Introducing Approximate Nearest Neighbor (ANN) search to Spanner
Zhiyan Liu
Software Engineer
Vector search is a technique used to find items that are similar to a given query item within a large dataset. It's particularly useful when dealing with unstructured data like images, text, or audio, where traditional search methods (based on exact matches) might not be as effective. Vector search plays a crucial role in generative AI applications because it can also be used to enhance large language model (LLM) prompts, increasing relevance and reducing hallucinations. Having this functionality built into a general-purpose database means you will have scalable vector search capabilities integrated directly into your operational database, without the need to manage a separate database or ETL pipeline.
Spanner exact k-nearest neighbor (KNN) vector search, currently in preview, is a great fit for highly partitionable workloads such as searching through personal photos, where the number of entities involved in each query is relatively small. Since we launched KNN vector search earlier this year, it has seen increased adoption by Spanner customers. And now, for large-scale unpartitioned workloads, you can take advantage of approximate nearest neighbor (ANN) search in Spanner, delivering:
-
Scale and speed: fast, high-recall search scaling to more than 10B vectors
-
Operational simplicity: no need to copy your data to a specialized vector DB
-
Consistency: the results are always fresh, reflecting the latest updates
With the addition of ANN search capabilities, Spanner is ready to provide highly scalable and efficient support for your vector search needs. But don’t take our word for it, hear what our customers are saying:
"By leveraging the power of semantic understanding provided by Spanner’s vector search, we’re looking to deliver hyper-relevant content and experiences to our customers, resulting in increased engagement and conversion rates." - Aniel Sud, Chief Technology Officer, Optimizely
Using ANN
Let us walk you through the details of the innovations in Spanner that deliver vector search at scale.
Spanner leverages ScaNN (Scalable Nearest Neighbors), Google Research's highly efficient vector similarity search algorithm, which is an integral part of Google and Google Cloud applications. The main ScaNN-based optimizations that are now in Spanner include:
-
Cluster embeddings into a tree-like structure for fast query time pruning of the scoring space, trading accuracy for significant performance boost
-
Quantized raw vector embeddings to speed up scoring and reduce storage
-
Optimized distance calculation by focusing on the most relevant parts of the vectors, improving partitioning and ranking for better recall
To perform ANN in Spanner, you need to create a vector index on vector embeddings using standard SQL DDL, specifying the search tree shape and a distance type.
Tree shape
Depending on the dataset size, the tree can be two- or three-level. Three-level trees have an extra layer of branch nodes between the root and leaves, providing hierarchical partitioning that scales to 10B+ vector datasets. Representatives of the leaf partitions, called centroids, which themselves are also embeddings, are calculated and stored in the root and branch nodes.
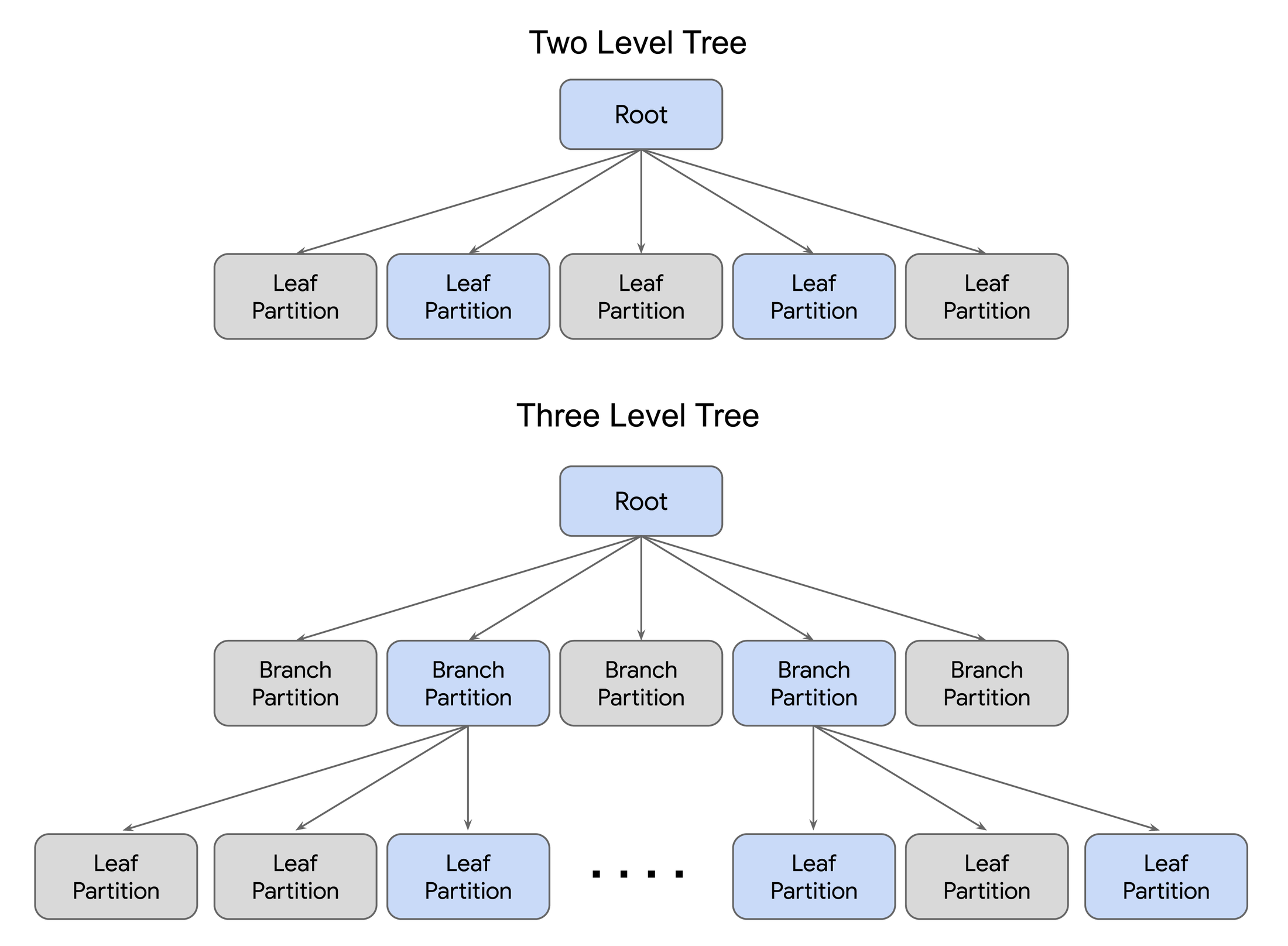
At query time, the incoming query embedding is first compared with all centroids stored in the root. Only the top closest centroids, and their corresponding leaves (for a two-level tree) or branches (for a three-level tree) are chosen for further evaluation. In the diagram above, the blue blocks represent the part of the search tree that is read for scoring, and the gray blocks represent the pruned part, which is the vast majority of the whole tree.
