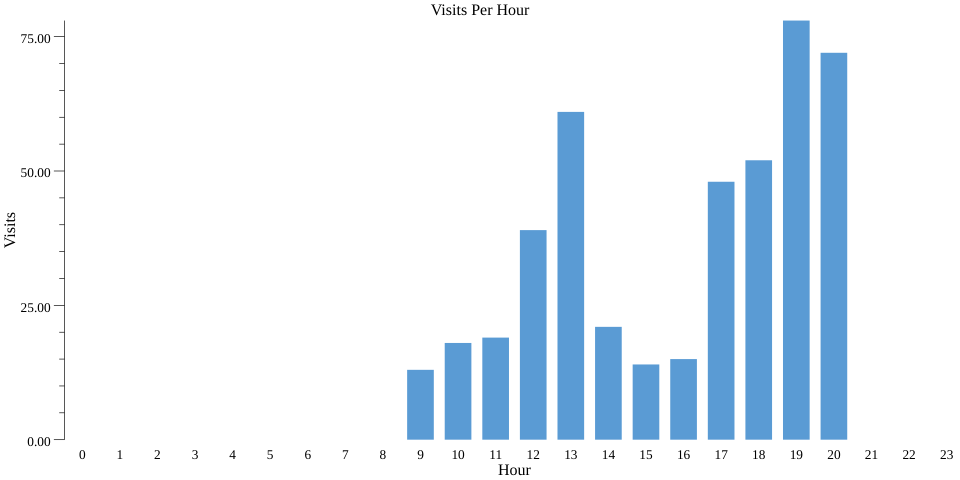
Esto genera un buen gráfico de barras (ejecuta bazel run codelab -- --example="count" --input_file=$(pwd)/day_data.csv --output_stats_file=$(pwd)/count.csv --output_chart_file=$(pwd)/count.png) en el directorio actual como count.png:
El siguiente paso es convertir tu canalización y tu gráfico de barras en uno privado. Lo hacemos de la siguiente manera:
Primero, llama a MakePrivateFromStruct en un PCollection<V> para obtener un PrivatePCollection<V>. El PCollection de entrada debe ser una colección de estructuras. Debemos ingresar un PrivacySpec y un idFieldPath como entrada para MakePrivateFromStruct.
spec := pbeam.NewPrivacySpec(epsilon, delta) pCol := pbeam.MakePrivateFromStruct(s, col, spec, "VisitorID")
PrivacySpec es una estructura que contiene los parámetros de privacidad diferenciales (épsilon y delta), que queremos usar para anonimizar los datos. (No los tengas en cuenta ahora, pero hay una sección opcional más adelante, si deseas obtener más información al respecto).
idFieldPath es la ruta del campo Identificador de usuario dentro de la estructura (Visit en nuestro ejemplo). Aquí, el identificador de usuario de los visitantes es el campo VisitorID de Visit.
A continuación, se llama a pbeam.Count(), en lugar de stats.Count(), pbeam.Count() toma como entrada una estructura CountParams que contiene parámetros, como MaxValue que afectan la exactitud del resultado.
visitsPerHour := pbeam.Count(s, visitHours, pbeam.CountParams{
// Visitors can visit the restaurant once (one hour) a day
MaxPartitionsContributed: 1,
// Visitors can visit the restaurant once within an hour
MaxValue: 1,
})
De manera similar, MaxPartitionsContributed limita la cantidad de horas de visita que un usuario puede contribuir. Esperamos que visiten el restaurante, al menos, una vez al día, pero no importa si lo visitan varias veces el mismo día, así que establecemos el valor en 1. Explicaremos estos parámetros con más detalle en una sección opcional.
MaxValue limita la cantidad de veces que un único usuario puede contribuir a los valores que registramos. En este caso particular, los valores que estamos registrando son los horarios de visita y esperamos que un usuario visite el restaurante solo una vez, aunque no importa si lo visitan varias veces el mismo día, así que establecemos este parámetro en 1.
