Building continuous integration & continuous delivery for autonomous vehicles on Google Cloud
Mo Elshenawy
Executive Vice President of Engineering, Cruise
San Francisco’s roads are a notoriously tough place for people to drive. Narrow streets, busy pedestrian traffic, and an extensive network of bicycle routes make driving through San Francisco roughly 40 times more complex than driving in a suburban environment, according to Cruise data. This level of complexity makes San Francisco, America’s second densest city, an ideal environment for testing the most advanced self-driving technology found in today’s autonomous vehicles (AVs).
Cruise has been focused on tackling city driving since 2013, and with more than 3 million autonomous miles under our belt, we are getting close to delivering an all-electric, shared, self-driving service. In January 2022 we reached a major milestone — members of the public took their first fully driverless rides in San Francisco.
Developing an urban fleet of fully autonomous vehicles is an incredible challenge. To be successful, we needed to build both the AV tech that’s out on the road and the ecosystem of tools our engineers use internally.
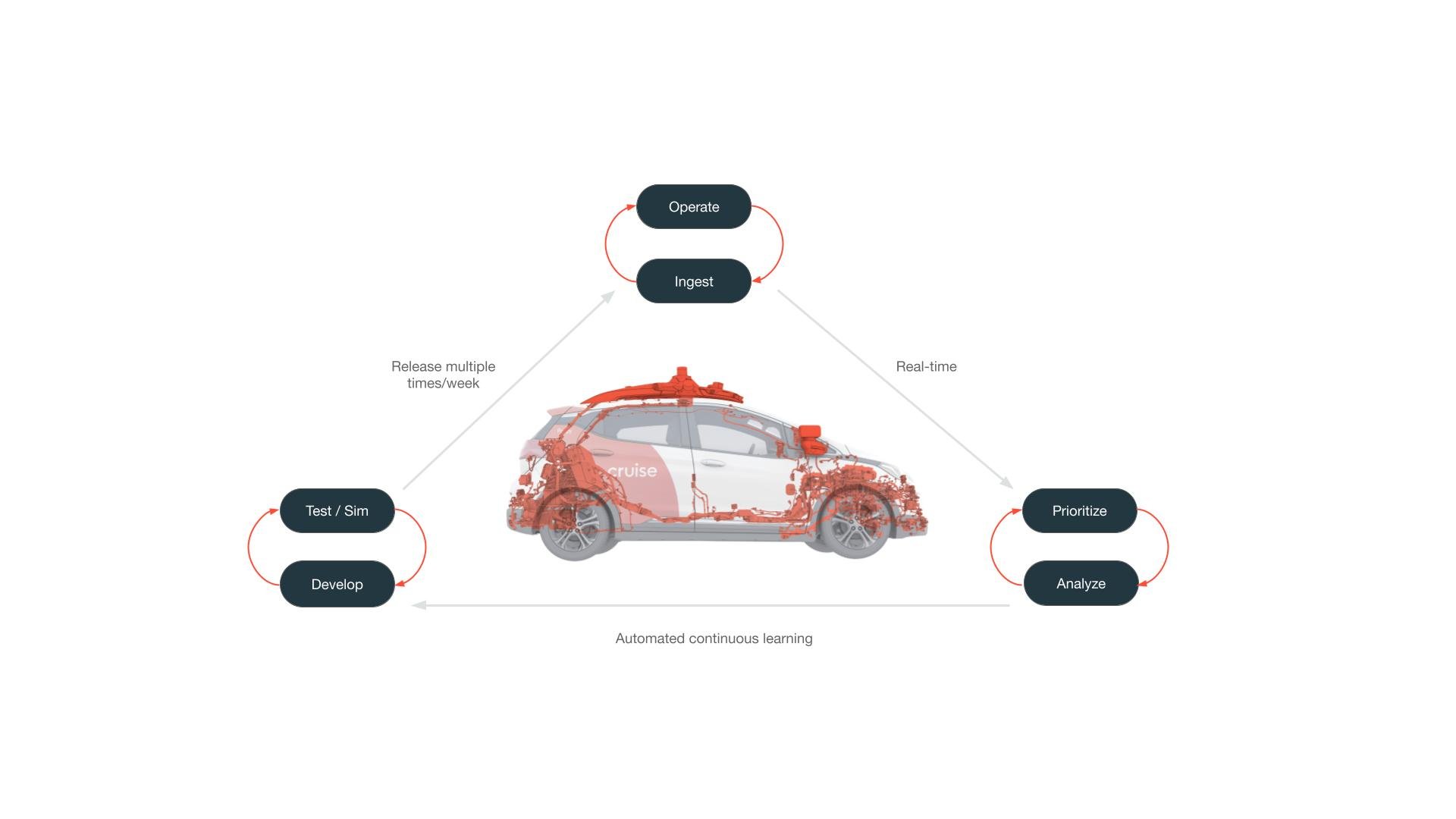
In creating this cycle, we thought carefully about how to best empower our engineers. Home-grown technology chains like this can get unwieldy quickly — the last thing you want as an engineer is to fight the disparate tools you are using or jump across too many of them to get your daily work done. Google Cloud has been a useful tool for us as we worked to streamline and support this development cycle, adapt our cloud-first infrastructure strategy, and seamlessly scale our systems. The frameworks we use in the vehicle, data logging, visualization, data mining, and ML modeling are all built on top of a common foundation that makes going from road to code — and from code to road — fast and safe.