The number of branches and leaves in the tree can be configured at index creation time, while the number of leaves to search can be adjusted at query time. By tuning the indexing knobs as well as query options, you can achieve your desired performance and accuracy tradeoff.
Distance functions
Distance functions provide a way to measure similarity between vector embeddings. Spanner already supports exact distance functions for KNN search. With ANN, we are introducing the following approximate distance functions for ANN search to use with a vector index:
-
APPROX_COSINE_DISTANCE() -
APPROX_EUCLIDEAN_DISTANCE() -
APPROX_DOT_PRODUCT()
At vector index creation time, the desired distance type should be specified as an index option. Possible values are COSINE, EUCLIDEAN, and DOT_PRODUCT.
Queries on the vector index need to use the corresponding distance function.
Example: mutual fund search
Let’s look at the example that was showcased in our ANN demo. A customer is looking for the right mutual funds to invest in. Each row in the MutualFunds table represents one mutual fund:
-
FundIdis a unique identifier of the mutual fund, and may be cross referenced in other tables. -
FundNameis the full name of the mutual fund. -
InvestmentStrategyis an unstructured text string that describes the fund’s strategy. -
Attributesis a protocol buffer that stores some structured data about the fund, such as its return. -
InvestmentStrategyEmbeddingis a vector representation of the investment strategy, which can be generated using theML.PREDICTfunction.
Use the following statement to create a vector index on it:
If the number of mutual funds is high, a three-level tree may be better:
After an index is created, query it as follows. Note the query_embedding is a vector representation of the desired investment strategy, generated by ML.PREDICT based on user input text, using the same embedding model that the InvestmentStrategyEmbedding column is generated from:
The query means to search in 50 of the leaves, and find the top 10 mutual funds that most resemble the query investment strategy. Adjust the num_leaves_to_search value to trade latency for recall.
Note that, for now:
-
The vector index to use needs to be explicitly specified as a query hint.
-
The query needs to have the same null-filtering (
IS NOT NULL) clause as the vector index. -
The approximate distance function needs to match the
distance_typeof the vector index. -
The distance function must be the only ORDER BY key, and a LIMIT must be provided.
Advanced use cases
Post filtering
ANN search results can be filtered by adding attributes to the query’s WHERE clause. The following query will return the funds that match the query strategy and have a 10-year return rate above 8%.
Multi-model queries
If you also create a Full Text Search index on the FundName field:
you can perform queries to look for funds that both resemble the query strategy (which might be the vector representation of a phrase like, “balanced low risk socially responsible fund”), and have “emerging markets” in their name:
Or look for funds that either resemble the desired strategy, or have “emerging markets” in their names; allowing us to find text matches and semantic matches that don’t necessarily have those words:
This way you can either filter or augment the traditional text search results with semantically relevant results.
Getting started
Learn more about Spanner and try it out today. For additional information, check out:
-
Spanner vector search demo
-
Spanner ANN user guide
-
Vector embeddings and how you can use Spanner’s vector search in retail
-
How to use Spanner’s ML.PREDICT SQL function for in-database vector embedding generation (tutorial), LLM queries (tutorial), and online inference with custom models (tutorial) served by Vertex AI
-
Spanner’s AI ecosystem integrations including LangChain and the open-source spanner-analytics package that facilitates common data-analytic operations in Python and that includes integrations with Jupyter Notebooks