Al finalizar, tu código se verá de la siguiente manera:
func PrivateCountVisitsPerHour(s beam.Scope, col beam.PCollection) beam.PCollection {
s = s.Scope("PrivateCountVisitsPerHour")
// Create a Privacy Spec and convert col into a PrivatePCollection
spec := pbeam.NewPrivacySpec(epsilon, delta)
pCol := pbeam.MakePrivateFromStruct(s, col, spec, "VisitorID")
visitHours := pbeam.ParDo(s, extractVisitHourFn, pCol)
visitsPerHour := pbeam.Count(s, visitHours, pbeam.CountParams{
// Visitors can visit the restaurant once (one hour) a day
MaxPartitionsContributed: 1,
// Visitors can visit the restaurant once within an hour
MaxValue: 1,
})
return visitsPerHour
}
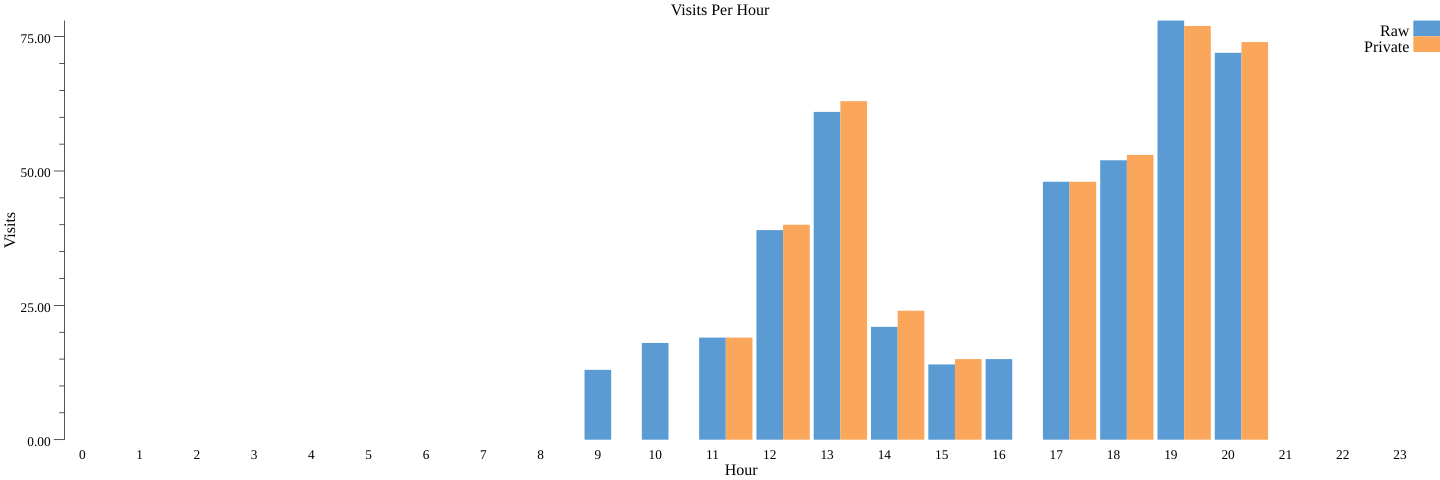
Vemos un gráfico de barras similar (count_dp.png) para la estadística privada de forma diferencial (el comando anterior ejecuta las canalizaciones no privadas y privadas):
Felicitaciones. Calculaste tu primera estadística privada diferencial.
El gráfico de barras que obtienes cuando ejecutas el código puede ser diferente de este. Está bien. Obtendrás un gráfico de barras diferente cada vez que ejecutes el código, debido al ruido en la privacidad diferencial, pero puedes ver que son más o menos similares al gráfico original de barras no privadas.
Recuerda que es muy importante que las garantías de privacidad no vuelvan a ejecutarse en la canalización varias veces (por ejemplo, para obtener un gráfico de barras que se vea mejor). El motivo por el cual no debes volver a ejecutar tus canalizaciones se explica en la sección "Calcula varias estadísticas".
En la sección anterior, es posible que hayas notado que descartamos todas las visitas (datos) de algunas particiones, es decir, horas.
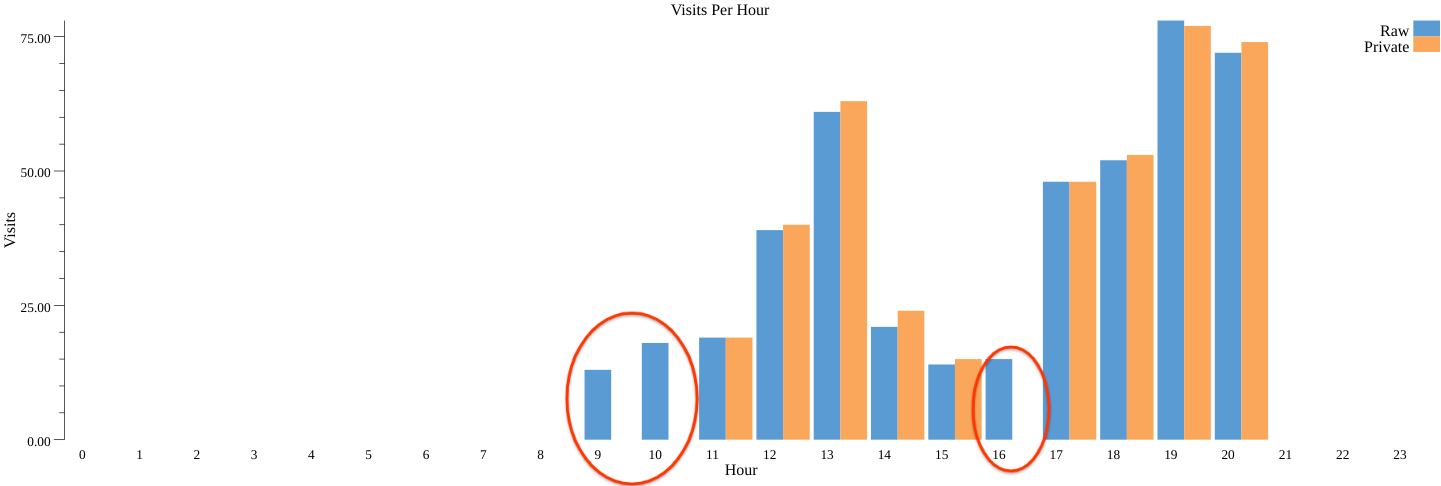
Esto se debe a la selección o al umbral de particiones, un paso importante para asegurar las garantías de privacidad diferenciales cuando el resultado de particiones depende solamente de los datos de usuario. Cuando este sea el caso, la existencia de una partición en el resultado puede filtrar la existencia de un usuario individual en los datos (para obtener una explicación sobre por qué esto infringe la privacidad, consulta esta entrada de blog. Para evitar esto, Privacy on Beam solo conserva las particiones que tengan una cantidad suficiente de usuarios.