Let’s take a deeper look at how Google Cloud supports the pillars of our homegrown AV development cycle.
The foundational platform
At the base of this development cycle is a strong foundation of Google Kubernetes Engine (GKE) and Compute Engine virtual machines (VMs) with other Google Cloud Infrastructure Services such as Cloud Storage, CloudSQL, PubSub, Cloud Functions, BigQuery, App Engine, and Cloud Logging and Monitoring, etc. We chose to use Kubernetes (k8s) to build our multi-tenant, multi environment Platform as a Service, and build a homegrown tool we call “Juno” that helps Cruise application developers to iterate and deploy at scale instantaneously.
On this Kubernetes and Istio-based Service platform (PaaS) we reuse a set of Kubernetes (k8s) operators/controllers to manage k8s clusters, manage nodepool migrations, and inject default add-ons for monitoring, logging, and service mesh. Under the hood we reuse Google Cloud’s Config Connector to manage dependencies while creating k8s resources. We run containerized workloads namespaced for multi-tenancy with high compute utilization and less operational overhead. We choose to isolate k8s clusters on the Service platform across development, staging, and production environments. We have also standardized continuous integration and continuous delivery to each of these environments.
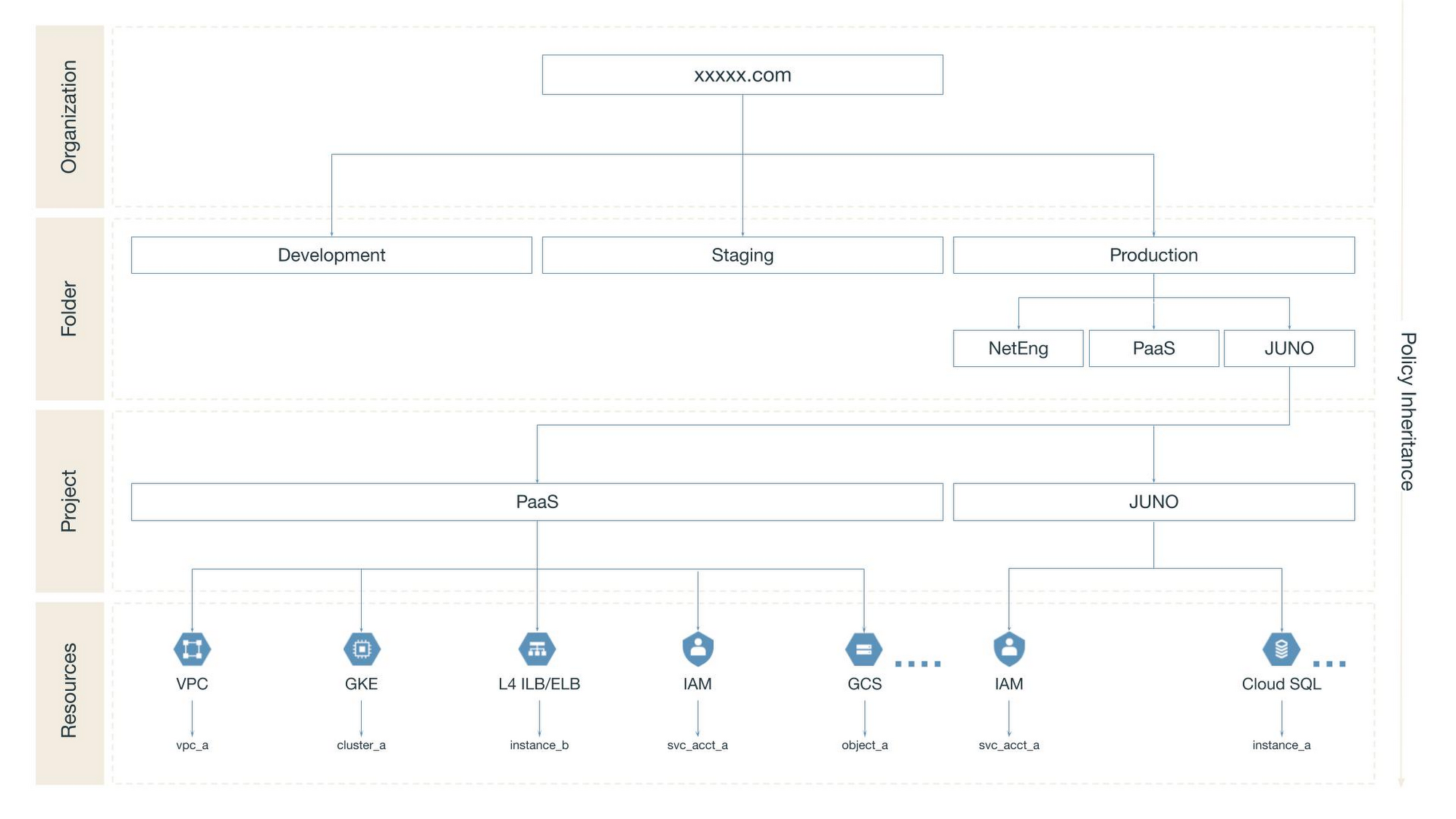
