Streaming melibatkan penerimaan respons terhadap perintah saat dihasilkan. Artinya, segera setelah model menghasilkan token output, token output akan dikirim.
Anda dapat membuat permintaan streaming ke Large Language Model (LLM) (model bahasa besar) Vertex AI menggunakan hal berikut:
- REST API Vertex AI dengan peristiwa yang dikirim server (SSE)
- REST API Vertex AI
- Vertex AI SDK untuk Python
- Library klien
API streaming dan non-streaming menggunakan parameter yang sama, serta tidak ada perbedaan harga dan kuota.
Vertex AI Studio
Anda dapat menggunakan Vertex AI Studio untuk mendesain dan menjalankan perintah serta menerima respons yang di-streaming. Dari halaman desain perintah, klik tombol Streaming Response untuk mengaktifkan streaming.
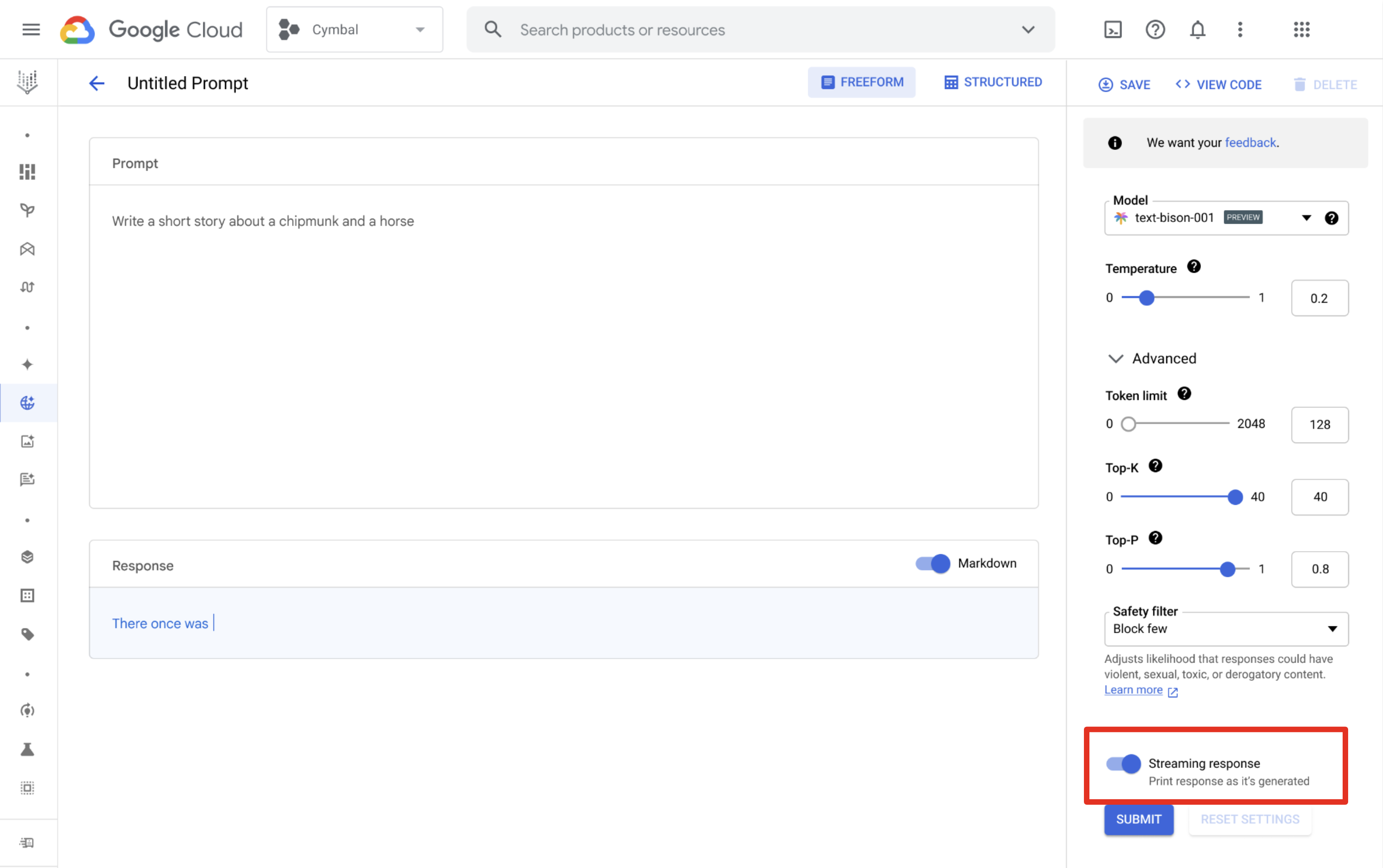
Bahasa yang didukung
| Kode bahasa | Bahasa |
|---|---|
en |
Inggris |
es |
Spanyol |
pt |
Portugis |
fr |
Prancis |
it |
Italia |
de |
Jerman |
ja |
Jepang |
ko |
Korea |
hi |
Hindi |
zh |
China |
id |
Indonesia |
Contoh
Anda dapat memanggil Streaming API menggunakan salah satu dari hal berikut:
REST API dengan peristiwa yang dikirim server (SSE)
Parameternya berbeda di seluruh jenis model yang digunakan dalam contoh berikut:
Teks
Model yang didukung saat ini adalah text-bison dan text-unicorn. Lihat versi yang tersedia.
Minta
PROJECT_ID=YOUR_PROJECT_ID
PROMPT="PROMPT"
MODEL_ID=text-bison
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/us-central1/publishers/google/models/${MODEL_ID}:serverStreamingPredict?alt=sse -d \
'{
"inputs": [
{
"struct_val": {
"prompt": {
"string_val": [ "'"${PROMPT}"'" ]
}
}
}
],
"parameters": {
"struct_val": {
"temperature": { "float_val": 0.8 },