Cuando la lista de particiones de salida no depende de datos privados del usuario, es decir, información pública, no necesitamos este paso de selección de particiones. Este es el caso de nuestro ejemplo del restaurante: conocemos el horario laboral (de 9:00 a.m. a 9:00 p.m.).
El código para este ejemplo está en codelab/public_partitions.go.
Solo crearemos una PCollection de horas entre las 9:00 a.m. y las 9:00 p.m. (exclusivamente) y la ingresaremos en el campo PublicPartitions de CountParams:
func PrivateCountVisitsPerHourWithPublicPartitions(s beam.Scope,
col beam.PCollection) beam.PCollection {
s = s.Scope("PrivateCountVisitsPerHourWithPublicPartitions")
// Create a Privacy Spec and convert col into a PrivatePCollection
spec := pbeam.NewPrivacySpec(epsilon, /* delta */ 0)
pCol := pbeam.MakePrivateFromStruct(s, col, spec, "VisitorID")
// Create a PCollection of output partitions, i.e. restaurant's work hours
// (from 9 am till 9pm (exclusive)).
hours := beam.CreateList(s, [12]int{9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20})
visitHours := pbeam.ParDo(s, extractVisitHourFn, pCol)
visitsPerHour := pbeam.Count(s, visitHours, pbeam.CountParams{
// Visitors can visit the restaurant once (one hour) a day
MaxPartitionsContributed: 1,
// Visitors can visit the restaurant once within an hour
MaxValue: 1,
// Visitors only visit during work hours
PublicPartitions: hours,
})
return visitsPerHour
}
Recuerda que es posible configurar delta en 0, si usas particiones públicas y Laplace Noise (predeterminado), como en el caso anterior.
Cuando ejecutamos la canalización con particiones públicas (con bazel run codelab -- --example="public_partitions" --input_file=$(pwd)/day_data.csv --output_stats_file=$(pwd)/public_partitions.csv --output_chart_file=$(pwd)/public_partitions.png), obtenemos lo siguiente (public_partitions_dp.png):
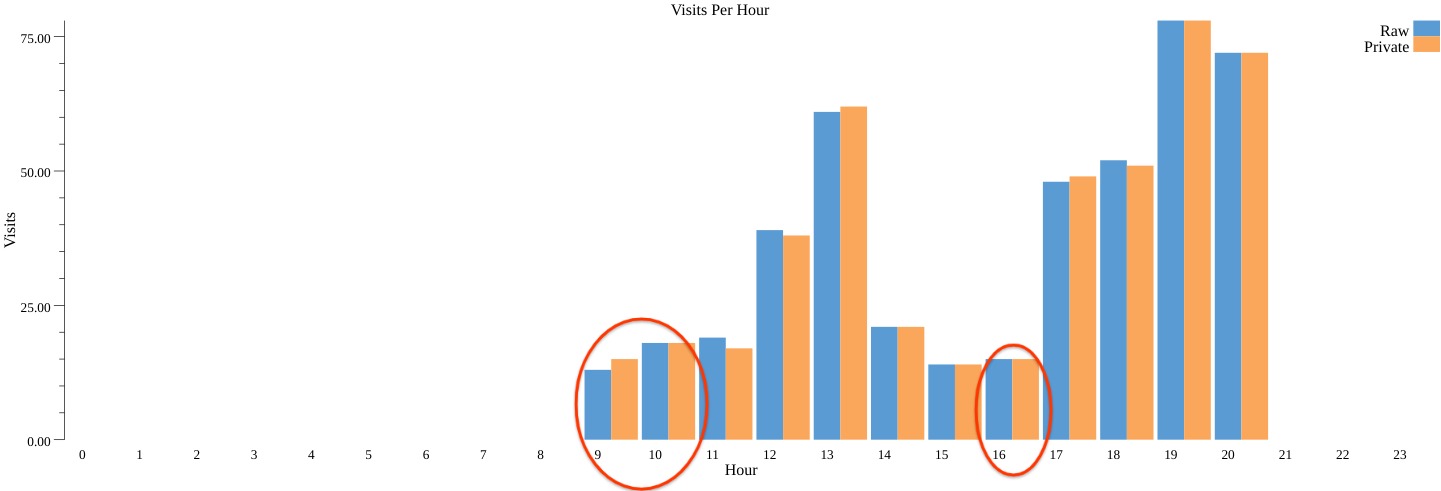
Como puedes ver, esta vez conservamos las particiones 9, 10 y 16 que descartamos antes sin particiones públicas.
El uso de particiones públicas no solo permite conservar más particiones, sino que también agrega aproximadamente la mitad del ruido a cada una. Esto es más de lo que se agregaría si no utilizaras particiones públicas, por no establecer un valor límite al presupuesto de privacidad, como épsilon y delta en la selección de particiones. Por este motivo, la diferencia entre los conteos sin procesar y privados es un poco menor en comparación con la ejecución anterior.
