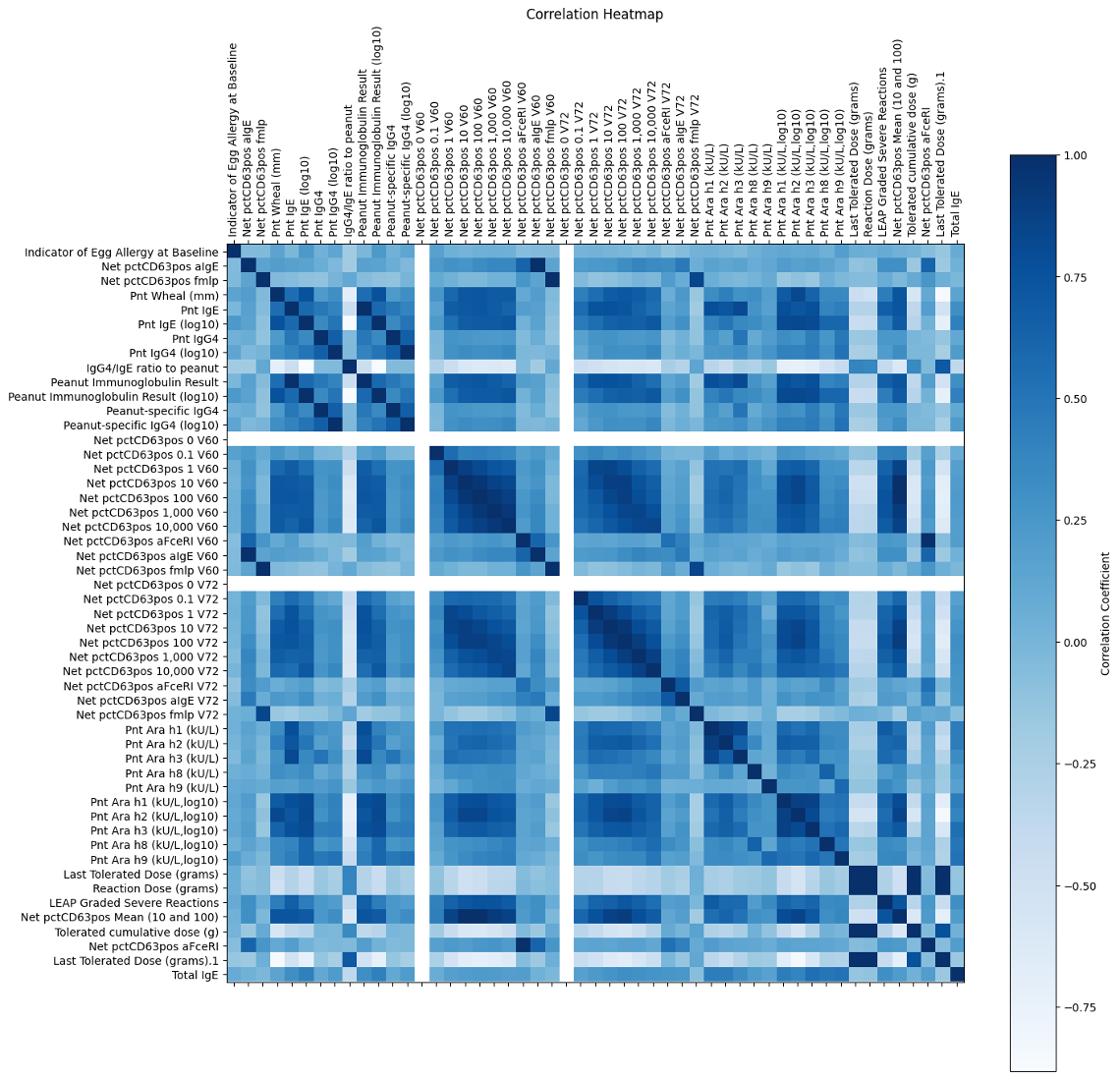
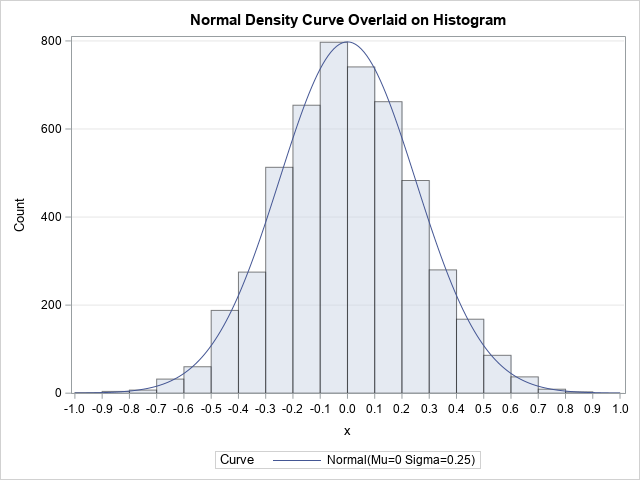
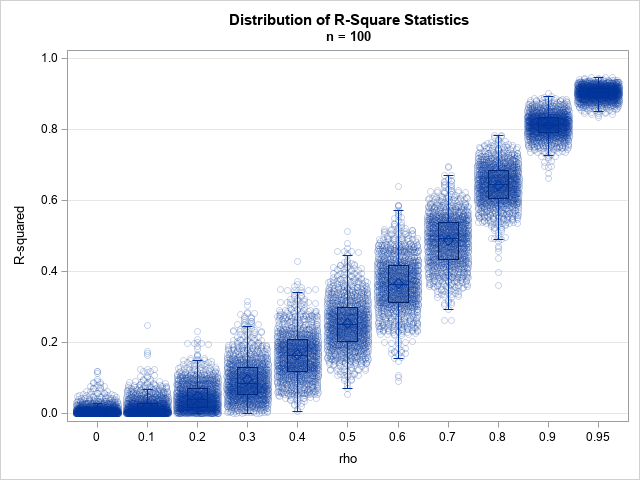
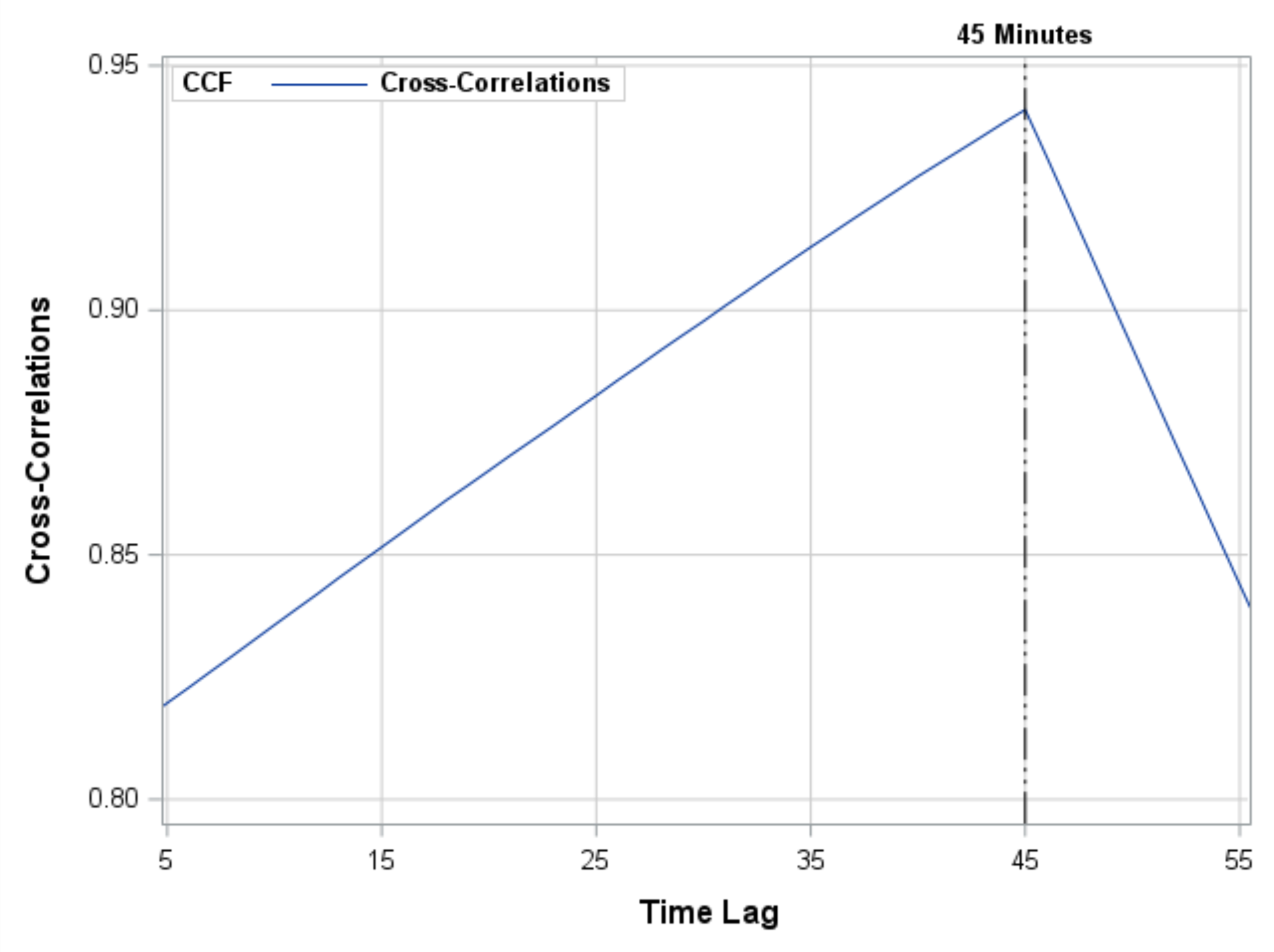
Get the right information, with visual impact, to the people who need it

A normal Christmas tree

O Christmas tree, O Christmas tree, How lovely are your branches! SAS programmers have a long history of creating yuletide-themed graphics. Christmas trees are a popular image because of their simplicity. I admit that I have indulged more than once in this holiday tradition: An old-school ASCII art image A