The Wikimedia family of websites includes one known as Wikimedia Commons. Its mission is to collect and organize freely licensed media so that other people can re-use them. More pragmatically, it collects all the files needed by different language Wikipedias (and other Wikimedia projects) into one place.
As you can imagine, it's extremely useful to have a library of freely licensed photos that you can just use to illustrate your articles.
However, it is not just useful for people writing encyclopedias. It is also useful for any sort of project.
To take advantage of this, MediaWiki, the software that powers Wikipedia and friends, comes with a feature to use this collection on your own Wiki. It's an option you can select when installing the software and is quite popular. Alternatively, it can be manually configured via $wgUseInstantCommons or the more advanced $wgForeignFileRepos.
The Issue
Unfortunately, instant commons has a reputation for being rather slow. As a weekend project I thought I'd measure how slow, and see if I could make it faster.
How Slow?
First things first, I'll need a test page. Preferably something with a large (but not extreme) number of images but not much else. A Wikipedia list article sounded ideal. I ended up using the English Wikipedia article: List of Governors General of Canada (Long live the Queen!). This has 85 images and not much else, which seemed perfect for my purposes.
I took the expanded Wikitext from https://en.wikipedia.org/w/index.php?title=List_of_governors_general_of_Canada&oldid=1054426240&action=raw&templates=expand, pasted it into my test wiki with instant commons turned on in the default config.
And then I waited...
Then I waited some more...
1038.18761 seconds later (17 minutes, 18 seconds) I was able to view a beautiful list of all my viceroys.
Clearly that's pretty bad. 85 images is not a small number, but it is definitely not a huge number either. Imagine how long [[Comparison_of_European_road_signs]] would take with its 3643 images or [[List_of_paintings_by_Claude_Monet]] with 1676.
Why Slow?
This raises the obvious question of why is it so slow. What is it doing for all that time?
When MediaWiki turns wikitext into html, it reads through the text. When it hits an image, it stops reading through the wikitext and looks for that image. Potentially the image is cached, in which case it can go back to rendering the page right away. Otherwise, it has to actually find it. First it will check the local DB to see if the image is there. If not it will look at Foreign image repositories, such as Commons (if configured).
To see if commons has the file we need to start making some HTTPS requests¹:
- We make a metadata request to see if the file is there and get some information about it: https://commons.wikimedia.org/w/api.php?titles=File%3AExample.png&iiprop=timestamp%7Cuser%7Ccomment%7Curl%7Csize%7Csha1%7Cmetadata%7Cmime%7Cmediatype%7Cextmetadata&prop=imageinfo&iimetadataversion=2&iiextmetadatamultilang=1&format=json&action=query&redirects=true&uselang=en
- We make an API request to find the url for the thumbnail of the size we need for the article. For commons, this is just to find the url, but on wikis with 404 thumbnail handling disabled, this is also needed to tell the wiki to generate the file we will need: https://commons.wikimedia.org/w/api.php?titles=File%3AExample.png&iiprop=url%7Ctimestamp&iiurlwidth=300&iiurlheight=-1&iiurlparam=300px&prop=imageinfo&format=json&action=query&redirects=true&uselang=en
- Some devices now have very high resolution screens. Screen displays are made up of dots. High resolution screens have more dots per inch, and thus can display more fine detailed. Traditionally 1 pixel equalled one dot on the screen. However if you keep that while increasing the dots-per-inch, suddenly everything on the screen that was measured in pixels is very small and hard to see. Thus these devices now sometimes have 1.5 dots per pixel, so they can display fine detail without shrinking everything. To take advantage of this, we use an image 1.5 times bigger than we normally would, so that when it is displayed in its normal size, we can take advantage of the extra dots and display a much more clear picture. Hence we need the same image but 1.5x bigger: https://commons.wikimedia.org/w/api.php?titles=File%3AExample.png&iiprop=url%7Ctimestamp&iiurlwidth=450&iiurlheight=-1&iiurlparam=450px&prop=imageinfo&format=json&action=query&redirects=true&uselang=en
- Similarly, some devices are even higher resolution and use 2 dots per pixel, so we also fetch an image double the normal size: https://commons.wikimedia.org/w/api.php?titles=File%3AExample.png&iiprop=url%7Ctimestamp&iiurlwidth=600&iiurlheight=-1&iiurlparam=600px&prop=imageinfo&format=json&action=query&redirects=true&uselang=en
This is the first problem - for every image we include we have to make 4 api requests. If we have 85 images that's 340 requests.
Latency and RTT
It gets worse. All of these requests are done in serial. Before doing request 2, we wait until we have the answer to request 1. Before doing request 3 we wait until we get the answer to request 2, and so on.
Internet speed can be measured in two ways - latency and bandwidth. Bandwidth is the usual measurement we're familiar with: how much data can be transferred in bulk - e.g. 10 Mbps.
Latency, ping time or round-trip-time (RTT) is another important measure - it's how long it takes your message to get somewhere and come back.