Hay dos aspectos importantes que debes tener en cuenta cuando usas particiones públicas:
- Ten cuidado cuando derives la lista de particiones a partir de datos sin procesar: si no lo haces de forma diferencial. Por ejemplo, solo leer la lista de todas las particiones en los datos del usuario, tu canalización ya no proporcionará garantías de privacidad diferenciales. Consulta la siguiente sección avanzada sobre cómo hacer esto de manera diferencial privada.
- Si no hay datos (p.ej., visitas) para algunas de las particiones públicas, el ruido se aplicará a esas particiones para preservar la privacidad diferencial. Por ejemplo, si usamos horas entre las 12:00 p.m. y las 12:00 a.m. (en lugar de las 9:00 a.m. y las 9:00 p.m.), se aplicaría ruido en todas las horas y se mostrarían visitas cuando no hay.
Cómo derivar particiones de los datos (avanzado)
Si estás ejecutando varias agregaciones con la misma lista de particiones de salida no públicas en la misma canalización, puedes derivar la lista de particiones una sola vez, utilizando SelectPartitions() y asignando las particiones para cada agregación como la entrada PublicPartition. Esto es seguro desde el punto de vista de la privacidad, sino que también permite agregar menos ruido, debido al uso del presupuesto de privacidad en la selección de particiones solo una vez para toda la canalización.
Ahora que ya sabemos cómo contar los elementos de manera diferencial privada, veamos cómo calcular valores promedio. Más concretamente, ahora calcularemos la duración promedio de la estadía de los visitantes.
El código de este ejemplo está en codelab/mean.go.
Por lo general, para calcular una media no privada de duración de estadías, usamos stats.MeanPerKey() con un paso de procesamiento previo que convierte el PCollection entrante de visitas en un PCollection<K,V>, donde K es el horario de visita y V. es el tiempo que el visitante pasa en el restaurante.
func MeanTimeSpent(s beam.Scope, col beam.PCollection) beam.PCollection {
s = s.Scope("MeanTimeSpent")
hourToTimeSpent := beam.ParDo(s, extractVisitHourAndTimeSpentFn, col)
meanTimeSpent := stats.MeanPerKey(s, hourToTimeSpent)
return meanTimeSpent
}
func extractVisitHourAndTimeSpentFn(v Visit) (int, int) {
return v.TimeEntered.Hour(), v.MinutesSpent
}
Esto genera un buen gráfico de barras (ejecuta bazel run codelab -- --example="mean" --input_file=$(pwd)/day_data.csv --output_stats_file=$(pwd)/mean.csv --output_chart_file=$(pwd)/mean.png) en el directorio actual como mean.png:
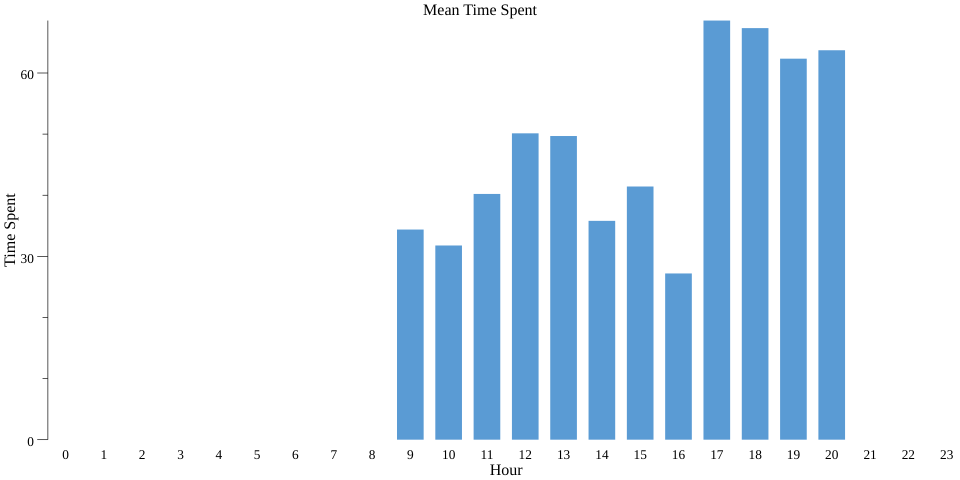
Para hacer que este elemento sea privado de forma diferencial, volvemos a convertir nuestra PCollection en PrivatePCollection y reemplazamos stats.MeanPerKey() por pbeam.MeanPerKey(). De manera similar que Count, tenemos MeanParams que contiene algunos parámetros, como MinValue y MaxValue, que afectan la exactitud. MinValue y MaxValue representan los límites que tengamos para cada contribución de usuario por clave.
meanTimeSpent := pbeam.MeanPerKey(s, hourToTimeSpent, pbeam.MeanParams{
// Visitors can visit the restaurant once (one hour) a day
MaxPartitionsContributed: 1,
// Visitors can visit the restaurant once within an hour
MaxContributionsPerPartition: 1,
// Minimum time spent per user (in mins)
MinValue: 0,
// Maximum time spent per user (in mins)
MaxValue: 60,
})
En este ejemplo, cada clave representa una hora, y los valores son los tiempos que los visitantes pasaron. Establecemos MinValue en 0 porque se espera que los visitantes pasen más de 0 minutos en el restaurante. Establecemos MaxValue en 60, lo que significa que si un visitante sobrepasa este valor, tomamos como que este usuario estuvo 60 minutos.
