In-memory query execution in Google BigQuery
Hossein Ahmadi
BigQuery Technical Lead
BigQuery is a fast petabyte-scale analytics database. To achieve that level of performance, BigQuery executes queries completely in memory. Most databases and data processing systems achieve scalability using hybrid executors that operate on both disk and memory. Meanwhile, BigQuery’s execution engine builds simple and purely in-memory operators and achieves petabyte-scale analytics through scalable data repartitioning, or "shuffle." This post takes a closer look at BigQuery shuffle, and how it enables high performance, in-memory query execution by leveraging Google’s petabit-scale networking technologies, such as Jupiter.
Shuffle is a key ingredient in any distributed data processing system, from Hadoop and Spark to Google Cloud Dataflow. The shuffle step is required for execution of large and complex joins, aggregations and analytic operations. For example, MapReduce uses the shuffle step as a mechanism to redistribute data between the "map" and "reduce" steps based on mapped keys. To support large-scale computation, shuffled data is transiently stored on remote servers. This enables separation of "map" and "reduce" phases and is a key principle in supporting large-scale data processing. The shuffle step is notoriously slow — Hadoop engineers joke that MapReduce should really be called small Map, huge Shuffle, and small Reduce.
The variety of BigQuery query characteristics and requirements called for rethinking of the shuffle step. In 2014, BigQuery shuffle migrated to a newly developed infrastructure that's memory-based (with support for disk spooling) and specifically designed for Google data center networking technology. Moreover, it's designed as a flexible data delivery system with use cases beyond specific distributed operations, for example hash joins. This project culminated a multi-year research and development effort on data transfer technologies.
In-memory BigQuery shuffle stores intermediate data produced from various stages of query processing in a set of nodes that are dedicated to hosting remote memory. Persisting the intermediate results of a data processing job is common in many systems, such as Spark (in the form of RDDs) or Piccolo (in the form of distributed hash sets). However, BigQuery takes a different direction with respect to in-memory intermediate results in a form that's tightly integrated with shuffle operations.
The data repartitioning abstraction defined by BigQuery shuffle consists of three entities: a producer creates data to be repartitioned, a consumer receives the repartitioned data and a controller process manages the shuffle. Shuffle defines the following high-level operations:
This API is carefully designed to provide a shared-memory abstraction at the right level: It's general purpose enough to support any form of data repartitioning and transfer in a data processing pipeline, yet it's specific enough to be implemented efficiently using Google networking technology. Conceptually, a shuffle operation can be illustrated as such:
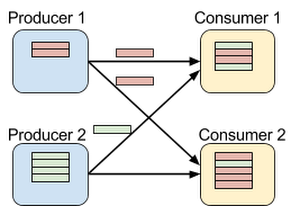
Given the particular set of operations supported by the above abstraction, BigQuery shuffle allows many producers to write to remote memory with minimal overhead and fragmentation while consumers can read concurrently with high throughput. In particular, producers log and index the created rows in a contiguous memory block. This index allows consumers to efficiently access the relevant rows and retrieve them. Additionally, BigQuery’s data structure and its communication protocol take advantage of hardware acceleration enabled by the Jupiter networking infrastructure.
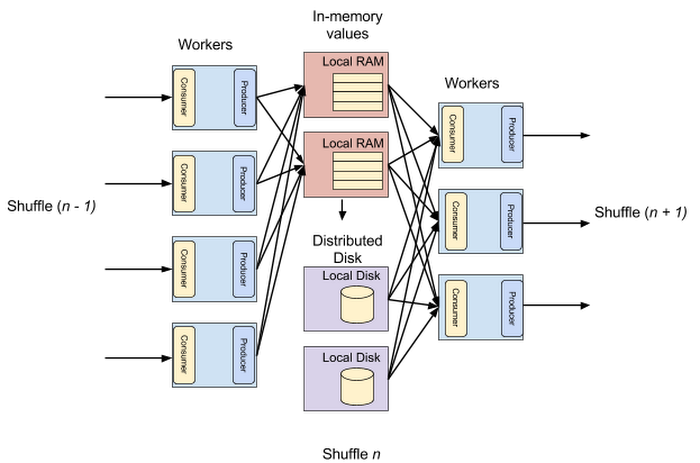
In addition to repartitioning data in-memory, BigQuery shuffle is different from the MapReduce-style of shuffle in another aspect: It does not act as a barrier between various stages of the data flow graph. Unlike MapReduce-style shuffles, where the first row in the repartitioned data set can be used after all rows have been sent and sorted, in BigQuery, each shuffled row can be consumed by BigQuery workers as soon as it's created by the producers. This makes it possible to execute distributed operations in a pipeline.
The partitioning of data has a significant impact on the performance of BigQuery queries. Specifically, it's important to use the right number of consumers and the right mapping function from producers to consumer to achieve the best result. Non-optimal partitioning can cause queries to run orders of magnitude slower and even fail due to resource constraints.
BigQuery uses a dynamic partitioning mechanism that intelligently chooses partitioning based on the type of operators used in the query, the data volume, background load and other factors. This functionality lets BigQuery users run efficient queries on arbitrary datasets, without the overhead of specifying distribution or sort keys.
BigQuery can be used to query petabytes of data. In many cases, the volume of data to be repartitioned makes purely in-memory shuffling cost-prohibitive. BigQuery shuffle addresses this issue by restructuring and moving transient data from remote memory to Colossus, Google’s distributed file system. Given that the performance characteristics of disk are fundamentally different from memory, BigQuery takes special care to automatically organize data in such a way that it minimizes disk seeks.
BigQuery is a multi-tenant service that allows any customer to start running queries without sizing or deploying a cluster of virtual machines or provisioning resources. To do that, BigQuery shuffle uses an intelligent memory resource management system that allows running most queries purely in memory. The system adapts instantaneously to load variations from customers.
Every BigQuery query involves one or more shuffle operations, and the same infrastructure is used to transfer a single row of data or query petabytes of data. The extreme flexibility of BigQuery shuffle combined with the tight integration with Google networking technology allows BigQuery users to take advantage of fast data analytics at any scale.