When we start to send many small messages in serial, latency starts to matter. How big your latency is depends on how close you are to the server you're talking to. For Wikimedia Commons, the data-centers (DCs) are located in San Francisco (ulsfo), Virginia (eqiad), Texas (codfw), Singapore (eqsin) and Amsterdam (esams). For example, I'm relatively close to SF, so my ping time to the SF servers is about 50ms. For someone with a 50ms ping time, all this back and forth will take at a minimum 17 seconds just from latency.
However, it gets worse; Your computer doesn't just ask for the page and get a response back, it has to setup the connection first (TCP & TLS handshake). This takes additional round-trips.
Additionally, not all data centers are equal. The Virginia data-center (eqiad)² is the main data center which can handle everything, the other DCs only have varnish servers and can only handle cached requests. This makes browsing Wikipedia when logged out very speedy, but the type of API requests we are making here cannot be handled by these caching DCs³. For requests they can't handle, they have to ask the main DC what the answer is, which adds further latency. When I tried to measure mine, i got 255ms, but I didn't measure very rigorously, so I'm not fully confident in that number. In our particular case, the TLS & TCP handshake are handled by the closer DC, but the actual api response has to be fetched all the way from the DC in Virginia.
But wait, you might say: Surely you only need to do the TLS & TCP setup once if communicating to the same host. And the answer would normally be yes, which brings us to major problem #2: Each connection is setup and tore down independently, requiring us to re-establish the TCP/TLS session each time. This adds 2 additional RTT. In our 85 image example, we're now up to 1020 round-trips. If you assume 50ms to caching DC and 255ms to Virginia (These numbers are probably quite idealized, there are probably other things I'm not counting), we're up to 2 minutes.
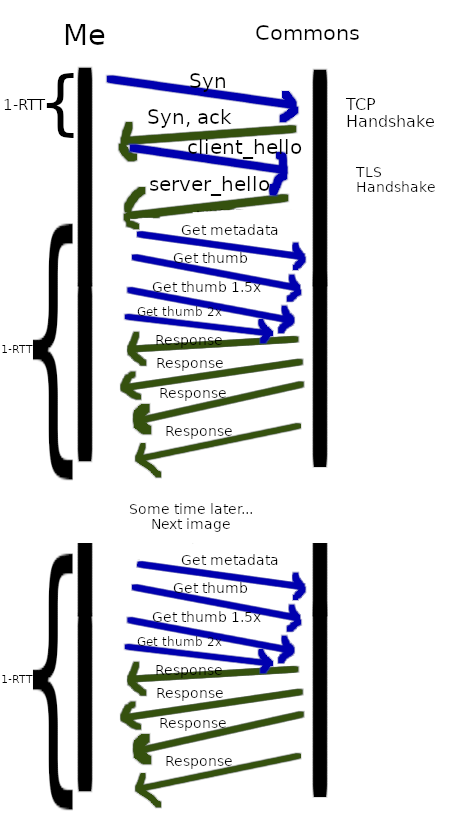
To put it altogether, here is a diagram representing all the back and forth communication needed just to use a single image:
12 RTT per image used! This is assuming TLS 1.3. Earlier versions of TLS would be even worse.
Introducing HTTP/2
In 2015, HTTP/2 came on the scene. This was the first major revision to the HTTP protocol in almost 20 years.
The primary purpose of this revision of HTTP, was to minimize the effect of latency when you are requesting many separate small resources around the same time. It works by allowing a single connection to be reused for many requests at the same time and allowing the responses to come in out of order or jumbled together. In HTTP/1.1 you can sometimes be stuck waiting for some request to finish before being allowed to start on the next one (Head of line blocking) resulting in inefficient use of network resources
This is exactly the problem that instant commons was having.
Now I should be clear, instant commons wasn't using HTTP/1.1 in a very efficient way, and it would be possible to do much better even with HTTP/1.1. However, HTTP/2 will still be that much better than what an improved usage of HTTP/1.1 would be.
Changing instant commons to use HTTP/2 changed two things:
- Instead of creating a new connection each time, with multiple round trips to set up TCP and TLS, we just use a single HTTP/2 connection that only has to do the setup once.
- If we have multiple requests ready to go, send them all off at once instead of having to wait for each one to finish before sending the next one.
We still can't do all requests at once, since the MediaWiki parser is serial, and it stops parsing once we hit an image, so we need to get information about the current image before we will know what the next one we need is. However, this still helps as for each image, we send 4 requests (metadata, thumbnail, 1.5dpp thumbnail and 2dpp thumbnail), which we can now send in parallel.
The results are impressive for such a simple change. Where previously my test page took 17 minutes, now it only takes 2 (139 seconds).
Transform via 404
In vanilla MediaWiki, you have to request a specific thumbnail size before fetching it; otherwise it might not exist. This is not true on Wikimedia Commons. If you fetch a thumbnail that doesn't exist, Wikimedia Commons will automatically create it on the spot. MediaWiki calls this feature "TransformVia404".
In instant commons, we make requests to create thumbnails at the appropriate sizes. This is all pointless on a wiki where they will automatically be created on the first attempt to fetch them. We can just output <img> tags, and the first user to look at the page will trigger the thumbnail creation. Thus skipping 3 of the requests.