Al finalizar, tu código se verá de la siguiente manera:
func PrivateMeanTimeSpent(s beam.Scope, col beam.PCollection) beam.PCollection {
s = s.Scope("PrivateMeanTimeSpent")
// Create a Privacy Spec and convert col into a PrivatePCollection
spec := pbeam.NewPrivacySpec(epsilon, /* delta */ 0)
pCol := pbeam.MakePrivateFromStruct(s, col, spec, "VisitorID")
// Create a PCollection of output partitions, i.e. restaurant's work hours
// (from 9 am till 9pm (exclusive)).
hours := beam.CreateList(s, [12]int{9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20})
hourToTimeSpent := pbeam.ParDo(s, extractVisitHourAndTimeSpentFn, pCol)
meanTimeSpent := pbeam.MeanPerKey(s, hourToTimeSpent, pbeam.MeanParams{
// Visitors can visit the restaurant once (one hour) a day
MaxPartitionsContributed: 1,
// Visitors can visit the restaurant once within an hour
MaxContributionsPerPartition: 1,
// Minimum time spent per user (in mins)
MinValue: 0,
// Maximum time spent per user (in mins)
MaxValue: 60,
// Visitors only visit during work hours
PublicPartitions: hours,
})
return meanTimeSpent
}
Vemos un gráfico de barras similar (mean_dp.png) para la estadística privada diferencial (el comando anterior ejecuta las canalizaciones no privadas y privadas):
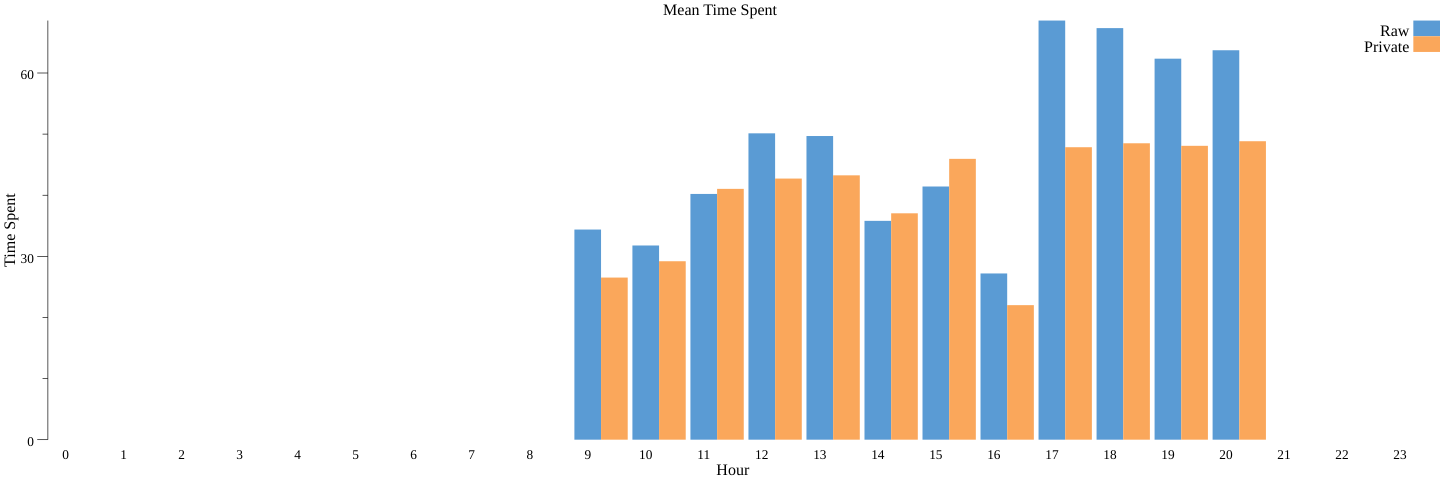
De nuevo, de manera similar al conteo y debido a que esta es una operación privada diferencial, obtendremos resultados distintos cada vez que la ejecutamos. Sin embargo, puedes ver que la duración de la estadía privada diferencial es muy similar al resultado verdadero.
Otra estadística interesante para ver son los ingresos por hora durante el transcurso del día.
El código de este ejemplo está en codelab/sum.go.