At the infrastructure level, we configured Google Cloud with vertical and horizontal boundaries. These boundaries and permissions, including Kubernetes namespace RBAC, Google Cloud projects and Google groups are managed centrally with our homegrown resource lifecycle manager, PaaS Juno.
Vertically, we use Google Cloud folders and projects to separate each team’s development, staging, and production environments from other teams’. These environments each have their own VPC, subnets, firewalls, interconnects, NAT gateways, private DNS, and any other Google Cloud service that the application service may need, for example GKE/k8s, Compute Engine, Cloud Storage, Pub/Sub, etc. The services are connected by a network, but traffic between them can be easily audited and regulated.
Horizontally, Google Cloud projects within each environment allow for distinct permission management and visibility constraints between tenants. Projects make it easy for tenants to focus on what matters to them. Separation between tenants makes it harder for malicious actors to gain unauthorized access, and prevents tenants from accidentally impacting one another.
The ML Brain: ingestion, analysis and modeling
With this strong foundation in place, we’re able to start feeding the pipeline. Every day, we traverse San Francisco’s city streets and collect a lot of anonymized road data.
At a high level, we take all sensor data as input — from camera, lidar, audio to radar. From there, Cloud Storage and Dataflow help us create highly scalable ETL pipelines and data lakes to create and extract petabytes of on-the-road data quickly and efficiently. Leveraging BigQuery, few hundred engineers are able to process exabytes of data across more than 20 million queries every month.