Adding this optimization took the time down from 139 seconds with just HTTP/2 to 18.5 seconds with both this and HTTP/2. This is 56 times faster than what we started with!
Prefetching
18.5 seconds is pretty good. But can we do better?
We might not be able to if we actually have to fetch all the images, but there is a pattern we can exploit.
Generally when people edit an article, they might change a sentence or two, but often don't alter the images. Other times, MediaWiki might re-parse a page, even if there are no changes to it (e.g. Due to a cache expiry). As a result, often the set of images we need is the same or close to the set that we needed for the previous version of the page. This set is already recorded in the database in order to display what pages use an image on the image description page
We can use this. First we retrieve this list of images used on the (previous version) of the page. We can then fetch all of these at once, instead of having to wait for the parser to tell us one at a time which image we need.
It is possible of course, that this list could be totally wrong. Someone could have replaced all the images on the page. If it's right, we speed up by pre-fetching everything we need, all in parallel. If it's wrong, we fetched some things we didn't need, possibly making things slower than if we did nothing.
I believe in the average case, this will be a significant improvement. Even in the case that the list is wrong, we can send off the fetch in the background while MediaWiki does other page processing - the hope being, that MediaWiki does other stuff while this fetch is running, so if it is fetching the wrong things, time is not wasted.
On my test page, using this brings the time to render (Where the previous version had all the same images) down to 1.06 seconds. A 980 times speed improvement! It should be noted, that this is time to render in total, not just time to fetch images, so most of that time is probably related to rendering other stuff and not instant commons.
Caching
All the above is assuming a local cache miss. It is wasteful to request information remotely, if we just recently fetched it. It makes more sense to reuse information recently fetched.
In many cases, the parser cache, which in MediaWiki caches the entire rendered page, will mean that instant commons isn't called that often. However, some extensions that create dynamic content make the parser cache very short lived, which makes caching in instant commons more important. It is also common for people to use the same images on many pages (e.g. A warning icon in a template). In such a case, caching at the image fetching layer is very important.
There is a downside though, we have no way to tell if upstream has modified the image. This is not that big a deal for most things. Exif data being slightly out of date does not matter that much. However, if the aspect ratio of the image changes, then the image will appear squished until InstantCommons' cache is cleared.
To balance these competing concerns, Quick InstantCommons uses an adaptive cache. If the image has existed for a long time, we cache for a day (configurable). After all, if the image has been stable for years, it seems unlikely it is going to be edited in very soon. However, if the image has been edited recently, we use a dynamically determined shorter time to live. The idea being, if the image was edited 2 minutes ago, there is a much higher possibility that it might be edited a second time. Maybe the previous edit was vandalism, or maybe it just got improved further.
As the cache entry for an image begins to get close to expiring, we refetch it in the background. The hope is that we can use the soon to be expired version now, but as MediaWiki is processing other things, we refetch in background so that next time we have a new version, but at the same time we don't have to stall downloading it when MediaWiki is blocked on getting the image's information. That way things are kept fresh without a negative performance impact.
MediaWiki's built-in instant commons did support caching, however it wasn't configurable and the default time to live was very low. Additionally, the adaptive caching code had a bug in it that prevented it from working correctly. The end result was that often the cache could not be effectively used.
Missing MediaHandler Extensions
In MediaWiki's built-in InstantCommons feature, you need to have the same set of media extensions installed to view all files. For example, PDFs won't render via instant commons without Extension:PDFHandler.
This is really unnecessary where the file type just renders to a normal image. After all, the complicated bit is all on the other server. My extension fixes that, and does its best to show thumbnails for file types it doesn't understand. It can't support advanced features without the appropriate extension e.g. navigating in 3D models, but it will show a static thumbnail.
Conclusion
In the end, by making a few, relatively small changes, we were able to improve the performance of instant commons significantly. 980 times as fast!
Do you run a MediaWiki wiki? Try out the extension and let me know what you think.
Footnotes:
¹ This is assuming default settings and an [object] cache miss. This may be different if $wgResponsiveImages is false in which case high-DPI images won't be fetched, or if apiThumbCacheExpiry is set to non-zero in which case thumbnails will be downloaded locally to the wiki server during the page parse instead of being hotlinked.
² This role actually rotates between the Virginia & Texas data center. Additionally, the Texas DC (when not primary) does do some things that the caching DCs don't that isn't particularly relevant to this topic. There are eventual plans to have multiple active DCs which all would be able to respond to the type of API queries being made here, but they are not complete as of this writing - https://www.mediawiki.org/wiki/Wikimedia_Performance_Team/Active-active_MediaWiki
³ The MediaWiki API actually supports an smaxage=<number of seconds> (shared maximum age) url parameter. This tells the API server you don't care if your request is that many seconds out of date, and to serve it from varnish caches in the local caching data center if possible. Unlike with normal Wikipedia page views, there is no cache invalidation here, so it is rarely used and it is not used by instant commons.






{kind=link}
{kind=link}
{kind=link}
{kind=link}