Una vez más, comenzaremos con la versión no privada. Con un procesamiento previo en nuestro conjunto de datos ficticio, podemos crear una PCollection<K,V>, donde K sea la hora de visita y V es el dinero que el visitante invirtió en el restaurante. Para calcular un ingreso no privado por hora, simplemente podemos sumar la cantidad total de dinero que gastaron los visitantes llamando a stats.SumPerKey():
func RevenuePerHour(s beam.Scope, col beam.PCollection) beam.PCollection {
s = s.Scope("RevenuePerHour")
hourToMoneySpent := beam.ParDo(s, extractVisitHourAndMoneySpentFn, col)
revenues := stats.SumPerKey(s, hourToMoneySpent)
return revenues
}
func extractVisitHourAndMoneySpentFn(v Visit) (int, int) {
return v.TimeEntered.Hour(), v.MoneySpent
}
Esto genera un buen gráfico de barras (ejecuta bazel run codelab -- --example="sum" --input_file=$(pwd)/day_data.csv --output_stats_file=$(pwd)/sum.csv --output_chart_file=$(pwd)/sum.png) en el directorio actual como sum.png:
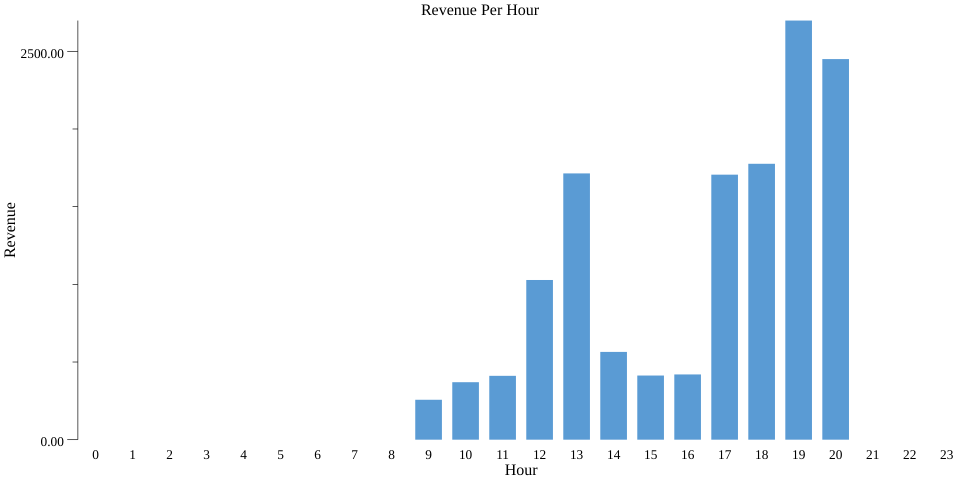
Para hacer que este elemento sea privado de forma diferencial, volvemos a convertir nuestra PCollection en PrivatePCollection y reemplazamos stats.SumPerKey() por pbeam.SumPerKey(). De manera similar que Count y MeanPerKey, tenemos SumParams que contiene algunos parámetros, como MinValue y MaxValue, que afectan la exactitud.
revenues := pbeam.SumPerKey(s, hourToMoneySpent, pbeam.SumParams{
// Visitors can visit the restaurant once (one hour) a day
MaxPartitionsContributed: 1,
// Minimum money spent per user (in euros)
MinValue: 0,
// Maximum money spent per user (in euros)
MaxValue: 40,
})
En este caso, MinValue y MaxValue representan los límites que tenemos para el dinero que gasta cada visitante. Establecemos MinValue en 0 porque se espera que los visitantes gasten más de 0 euros en el restaurante. Establecemos MaxValue en 40, lo que significa que si un visitante gasta más de 40 euros, tomamos como el usuario gastó 40 euros.
Al finalizar, tu código se verá de la siguiente manera:
func PrivateRevenuePerHour(s beam.Scope, col beam.PCollection) beam.PCollection {
s = s.Scope("PrivateRevenuePerHour")
// Create a Privacy Spec and convert col into a PrivatePCollection
spec := pbeam.NewPrivacySpec(epsilon, /* delta */ 0)
pCol := pbeam.MakePrivateFromStruct(s, col, spec, "VisitorID")
// Create a PCollection of output partitions, i.e. restaurant's work hours
// (from 9 am till 9pm (exclusive)).
hours := beam.CreateList(s, [12]int{9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20})
hourToMoneySpent := pbeam.ParDo(s, extractVisitHourAndMoneySpentFn, pCol)
revenues := pbeam.SumPerKey(s, hourToMoneySpent, pbeam.SumParams{
// Visitors can visit the restaurant once (one hour) a day
MaxPartitionsContributed: 1,
// Minimum money spent per user (in euros)
MinValue: 0,
// Maximum money spent per user (in euros)
MaxValue: 40,
// Visitors only visit during work hours
PublicPartitions: hours,
})
return revenues
}
Vemos un gráfico de barras similar (sum_dp.png) para la estadística privada diferencial (el comando anterior ejecuta las canalizaciones no privadas y privadas):
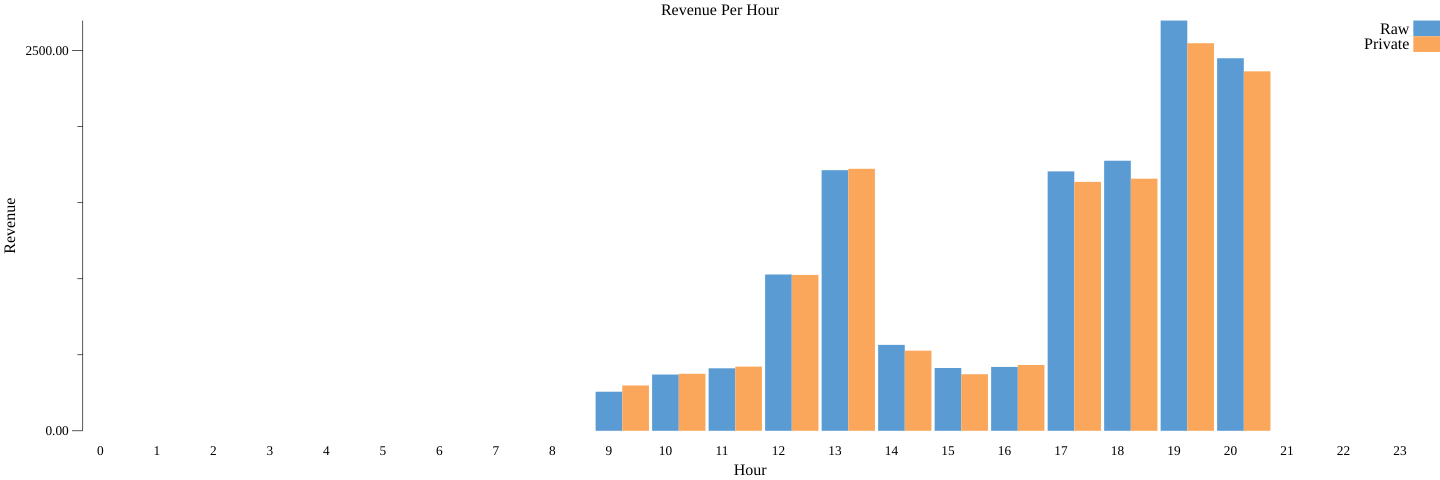
De nuevo, de manera similar al conteo y la media, ya que esta es una operación privada diferencial, obtenemos resultados distintos cada vez que la ejecutamos. Sin embargo, puedes ver que el resultado privado diferencial es muy similar a los ingresos reales por hora.