"maxOutputTokens": { "int_val": 1024 },
"topK": { "int_val": 40 },
"topP": { "float_val": 0.95 }
}
}
}'
Respons
Respons adalah pesan peristiwa yang dikirim server.
data: {"outputs": [{"structVal": {"content": {"stringVal": [RESPONSE]},"safetyAttributes": {"structVal": {"blocked": {"boolVal": [BOOLEAN]},"categories": {"listVal": [{"stringVal": [Safety category name]}]},"scores": {"listVal": [{"doubleVal": [Safety category score]}]}}},"citationMetadata": {"structVal": {"citations": {}}}}}]}
Chat
Model yang didukung saat ini adalah chat-bison. Lihat versi yang tersedia.
Minta
PROJECT_ID=YOUR_PROJECT_ID
PROMPT="PROMPT"
AUTHOR="USER"
MODEL_ID=chat-bison
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/us-central1/publishers/google/models/${MODEL_ID}:serverStreamingPredict?alt=sse -d \
$'{
"inputs": [
{
"struct_val": {
"messages": {
"list_val": [
{
"struct_val": {
"content": {
"string_val": [ "'"${PROMPT}"'" ]
},
"author": {
"string_val": [ "'"${AUTHOR}"'"]
}
}
}
]
}
}
}
],
"parameters": {
"struct_val": {
"temperature": { "float_val": 0.5 },
"maxOutputTokens": { "int_val": 1024 },
"topK": { "int_val": 40 },
"topP": { "float_val": 0.95 }
}
}
}'
Respons
Respons adalah pesan peristiwa yang dikirim server.
data: {"outputs": [{"structVal": {"candidates": {"listVal": [{"structVal": {"author": {"stringVal": [AUTHOR]},"content": {"stringVal": [RESPONSE]}}}]},"citationMetadata": {"listVal": [{"structVal": {"citations": {}}}]},"safetyAttributes": {"structVal": {"blocked": {"boolVal": [BOOLEAN]},"categories": {"listVal": [{"stringVal": [Safety category name]}]},"scores": {"listVal": [{"doubleVal": [Safety category score]}]}}}}}]}
Kode
Model yang didukung saat ini adalah code-bison. Lihat versi yang tersedia.