But even in San Francisco, less than 1% of the raw data contains useful information, and we quickly realized that we would need to distinguish the signal from the noise to make this work. At our scale, automation was the only answer, so we invested heavily in automatic AI-based event extraction and classification. Using advanced AI for scene understanding, today we can automatically label and tag many different classes of events, and then make them immediately available to every engineer. For example, we rely on panoptic segmentation to recognize trash bins and other objects along the side of the road; we use fine-grained classification to distinguish emergency vehicles from other cars; and we track objects across time and sensors to estimate their motions.
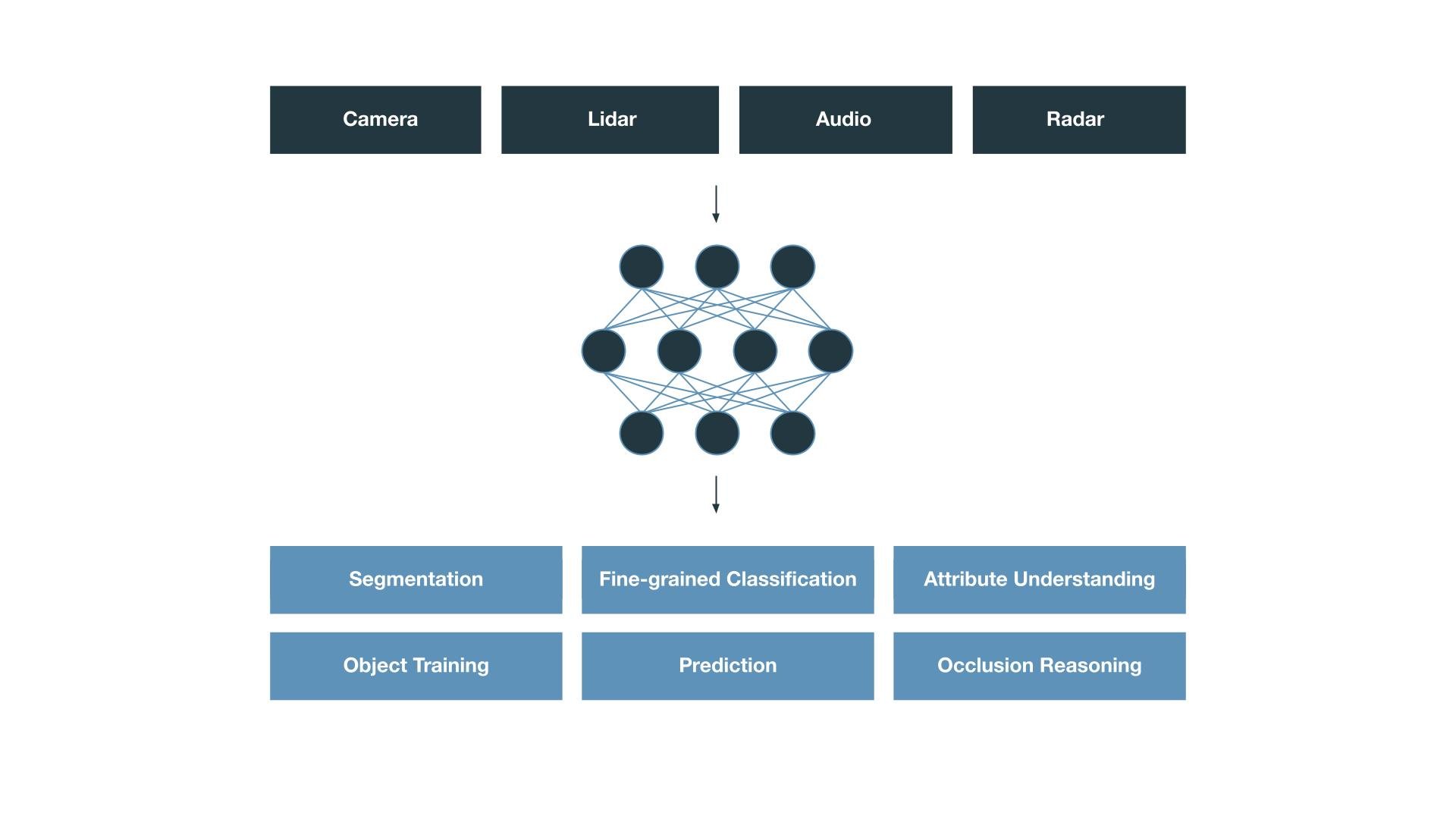
After we ingest and analyze that data, it’s fed back into our dynamic ML Brain — a continuous learning machine that actively mines from the collected data to automatically train new models that exceed the performance of the older models. This is done with the help of Vertex AI, where we are able to train hundreds of models simultaneously, using hundreds of GPU years every month!