La mayoría de las veces, es posible que te interese calcular varias estadísticas de los mismos datos subyacentes, algo similar a lo que hiciste con el conteo, la media y la suma. Por lo general, es más prolijo y sencillo de hacer esto en una sola canalización de Beam y en un único objeto binario. Puedes hacer esto con Privacy on Beam también. Puedes escribir una sola canalización para ejecutar tus transformaciones y cálculos, y usar una sola prueba PrivacySpec para toda la canalización.
Es más conveniente y mejor en términos de privacidad hacer esto con un único PrivacySpec. Si recuerdas los parámetros de épsilon y delta que proporcionamos a las pruebas PrivacySpec. Estos representan un elemento que se denomina presupuesto de privacidad, que mide qué parte de la privacidad de los usuarios incluye los datos subyacentes que se están filtrando.
Recuerda que el presupuesto de privacidad es una suma: si ejecutas una canalización con un épsilon ε o delta δ en particular una sola vez, gastarás un presupuesto de privacidad (ε,δ). Si la ejecutas por segunda vez, habrás usado un presupuesto total de (2ε, 2δ). Del mismo modo, si calculas varias estadísticas con un PrivacySpec (y luego un presupuesto de privacidad ) de (ε,δ), habrás usado un presupuesto total de (2ε, 2δ). Esto significa que está degradando las garantías de privacidad.
Para evitar esto, cuando deseas calcular varias estadísticas sobre los mismos datos subyacentes, debes usar un único PrivacySpec con el presupuesto total. Luego, deberás especificar el épsilon y el delta que deseas usar para cada agregación. Al finalizar, recibirás la misma garantía general de privacidad, pero cuanto más alto sea el épsilon y delta de una agregación en particular, mayor será la exactitud que tendrá.
Para ver cómo funciona, podemos calcular las tres estadísticas (conteo, media y suma) que calculamos por separado antes en una sola canalización.
El código de este ejemplo está en codelab/multiple.go. Observa cómo dividimos el presupuesto total (ε,δ) entre las tres agregaciones:
func ComputeCountMeanSum(s beam.Scope, col beam.PCollection) (visitsPerHour, meanTimeSpent, revenues beam.PCollection) {
s = s.Scope("ComputeCountMeanSum")
// Create a Privacy Spec and convert col into a PrivatePCollection
// Budget is shared by count, mean and sum.
spec := pbeam.NewPrivacySpec(epsilon, /* delta */ 0)
pCol := pbeam.MakePrivateFromStruct(s, col, spec, "VisitorID")
// Create a PCollection of output partitions, i.e. restaurant's work hours
// (from 9 am till 9pm (exclusive)).
hours := beam.CreateList(s, [12]int{9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20})
visitHours := pbeam.ParDo(s, extractVisitHourFn, pCol)
visitsPerHour = pbeam.Count(s, visitHours, pbeam.CountParams{
// Visitors can visit the restaurant once (one hour) a day
MaxPartitionsContributed: 1,
// Visitors can visit the restaurant once within an hour
MaxValue: 1,
// Visitors only visit during work hours
PublicPartitions: hours,
})
hourToTimeSpent := pbeam.ParDo(s, extractVisitHourAndTimeSpentFn, pCol)
meanTimeSpent = pbeam.MeanPerKey(s, hourToTimeSpent, pbeam.MeanParams{
// Visitors can visit the restaurant once (one hour) a day
MaxPartitionsContributed: 1,
// Visitors can visit the restaurant once within an hour
MaxContributionsPerPartition: 1,
// Minimum time spent per user (in mins)
MinValue: 0,
// Maximum time spent per user (in mins)
MaxValue: 60,
// Visitors only visit during work hours
PublicPartitions: hours,
})
hourToMoneySpent := pbeam.ParDo(s, extractVisitHourAndMoneySpentFn, pCol)
revenues = pbeam.SumPerKey(s, hourToMoneySpent, pbeam.SumParams{
// Visitors can visit the restaurant once (one hour) a day
MaxPartitionsContributed: 1,
// Minimum money spent per user (in euros)
MinValue: 0,
// Maximum money spent per user (in euros)
MaxValue: 40,
// Visitors only visit during work hours
PublicPartitions: hours,
})
return visitsPerHour, meanTimeSpent, revenues
}
Has visto algunos parámetros mencionados en este codelab: épsilon, delta, maxPartitionsContributed, etc. Podemos dividirlos en dos categorías: Parámetros de privacidad y parámetros de utilidad.