Minta
PROJECT_ID=YOUR_PROJECT_ID
PROMPT="PROMPT"
MODEL_ID=code-bison
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/us-central1/publishers/google/models/${MODEL_ID}:serverStreamingPredict?alt=sse -d \
$'{
"inputs": [
{
"struct_val": {
"prefix": {
"string_val": [ "'"${PROMPT}"'" ]
}
}
}
],
"parameters": {
"struct_val": {
"temperature": { "float_val": 0.8 },
"maxOutputTokens": { "int_val": 1024 },
"topK": { "int_val": 40 },
"topP": { "float_val": 0.95 }
}
}
}'
Respons
Respons adalah pesan peristiwa yang dikirim server.
data: {"outputs": [{"structVal": {"citationMetadata": {"structVal": {"citations": {}}},"safetyAttributes": {"structVal": {"blocked": {"boolVal": [BOOLEAN]},"categories": {"listVal": [{"stringVal": [Safety category name]}]},"scores": {"listVal": [{"doubleVal": [Safety category score]}]}}},"content": {"stringVal": [RESPONSE]}}}]}
Chat kode
Model yang didukung saat ini adalah codechat-bison. Lihat versi yang tersedia.
Minta
PROJECT_ID=YOUR_PROJECT_ID
PROMPT="PROMPT"
AUTHOR="USER"
MODEL_ID=codechat-bison
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/us-central1/publishers/google/models/${MODEL_ID}:serverStreamingPredict?alt=sse -d \
$'{
"inputs": [
{
"struct_val": {
"messages": {
"list_val": [
{
"struct_val": {
"content": {
"string_val": [ "'"${PROMPT}"'" ]
},
"author": {
"string_val": [ "'"${AUTHOR}"'"]
}
}
}
]
}
}
}
],
"parameters": {
"struct_val": {
"temperature": { "float_val": 0.5 },
"maxOutputTokens": { "int_val": 1024 },
"topK": { "int_val": 40 },
"topP": { "float_val": 0.95 }
}
}
}'
Respons
Respons adalah pesan peristiwa yang dikirim server.
data: {"outputs": [{"structVal": {"safetyAttributes": {"structVal": {"blocked": {"boolVal": [BOOLEAN]},"categories": {"listVal": [{"stringVal": [Safety category name]}]},"scores": {"listVal": [{"doubleVal": [Safety category score]}]}}},"citationMetadata": {"listVal": [{"structVal": {"citations": {}}}]},"candidates": {"listVal": [{"structVal": {"content": {"stringVal": [RESPONSE]},"author": {"stringVal": [AUTHOR]}}}]}}}]}
REST API
Parameternya berbeda di seluruh jenis model yang digunakan dalam contoh berikut:
Teks
Model yang didukung saat ini adalah text-bison dan text-unicorn. Lihat versi yang tersedia.
Minta
PROJECT_ID=YOUR_PROJECT_ID
PROMPT="PROMPT"
MODEL_ID=text-bison
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/us-central1/publishers/google/models/${MODEL_ID}:serverStreamingPredict -d \
'{
"inputs": [
{
"struct_val": {
"prompt": {
"string_val": [ "'"${PROMPT}"'" ]
}
}
}
],
"parameters": {
"struct_val": {
"temperature": { "float_val": 0.8 },
"maxOutputTokens": { "int_val": 1024 },
"topK": { "int_val": 40 },
"topP": { "float_val": 0.95 }
}
}
}'
Respons
{
"outputs": [
{
"structVal": {
"citationMetadata": {
"structVal": {
"citations": {}
}
},
"safetyAttributes": {
"structVal": {
"categories": {},
"scores": {},
"blocked": {
"boolVal": [
false
]
}
}
},
"content": {
"stringVal": [
RESPONSE
]
}
}
}
]
}
Chat
Model yang didukung saat ini adalah chat-bison. Lihat versi yang tersedia.