Together, the automation, data sharing, and collaboration that Google Cloud’s tools provide supercharge Cruise engineers’ daily work.
Testing and simulation: Building an AV “time machine”
In addition to powering the ML Brain of the fleet, we also leverage our Google Cloud infrastructure to test/validate at scale, and build the confidence we need in order to release multiple times per week.
No matter how many miles our fleet racks up on the road, there will always be unexpected moments that we won’t capture with road miles alone—we need to couple road data with robust simulation data to ensure a safe and comfortable ride for future customers.
To make this happen, we developed a highly complex, distributed suite of testing and simulation tools that work in concert on top of Compute Engine.
First, we rely on a tool we call “Morpheus” to generate specific testing scenarios quickly. Simulations are a scalable way to perform robust testing around rare and difficult events at any time of day, in any condition, and in any location. Need to test an AV driving down a misty one-way road at twilight? Or see what it’s like to crest a steep hill while driving east at sunrise? What about a rush-hour evening drive along the Embarcadero on game day? Morpheus automatically creates a realistic real world to “drive” through to maintain Cruise’s rigorous safety standards.

To populate that world with unique driving scenarios we developed a tool called “Road-to-Sim” which fuses information from our millions of real-world miles to create a full-simulation environment from road data. This is an automated conversion pipeline that procedurally recreates any on-road event without manual intervention. This lets us easily create permutations of the event and change attributes like vehicle and pedestrian types.
Simulation helps us prepare for geographic scale as well. We developed “WorldGen”, a system that can procedurally generate entire cities, allowing us to test in new operational design domains more efficiently and with a shorter lead time. By combining multiple sources of data, we build seamless map tiles across large geographic areas that can immediately be used for large-scale testing.
At the root of this robust simulation engine is “Hydra”, our homegrown batch scheduling platform that scales up to tens of thousands of custom VMs that are optimized using Google Cloud's custom instances to run millions of simulations every day.
While Hydra is a batch servicer, we have many types of batch workloads like simulation, ground truth labeling, and remote builds. All in all, Google Cloud’s highly elastic platform allows us to easily consume 10s of GPU years per day and 1000s of core years per day. In return, our simulation engine generates petabytes of synthetic data daily, which then is parsed, analyzed and fed back into our development cycle.
This robust simulation and testing engine not only helps us scale and improve our current fleet of AVs, it also gives us a head start in testing and validating our next-generation vehicle: the Origin. Before the Origin ever hits the road, it will have been driving in simulation for years beforehand, encountering and learning from countless long-tail events in the cloud.
Ensuring resilience amidst uncertainty
In addition to supporting our continuous development cycle, Google Cloud has supported our infrastructure and engineering teams during a period of high growth and unprecedented challenges. Since early 2020, the Cruise Development Platform has proved to be resilient as our engineering team has nearly doubled in size, our workforce transitioned from in-office to work-from-home, and the tech industry has encountered unprecedented supply chain shortages.
During this time, Google Cloud has enabled the entire organization to seamlessly scale:
We grew our compute usage by 6x from the month preceding the pandemic to the present
During this pandemic-era transition we tripled our daily compute usage
We also tripled our total capacity enabling us to scale up by more than 150x our base usage in any given day.
Now, we have the ability to serialize terabytes of data per minute.
A strong and scalable infrastructure is critical for our ability to offer rides to paying customers on complex city roads. As we inch closer to that reality, Google Cloud gives us unprecedented speed and elasticity in our systems, and ensures the high level of safety our fleet needs.
For more information on the complex chain of technologies powering Cruise AVs, watch our engineering showcase “Under the Hood.”