Parámetros de privacidad
Épsilon y delta son los parámetros que cuantifican la privacidad que ofrecemos mediante la privacidad diferencial. Más precisamente, épsilon y delta son una medida de cuánta información podría obtener un atacante potencial sobre los datos subyacentes al observar el resultado anónimo. Cuanto mayor sea el épsilon y el delta, más información obtendrán los atacantes sobre los datos subyacentes, poniendo en riesgo la privacidad.
Por otro lado, mientras más bajos el épsilon y el delta, debes agregar más ruidos a la salida para que los resultados sean anónimos. Además, debes tener mayor cantidad de usuarios únicos en cada partición para mantener esa partición del resultado anónimo. Aquí se debe decidir qué priorizar, si utilidad o privacidad.
En Privacy on Beam, debes preocuparte por las garantías de privacidad que deseas en la salida anónima cuando establezcas el presupuesto de privacidad total en PrivacySpec. Recuerda que si deseas que tus garantías de privacidad sean las mismas, debes seguir las sugerencias de este codelab sobre cómo usar de manera adecuada tu presupuesto, utilizando un PrivacySpec separado para cada agregación o evitar ejecutar la canalización varias veces.
Para obtener más información sobre la privacidad diferencial y el significado de los parámetros de privacidad, consulta la literatura.
Parámetros de utilidad
Estos son parámetros no afectarán las garantías de privacidad (siempre y cuando sigas los consejos de cómo utilizar Privacy on Beam de manera adecuada), pero sí pueden afectar la exactitud y, por ende, la utilidad del resultado. Se ubican en las estructuras Params de cada agregación, p.ej., CountParams, SumParams, etc. Estos parámetros se usan para escalar el ruido que se agrega.
Un parámetro de utilidad que se muestra en Params y que se aplica a todas las agregaciones es MaxPartitionsContributed. Una partición corresponde a una clave de la PCollection que genera una operación de agregación en Privacy on Beam, p.ej., Count, SumPerKey, etc. Por lo tanto, MaxPartitionsContributed limita la cantidad de valores clave que un usuario puede contribuir al resultado. Si un usuario contribuye a más de MaxPartitionsContributed claves en los datos subyacentes, se descartarán algunas de sus contribuciones a fin de que sean exactamente MaxPartitionsContributed claves.
De manera similar a MaxPartitionsContributed, la mayoría de las agregaciones tienen un parámetro MaxContributionsPerPartition. Se proporcionan en las estructuras Params y cada agregación podría tener valores distintos. A diferencia de MaxPartitionsContributed, MaxContributionsPerPartition limita la contribución de un usuario para cada clave. En otras palabras, un usuario solo puede contribuir con valores MaxContributionsPerPartition para cada clave.
El ruido que se agrega al resultado se escala en MaxPartitionsContributed y MaxContributionsPerPartition, por lo que hay una desventaja aquí: Mientras más sean las MaxPartitionsContributed y MaxContributionsPerPartition, ambas significan que retienes más datos, pero también obtendrás resultados con más ruidos.
Algunas agregaciones requieren MinValue y MaxValue. Estos establecen los límites para las contribuciones de cada usuario. Si un usuario aporta un valor inferior a MinValue, ese valor se aumentará para que sea equivalente a MinValue. De manera similar, si un usuario aporta un valor mayor que MaxValue, el valor se reducirá para que sea equivalente a MaxValue. Esto significa que, para mantener más valores originales, debe establecer límites más grandes. De manera similar que en MaxPartitionsContributed y MaxContributionsPerPartition, el ruido se escala según el tamaño de los límites, por ende los límites más altos implican que se conservarán más datos, pero obtendrás un resultado con más ruidos.
El último parámetro es NoiseKind. Admitimos dos mecanismos de ruido diferentes en Privacy On Beam: GaussianNoise y LaplaceNoise. Ambos tienen sus ventajas y desventajas, pero la distribución de Laplace ofrece una mejor utilidad con límites de contribución bajos, por lo que Privacy On Beam la usa de forma predeterminada. Sin embargo, si deseas usar un ruido de distribución de Gauss, puedes aplicar Params con una variable pbeam.GaussianNoise{}.
¡Estupendo! Completaste el codelab sobre Privacy on Beam. Haz aprendido mucho sobre la privacidad diferencial y Privacy on Beam:
- Cómo convertir tu
PCollectionen unPrivatePCollectionllamando unMakePrivateFromStruct - Cómo utilizar
Countpara calcular conteos privados - Cómo utilizar
MeanPerKeypara calcular medios de privacidad distintos - Cómo utilizar
SumPerKeypara calcular sumas privadas diferenciales - Cómo calcular varias estadísticas con un solo
PrivacySpecen una única canalización - (Opcional) Cómo personalizar los parámetros de
PrivacySpecy de agregación (CountParams, MeanParams, SumParams)
Sin embargo, hay muchas más agregaciones (por ejemplo, cuantiles, contando valores distintos) que puedes hacer con Privacy on Beam. Obtén más información sobre esto en el repositorio de GitHub o en godoc.
Si tienes tiempo, completa una encuesta para enviarnos tus comentarios sobre el codelab.