Minta
PROJECT_ID=YOUR_PROJECT_ID
PROMPT="PROMPT"
AUTHOR="USER"
MODEL_ID=chat-bison
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/us-central1/publishers/google/models/${MODEL_ID}:serverStreamingPredict -d \
$'{
"inputs": [
{
"struct_val": {
"messages": {
"list_val": [
{
"struct_val": {
"content": {
"string_val": [ "'"${PROMPT}"'" ]
},
"author": {
"string_val": [ "'"${AUTHOR}"'"]
}
}
}
]
}
}
}
],
"parameters": {
"struct_val": {
"temperature": { "float_val": 0.5 },
"maxOutputTokens": { "int_val": 1024 },
"topK": { "int_val": 40 },
"topP": { "float_val": 0.95 }
}
}
}'
Respons
{
"outputs": [
{
"structVal": {
"candidates": {
"listVal": [
{
"structVal": {
"content": {
"stringVal": [
RESPONSE
]
},
"author": {
"stringVal": [
AUTHOR
]
}
}
}
]
},
"citationMetadata": {
"listVal": [
{
"structVal": {
"citations": {}
}
}
]
},
"safetyAttributes": {
"listVal": [
{
"structVal": {
"categories": {},
"blocked": {
"boolVal": [
false
]
},
"scores": {}
}
}
]
}
}
}
]
}
Kode
Model yang didukung saat ini adalah code-bison. Lihat versi yang tersedia.
Minta
PROJECT_ID=YOUR_PROJECT_ID
PROMPT="PROMPT"
MODEL_ID=code-bison
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/us-central1/publishers/google/models/${MODEL_ID}:serverStreamingPredict -d \
$'{
"inputs": [
{
"struct_val": {
"prefix": {
"string_val": [ "'"${PROMPT}"'" ]
}
}
}
],
"parameters": {
"struct_val": {
"temperature": { "float_val": 0.8 },
"maxOutputTokens": { "int_val": 1024 },
"topK": { "int_val": 40 },
"topP": { "float_val": 0.95 }
}
}
}'
Respons
{
"outputs": [
{
"structVal": {
"safetyAttributes": {
"structVal": {
"categories": {},
"scores": {},
"blocked": {
"boolVal": [
false
]
}
}
},
"citationMetadata": {
"structVal": {
"citations": {}
}
},
"content": {
"stringVal": [
RESPONSE
]
}
}
}
]
}
Chat kode
Model yang didukung saat ini adalah codechat-bison. Lihat versi yang tersedia.
Minta
PROJECT_ID=YOUR_PROJECT_ID
PROMPT="PROMPT"
AUTHOR="USER"
MODEL_ID=codechat-bison
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/us-central1/publishers/google/models/${MODEL_ID}:serverStreamingPredict -d \
$'{
"inputs": [
{
"struct_val": {
"messages": {
"list_val": [
{
"struct_val": {
"content": {
"string_val": [ "'"${PROMPT}"'" ]
},
"author": {
"string_val": [ "'"${AUTHOR}"'"]
}
}
}
]
}
}
}
],
"parameters": {
"struct_val": {
"temperature": { "float_val": 0.5 },
"maxOutputTokens": { "int_val": 1024 },
"topK": { "int_val": 40 },
"topP": { "float_val": 0.95 }
}
}
}'
Respons
{
"outputs": [
{
"structVal": {
"candidates": {
"listVal": [
{
"structVal": {
"content": {
"stringVal": [
RESPONSE
]
},
"author": {
"stringVal": [
AUTHOR
]
}
}
}
]
},
"citationMetadata": {
"listVal": [
{
"structVal": {
"citations": {}
}
}
]
},
"safetyAttributes": {
"listVal": [
{
"structVal": {
"categories": {},
"blocked": {
"boolVal": [
false
]
},
"scores": {}
}
}
]
}
}
}
]
}
Vertex AI SDK untuk Python
Untuk mengetahui informasi tentang cara menginstal Vertex AI SDK untuk Python, lihat Menginstal Vertex AI SDK untuk Python.
Teks
import vertexai
from vertexai.language_models import TextGenerationModel
def streaming_prediction(
project_id: str,
location: str,
) -> str:
"""Streaming Text Example with a Large Language Model"""
vertexai.init(project=project_id, location=location)
text_generation_model = TextGenerationModel.from_pretrained("text-bison")
parameters = {
"temperature": temperature, # Temperature controls the degree of randomness in token selection.
"max_output_tokens": 256, # Token limit determines the maximum amount of text output.
"top_p": 0.8, # Tokens are selected from most probable to least until the sum of their probabilities equals the top_p value.
"top_k": 40, # A top_k of 1 means the selected token is the most probable among all tokens.
}
responses = text_generation_model.predict_streaming(prompt="Give me ten interview questions for the role of program manager.", **parameters)
for response in responses:
`print(response)`
Chat
import vertexai
from vertexai.language_models import ChatModel, InputOutputTextPair
def streaming_prediction(
project_id: str,
location: str,
) -> str:
"""Streaming Chat Example with a Large Language Model"""
vertexai.init(project=project_id, location=location)
chat_model = ChatModel.from_pretrained("chat-bison")
parameters = {
"temperature": 0.8, # Temperature controls the degree of randomness in token selection.
"max_output_tokens": 256, # Token limit determines the maximum amount of text output.
"top_p": 0.95, # Tokens are selected from most probable to least until the sum of their probabilities equals the top_p value.
"top_k": 40, # A top_k of 1 means the selected token is the most probable among all tokens.
}
chat = chat_model.start_chat(
context="My name is Miles. You are an astronomer, knowledgeable about the solar system.",
examples=[
InputOutputTextPair(
input_text="How many moons does Mars have?",
output_text="The planet Mars has two moons, Phobos and Deimos.",
),
],
)
responses = chat.send_message_streaming(
message="How many planets are there in the solar system?", **parameters)
for response in responses:
`print(response)`
Kode
import vertexai
from vertexai.language_models import CodeGenerationModel
def streaming_prediction(
project_id: str,
location: str,
) -> str:
"""Streaming Chat Example with a Large Language Model"""
vertexai.init(project=project_id, location=location)
code_model = CodeGenerationModel.from_pretrained("code-bison")
parameters = {
"temperature": 0.8, # Temperature controls the degree of randomness in token selection.
"max_output_tokens": 256, # Token limit determines the maximum amount of text output.
}
responses = code_model.predict_streaming(
prefix="Write a function that checks if a year is a leap year.", **parameters)
for response in responses:
`print(response)`
Chat kode
import vertexai
from vertexai.language_models import CodeChatModel
def streaming_prediction(
project_id: str,
location: str,
) -> str:
"""Streaming Chat Example with a Large Language Model"""
vertexai.init(project=project_id, location=location)
codechat_model = CodeChatModel.from_pretrained("codechat-bison")
parameters = {
"temperature": 0.8, # Temperature controls the degree of randomness in token selection.
"max_output_tokens": 1024, # Token limit determines the maximum amount of text output.
}
codechat = codechat_model.start_chat()
responses = codechat.send_message_streaming(
message="Please help write a function to calculate the min of two numbers", **parameters)
for response in responses:
`print(response)`
Library klien yang tersedia
Anda dapat menggunakan salah satu library klien berikut untuk melakukan streaming respons:
- Python
- Node.js
- Java
- Go
- C#
Untuk melihat contoh permintaan dan respons kode menggunakan REST API, lihat Contoh menggunakan REST API.
Untuk melihat contoh permintaan dan respons kode menggunakan Vertex AI SDK untuk Python, lihat Contoh penggunaan Vertex AI SDK untuk Python.
Responsible AI
Filter responsible Artificial Intelligence (RAI)
memindai output streaming saat model menghasilkannya. Jika pelanggaran terdeteksi,
filter akan memblokir token output yang melanggar, dan menampilkan output dengan
tanda diblokir di bagian safetyAttributes, yang menghentikan streaming.
Langkah berikutnya
- Pelajari cara mendesain perintah teks dan perintah chat teks.
- Pelajari cara menguji perintah di Vertex AI Studio.
- Pelajari cara penyematan teks.
- Cobalah menyesuaikan model dasar bahasa.
- Pelajari praktik terbaik AI yang bertanggung jawab dan filter keamanan Vertex AI.